175M+ ethically sourced IPs built for the highest reliability.
High-speed, cost-effective proxies built for any scraping workload.
Premium static residential proxies from trusted ASNs for most difficult targets.
Dedicated IPs from premium ASNs for demanding scraping.

AI-powered proxy solution for optimized web scraping performance.

20M+ IP addresses from real mobile devices for precise targeting.

Free Chrome proxy manager extension that works with any proxy provider.

Free Android proxy manager app that works with any proxy provider.

Free community-driven tools to improve your web scraping projects.
Web Scraper API
All-in-one web data collection platform for every stage of web scraping.
Fast Search API
Ultra-fast organic search results scraper tailored for AI workflows.
Headless Browser
Advanced browser automation solution for AI agents and scraping.
AI Studio
A suite of AI-powered tools for various scraping projects.

Documentation
All features, parameters, and integration details, backed by code samples in every coding language.
Tutorials, samples, and guides.
Latest fixes and features.






![]() AI Summary:
AI Summary:
This tutorial walks through building a custom Amazon ASIN scraper with Python, covering key challenges like anti-scraping measures and high-speed data collection, along with a simpler API-based alternative. It also outlines the full workflow, from setting up requests and parsing results to saving structured data.
Scraping Amazon ASIN data has many benefits for your competitive e-commerce strategy, yet the process is cumbersome due to Amazon’s stringent anti-scraping measures and its multiplex page structure. In this tutorial, you’ll discover how to build a custom, high-speed Amazon data scraper from scratch and explore a dedicated ASIN scraper as a more convenient alternative.
What is Amazon ASIN?
The Amazon Standard Identification Number (ASIN) is an alphanumeric universal product code, composed of 10 digits. Each ASIN is unique to a product and helps streamline operations by facilitating product searches, monitoring availability, managing listings, and ensuring accurate stock levels across Amazon's marketplace. Books, on the other hand, don’t use ASINs; instead, they utilize the International Standard Book Number (ISBN).
ASIN example: B01B3SL1UA
ISBN-10 example: 1449355730
You can find the ASIN and ISBN codes in the product URLs, for example https://www.amazon.com/dp/B01B3SL1UA. Another method to locate ASINs is by inspecting the page's HTML and searching for elements containing the data-asin or data-csa-c-asin attribute.
Scraping Amazon ASINs
Since Amazon uses a complex anti-scraping system, a basic scraper won’t hold up even for small-scale public data collection operations. When Amazon suspects that a request might not be from a human, it prevents the page from loading and prompts a CAPTCHA challenge. In cases where Amazon is certain that the request is automated, it fully blocks access and returns a 503 error, displaying a page like this:

