Back to blog
Next Chapter for Real-Time Crawler: New Products With Dedicated Focus

Gabija Fatenaite
For the past few months, we have been working on some changes for our Real-Time Crawler product. We are happy to finally announce that starting today, our scraper will be switching its focus (and its name) and will be split into three distinct Scraper APIs.
Our product was great and it served its purpose well, but it was time for a change. In today’s blog post, we’ll explain why we’ve decided to evolve it.
So what has changed?
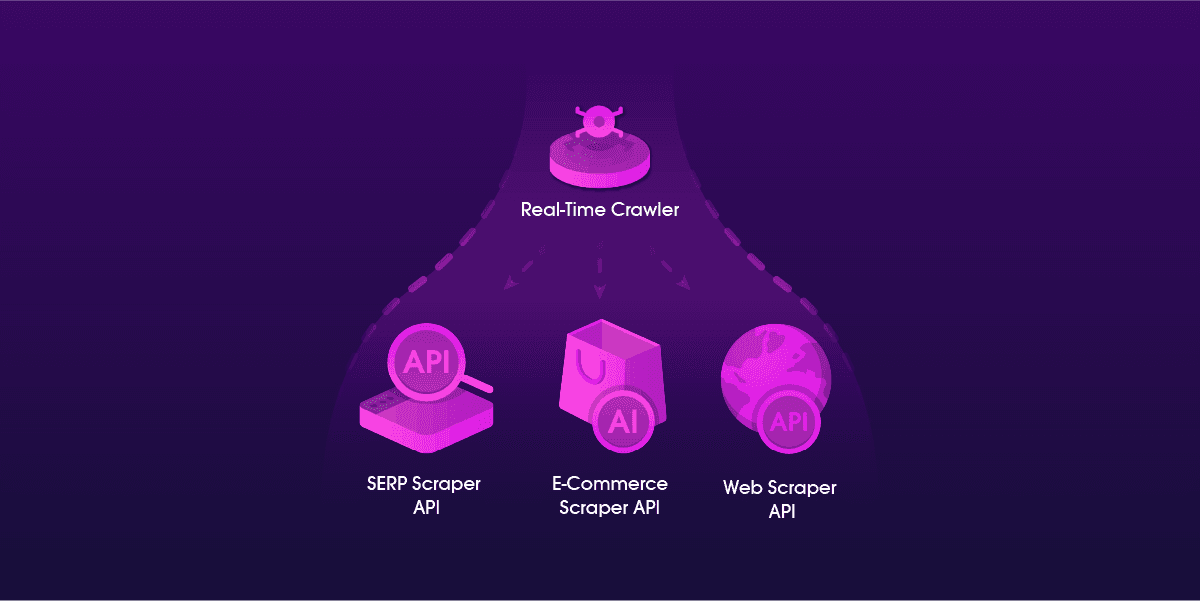
Real-Time Crawler was one of the first data gathering tools in the web scraping industry that focused on gathering e-commerce and search engine data on a large scale. It helped a number of companies to easily acquire public data, but now we are making it even better both internally and externally.

