175M+ ethically sourced IPs built for the highest reliability.
High-speed, cost-effective proxies built for any scraping workload.
Premium static residential proxies from trusted ASNs for most difficult targets.
Dedicated IPs from premium ASNs for demanding scraping.

AI-powered proxy solution for optimized web scraping performance.

20M+ IP addresses from real mobile devices for precise targeting.

Free Chrome proxy manager extension that works with any proxy provider.

Free Android proxy manager app that works with any proxy provider.

Free community-driven tools to improve your web scraping projects.
Web Scraper API
All-in-one web data collection platform for every stage of web scraping.
Fast Search API
Ultra-fast organic search results scraper tailored for AI workflows.
Headless Browser
Advanced browser automation solution for AI agents and scraping.
AI Studio
A suite of AI-powered tools for various scraping projects.

Documentation
All features, parameters, and integration details, backed by code samples in every coding language.
Tutorials, samples, and guides.
Latest fixes and features.





Scrapy Playwright Tutorial: How to Scrape JavaScript Websites



Agnė Matusevičiūtė
Last updated by Akvilė Lūžaitė
2025-07-31
6 min read
![]() AI Summary:
AI Summary:
Scrapy Playwright integrates Playwright's browser automation with Scrapy's web scraping framework. This allows Scrapy to effectively render and interact with JavaScript-heavy websites, enabling the extraction of dynamic content. The tutorial demonstrates installation, configuration, advanced page interactions, and proxy usage for robust data collection.
Scrapy is a popular Python package commonly used in the web scraping field. While it’s ideal for scraping static web pages, the same could not be said for dynamic, JavaScript rendering-heavy websites: it may require rendering and additional user input.
As a result, Scrapy Playwright was released – an advanced headless browser designed for scraping dynamic, JavaScript-enabled sites. In this Scrapy Playwright tutorial, we’ll demonstrate how to successfully gather public data using Playwright integration for Scrapy paired with Oxylabs' proxies. If you're new to scraping, get a quick start with this JavaScript & Node.js scraping guide.
Let's get started!
1. Installing Scrapy Playwright
First, let’s install the Scrapy Playwright pip package:
pip install scrapy-playwrightNow, we can install all the prerequisite browser engines:
playwright install2. Setting up Scrapy Playwright
Now that we have the Playwright integration for Scrapy installed, let’s set up a basic Scrapy spider using the following command:
scrapy startproject scrapy_book_crawler
cd scrapy_book_crawler
scrapy genspider books https://books.toscrape.com/js/This command will initialize a base Scrapy project, navigate to it and create a spider named books for us to work with.
3. Reviewing main settings
To finish setting up our Playwright integration, we need to add some specific Scrapy settings in our settings.py file.
DOWNLOAD_HANDLERS = {
"http": "scrapy_playwright.handler.ScrapyPlaywrightDownloadHandler",
"https": "scrapy_playwright.handler.ScrapyPlaywrightDownloadHandler",
}
PLAYWRIGHT_DEFAULT_NAVIGATION_TIMEOUT = (
30 * 1000
)
PLAYWRIGHT_BROWSER_TYPE = "chromium"In DOWNLOAD_HANDLERS, we specify that we’ll want to use the Scrapy Playwright request handlers for both our http and https requests.
In PLAYWRIGHT_DEFAULT_NAVIGATION_TIMEOUT, we can specify the timeout value to be used when requesting pages with Playwright. The default value for Playwright timeouts is 30 seconds.