To successfully scrape Amazon products, you'll need to simulate real browser requests as closely as possible. In this section, you’ll learn how to do that using HTTP headers and rotating proxy servers to scrape Amazon ASIN data.
1. Install prerequisites
Begin by installing Python if you don’t already have it. Then, open your computer’s or IDE’s terminal and, in a new folder, activate a virtual environment with these two commands for macOS and Linux systems:
python3 -m venv .env
source .env/bin/activateIf you’re using Windows, the commands should look like this:
python -m venv .env
.env\scripts\activateNext, run the following pip command in your terminal to install the required libraries:
python -m pip install asyncio aiohttp aiofiles lxmlDepending on your Python setup, you may need to use the python3 keyword:
python3 -m pip install asyncio aiohttp aiofiles lxmlSince this tutorial aims to build a high-speed scraper, let’s leverage the power of asyncio and aiohttp to make asynchronous web requests to Amazon’s servers. For fast and efficient parsing of raw HTML data, lxml will handle the data extraction process. Finally, to ensure non-blocking file operations when saving scraped data, let’s use aiofiles.
2. Set up headers, search keywords, and proxies
Once you have everything installed, create a new Python file and import the libraries:
import asyncio, aiohttp, aiofiles, json, random
from lxml import htmlHTTP headers
While leveraging a headless browser to automatically handle HTTP headers is often the preferred method for web scraping, manually constructing your own header set can still be highly effective. To scrape Amazon, you can define a headers dictionary as shown below:
headers = {
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9",
"Accept-Encoding": "gzip, deflate, br",
"Accept-Language": "en-US,en;q=0.9",
"Connection": "keep-alive",
"Referer": "https://www.amazon.com/",
"Upgrade-Insecure-Requests": "1",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/129.0.0.0 Safari/537.36"
}Additionally, you may want to rotate different User-Agent strings to make your scraper more stealthy. This is because the more requests you send, the more likely Amazon is to detect and flag them even when using proxies.
Search keywords
Next, define the keywords list and add as many search results terms as you need:
keywords = ["computer mouse", "wireless headset", "keyboard", "laptop", "wired headset"]Proxy server settings
This step is optional if you’re scraping a few pages for a few keywords every now and then. For any larger and more frequent project, proxy servers are a must to spread your requests across different IP addresses and overcome Amazon’s anti-scraping measures.
You can use any proxy server you like. As a demonstration, let’s set up Oxylabs’ Residential Proxies that rotate with each request:
USERNAME = "your_username"
PASSWORD = "your_password"
PROXY_ADDRESS = "pr.oxylabs.io:7777"
proxy = f"https://customer-{USERNAME}-cc-US:{PASSWORD}@{PROXY_ADDRESS}"Note that for our Residential Proxies, you must attach the customer- string to your proxy username. Additionally, the -cc-US parameter sets the location of proxies to the United States.
3. Fetch Amazon search pages
Next, to index product catalog pages, define a fetch() coroutine that uses asyncio’s semaphore function to limit the concurrent connections. Before each request, set a random sleep time. These two settings will ensure your web requests resemble human-like browsing and help avoid the 503 error.
async def fetch(session, url, semaphore):
async with semaphore:
await asyncio.sleep(random.uniform(5, 10))
try:
async with session.get(
url,
headers=headers,
proxy=proxy
) as response:
print(f"Status code {response.status} for {url}")
if response.status == 200:
return await response.text()
except Exception as e:
print(f"Error fetching {url}: {e}")
return None4. Parse the data
To parse Amazon search result pages, first, you need to craft an XPath selector that finds the product data on the page. You can do it by targeting a <div> element that has the cel_widget_id attribute containing SEARCH text value:

Let’s define another async coroutine called parse() and create a product listing selector:
async def parse(page):
tree = html.fromstring(page)
products = tree.xpath("//div[contains(@cel_widget_id, 'SEARCH')]")
parsed_products = []Title
Additionally, you can extract product details, such as title, by targeting the <h2> element, which has a <span> element inside:

for product in products:
title = product.xpath(".//h2//span//text()")ASIN
To extract each Amazon product ASIN, select a <div> element with a data-csa-c-asin attribute that holds the ASIN as its value:

asin = product.xpath(".//div/@data-csa-c-asin")Link
If you need to get the Amazon page URL, attach the previously extracted product ASIN to this universal product link: https://www.amazon.com/gp/product/.
Finally, append all the extracted data to the parsed_products list:
parsed_products.append({
"title": title[0] if title else None,
"asin": asin[0] if asin else None,
"link": f"https://www.amazon.com/gp/product/{asin[0]}" if asin else None
})
return parsed_products5. Save data to JSON files
The next step is to define the save_to_file() asynchronous coroutine. It will store all the scraped data from every page related to a specific keyword into a neatly formatted JSON file:
async def save_to_file(keyword, asin_data):
async with aiofiles.open(f"{keyword.replace(' ', '_')}.json", "w") as f:
await f.write(json.dumps(asin_data, indent=4))6. Bring the code together
The following two coroutines will combine all of the code. Start with a gather_data() coroutine that generates five Amazon search URLs for every keyword. You can specify the number of pages by adjusting the range(1, 6) function.
async def gather_data(keyword, session, semaphore):
base_url = f"https://www.amazon.com/s?k={keyword.replace(' ', '+')}&page="
urls = [f"{base_url}{i}" for i in range(1, 6)]Next, fetch each URL in the urls list, run all tasks concurrently using asyncio.gather(), and then save the scraped data to a pages list:
fetch_tasks = [fetch(session, url, semaphore) for url in urls]
pages = await asyncio.gather(*fetch_tasks)For each page in the list, parse the HTML and add the results to the asin_data list. After that, you can save the ASIN data to a file:
asin_data = []
for page in pages:
if page:
products = await parse(page)
asin_data.extend(products)
await save_to_file(keyword, asin_data)Let’s create the final asynchronous coroutine, called main(), which sets asyncio.Semaphore to 5 concurrent requests, creates an aiohttp session, and concurrently executes the gather_data() coroutine for each keyword:
async def main():
semaphore = asyncio.Semaphore(5)
async with aiohttp.ClientSession() as session:
await asyncio.gather(*(gather_data(keyword, session, semaphore) for keyword in keywords))
if __name__ == "__main__":
asyncio.run(main())Full code for custom Amazon ASIN scraper
By now, you should have compiled the following custom ASIN scraper code:
import asyncio, aiohttp, aiofiles, json, random
from lxml import html
headers = {
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9",
"Accept-Encoding": "gzip, deflate, br",
"Accept-Language": "en-US,en;q=0.9",
"Connection": "keep-alive",
"Referer": "https://www.amazon.com/",
"Upgrade-Insecure-Requests": "1",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/129.0.0.0 Safari/537.36"
}
keywords = ["computer mouse", "wireless headset", "keyboard", "laptop", "wired headset"]
USERNAME = "your_username"
PASSWORD = "your_password"
PROXY_ADDRESS = "pr.oxylabs.io:7777"
proxy = f"https://customer-{USERNAME}-cc-US:{PASSWORD}@{PROXY_ADDRESS}"
async def fetch(session, url, semaphore):
async with semaphore:
await asyncio.sleep(random.uniform(5, 10))
try:
async with session.get(
url,
headers=headers,
proxy=proxy
) as response:
print(f"Status code {response.status} for {url}")
if response.status == 200:
return await response.text()
except Exception as e:
print(f"Error fetching {url}: {e}")
return None
async def parse(page):
tree = html.fromstring(page)
products = tree.xpath("//div[contains(@cel_widget_id, 'SEARCH')]")
parsed_products = []
for product in products:
title = product.xpath(".//h2//span//text()")
asin = product.xpath(".//div/@data-csa-c-asin")
parsed_products.append({
"title": title[0] if title else None,
"asin": asin[0] if asin else None,
"link": f"https://www.amazon.com/gp/product/{asin[0]}" if asin else None
})
return parsed_products
async def save_to_file(keyword, asin_data):
async with aiofiles.open(f"{keyword.replace(' ', '_')}.json", "w") as f:
await f.write(json.dumps(asin_data, indent=4))
async def gather_data(keyword, session, semaphore):
base_url = f"https://www.amazon.com/s?k={keyword.replace(' ', '+')}&page="
urls = [f"{base_url}{i}" for i in range(1, 6)]
fetch_tasks = [fetch(session, url, semaphore) for url in urls]
pages = await asyncio.gather(*fetch_tasks)
asin_data = []
for page in pages:
if page:
products = await parse(page)
asin_data.extend(products)
await save_to_file(keyword, asin_data)
