175M+ ethically sourced IPs built for the highest reliability.
High-speed, cost-effective proxies built for any scraping workload.
Premium static residential proxies from trusted ASNs for most difficult targets.
Dedicated IPs from premium ASNs for demanding scraping.

AI-powered proxy solution for optimized web scraping performance.

20M+ IP addresses from real mobile devices for precise targeting.

Free Chrome proxy manager extension that works with any proxy provider.

Free Android proxy manager app that works with any proxy provider.

Free community-driven tools to improve your web scraping projects.
Web Scraper API
All-in-one web data collection platform for every stage of web scraping.
Fast Search API
Ultra-fast organic search results scraper tailored for AI workflows.
Headless Browser
Advanced browser automation solution for AI agents and scraping.
AI Studio
A suite of AI-powered tools for various scraping projects.

Documentation
All features, parameters, and integration details, backed by code samples in every coding language.
Tutorials, samples, and guides.
Latest fixes and features.







![]() AI Summary:
AI Summary:
This article guides readers through web scraping using Java with two popular libraries, JSoup and HtmlUnit. It covers how to set up a project, manage dependencies with Maven, connect to web pages, and extract data using CSS selectors or XPath.
Determining the best programming language for web scraping tasks may feel daunting, as there are many options. Some of the most popular languages used for web scraping are Python, JavaScript with Node.js, PHP, Java, and C#. Each language has its strengths and weaknesses, making the choice less straightforward.
This article focuses on web scraping with Java and shows how to build a Java web scraper that extracts data from an HTML page or fully rendered web pages, covering both static and dynamic content.
Java web scraping tools and libraries
There are two most commonly used libraries for web scraping with Java – JSoup and HtmlUnit.
JSoup is a powerful library that can handle malformed HTML effectively. The name of this library comes from the phrase “tag soup”, which refers to the malformed HTML document.
HtmlUnit is a GUI-less, or headless, browser for Java Programs. It can emulate the key aspects of a browser, such as finding specific elements by class from the web page, clicking those elements, etc. As the name of this library suggests, it’s commonly used for unit testing. It’s a way to simulate a browser for testing purposes.
HtmlUnit can also be used for web scraping. The good thing is that with just one line, the JavaScript and CSS can be turned off. It’s helpful in web scraping as JavaScript and CSS aren’t required most of the time. In the later sections, we’ll examine both libraries and create web scrapers.
Prerequisite for web scraping in Java
This tutorial on web scraping with Java assumes you’re already comfortable with the basics of the Java programming language.
To manage packages, Java projects typically use build tools like Maven or Gradle. These tools help you add external libraries (such as JSoup or Selenium) to your Java project without having to download and manage them manually. In this tutorial, we’ll be using Maven, but most concepts apply if you prefer Gradle.
It also helps to have a general understanding of how websites are structured. Basic knowledge of HTML and how to select elements, XPath or CSS selectors, will make things much easier. Keep in mind that not all libraries support XPath, so CSS selectors are often the safer choice.
Quick overview of CSS Selectors
Before we proceed with this Java web scraping tutorial, it will be a good idea to review the CSS selectors:
#firstname – selects any element where id equals “firstname”
.blue – selects any element where class contains “blue”
p – selects all <p> tags
div#firstname – select div elements where id equals “firstname”
p.link.new – Note that there is no space here. This selects <p class="link new">
p.link .new – Note the space here. Selects any element with class “new”, which are inside <p class="link">
Getting started
Before creating a Java web scraper, you must meet the following requirements:
Java LTS 8+: You need to install the latest version of Java LTS (Long-Term Support). At the time of writing, Java 20.0.2 is the latest version. You can download the latest version from here.
Maven: It’s a build automation tool. You need this tool for dependency management of your web scraping project. You can get Maven from here.
Java IDE: You can use any IDE for the development of your project. Just make sure that it supports Maven dependencies. For this tutorial, we’re using IntelliJ IDEA.
After installing, you can verify your Java and Maven versions using the following commands:
java -version
mvn -v
Now, let’s have a look at the target website for this guide. It’s the Jsoup library Wikipedia page, which looks like this:

You’ll extract the specific content from it. There are various libraries you can use for web scraping with Java, so let’s review the libraries that we’ll use for this tutorial.
Web scraping with Java using JSoup
JSoup is perhaps the most commonly used Java library for web scraping with Java. We’ll examine this library to create a Java website scraper.
Broadly, there are four steps involved in web scraping using Java.
Step 1. Create your project
The first step is to create a new project in your IDE. Provide the name of your project. Select your build system as Maven and create the project.

Wait for the project to be initialized. You’ll have a Java file and a pom.xml file in the project directory.

The `pom.xml` file is used for dependencies management. We’ll add the dependencies here.
Step 2. Getting JSoup library
The next step of web scraping with Java is to get the Java libraries. Maven can help here.
In the pom.xml (Project Object Model) file, add a new section for dependencies and a dependency for JSoup. The pom.xml file would look something like this:
<dependencies>
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.15.3</version>
</dependency>
</dependencies>With this, you’re ready to create a Java scraper.
Step 3. Fetching and parsing the HTML
The next step of web scraping with Java is to get the HTML from the target URL and parse it into a Java object. Let’s begin with the imports:
import org.jsoup.Connection;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;Note that it isn’t a good practice to import everything with a wildcard – import org.jsoup.*. Always import precisely what you need. The above imports are what we’re going to use in this Java web scraping tutorial.
JSoup provides the connect function. This function takes the URL and returns a Document. Here’s how the function can be used:
Document doc = Jsoup.connect(url).get();The connect() method connects to the target website, and the get() method helps to get the HTML of that web page and save it in the Document object. Remember that if the connection isn’t established successfully, the connect() method throws an IOException. So, it’s advised to handle that exception while using this function.
try {
// fetching the target website
Document doc = Jsoup
.connect("https://en.wikipedia.org/wiki/Jsoup").get();
}
catch(IOException e)
{
throw new RuntimeException(e);
}Remember that many websites automatically reject requests that lack a specific set of HTTP headers. This is one of the most fundamental anti-scraping techniques; thus, by manually setting these HTTP headers, you can avoid interruptions.
The User-Agent header is typically the most important one to set. The server may identify the program, operating system, and vendor from which the HTTP request originated with the help of this string.
try {
// fetching the target website
Document doc = Jsoup
.connect("https://en.wikipedia.org/wiki/Jsoup")
.userAgent("Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.0.0 Safari/537.36")
.header("Accept-Language", "*")
.get();
}
catch(IOException e)
{
throw new RuntimeException(e);
}Step 4. Querying HTML
The most crucial step of any Java web scraper building process is to query the HTML Document object for the desired data. This is the point where you’ll be spending most of your time writing the web scraper in Java.