In PLAYWRIGHT_BROWSER_TYPE, we define the type of browser engine to be used to process requests.
For more in-depth information about these and all the other possible configuration parameters, you can check out the Playwright documentation on GitHub.
4. Scraping with Scrapy Playwright
Let’s start with a simple scraping task just to see if our setup is correct. We’ll gather book titles and prices from https://books.toscrape.com/, a mock website designed for people to practice web scraping.
First, we’ll create a model for the information that we want scraped:
import scrapy
class Book(scrapy.Item):
title = scrapy.Field()
price = scrapy.Field()We should put this model in the file items.py, which was already created by the Scrapy project initializer.
Here, we’ve created an Item in the context of Scrapy and defined some fields for it. An Item basically defines the data that we’ll want to extract during our scraping.
Next, let’s add some logic to our spider in spiders/books.py.
import scrapy
from scrapy_book_crawler.items import Book
class BooksSpider(scrapy.Spider):
"""Class for scraping books from https://books.toscrape.com/"""
name = "books"
def start_requests(self):
url = "https://books.toscrape.com/"
yield scrapy.Request(
url,
meta=dict(
playwright=True,
playwright_include_page=True,
errback=self.errback,
),
)
async def parse(self, response):
page = response.meta["playwright_page"]
await page.close()
for book in response.css("article.product_pod"):
book = Book(
title=book.css("h3 a::attr(title)").get(),
price=book.css("p.price_color::text").get(),
)
yield book
async def errback(self, failure):
page = failure.request.meta["playwright_page"]
await page.close()
In the start_requests(self) function, we define the URL and the meta parameters for our requests. To use Playwright, we need to add some variables to our meta dictionary:
playwright=True indicates that Scrapy should use Playwright to process this request.
playwright_include_page=True makes sure that we can access the Page Playwright object when processing the request and add PageMethods, which will be used later on.
errback=self.errback function would close the pages for us in case the request fails at some point.
In the parse(self, response) function, we instruct the Page to close after processing, extract the data for the Book item, and yield it.
Now, we can run our spider with the following command and inspect the results:
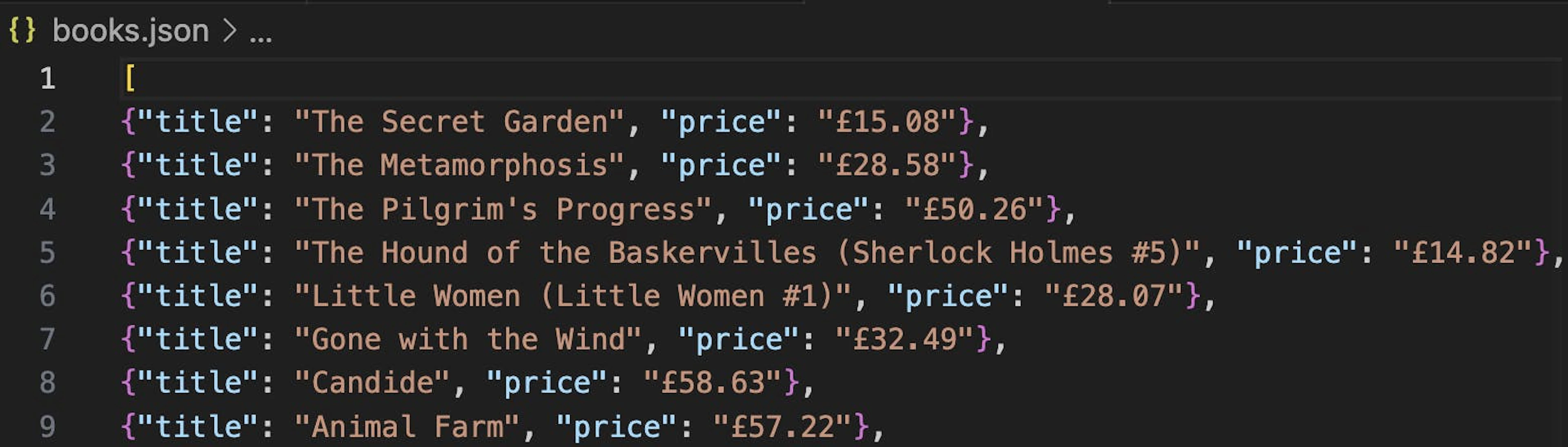
scrapy crawl books -o books.jsonThis will save all of the items yielded by Scrapy into a json file.
5. Scraping multiple pages
To gather data from several pages, we need Scrapy to yield an additional request for each URL we find inside our current one.
Let’s modify our function to do just that.
async def parse(self, response):
page = response.meta["playwright_page"]
await page.close()
for book in response.css("article.product_pod"):
book = Book(
title=book.css("h3 a::attr(title)").get(),
price=book.css("p.price_color::text").get(),
)
yield book
next_page = response.css("li.next a::attr(href)").get()
if next_page:
next_page_url = response.urljoin(next_page)
yield scrapy.Request(
next_page_url,
meta=dict(
playwright=True,
playwright_include_page=True,
errback=self.errback,
),
)Our newly added code will now find the next page URL within our currently processed one. Also, it will yield an additional request for the page to our Scrapy pipeline to be processed. This process will repeat until there are no pages left.
If we run the code with the same command:
scrapy crawl books -o books.jsonWe can see that there are many more books in our result file now, as our spider has gone through multiple pages to fetch them.
6. Interacting with page
Until now, we haven’t made the most of the potential that Playwright can give. Let’s do something like clicking a category link and taking a screenshot of the rendered webpage.
If we open the page we are scraping, we can see that there’s a list of categories on the right, and each category is clickable.
Let’s create a Python enum for all the categories so that we can access them in the code conveniently later on. To do that, we’ll create a file named enums.py and add the enum there:
from enum import Enum
class BookCategory(int, Enum):
"""All category li nth:child numbers for books.toscrape.com"""
TRAVEL = 1
MYSTERY = 2
HISTORICAL_FICTION = 3
SEQUENTIAL_ART = 4
CLASSICS = 5
PHILOSOPHY = 6
ROMANCE = 7
WOMENS_FICTION = 8
FICTION = 9
CHILDRENS = 10
RELIGION = 11
NONFICTION = 12
MUSIC = 13
DEFAULT = 14
SCIENCE_FICTION = 15
SPORTS_AND_GAMES = 16
ADD_A_COMMENT = 17
FANTASY = 18
NEW_ADULT = 19
YOUNG_ADULT = 20
SCIENCE = 21
POETRY = 22
PARANORMAL = 23
ART = 24
PSYCHOLOGY = 25
AUTOBIOGRAPHY = 26
PARENTING = 27
ADULT_FICTION = 28
HUMOR = 29
HORROR = 30
HISTORY = 31
FOOD_AND_DRINK = 32
CHRISTIAN_FICTION = 33
BUSINESS = 34
BIOGRAPHY = 35
THRILLER = 36
CONTEMPORARY = 37
SPIRITUALITY = 38
ACADEMIC = 39
SELF_HELP = 40
HISTORICAL = 41
CHRISTIAN = 42
SUSPENSE = 43
SHORT_STORIES = 44
NOVELS = 45
HEALTH = 46
POLITICS = 47
CULTURAL = 48
EROTICA = 49
CRIME = 50
Now, we’ll adjust our start_requests(self) function to make use of some PageMethods.
def start_requests(self):
category_number = BookCategory.CLASSICS
url = "https://books.toscrape.com/"
yield scrapy.Request(
url,
meta=dict(
playwright=True,
playwright_include_page=True,
playwright_page_methods=[
PageMethod(
"click",
selector=f"div.side_categories > ul > li > ul > li:nth-child({self.category_number.value}) > a",
),
PageMethod("wait_for_selector", "article.product_pod"),
],
errback=self.errback,
),
)PageMethod allows us to interact with the page before we finish rendering it and sending it as our response for parsing. We specify one method to click the category we have selected from our enum in the variable category_number and another method to wait for a CSS selector of a product listing to load.
Next, we’ll update the parse(self, response) function to take a screenshot of the rendered page using the page.screenshot function and save it as a file:
async def parse(self, response):
category_number = BookCategory.CLASSICS
page = response.meta["playwright_page"]
await page.screenshot(path=f"books-{self.category_number.name}.png")
await page.close()
for book in response.css("article.product_pod"):
book = Book(
title=book.css("h3 a::attr(title)").get(),
price=book.css("p.price_color::text").get(),
)
yield bookThe full code for our Scrapy spider should look like this:
import scrapy
from scrapy_playwright.page import PageMethod
from scrapy_book_crawler.items import Book
from scrapy_book_crawler.enums import BookCategory
class BooksSpider(scrapy.Spider):
"""Class for scraping books from https://books.toscrape.com/"""
name = "books"
category_number = BookCategory.CLASSICS
def start_requests(self):
url = "https://books.toscrape.com/"
yield scrapy.Request(
url,
meta=dict(
playwright=True,
playwright_include_page=True,
playwright_page_methods=[
PageMethod(
"click",
selector=f"div.side_categories > ul > li > ul > li:nth-child({self.category_number.value}) > a",
),
PageMethod("wait_for_selector", "article.product_pod"),
