175M+ ethically sourced IPs built for the highest reliability.
High-speed, cost-effective proxies built for any scraping workload.
Premium static residential proxies from trusted ASNs for most difficult targets.
Dedicated IPs from premium ASNs for demanding scraping.

AI-powered proxy solution for optimized web scraping performance.

20M+ IP addresses from real mobile devices for precise targeting.

Free Chrome proxy manager extension that works with any proxy provider.

Free Android proxy manager app that works with any proxy provider.

Free community-driven tools to improve your web scraping projects.
Web Scraper API
All-in-one web data collection platform for every stage of web scraping.
Fast Search API
Ultra-fast organic search results scraper tailored for AI workflows.
Headless Browser
Advanced browser automation solution for AI agents and scraping.
AI Studio
A suite of AI-powered tools for various scraping projects.

Documentation
All features, parameters, and integration details, backed by code samples in every coding language.
Tutorials, samples, and guides.
Latest fixes and features.






![]() AI Summary:
AI Summary:
This article explains in detail what CAPTCHA is and how it works. CAPTCHA (Completely Automated Public Turing Test to Tell Computers and Humans Apart) presents tasks designed to distinguish human users from automated bots. These tests, ranging from distorted text to image recognition, prevent website abuse.
It would be hard to find a person who has never had to prove a computer they are a human. Solving weird puzzles with fire hydrants may seem like an odd way to prove you have consciousness. It will not seem that odd after reading this article. You will soon find out how CAPTCHAs work and that by solving them, you play an important role in training Artificial Intelligence. You will also find out how do reCAPTCHAs work.
For your convenience, we also have a video that covers this topic:

So, let's get into it.
What does CAPTCHA mean?
CAPTCHA is an acronym for Completely Automated Public Turing Test to Tell Computers and Humans Apart. Sometimes it is also called Human Interaction Proof (HIP). The CAPTCHA test is meant to differentiate humans from bots. A traditional CAPTCHA stretches and distorts letters and/or numbers and asks users to identify the text – something that may seem rather easy for a human but is challenging for a robot.
In 1950 Alan Turing, often called the father of modern computing, introduced the Turing Test. This assessment was designed to show whether machines could think or appear to think as humans. During the test, an interrogator asks two participants a series of questions. One participant is a human, while the other one is a machine. The interrogator does not know which is which and has to guess based solely on their answers. If the interrogator fails to identify the participants, the machine passes the test.
As the name suggests, traditional CAPTCHA is based on the Turing test.
How do CAPTCHAs work?
A CAPTCHA’s goal is to separate humans from bots. To achieve that, the CAPTCHA test presents different images to various users. The database of CAPTCHAs is massive in order to suggest as many different variations as possible. If the answer to the CAPTCHA code was hidden in the metadata of the image, or if the solution was always the same, it would take no time for a computer to solve it.
While CAPTCHAs are created to be solved only by humans, it does not mean that everyone can solve a CAPTCHA on the first try. Researchers say that humans should be able to solve around 80% of CAPTCHAs, and the success rate for machines should be 0.01%.
Most traditional CAPTCHA tests rely on vision, as computers are not as sophisticated as humans when it comes to processing visual information. Most people can pick out patterns quite quickly or make connections between different subjects. An ability to see previously known patterns where they do not appear is called pareidolia. For example, we can see familiar shapes in the clouds as our brains try to associate information with patterns.
For people with impaired vision, CAPTCHAs are presented in audio format. The audio normally has some background noise in order to prevent bots from solving these tests.