JSoup supports many ways to extract the desired elements. There are many methods, such as getElementByID, getElementsByTag, etc., that make it easier to query the DOM.
Here is an example of navigating to the JSoup page on Wikipedia. Right-click the heading and select Inspect, thus opening the developer tool with the heading selected.
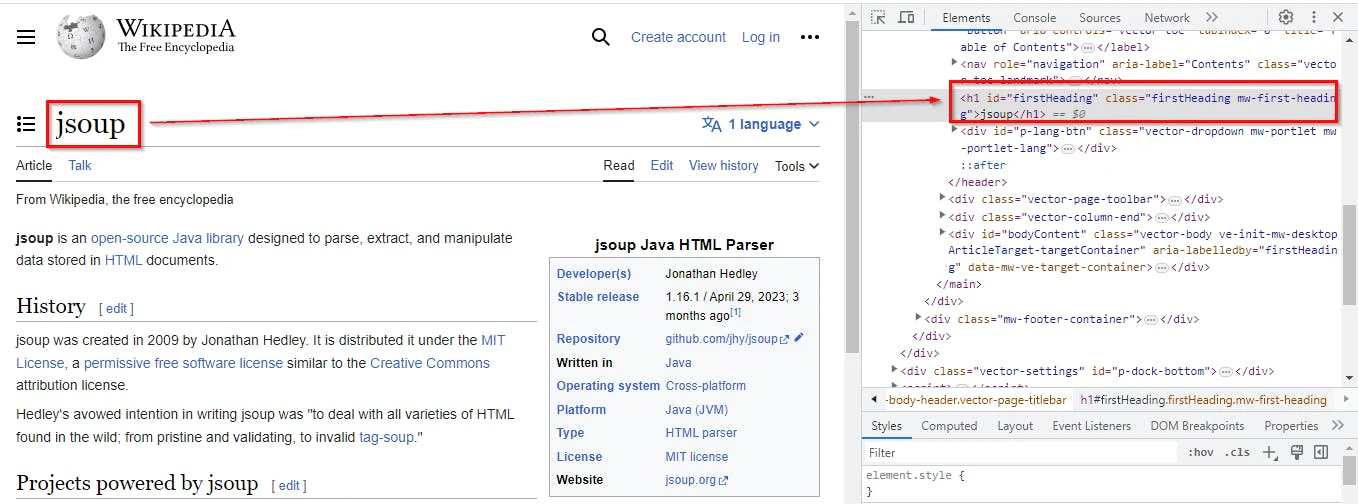
HTML Element with a unique class
In this case, either getElementByID or getElementsByClass can be used. One important point to note here is that getElementById (note the singular Element) returns one Element object, whereas getElementsByClass (note plural Elements) returns an Array list of Element objects.
Conveniently, this library has a class Elements that extends ArrayList<Element>. This makes code cleaner and provides more functionality.
In the code example below, the first() method can be used to get the first element from the ArrayList. After getting the reference of the element, the text() method can be called to get the text.
Element firstHeading = doc.getElementsByClass("firstHeading").first();
System.out.println(firstHeading.text());These functions are good; however, they're specific to JSoup. For most cases, the select function can be a better choice. The only case when select functions won't work is when you need to traverse the document. In these cases, you may want to use parent(), children(), and child(). For a complete list of all the available methods, visit this page.
The following code demonstrates how to use the selectFirst() method, which returns the first match.
Element firstHeading= doc.selectFirst(".firstHeading");
System.out.println(firstHeading.text());In this example, selectFirst() method was used. If multiple elements need to be selected, you can use the select() method. This will take the CSS selector as a parameter and return an instance of Elements, which is an extension of the type ArrayList<Element>.
Let’s combine all the code together and see the output:
package org.oxylabs;
import org.jsoup.Connection;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import java.io.IOException;
public class Main {
public static void main(String[] args) {
try {
// fetching the target website
Document doc = Jsoup
.connect("https://en.wikipedia.org/wiki/Jsoup")
.userAgent("Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.0.0 Safari/537.36")
.header("Accept-Language", "*")
.get();
Element firstHeading= doc.selectFirst(".firstHeading");
System.out.println(firstHeading.text());
}
catch(IOException e)
{
throw new RuntimeException(e);
}
}
}
Web scraping with Java using HtmlUnit
There are many methods to read and modify the loaded page. HtmlUnit makes it easy to interact with a web page like a browser, which involves reading text, filling forms, clicking buttons, etc. In this case, we’ll be using methods from this library to read the information from URLs.
In this example, let’s use this Librivox page as a target. We can first have a look at the page and its corresponding HTML.

This webpage contains information about the book “The First Man in the Moon”. You can get the book title from this page; hence, the following image shows the corresponding HTML of this heading.