],
errback=self.errback,
),
)
async def parse(self, response):
page = response.meta["playwright_page"]
await page.screenshot(path=f"books-{self.category_number.name}.png")
await page.close()
for book in response.css("article.product_pod"):
book = Book(
title=book.css("h3 a::attr(title)").get(),
price=book.css("p.price_color::text").get(),
)
yield book
async def errback(self, failure):
page = failure.request.meta["playwright_page"]
await page.close()If we run it with this command:
scrapy crawl books -o books.jsonWe’ll see our screenshot saved within the project files and our results file populated with books from the selected category:
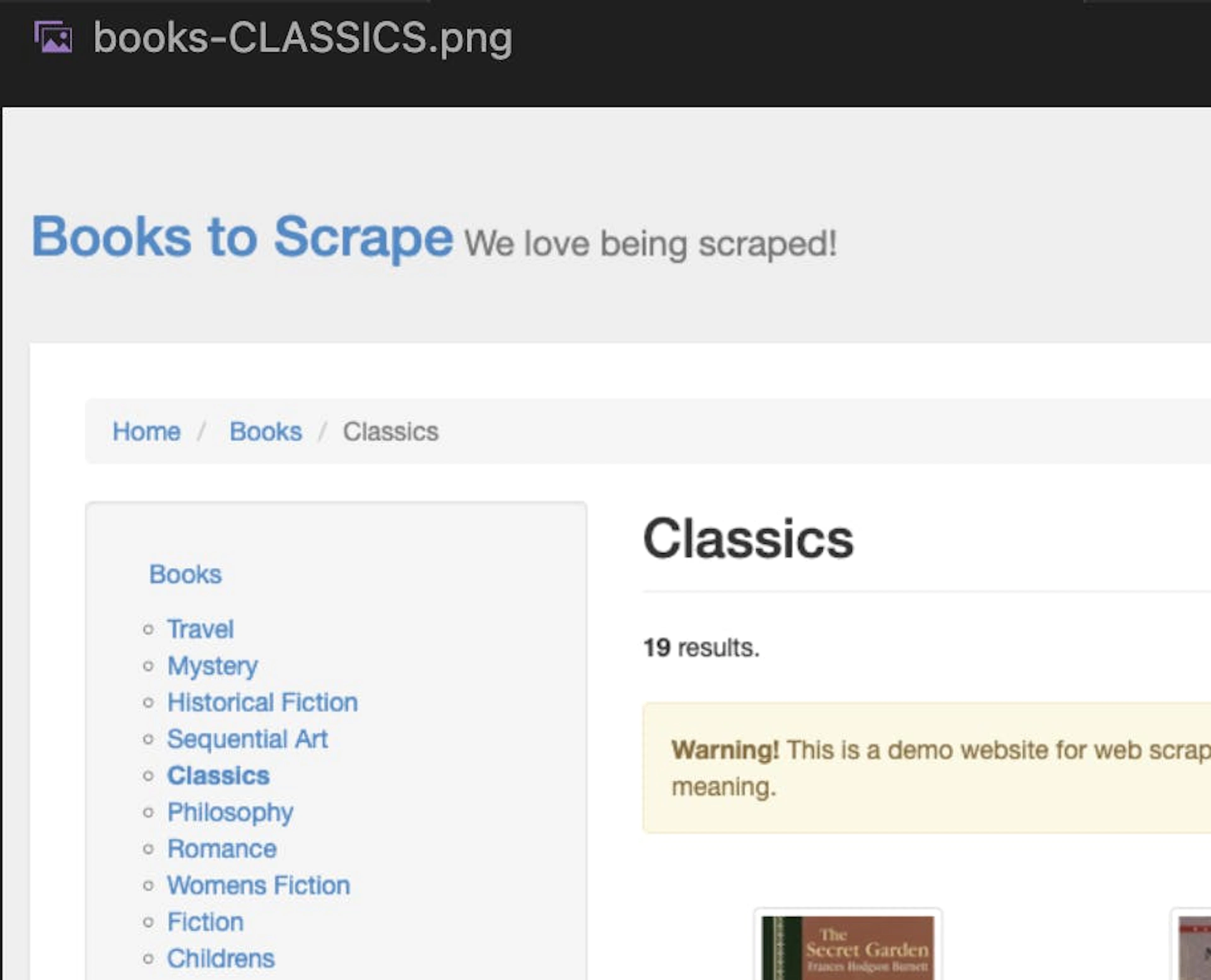
classics
7. Using proxies with Scrapy Playwright
Scrapy Playwright works best with proxies – they can enhance your anonymity by concealing your real IP address and location, thus increasing your chances for successful and hassle-free scraping operations.
For the sake of this tutorial, we’re going to use Oxylabs’ Dedicated Datacenter Proxies, but feel free to use another type if you want.
You can set up proxies for your Playwright spiders in three different ways:
1) Spider class custom_settings
We can add the proxy settings as launch options within the custom_settings parameter used by the Scrapy Spider class:
class BooksSpider(scrapy.Spider):
"""Class for scraping books from https://books.toscrape.com/"""
name = "books"
custom_settings = {
"PLAYWRIGHT_LAUNCH_OPTIONS": {
"proxy": {
"server": "127.0.0.1:60000",
"username": "username",
"password": "password",
},
}
}2) Meta dictionary in start_requests
We can also define the proxy within the start_requests function by passing it within the meta dictionary:
def start_requests(self) -> Generator[scrapy.Request, None, None]:
url = "https://books.toscrape.com/"
yield scrapy.Request(
url,
meta=dict(
playwright=True,
playwright_include_page=True,
playwright_context_kwargs={
"proxy": {
"server": "127.0.0.1:60000",
"username": "username",
"password": "password",
},
},
errback=self.errback,
),
)3) PLAYWRIGHT_CONTEXTS in settings.py
Lastly, we can also define the proxy we want to use within the Scrapy settings file:
PLAYWRIGHT_CONTEXTS = {
"default": {
"proxy": {
"server": "127.0.0.1:60000",
"username": "username",
"password": "password",
},
},
"alternative": {
"proxy": {
"server": "127.0.0.1:60001",
"username": "username",
"password": "password",
},
},And there you have it – we’ve successfully built a scraper that utilizes Playwright to render and interact with JavaScript-enabled websites.
If you want more tips on how to succeed with Playwright, check out these 9 Playwright best practices.
Picking the right proxy for your scraping needs
When working with Scrapy Playwright, the type of proxy you choose can make a huge difference. Here’s a quick guide to help you decide:
Residential Proxies – These come from real user devices and are great when you need to look like genuine traffic. They’re perfect for scraping JavaScript-heavy sites that are strict about interrupting automated requests.
Mobile Proxies – If you’re scraping content that’s often accessed on mobile, like social apps or sites with infinite scroll, mobile proxies can help emulate real smartphone users.
ISP Proxies – A mix between datacenter speed and residential trust. These are ideal when you need stable sessions and fewer IP mismanagement without sacrificing performance.
Datacenter Proxies – The fastest and cheapest option, best for high-volume scraping of less protected sites where speed matters more than stealth.