CAPTCHA tests are meant to tell humans and robots apart
Why are CAPTCHAs used?
CAPTCHAs are primarily used to protect web pages from malicious acts. Many websites do not want to be abused by bots and therefore ask users for CAPTCHA validation. However, sometimes CAPTCHAs stand in the way when people want to collect public data for research or business purposes.
Here are some examples of how CAPTCHAs are used:
If a free email platform does not use CAPTCHAs, someone may use them to send spam advertisements from many different email addresses. CAPTCHA helps to identify bots and stops them before they do any harm.
Ticket sellers also often use CAPTCHAs. Resellers sometimes employ bots to get a bunch of tickets to the most popular events mere seconds after their release. They buy out all the tickets and later sell them for a larger price. CAPTCHAs help stop these bots.
DDoS attacks (Distributed Denial-of-Service) are another common threat. Attackers aim to intentionally disrupt services by sending a large number of requests to one target. Websites introduce CAPTCHAs to avoid potential attacks that may stop their services.
On the other hand, CAPTCHAs may slow down work. For example, researchers have to go through vast amounts of public information, download documents, and collect data. CAPTCHAs interfere with their tasks and become a burden.
Types of CAPTCHAs
CAPTCHAs have three categories based on the type of content: text-based, picture-based, and sound-based.
Text CAPTCHAs
The most common type blends various explanations or articulations, letters, and digits.
The characters are displayed in odd and distorted styles and could have textured backgrounds, amplifying the difficulty of reading to non-humans.
Approaches to forming text CAPTCHAs include:
Gimpy – a group of distorted words.
EZ-Gimpy – similar to Gimpy but only a single word.
Gimpy-r – a random collection of disfigured letters.
Simard’s HIP – a random collection of disfigured letters and numbers overlaid with abstract interruptive figures.
All of the variations above may or may not include distorting backgrounds.
Image CAPTCHAs
Usually, a set of photographs of ordinary things in a square grid. The user must pick the images that feature the requested elements. Google often utilizes its Street View to ask to identify crosswalks, certain vehicle types, and other mundane objects. Most users can complete image CAPTCHAs very quickly. However, a bot would have to run an increasingly lengthy comparison algorithm to identify an object, interrupting its path to the target destination. Due to the more complex nature of imagery-based evaluation, image CAPTCHAs are a more preferred anti-bot measure compared to text CAPTCHAs.
Audio CAPTCHAs