You can extract the element using its XPath selector. To get the XPath of any HTML element, right-click on its HTML and select “Copy XPath” as shown in the image below:

As discussed in the previous section, there are four steps involved in web scraping with Java.
Step 1. Create your project
The first step is to create a new project in your IDE. Provide the name of your project. Select your build system as Maven and create the project.

Wait for the project to be initialized. You’ll have a Java file and a pom.xml file in the project directory.

The pom.xml file is used for dependencies management. We’ll add the dependencies here.
Step 2. Getting HtmlUnit library
The next step of web scraping with Java is to get the Java libraries. Maven can help here.
In the pom.xml file, add a new section for dependencies and add a dependency for HtmlUnit. The pom.xml file would look something like this:
<dependency>
<groupId>net.sourceforge.htmlunit</groupId>
<artifactId>htmlunit</artifactId>
<version>2.51.0</version>
</dependency>Step 3. Getting and parsing the HTML
The next step is to retrieve the HTML from the target URL as a Java object. Let’s begin with the imports:
import com.gargoylesoftware.htmlunit.WebClient;
import com.gargoylesoftware.htmlunit.html.DomNode;
import com.gargoylesoftware.htmlunit.html.DomNodeList;
import com.gargoylesoftware.htmlunit.html.HtmlElement;
import com.gargoylesoftware.htmlunit.html.HtmlPage;As discussed in the previous section, it’s not a good practice to do a wildcard import such as import com.gargoylesoftware.htmlunit.html.*. Import only what you need. The above imports are what we’re going to use in this Java web scraping tutorial.
HtmlUnit uses the WebClient class to get the page. After importing the required packages, we’ll create an instance of this class. In this example, there's no need for CSS rendering, and there's no use of JavaScript as well. We can set the options to disable these two.
WebClient webClient = new WebClient();
webClient.getOptions().setCssEnabled(false);
webClient.getOptions().setJavaScriptEnabled(false);
HtmlPage page = webClient.getPage("https://librivox.org/the-first-men-in-the-moon-by-hg-wells");Note that getPage() functions can throw IOException. You would need to surround it in a try-catch.
Here's one example implementation of a function that returns an instance of HtmlPage:
public static HtmlPage getDocument(String url) {
HtmlPage page = null;
try (final WebClient webClient = new WebClient()) {
webClient.getOptions().setCssEnabled(false);
webClient.getOptions().setJavaScriptEnabled(false);
page = webClient.getPage(url);
} catch (IOException e) {
e.printStackTrace();
}
return page;
} Now we can proceed with the next step.
Step 4. Querying HTML
There are three categories of methods that can be used with HtmlPage. The first is DOM methods such as getElementById(), getElementByName(), etc. that return one element.
The second category of a selector uses XPath. As discussed before, you can get the XPath by inspecting the HTML of the element.
There are two methods that can work with XPath — getByXPath() and getFirstByXPath(). They return HtmlElement instead of DomElement. Note that special characters like quotation marks will need to be escaped using a backslash:
HtmlElement book = page.getFirstByXPath("//div[@class=\"content-wrap clearfix\"]/h1");
System.out.print(book.asNormalizedText());Lastly, the third category of methods uses CSS selectors. These methods are querySelector() and querySelectorAll(). They return DomNode and DomNodeList<DomNode>, respectively.
To make this Java web scraper tutorial more realistic, let’s print all the chapter names, reader names, and duration from the page. Let’s look at the HTML of the table to extract the content from it.

