175M+ ethically sourced IPs built for the highest reliability.
High-speed, cost-effective proxies built for any scraping workload.
Premium static residential proxies from trusted ASNs for most difficult targets.
Dedicated IPs from premium ASNs for demanding scraping.

AI-powered proxy solution for optimized web scraping performance.

20M+ IP addresses from real mobile devices for precise targeting.

Free Chrome proxy manager extension that works with any proxy provider.

Free Android proxy manager app that works with any proxy provider.

Free community-driven tools to improve your web scraping projects.
Web Scraper API
All-in-one web data collection platform for every stage of web scraping.
Fast Search API
Ultra-fast organic search results scraper tailored for AI workflows.
Headless Browser
Advanced browser automation solution for AI agents and scraping.
AI Studio
A suite of AI-powered tools for various scraping projects.

Documentation
All features, parameters, and integration details, backed by code samples in every coding language.
Tutorials, samples, and guides.
Latest fixes and features.





Guide to Using Google Sheets for Basic Web Scraping



Vytenis Kaubrė
Last updated by Dovydas Vėsa
2025-07-18
10 min read
![]() AI Summary:
AI Summary:
A practical guide to no-code web scraping using Google Sheets' built-in import functions. Covers IMPORTXML for HTML and XML content with XPath queries, IMPORTHTML for tables and lists, IMPORTFEED for RSS and Atom feeds, and IMPORTDATA for CSV files. Also includes an XPath primer, step-by-step scraping examples, data freshness behaviour, advantages and limitations, and common errors to watch out for.
Google Sheets web scraping can be an effective technique. If you're new to web scraping, you can check out our detailed guide on what is web scraping and how to scrape a website. While most ways of web scraping require you to write code, web scraping with Google Sheets requires no coding or add-ons. All you need to do is use a built-in function of Google Sheets. Thus, it acts as a basic web scraper.
This guide will show you how to extract data from website to Google Sheets automatically using pre-made functions with practical examples. For your convenience, we also prepared this tutorial in a video format:

Importing XML and HTML
IMPORTXML is a function that imports data from various structured data types. You can use it not only to scrape XML documents but also HTML documents. Other structured data types that the IMPORTXML formula supports are Comma Separated Values (CSV), Tab Separated Values (TSV), Really Simple Syndication (RSS), and Atom XML feeds.
How IMPORTXML works
The IMPORTXML function needs two parameters – the URL of the page to examine and the XPath query.
If you would like to see the official documentation, click here. However, this article will explain IMPORTXML and a few other related functions in detail. Let's look at some of the examples to help us understand the IMPORTXML function a little better.
To extract the title element from the https://quotes.toscrape.com/ web page, the formula would be as follows:
=IMPORTXML("https://quotes.toscrape.com/","//title")As evident here, the first parameter is the website URL, and the second parameter is the XPath query. Also, note that you would need to enclose both parameters in quotation marks unless these are a reference to another cell.
You can create an XPath query directly from the browser. Open the webpage in your preferred browser, right-click the element you want to extract, and select Inspect. You’ll see the developer tools open with the HTML element highlighted. Right-click the HTML of the highlighted element, then select Copy and choose Copy XPath. This action copies the XPath and saves that element to your clipboard.

Copying an element's XPath
Let's look at one more example. If you want to extract the first quote from the webpage, the formula will be as follows:
=IMPORTXML("https://quotes.toscrape.com/","(//*[@class='text']/text())[1]")If this XPath query seems like something you aren’t comfortable with, we recommend reading the XPath section on our blog to learn more about writing XPath queries.
Alternatively, you can enter the URL in cells. For example, if you enter the URL in cell A1 and XPath in cell A2, your formula will refer to these cells as follows:
=IMPORTXML(A1,A2)Quick XPath introduction
The IMPORTXML works only with XPath. This section gives you a quick overview of XPath, which is enough to start using the IMPORTXML formula.
If you have an HTML where the body tag directly contains h1, you can use the following XPath to locate this h1 element:
/html/body/h1The forward slash at the beginning of an XPath expression represents the document. We can read the above XPath as follows:
Begin with the root of the document
Find an html tag in the document
Find a body tag in the html tag
Find an h1 tag
If you want to match all the h1 tags, you can make this Xpath much shorter as follows:
//h1Two forward slashes mean to match all descendants. This XPath expression will match all the h1 elements found anywhere in the document. Next, to extract the text contained in the h1 element, you can use the text() function:
//h1/text()It’s also possible to extract the value of any attribute. For example, if you want to extract the value of the class attribute of h1 tags, the XPath will be as follows:
//h1/@classAs you can see, to work with attributes, you have to prefix the @ character. Learning how to extract elements by class in XPath will help you to efficiently scrape the data that you need.
Let's take a look at filtering. For example, what if you wanted to get only the h1 elements with a class named pdp_orange applied? The following XPath will do just that:
//h1[@class="pdp_orange"]We learn from this expression that we need to use square brackets.
You can also take a look at how to use XPath to select elements based on their text content.
How to extract data from a website to Google Sheets
Follow the steps below to extract data from a website to Google Sheets without the use of add-ons:
1. First, let’s find the XPath in Chrome to select elements. Load the site in Chrome, Right-click the element, and select Inspect.
You’ll see the developer tools window opening with the Elements panel. As you might know, the Developer Tools is crucial to building any web scraper. Next, if you want to select only one element, right-click the HTML element, select Copy, and click Copy XPath.
In this example, we’ll work with https://books.toscrape.com/, aiming to get all the book titles. These requirements mean that we need to write a custom XPath that looks like this:
//h3/a/@titlePress Ctrl+F or Command+F when the Elements tab of the developer toolbar is open and paste this XPath. You’ll see a preview of the 20 items selected.