async def main():
semaphore = asyncio.Semaphore(5)
async with aiohttp.ClientSession() as session:
await asyncio.gather(*(gather_data(keyword, session, semaphore) for keyword in keywords))
if __name__ == "__main__":
asyncio.run(main())Here’s a snippet of the scraped results for the keyword “computer mouse”:
[
{
"title": "Amazon Basics 2.4 Ghz Wireless Optical Computer Mouse with USB Nano Receiver, Black",
"asin": "B005EJH6Z4",
"link": "https://www.amazon.com/gp/product/B005EJH6Z4"
},
{
"title": "memzuoix 2.4G Portable Wireless Mouse, 1200 DPI Mobile Optical Cordless Mice with USB Receiver for Computer, Laptop, PC, Desktop, MacBook, 5 Buttons, Blue",
"asin": "B086MF8Q52",
"link": "https://www.amazon.com/gp/product/B086MF8Q52"
},
{
"more": "data"
},
{
"title": "Bluetooth Mouse,Rechargeable Wireless Mouse with Tri-Mode (BT 5.0/4.0+2.4GHz), Visible Battery Level, Ergonomic Design Silent Wireless Mouse for Laptop and PC(Yellow)",
"asin": "B0CDKFGV21",
"link": "https://www.amazon.com/gp/product/B0CDKFGV21"
},
{
"title": "ELECOM DEFT PRO Trackball Mouse, Wired, Wireless, Bluetooth 3 Types Connection, Ergonomic Design, 8-Button Function, Red Ball, Windows11, MacOS (M-DPT1MRXBK)",
"asin": "B07C9T4TTW",
"link": "https://www.amazon.com/gp/product/B07C9T4TTW"
}
]Be aware that executing this scraper for larger data-gathering tasks may still trigger a 503 error from Amazon, which will be displayed in your terminal's console as shown below:
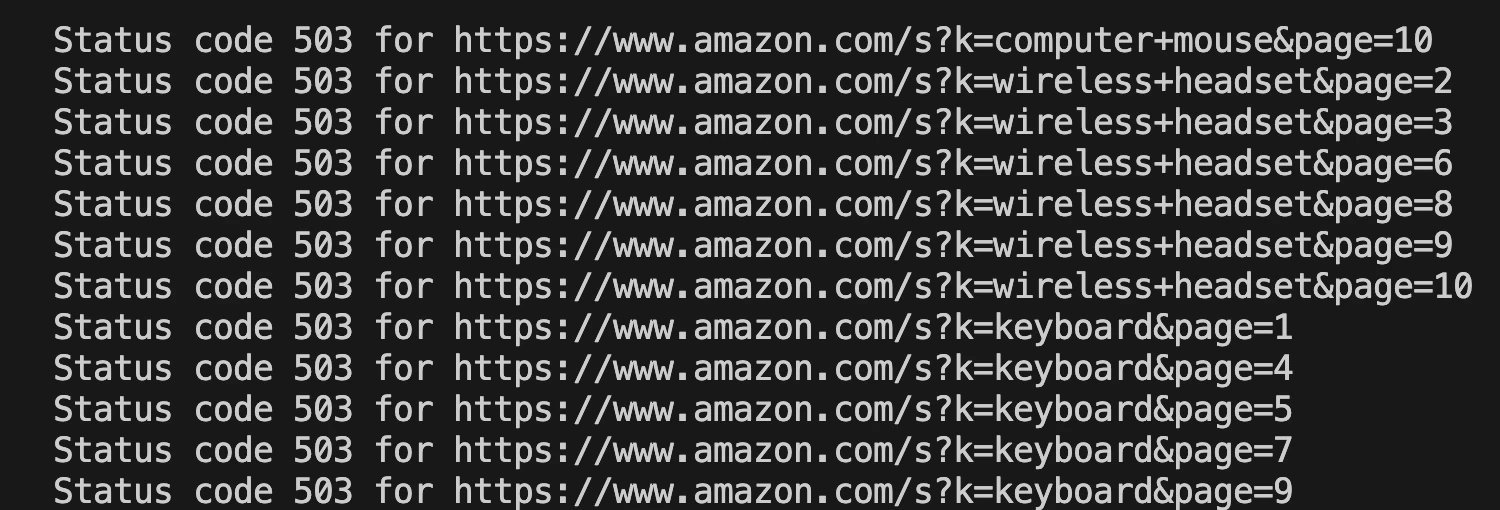
An easier solution: robust Amazon ASIN scraper
Larger scraping projects will require a more sophisticated approach to overcome Amazon’s anti-scraping measures. Proxy servers combined with headless browsers and a requests retry mechanism will greatly improve your scraping success rate.
A much simpler approach is to use a dedicated Amazon API, a part of Web Scraper API, which can handle enterprise-level data needs without blocks. It can also extract information from multiple product categories, allowing you to easily catalog data across the entire Amazon website.
Additionally, the amazon_search query now supports filtering and sorting of search results prior to scraping – for full details on usage and options, please refer to the documentation.
Try for free
Get a free trial to test Web Scraper API for your projects.
Up to 2K free results
No credit card is required
In this section, you’ll learn how to use Oxylabs Python SDK to scrape Amazon ASINs. Alternatively, you can utilize our Go SDK if you prefer Go over Python.
Check out our other article to learn more about SDKs and their benefits over raw APIs.
1. Install prerequisites
Let’s start by installing Oxylabs SDK, asyncio, and aiofiles libraries. The SDK will handle much of the API polling complexities, while asyncio and aiofiles will take care of asynchronous tasks. Create a new project folder and activate a virtual environment if you haven't already, then open your terminal and run this pip command:
python -m pip install oxylabs asyncio aiofilesBased on your installation, you might need to run the command with the python3 keyword:
python3 -m pip install oxylabs asyncio aiofiles 2. Set up the ASIN scraper
Begin by importing all the necessary libraries and the asynchronous client from the SDK:
import asyncio, aiofiles, json
from oxylabs import AsyncClientInitialize the client by assigning it to a variable and using the API user credentials that you’ve created in the dashboard. Then, add your keywords to a queries list:
c = AsyncClient("your_username", "your_password")
queries = ["computer mouse", "wireless headset", "keyboard", "laptop", "wired headset"]Next, define an asynchronous fetch() coroutine that accepts the necessary API parameters and a single search query (keyword). Specify the preferred Amazon delivery location using a ZIP code, and set the number of pages to scrape. Additionally, include the parse=True parameter to enable automatic result parsing. For better scraper control, add the poll_interval parameter to manage how often the SDK checks whether the API has finished scraping a page:
async def fetch(c, query):
response = await c.ecommerce.amazon.scrape_search(
f"{query}",
domain="com",
geo_location="10019",
pages=5,
parse=True,
timeout=240,
poll_interval=5
)
return response.raw3. Save results to JSON files
Start off by creating a save_to_file() coroutine and setting the filename to a query that the API used to search Amazon for:
async def save_to_file(response):
filename = response["results"][0]["content"]["query"].replace(" ", "_")Next, extract the data you need, including the product ASIN, from the parsed results. Here, you can utilize Python’s list comprehension logic to navigate through the nested structure of the response, iterating over results:
asin_data = [
{
"title": product.get("title"),
"asin": product.get("asin"),
"product_url": f"https://www.amazon.com{product.get('url').split('/ref')[0]}"
}
for result in response["results"]
for section in result["content"]["results"].values()
for product in section
]After that, save the extracted ASIN data to a JSON file:
async with aiofiles.open(f"{filename}.json", "w") as f:
await f.write(json.dumps(asin_data, indent=4))4. Set up the main() function
Finally, combine every coroutine under the main() function, which creates a list of tasks for each query, runs them asynchronously, and saves the results as each task completes:
async def main():
tasks = [fetch(c, query) for query in queries]
for task in asyncio.as_completed(tasks):
response = await task
await save_to_file(response)
if __name__ == "__main__":
asyncio.run(main())Full SDK code sample
Here’s the complete ASIN scraper code with AsynClient and queries list placed inside the main() function:
import asyncio, aiofiles, json
from oxylabs import AsyncClient
async def fetch(c, query):
response = await c.ecommerce.amazon.scrape_search(
f"{query}",
domain="com",
geo_location="10019",
pages=5,
parse=True,
timeout=240,
poll_interval=5
)
return response.raw
async def save_to_file(response):
filename = response["results"][0]["content"]["query"].replace(" ", "_")
asin_data = [
{
"title": product.get("title"),
"asin": product.get("asin"),
"product_url": f"https://www.amazon.com{product.get('url').split('/ref')[0]}"
}
for result in response["results"]
for section in result["content"]["results"].values()
for product in section
]
async with aiofiles.open(f"{filename}.json", "w") as f:
await f.write(json.dumps(asin_data, indent=4))
async def main():
c = AsyncClient("your_username", "your_password")
queries = ["computer mouse", "wireless headset", "keyboard", "laptop", "wired headset"]
tasks = [fetch(c, query) for query in queries]
for task in asyncio.as_completed(tasks):
response = await task
await save_to_file(response)
if __name__ == "__main__":
asyncio.run(main())Running the scraper will produce separate JSON files for each search query. Here’s a snippet of the extracted ASIN data for the “computer mouse” query:
[
{
"title": "Logitech MX Master 3S - Wireless Performance Mouse, Ergo, 8K DPI, Track on Glass, Quiet Clicks, USB-C, Bluetooth, Windows, Linux, Chrome - Graphite - With Free Adobe Creative Cloud Subscription",
"asin": "B09HM94VDS",
"product_url": "https://www.amazon.com/Logitech-MX-Master-3S-Graphite/dp/B09HM94VDS"
},
{
"title": "Apple Magic Mouse: Wireless, Bluetooth, Rechargeable. Works with Mac or iPad; Multi-Touch Surface - White",
"asin": "B09BRD98T4",
"product_url": "https://www.amazon.com/Apple-Magic-Mouse-Wireless-Rechargable/dp/B09BRD98T4"
},
{
"more": "data"
},
{
"title": "Logitech M585 Wireless Mouse, Graphite",
"asin": "B072M4YLN6",
"product_url": "https://www.amazon.com/Logitech-Wireless-Multi-Device-Cross-Computer-Graphite/dp/B072M4YLN6"
},
{
"title": "Corsair Katar Pro XT Ultra-Light Gaming Mouse- 18k DPI PixArt Optical Sensor- RGB Scroll Wheel Lighting- 6 Programmable Buttons- Lightweight Paracord Cable,Black",
"asin": "B08SHCKVTG",
"product_url": "https://www.amazon.com/Corsair-Katar-Ultra-Light-Gaming-Mouse/dp/B08SHCKVTG"
}
]Wrap up
Creating your own Amazon ASINs scraper is a relatively budget-friendly way that requires significant coding expertise and proxy servers if you want to collect ASIN data from Amazon without blocks.
A much more streamlined approach, especially for business intelligence efforts, is to use a dedicated scraper like Oxylabs’ Amazon Scraper API that’s designed to overcome blocks and return parsed data. You can use it to scrape Amazon ASIN data, Amazon best sellers, Amazon books, and other useful data for your projects.
Additionally, a single API purchase unlocks other e-commerce platforms, including Walmart and Best Buy, search engines like Google and Bing, and many other websites, making it a diverse web scraping tool for any public web data project.
About the author