Since you need to select the elements using its CSS selector, you can get the CSS class of the table element and get all the rows.
String selector = ".chapter-download tbody tr";
DomNodeList<DomNode> rows = page.querySelectorAll(selector);This method will get all the table rows and save them as an array of DomNode. You can loop through this array and get the content of each row:
for (DomNode row : rows) {
String chapter = row.querySelector("td:nth-child(2) a").asNormalizedText();
String reader = row.querySelector("td:nth-child(3) a").asNormalizedText();
String duration = row.querySelector("td:nth-child(4)").asNormalizedText();
System.out.println(chapter + "\t " + reader + "\t " + duration);
}This code snippet will iterate through each row and get the content of each cell. You can later print this data on your screen, so let’s put together all the code and see the output:
package org.oxylabs;
import com.gargoylesoftware.htmlunit.WebClient;
import com.gargoylesoftware.htmlunit.html.DomNode;
import com.gargoylesoftware.htmlunit.html.DomNodeList;
import com.gargoylesoftware.htmlunit.html.HtmlElement;
import com.gargoylesoftware.htmlunit.html.HtmlPage;
import java.io.IOException;
public class HtmlUnitDemo {
public static void main(String[] args) {
HtmlPage page = HtmlUnitDemo.getDocument("https://librivox.org/the-first-men-in-the-moon-by-hg-wells");
HtmlElement book = page.getFirstByXPath("//div[@class=\"content-wrap clearfix\"]/h1");
System.out.print(book.asNormalizedText());
String selector = ".chapter-download tbody tr";
DomNodeList<DomNode> rows = page.querySelectorAll(selector);
for (DomNode row : rows) {
String chapter = row.querySelector("td:nth-child(2) a").asNormalizedText();
String reader = row.querySelector("td:nth-child(3) a").asNormalizedText();
String duration = row.querySelector("td:nth-child(4)").asNormalizedText();
System.out.println(chapter + "\t " + reader + "\t " + duration);
}
}
public static HtmlPage getDocument (String url) {
HtmlPage page = null;
try (final WebClient webClient = new WebClient()) {
webClient.getOptions().setCssEnabled(false);
webClient.getOptions().setJavaScriptEnabled(false);
page = webClient.getPage(url);
} catch (IOException e) {
e.printStackTrace();
}
return page;
}
}And here’s the output:

Advanced web scraping using Java
The earlier sections covered the basics of web scraping. In real-world scenarios, however, scraping often comes with additional challenges. In this section, we will look at some common practical issues you may encounter and how to handle them.
Crawling multiple web pages
A very common scenario in web scraping is extracting data from multiple pages. Many websites provide a “Next” button to navigate between pages. A simple way to handle this is to locate the “Next” button and follow its link as long as it exists.
To understand this, let’s look at https://quotes.toscrape.com/. This website displays a set of quotes on each page, along with a “Next” button at the bottom. Clicking the button loads the next page of quotes.
If we examine the HTML markup of the next button, we can clearly see that it is a hyperlink wrapped in an <li> tag.
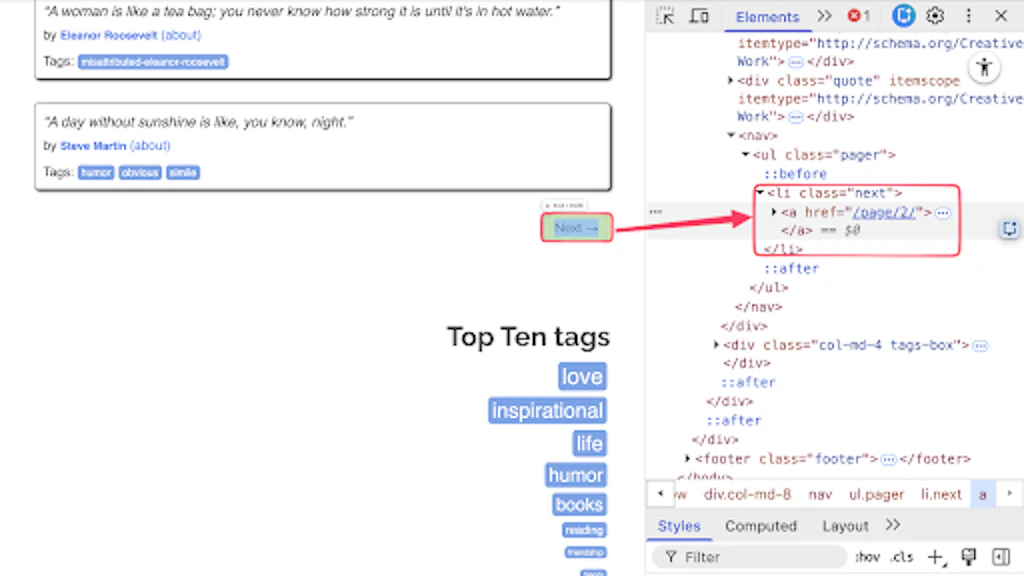
We can locate this element using the following line of code:
Element nextButton = doc.selectFirst("li.next > a");Next, we check whether the button exists and contains a valid URL. If it does, we continue the loop and apply the same extraction logic to the next page.
Here is the entire script:
package org.oxylabs;
import org.jsoup.Connection;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import java.io.IOException;
public class JsoupPagination {
public static void main(String[] args) throws IOException {
String url = "https://quotes.toscrape.com/";
Element nextButton = null;
while (url != null) {
Document doc = Jsoup.connect(url).get();
Elements quotes = doc.select(".quote");
for (Element quote : quotes) {
String text = quote.selectFirst(".text").text();
String author = quote.selectFirst(".author").text();
System.out.println(text + " - " + author);
}
nextButton = doc.selectFirst("li.next > a");
if (nextButton != null) {
String nextHref = nextButton.attr("abs:href");
url = nextHref.isEmpty() ? null : nextHref;
} else {
url = null;
}
}
}
}If you are using the HtmlUnit library, the same concept applies. Here is the full example:
package org.oxylabs;
import com.gargoylesoftware.htmlunit.WebClient;
import com.gargoylesoftware.htmlunit.html.DomNode;
import com.gargoylesoftware.htmlunit.html.DomNodeList;
import com.gargoylesoftware.htmlunit.html.HtmlAnchor;
import com.gargoylesoftware.htmlunit.html.HtmlPage;
import java.io.IOException;
public class HtmlUnitPagination {
public static void main(String[] args) throws IOException {
String url = "https://quotes.toscrape.com/";
try (WebClient webClient = new WebClient()) {
webClient.getOptions().setCssEnabled(false);
webClient.getOptions().setJavaScriptEnabled(false);
while (url != null) {
HtmlPage page = webClient.getPage(url);
DomNodeList<DomNode> quotes = page.querySelectorAll(".quote");
for (DomNode quote : quotes) {
String text = quote.querySelector(".text").asNormalizedText();
String author = quote.querySelector(".author").asNormalizedText();
System.out.println(text + " - " + author);
}
HtmlAnchor nextButton = page.querySelector("li.next > a");
if (nextButton != null) {
url = nextButton.getHrefAttribute().isEmpty() ? null
: page.getFullyQualifiedUrl(nextButton.getHrefAttribute()).toString();
} else {
url = null;
}
}
}
}
}Scraping dynamic content websites
Libraries such as JSoup work only with static HTML. They are not suitable for websites where content is loaded dynamically using JavaScript.
Dynamic websites do not return all content directly in the initial response. Instead, JavaScript is used to render the data after the page loads in the browser.
For example, https://quotes.toscrape.com/js/, loads its content dynamically. If you try to scrape this page using JSoup, you will not get the expected results.
To handle such cases, you need a tool that can render JavaScript, such as a real browser. Selenium is one of the most widely used libraries for this purpose.
First, add Selenium as a dependency in your pom.xml:
<dependency>
<groupId>org.seleniumhq.selenium</groupId>
<artifactId>selenium-java</artifactId>
<version>4.36.0</version>
</dependency>Next, launch a browser:
WebDriver driver = new ChromeDriver();
driver.get("https://quotes.toscrape.com/js/");Once the page is loaded in the browser, getting elements is easy:
List<WebElement> quotes = driver.findElements(By.cssSelector(".quote"));Finally, don't forget to close the browser:
driver.quit();Putting everything together, here is the complete example. For better reliability, you can also wrap it in try-catch statements.
package org.oxylabs;
import org.openqa.selenium.By;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.WebElement;
import org.openqa.selenium.chrome.ChromeDriver;
import org.openqa.selenium.chrome.ChromeOptions;
import org.openqa.selenium.support.ui.ExpectedConditions;
import org.openqa.selenium.support.ui.WebDriverWait;
import java.time.Duration;
import java.util.List;
public class SeleniumDynamicContent {
public static void main(String[] args) {
ChromeOptions options = new ChromeOptions();
options.addArguments("--headless=new");
WebDriver driver = new ChromeDriver(options);
try {
driver.get("https://quotes.toscrape.com/js/");
WebDriverWait wait = new WebDriverWait(driver, Duration.ofSeconds(10));
wait.until(ExpectedConditions.presenceOfElementLocated(By.cssSelector(".quote")));
List<WebElement> quotes = driver.findElements(By.cssSelector(".quote"));
for (WebElement quote : quotes) {
String text = quote.findElement(By.cssSelector(".text")).getText();
String author = quote.findElement(By.cssSelector(".author")).getText();
System.out.println(text);
System.out.println(author);
System.out.println();
}
} finally {
driver.quit();
}
}
}Handling errors and retries
In real-world scraping, failures are common. You should assume that not every request will succeed on the first attempt.
Errors can occur due to timeouts, slow-loading pages, or temporary network issues.
Your code can handle many common errors by adding a retry loop. It is also a good idea to set a limit for maximum retries. The following example demonstrates this using Selenium:
package org.oxylabs;
import org.openqa.selenium.By;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.WebElement;
import org.openqa.selenium.TimeoutException;
import org.openqa.selenium.chrome.ChromeDriver;
import org.openqa.selenium.chrome.ChromeOptions;
import org.openqa.selenium.support.ui.ExpectedConditions;
import org.openqa.selenium.support.ui.WebDriverWait;
import java.time.Duration;
import java.util.List;
public class SeleniumRetries {
public static void main(String[] args) {
int maxRetries = 3;
int attempt = 0;
while (attempt < maxRetries) {
WebDriver driver = null;
try {
ChromeOptions options = new ChromeOptions();
options.addArguments("--headless=new");
driver = new ChromeDriver(options);
driver.get("https://quotes.toscrape.com/js/");
WebDriverWait wait = new WebDriverWait(driver, Duration.ofSeconds(10));
wait.until(ExpectedConditions.presenceOfElementLocated(By.cssSelector(".quote")));
List<WebElement> quotes = driver.findElements(By.cssSelector(".quote"));
for (WebElement quote : quotes) {
String text = quote.findElement(By.cssSelector(".text")).getText();
String author = quote.findElement(By.cssSelector(".author")).getText();
System.out.println(text + " - " + author);
}
break;
} catch (TimeoutException e) {
attempt++;
System.out.println("Request failed. Retrying... (" + attempt + "/" + maxRetries + ")");
} finally {
if (driver != null) {
driver.quit();
}
}
}
}
}In Selenium, it is common to catch org.openqa.selenium.TimeoutException when handling timeouts.
If you are using JSoup, you should catch java.io.IOException, which covers network-related errors, such as timeouts.
For HTMLUnit, you can also catch java.io.IOException. Or if you need more control over HTTP status handling, you may additionally catch com.gargoylesoftware.htmlunit.FailingHttpStatusCodeException.
Best practices for web scraping in Java
Whether you're building a simple Java project or a more advanced Java web scraper, following best practices will help you ensure reliability, efficiency, and long-term maintainability.
Check robots.txt
Websites define access rules in their robots.txt file, specifying which parts of a web page can be accessed. Always review it before starting to ensure your scraping activity complies with site policies.
Avoid sending too many HTTP requests
Sending too many requests in a short time can slow down a website or trigger anti-bot mechanisms. Implement rate limiting to keep your scraping stable and ensure continuous access to the site.
Mimic real browser behavior
Websites often detect automated traffic. Setting a proper user agent can help your Java web scraper appear more like a real browser. In many cases, this simple step improves success rates (as shown in the JSoup example above).