Audio CAPTCHA is often utilized alongside text and picture-based CAPTCHAs. The audio features a voice recording spelling featured symbols paired with background noise. The noise serves as an obstruction, usually various technical sounds, such as static. In audio CAPTCHA, bots can’t distinguish featured symbols from background clutter.
What is reCAPTCHA?
ReCAPTCHA is a service from Google that performs the same function as a regular CAPTCHA. Many websites use this as a free web protection solution. You may have noticed reCAPTCHAs that only ask users to tick a box rather than solve a puzzle. These are called “noCAPTCHA reCAPTCHA”. After ticking the box, if the system is still not convinced, the user will be asked to prove they are a human.
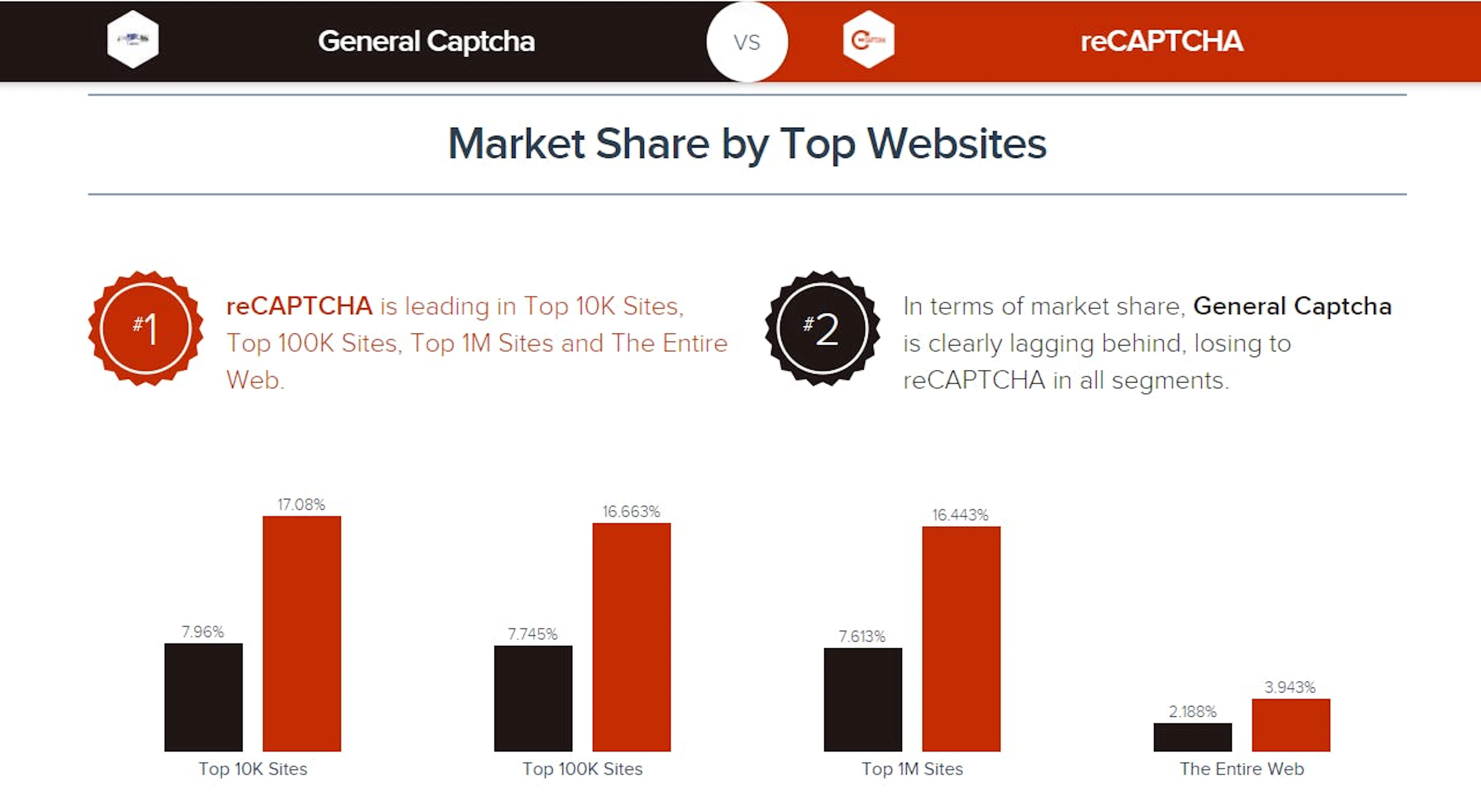
ReCAPTCHAs are more popular than any other CAPTCHA services
Source: www.similartech.com/compare/general-captcha-vs-recaptcha
How do reCAPTCHAs work?
First reCAPTCHAs were created by digitalizing books, using images of street names, taking text pieces from newspapers, and asking users to decrypt words or their combinations. While reading text on an image is not a difficult task for a human, it is challenging for a bot.
Computers are getting more and more sophisticated, but so are reCAPTCHAs. Over time, more types of reCAPTCHAs have been developed and now include image recognition, checkboxes, and general user behavior assessment that does not require any user interaction.
Different types of reCAPTCHA
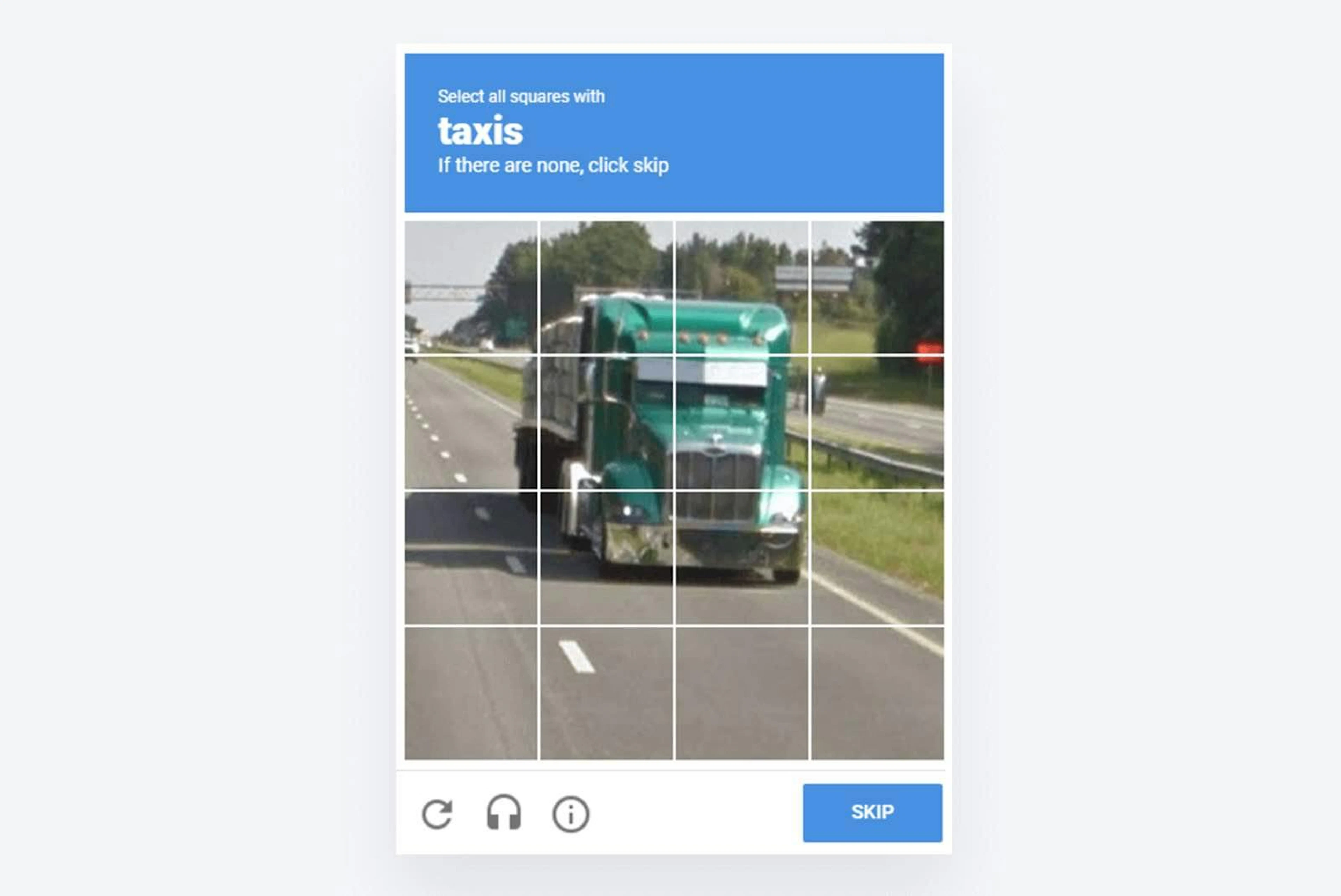
Image recognition
Image recognition reCAPTCHAs give a user nine or 16 square images. These images may be related or completely different. The user has to identify images that include (or do not include) a certain object. It can be street signs, fire hydrants, clouds, or anything else. How does the system know if the answer is correct? The response has to match the answers submitted by most of the other users who solved the same test.
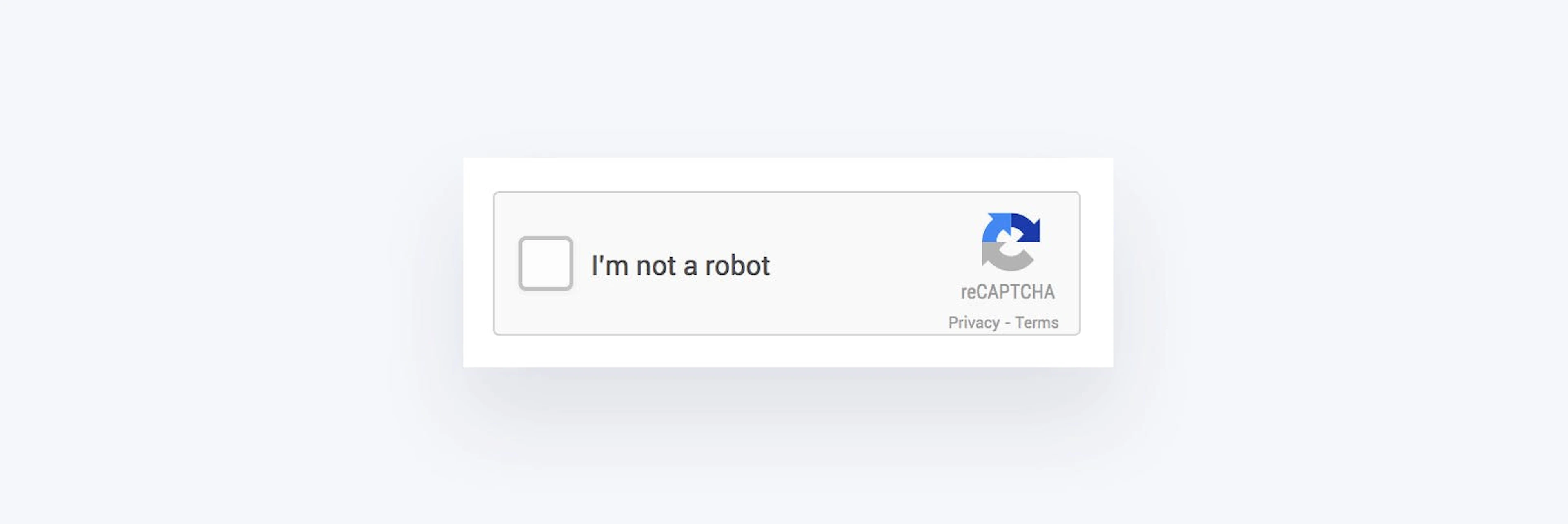
Single checkbox
How do checkbox CAPTCHAs work? Merely ticking a checkbox that says “I’m not a robot” is not the real test. The real test is what leads to the checkbox.
This test considers mouse movements as it comes closer to the checkbox. Human users are much less predictable than bots. Even the most direct mouse movement performed by a person is not straight, and bots are unable to replicate the same pattern. ReCAPTCHAs may also inspect HTTP cookies that the browser stores in the device.
As mentioned previously, sometimes the user may be presented with an additional challenge, if the test cannot determine whether the user is a human or a bot.
No interaction
The most recent edition of reCAPTCHA is able to determine whether the user is a human without any puzzles or checkboxes. The test takes into account the user’s behavior and history of interacting with websites. In most cases, the system can decide whether the user is a bot based on these factors. If this information is not enough, then the user will be challenged with one of the previously mentioned reCAPTCHAs.