Vytenis Kaubrė
Technical Content Researcher
Vytenis Kaubrė was a Technical Content Researcher at Oxylabs. Creative writing and a growing interest in technology fueled his work, where he researched and crafted technical content while honing his skills in Python. Off duty, he could often be found working on personal projects, learning about cybersecurity, or relaxing with a book.
All information on Oxylabs Blog is provided on an "as is" basis and for informational purposes only. We make no representation and disclaim all liability with respect to your use of any information contained on Oxylabs Blog or any third-party websites that may be linked therein. Before engaging in scraping activities of any kind you should consult your legal advisors and carefully read the particular website's terms of service or receive a scraping license.
Related articles

Cheerio vs. Puppeteer: Which Should You Use for Web Scraping?

Shinthiya Nowsain Promi
2026-06-23



List Crawling in Python: Tools, Tips, and Techniques

Danielė Virinaitė
2026-06-17
Try Amazon Scraper API
Choose Oxylabs' Amazon Scraper API to gather real-time e-commerce data hassle-free.

Get the latest news from data gathering world
Scale up your business with Oxylabs®
Proxies
Advanced proxy solutions
Data Collection
Datasets
Resources
Innovation hub
Try Amazon Scraper API
Choose Oxylabs' Amazon Scraper API to gather real-time e-commerce data hassle-free.