Pasting the XPath
Looking at the HTML markup, you’ll see that the book name is incomplete for many books within the element text. That's why we’re extracting the title attribute values containing the complete book title.
2. Navigate to Google Sheets and create a new sheet. This step requires you to log in to your Google account if you haven't done so already. Depending on how many sheets you have created in the past, you would see a New sheet tile on the top or a floating New Sheet button in the lower right corner.
Tip: Open sheets.new to directly create a new sheet.

Creating a new sheet
3. Enter the URL of the webpage and the XPath in two cells. Entering these values in the cells enables us to create a formula that’s easy to maintain.
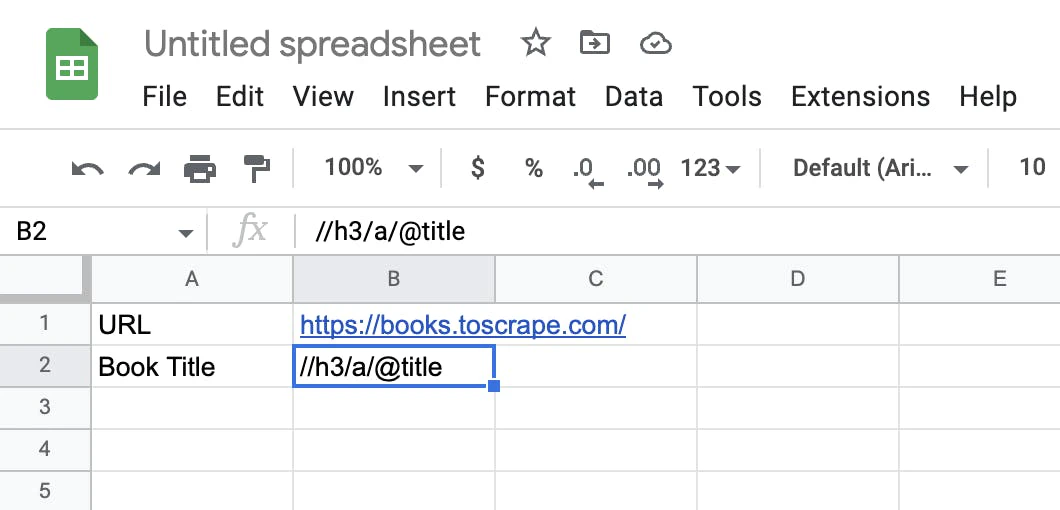
Entering the URL and the XPath
4. Finally, we can start extracting website data with Google Sheets. In a new cell, for example, A4, enter the following formula:
=IMPORTXML(B1,B2)This formula effectively calls the function below:
=IMPORTXML("https://books.toscrape.com/","//h3/a/@title")Press ENTER to execute this function. It’ll take a moment and get all the twenty book titles.

The scraped book titles
You’ll see that one single formula extracts all twenty book titles efficiently. In order to extract the book prices, the first step is to create the XPath for prices. This XPath would be as follows:
//*[@class="price_color"]/text()Enter this XPath in a cell, let's say, B3. After that, enter the following formula in cell B4:
=IMPORTXML(B1, B3)You’ll see that now you have the book prices fetched.