reCAPTCHA v2 vs v3
Contrary to the seemingly obvious, reCAPTCHA v3 isn’t just a newer version of reCAPTCHA v2. In fact, the two solutions are quite different and fit different needs.
Adding a checkmark to a box titled “I am not a robot” is what defines reCAPTCHA v2. Most of the time, it’s the end of the test, while occasionally, a user will be asked to complete a further test to prove their authenticity.
You may be completely unaware of reCAPTCHA v3 as it works in the background using machine learning and advanced risk analysis. ReCAPTCHA v3 returns a score to a webmaster based on the user’s behavior. Depending on the score, you are deemed a human or a bot. The higher the score, the bigger the chance of being a human. The final choice of applying restrictions, testing further, or allowing the passage is left to a webmaster.
ReCAPTCHAs v2 and v3 can halt a sizable portion of bot traffic. However, they can’t stop advanced web scrapers or DDoS attacks. ReCAPTCHAs shouldn't be employed as a main bot handling solution due to the following reasons:
Diminished user experience → increased bounce rate → lesser revenue.
High possibility of false positives and false negatives.
Easily managed using CAPTCHA farms and advanced bots.
No tangible feedback regarding user passes and failures.
The use of v3 and v2 is entirely situational. ReCAPTCHA v2 suits smaller sites that would like to limit regular bot traffic. You can add v2 to a website with only 2 lines of HTML code.
If you have a larger site with heavier traffic and dedicated personnel to upkeep it, consider reCAPTCHA v3. While reCAPTCHA v3 is a more user-friendly solution, it’s an extra burden to webmasters.
What triggers CAPTCHAs and reCAPTCHAs?
If the system suspects that the user is a bot, then a CAPTCHA shows up. It can be triggered by, for example, sending too many requests to the same target.
ReCAPTCHAs seem to be more sophisticated. While it is not exactly clear what triggers reCAPTCHAs, there are some potential factors:
Mouse movements
Tracking cookies
Browsing history
CAPTCHAs and Artificial Intelligence
CAPTCHAs and reCAPTCHAs are a perfect examples of Artificial Intelligence (AI) training. As mentioned earlier, when the system asks, for example, to click on every kitten on the images, it decides whether the answer is correct based on other users’ answers. This information also feeds AI and helps computers get better at recognizing images.
Image recognition is challenging for computers. For example, unlike the human eye, robots cannot make the same connections when a picture is taken from different angles. But with most recent technologies, computers are getting more sophisticated, and machine learning makes robots smarter day by day.
If you are wondering how machine learning works, this is an entertaining and informative video:

Can CAPTCHA be handled?
Handling CAPTCHAs means that these tests can be improved, and identifying weak points is the first step towards creating even better solutions. Whenever a bot solves a CAPTCHA, it is a step toward creating better tests. However, handling CAPTCHAs is not an easy task.
Losing access or getting CAPTCHAs are some of the most common challenges while web scraping. These challenges can interrupt large-scale public data-gathering operations. Some companies have already found solutions for managing CAPTCHAs. For example, Web Scraper API helps to deliver requested data without any IP restrictions or CAPTCHAs.
Another common way is to use free headless browsers that make your web scraping requests emulate browser behavior. Check out our post on Selenium web scraping, scrapy Playwright tutorial, and Puppeteer tutorial.
Conclusion
CAPTCHAs are used to protect websites from spam and abuse. The goal of a CAPTCHA is to determine human users from bots by giving them a test that should only be solved by humans. The idea of CAPTCHA is based on the Turing Test.
ReCAPTCHAs is a CAPTCHA service provided by Google. There are different types of reCAPTCHA tests, and some of them do not even require any human interaction. It is not exactly clear what triggers reCAPTCHAs, but some of the factors include cookie tracking, browser history, and interaction with a website in real time.
Managing CAPTCHAs for computers is a hard task, as their primary task is to be unsolvable for bots. However, some solutions, such as Web Scraper API, support web scraping without any CAPTCHAs or IP restrictions.
People also ask
Can proxies handle CAPTCHA?
In most cases, self-managed proxies are not capable of handling CAPTCHA. However, more advanced proxy solutions, such as Web Unblocker and CAPTCHA proxies, can handle CAPTCHA.
About the author