Aleksandras Šulženko, Scraper APIs Product Owner @Oxylabs
We distinguished Real-Time Crawler’s capabilities and developed it into three distinct scrapers covering specific targets. This allows us to focus on more agile product development and, in turn, improve the overall performance and user experience for our clients.
So, from now on, Real-Time Crawler becomes a group of powerful Scraper APIs, each using its own edge for the best results on the corresponding targets:
Refined product features
Scraper APIs were developed with more expressed features and benefits in mind. All Scraper APIs guarantee:
High data delivery success rate
Patented proxy rotator
High scalability
Easy integration
102M+ proxy infrastructure
Data delivery in your preferred way (AWS S3 or GCS)
24/7 support.
Each product shines through with specific benefits:
SERP Scraper API:
Localized search results
Live and reliable data
Resilient to SERP layout changes
E-Commerce Scraper API:
1000s of e-commerce websites available for scraping
Structured data in JSON
Web Scraper API:
Customizable request parameters
JavaScript rendering
Convenient data delivery
Best part is that with Scraper APIs, you can forget about proxy management and focus on data analysis.
New look
All Three Scraper APIs can now be identified by their updated logos matching the targets they cover:
Same integration methods
To keep it simple for our clients and all those who tried out our products before this update, we decided to keep the same integration and authentication methods, as well as the same request parameters.
SERP Scraper API authentication method
SERP Scraper API uses basic HTTP authentication that requires a username and a password. It’s one of the simplest ways to start using this tool. The code example below shows how to send a GET request to scrape data from a search engine using the Realtime method.* For more information, read SERP Scraper API quick start guide.
curl --user "USERNAME:PASSWORD" 'https://realtime.oxylabs.io/v1/queries' -H "Content-Type: application/json" -d '{"source": "SEARCH_ENGINE_search", "domain": "com", "query": "shoes"}'*For this example, you need to specify the exact source to find available sources. Please refer to the SERP Scraper API documentation.
E-Commerce Scraper API authentication method
E-Commerce Scraper API employs basic HTTP authentication which requires a username and a password. This is the easiest way to get started with the tool. The code example below shows how you can send a GET request to books.toscrape.com using the Realtime delivery method. For more information, read E-Commerce Scraper API quick start guide or E-Commerce Scraper API documentation:
curl --user "USERNAME:PASSWORD" 'https://realtime.oxylabs.io/v1/queries' -H "Content-Type: application/json" -d '{"source": "universal_ecommerce", "url": "https://books.toscrape.com/catalogue/a-light-in-the-attic_1000/index.html", "geo_location": "United States", "parse": true, "parser_type": "ecommerce_product"}'Web Scraper API authentication method
Web Scraper API employs basic HTTP authentication which requires a username and a password. This is the easiest way to get started with the tool. The code example below shows how you can send a GET request to https://ip.oxylabs.io/location using the Realtime delivery method. For more information, read Web Scraper API quick start guide or Web Scraper API documentation:
curl --user "USERNAME:PASSWORD"'https://realtime.oxylabs.io/v1/queries' -H "Content-Type: application/json" -d '{"source": "universal", "url": "https://ip.oxylabs.io/location"}'Wrapping up
Some changes all over the web and communication will happen over some period of time. All of these changes should be completed by the end of this year.
If you have any questions or suggestions regarding Scraper APIs changes, please feel free to contact us either via your Dedicated Account Manager or hello@oxylabs.io.
About the author
Gabija Fatenaite
Lead Product Marketing Manager
Gabija Fatenaite is a Lead Product Marketing Manager at Oxylabs. Having grown up on video games and the internet, she grew to find the tech side of things more and more interesting over the years. So if you ever find yourself wanting to learn more about proxies (or video games), feel free to contact her - she’ll be more than happy to answer you.
All information on Oxylabs Blog is provided on an "as is" basis and for informational purposes only. We make no representation and disclaim all liability with respect to your use of any information contained on Oxylabs Blog or any third-party websites that may be linked therein. Before engaging in scraping activities of any kind you should consult your legal advisors and carefully read the particular website's terms of service or receive a scraping license.
Related articles

Residential Proxies Price Drop: Now More Accessible Than Ever!
Yelyzaveta Nechytailo
2024-03-25

Introducing Oxylabs Scraper APIs Playground: A New Way to Test Out Our Scraper API Solutions
Danielius Radavicius
2023-09-05

Oxylabs Reaches 100M+ Ethically-Obtained Residential Proxies Mark
Vytautas Kirjazovas
2020-09-14

Get the latest news from data gathering world
Forget about complex web scraping processes
Choose Oxylabs' advanced web intelligence collection solutions to gather real-time public data hassle-free.
Scale up your business with Oxylabs®
GET IN TOUCH
General:
hello@oxylabs.ioSupport:
support@oxylabs.ioCareer:
career@oxylabs.io
Certified data centers and upstream providers
Connect with us
Advanced proxy solutions
Resources
Innovation hub
oxylabs.io© 2024 All Rights Reserved