The scraped book prices
Other related functions
Apart from IMPORTXML, you can employ a few more functions to make Google Sheets get data from website elements in different formats. Again, there is no need for add-ons, as these are available natively.
These functions are as follows:
IMPORTHTML
IMPORTFEED
IMPORTDATA
You can use the IMPORTHTML function to extract data from tables and lists. IMPORTDATA function can scrape data when your target website URL contains data in a CSV or TSV format. IMPORTFEED function can import RSS or Atom feeds. We’ll detail these functions shortly.
Import a table from a website to Google Sheets
If your target page contains data in a table, the IMPORTHTML function is perfect for you. This function expects three parameters:
URL – This is the page URL you want to scrape. This URL should be complete, including the http:// part.
Either "table" or "list" – IMPORTHTML formula can get data from lists too. If you want to extract a table, set this value to "table".
The INDEX of the table or the list you want to scrape.
Note the following about the INDEX formula:
a. The INDEX begins from 1
b. The INDEX for tables and lists is separate. Therefore, the number 1 could simultaneously mean the first table and the first list. What you get depends on the second parameter.
For example, let’s look at https://en.wikipedia.org/wiki/List_of_highest-grossing_films. This page contains the list in a table.
So, start by creating a new sheet, and enter this URL in a cell. For example, we have entered the URL in cell B1.
Next, enter the following formula in cell A3:
=IMPORTHTML(B1,"table",1)This formula gets the first table from the page. As a result, you’ll see the whole table fetched from the web page into the Google spreadsheet.

The scraped table
It’s also possible to extract only a single column. For this, you can use another Google Sheets web scraping function – INDEX. The INDEX function can extract any row or column from a table. It requires one mandatory and two optional parameters:
The reference of the table
Row – Optional
Column – Optional
For example, if we wanted only the movie titles, which are in column number 3, our formula would be as shown below:
=INDEX(IMPORTHTML("https://en.wikipedia.org/wiki/List_of_highest-grossing_films","table",1),,3)We have skipped the optional parameter “row” as we want to keep all the rows. Let’s move on to another helpful function – IMPORTFEED.
Import data from XML feeds to Google Sheets
RSS and Atom are two standard XML formats to generate website feeds. Even though scraping data from them using the IMPORTXML function is possible, that would still require writing the XPath queries. Thus, a specialized function is more suitable. There are a few third-party add-ons, but we don’t need any of them.
This is where the IMPORTFEED function comes in. It only needs one argument line, which is the URL of the feed. If you send the feed URL, this function will fetch the data and present it to you in Google Sheets. Let's take the example of the New York Times Technology feeds to see this function in action.
1. Create a new sheet and enter the URL of the feed in cell B1:
https://rss.nytimes.com/services/xml/rss/nyt/Technology.xml2. Now, in cell A2, enter the following formula:
=IMPORTFEED(B1)
Imported data from a website feed
3. Press Enter, and you’ll see twenty feed items imported into your Google Sheets document.
Customizing data imported by IMPORTFEED
The IMPORTFEED function has the following optional parameters:
Query – You can use this to specify which information you want to import.
Headers – As you can see from the above image, there are no headers in the imported data. If you want to see column headers, then set this parameter to TRUE.
num_items – You can also control how many items are fetched. If you want only five items to be imported, set this parameter to 5.
Let’s update the function call to the following:
=IMPORTFEED(B1,,TRUE,5)
Imported data with headers
Note that we have left a blank space for the query. This function call brings all the columns. However, now you’ll see only five items fetched along with column headers.
If you want specific information from the feed, there is a list of possible items that you can send to the second parameter, which we have not used so far. If you want only the information about the feed, enter the following formula:
=IMPORTFEED(B1,"feed")This formula returns a single row with the feed information. In this particular example, the output is as follows:
NYT > Technology https://www.nytimes.com/section/technology
You can narrow down this information further by specifying which piece of information you want from the feed information. For example, if you only need the title, modify the formula as follows:
=IMPORTFEED(B1,"feed title")Other options are feed description, feed author, and feed URL. You’ll see an error if any of the information is not found in the feed.