Adelina Kiskyte
Former Senior Content Manager
Adelina Kiskyte is a former Senior Content Manager at Oxylabs. She constantly follows tech news and loves trying out new apps, even the most useless. When Adelina is not glued to her phone, she also enjoys reading self-motivation books and biographies of tech-inspired innovators. Who knows, maybe one day she will create a life-changing app of her own!
All information on Oxylabs Blog is provided on an "as is" basis and for informational purposes only. We make no representation and disclaim all liability with respect to your use of any information contained on Oxylabs Blog or any third-party websites that may be linked therein. Before engaging in scraping activities of any kind you should consult your legal advisors and carefully read the particular website's terms of service or receive a scraping license.
Related articles

List Crawling in Python: Tools, Tips, and Techniques

Danielė Virinaitė
2026-06-17

Top 7 Web Price Scraping Software and Tools for 2026

Shinthiya Nowsain Promi
2026-06-11

Web Scraping Best Practices: Complete 2026 Guide

Dovydas Vėsa
2026-06-01
Web Scraper API for CAPTCHA-free scraping
Collect web data at scale from any target while successfully avoiding CAPTCHA.

Get the latest news from data gathering world
Scale up your business with Oxylabs®
Proxies
Advanced proxy solutions
Data Collection
Datasets
Resources
Innovation hub
Web Scraper API for CAPTCHA-free scraping
Collect web data at scale from any target while successfully avoiding CAPTCHA.