Choose the right Java web scraping library
Selecting the right Java library is essential. Lightweight libraries like JSoup work well for static web pages, while tools like Selenium are better suited for dynamic content. Keep in mind that Selenium runs a full browser, which can slow down performance. Use the library that best fits your use case.
Handle errors and retries
When scraping web pages, always assume that your scraper will encounter errors. Follow the steps outlined in the tutorial to make sure your code can handle most of them, ensuring a more reliable scraping process.
Wait for elements, not time
Dynamic web pages may load content asynchronously. Instead of using fixed delays, wait for specific elements to appear (e.g., using selectors). This makes your scraper more efficient and accurate. For example:
wait.until(ExpectedConditions.presenceOfElementLocated(By.cssSelector(".quote")));Use stable selectors
Your selectors should be robust and resistant to small changes in the HTML page. Prefer IDs or consistent attributes when available, as they make your scraper more reliable and easier to maintain.
Use proxies for large-scale scraping
For scalable web scraping with Java, proxies are essential. They help distribute requests, improve speed, and ensure your traffic remains within acceptable server limits when scraping web pages at scale.
Conclusion
Almost every business needs web scraping to analyze data and stay competitive in the market, and knowing how to use that web scraping knowledge to build a basic web scraper with Java can result in much more informed and quick decisions. This is essential for a business to succeed.
In this article, we’ve gone through a few Java web scraping examples. In case you have a cURL command you'd like to replicate in Java, take advantage of this cURL to Java converter.
If you already know Java, there may not be a need to explore any other language used for web scraping tasks. Still, if you want to see how Python, C#, or another JVM language can be used for web scraping, we have tutorials on Python web scraping, C# web scraping, and web scraping with Scala – the Scala guide builds on the same jsoup library you used here.
We also have tutorials on sending HTTP requests in Java, web scraping with JavaScript and Node.js as well as scraping with Golang. All these articles should help you select the best programming language suitable for your specific needs. Lastly, don’t hesitate to try our own general-purpose web scraper for free.
People also ask
Can you web scrape with Java?
Yes. There are many powerful Java web scraping libraries. Two such examples are JSoup and HtmlUnit. These libraries help you connect to a web page and offer many methods to extract the desired information. If you know Java, it will take very little time to get started with these Java libraries.
Is web scraping legal?
About the author

Maryia Stsiopkina
Former Senior Content Manager
Maryia Stsiopkina was a Senior Content Manager at Oxylabs. As her passion for writing was developing, she was writing either creepy detective stories or fairy tales at different points in time. Eventually, she found herself in the tech wonderland with numerous hidden corners to explore. At leisure, she does birdwatching with binoculars (some people mistake it for stalking), makes flower jewelry, and eats pickles.
All information on Oxylabs Blog is provided on an "as is" basis and for informational purposes only. We make no representation and disclaim all liability with respect to your use of any information contained on Oxylabs Blog or any third-party websites that may be linked therein. Before engaging in scraping activities of any kind you should consult your legal advisors and carefully read the particular website's terms of service or receive a scraping license.
Related articles





Web Scraper API for your scraping project
Make the most of efficient web scraping while navigating CAPTCHAs and ensuring continuous data collection.

Get the latest news from data gathering world
Scale up your business with Oxylabs®
Proxies
Advanced proxy solutions
Data Collection
Datasets
Resources
Innovation hub
Web Scraper API for your scraping project
Make the most of efficient web scraping while navigating CAPTCHAs and ensuring continuous data collection.