An error message showing that the information is not found in the feed
If you want to see a specific column, you can use the query as "items <type>". For example, if you want to get only the titles, enter the following formula:
=IMPORTFEED(B1,"items title")
The scraped titles
Note that you can't specify more than one column in such a manner. If you want to get two columns, you need to make a separate function call.
Importing Data from CSV to Google Sheets
If you have a website URL that contains a CSV file, you can use the IMPORTDATA function to get the data. For example, create a new sheet and enter the following URL in the cell B1:
https://www2.census.gov/programs-surveys/decennial/2020/data/apportionment/apportionment.csvIn the cell A2, enter the following formula:
=IMPORTDATA(B1)
Extracted data from a CSV file
Does the data stay fresh?
If you keep your Google sheet open, these functions check for updated data every hour. Data will also be refreshed if you delete and add the same cell. Note that data will not be refreshed if you refresh your sheet or if you copy-paste a cell with these functions.
Advantages and drawbacks of import functions
There are a few key advantages of using the import functions in Google Sheets:
The most significant advantage of all these functions is that you don’t need to learn to code. In addition, you don’t need any add-on to create a Google Sheet web scraper.
The extracted data remains reasonably fresh automatically.
You can use somewhat dynamic imports, as these formulas can be used as regular Google Sheets formulas, which means these can reference other cells.
There are plenty of drawbacks as well:
This method is not scalable. If you want to import millions of records, Google Sheets is not what you need.
There is no option to customize the headers. The headers sent are standard Google headers, including the user-agent, which means many websites would block it.
On top of it, there is no option to send a POST request. Even a slightly complex web scraping task will not work.
Finally, you have no option to use a proxy. For anything advanced, you would have to rely on either programming or a professional solution such as Large-scale Web Data Acquisition.
Common Errors
The following are some of the common errors you may face while creating a Google spreadsheet for web scraping:
Error: Array result was not expanded
The most common error is an #REF error. If you move your mouse over the error, you’ll see a message similar to the following:
Array result was not expanded because it would overwrite data in A36.
This error means that you need to make room by adding more cells for the results.
Error: Result too large
If you see this error, it means that the results are too big to be handled by Google Sheets. This error happens when using the IMPORTXML function. The solution is to update the XPath query so that a smaller amount of data is returned.
Errors related to volatile functions
When you see the following error:
Error: This function is not allowed to reference a cell with NOW(), RAND(), or RANDBETWEEN()
It means that you’re trying to reference one of the volatile functions, such as NOW, RAND, or RANDBETWEEN, in one of the parameters. These references may be indirect or direct.
The import functions can’t use most of the volatile functions. The solution is to copy and paste values and then reference the values.
Conclusion
Google Sheets is a great way to begin web scraping without writing any code. This way, you’re colyou can employ a few more functions to make Google Sheets get data from website elements in different formats. However, it has limited scope, and you would need to create or use a web scraper for any advanced web scraping. For ease of use, you can also find this guide on GitHub.
If you would like to learn more about web scraping using different programming languages, take a look at our blog posts, such as Web Scraping with JavaScript, Web Scraping with Java, Web Scraping with C#, Python Web Scraping Tutorial, and many more.
Frequently asked questions
Can Google Sheets take data from a website?
Yes, Google Sheets can take data from a website using its built-in IMPORTXML, IMPORTHTML, IMPORTFEED, or IMPORTDATA functions. They allow you to pull data from website to Google Sheets without needing to write any code or use third-party add-ons.
How do I get data from a URL in Google Sheets?
How do I pull a table from a website into Google Sheets?
About the author
Vytenis Kaubrė
Technical Content Researcher
Vytenis Kaubrė was a Technical Content Researcher at Oxylabs. Creative writing and a growing interest in technology fueled his work, where he researched and crafted technical content while honing his skills in Python. Off duty, he could often be found working on personal projects, learning about cybersecurity, or relaxing with a book.
All information on Oxylabs Blog is provided on an "as is" basis and for informational purposes only. We make no representation and disclaim all liability with respect to your use of any information contained on Oxylabs Blog or any third-party websites that may be linked therein. Before engaging in scraping activities of any kind you should consult your legal advisors and carefully read the particular website's terms of service or receive a scraping license.
Related articles

10 Best No-Code Web Scrapers for Web Data Extraction in 2026

Enrika Pavlovskytė
2026-04-22

Guide to Extracting Website Data by Using Excel VBA

Yelyzaveta Hayrapetyan
2026-01-09

Guide to Scraping Data from Websites to Excel with Web Query

Iveta Liupševičė
2024-04-05
High-quality proxy servers
Forget about IP blocks and CAPTCHAs with 175M+ premium proxies located in 195 countries
Effortless data gathering
Extract data even from the most complex websites without hassle by using Web Scraper API.

Get the latest news from data gathering world
Scale up your business with Oxylabs®
Proxies
Advanced proxy solutions
Data Collection
Datasets
Resources
Innovation hub
High-quality proxy servers
Forget about IP blocks and CAPTCHAs with 175M+ premium proxies located in 195 countries
Effortless data gathering
Extract data even from the most complex websites without hassle by using Web Scraper API.