Free Proxies – Technically an option, but usually slow, unreliable, and risky, unless they're a free trial from a reputable provider. Avoid them for anything serious – instead, use them for testing.
The best choice depends on your project. For example, scraping a heavily protected retail site might call for rotating residential proxies, while collecting data from simpler sites could be done efficiently with datacenter proxies or even free proxies.
Wrapping up
We’ve covered how to set up Scrapy Playwright from installation to handling JavaScript rendering. With the right proxy setup, this combination can handle most scraping scenarios – from a basic Scrapy spider to advanced workflows using async def parse and Playwright page methods.
That said, if managing browser contexts, request scheduling, and proxies feels like too much overhead, you can skip the complexity entirely by using Web Scraper API. It handles JavaScript rendering, rotating user agents, and proxies for you, so you can focus on extracting data instead of managing infrastructure.
Whether you stick with Scrapy Playwright, build a plain Playwright scraper, or opt for a web scraping API, you now have the tools to scrape both static and dynamic sites efficiently.
Frequently asked questions
Is Playwright good for scraping?
Yes, Playwright is excellent for scraping dynamic websites that are JavaScript-heavy , handling unsupported URL scheme https errors, and interacting with dynamic elements like dropdowns or login forms. It’s especially useful when dealing with requesting pages that require JavaScript rendering or custom user agent headers.
Pairing Playwright with Scrapy lets you take advantage of Scrapy’s efficient request scheduling and item pipelines while using Playwright for its page object capabilities and full browser context emulation.
Is Playwright better than Selenium?
Can Scrapy parse JavaScript?
What is the difference between Playwright and Scrapy Splash?
What is the difference between Scrapy and Playwright?
How to use Scrapy with Playwright?
Is Scrapy better than BeautifulSoup?
Human-like scraping without IP interruptions
Forget about IP interruptions and CAPTCHAs with 170M+ premium proxies located in 195 countries.
Effortless data gathering
Extract data even from the most complex websites without hassle by using Web Scraper API.
About the author
Agnė Matusevičiūtė
Technical Copywriter
With a background in philology and pedagogy, Agnė focuses on making complicated tech simple.
All information on Oxylabs Blog is provided on an "as is" basis and for informational purposes only. We make no representation and disclaim all liability with respect to your use of any information contained on Oxylabs Blog or any third-party websites that may be linked therein. Before engaging in scraping activities of any kind you should consult your legal advisors and carefully read the particular website's terms of service or receive a scraping license.
Related articles


List Crawling in Python: Tools, Tips, and Techniques

Danielė Virinaitė
2026-06-17

Top 7 Web Price Scraping Software and Tools for 2026

Shinthiya Nowsain Promi
2026-06-11

Get the latest news from data gathering world
Scale up your business with Oxylabs®
Proxies
Advanced proxy solutions
Data Collection
Datasets
Resources
Innovation hub
Human-like scraping without IP interruptions
Forget about IP interruptions and CAPTCHAs with 170M+ premium proxies located in 195 countries.
Effortless data gathering
Extract data even from the most complex websites without hassle by using Web Scraper API.