175M+ ethically sourced IPs built for the highest reliability.
High-speed, cost-effective proxies built for any scraping workload.
Premium static residential proxies from trusted ASNs for most difficult targets.
Dedicated IPs from premium ASNs for demanding scraping.

AI-powered proxy solution for optimized web scraping performance.

20M+ IP addresses from real mobile devices for precise targeting.

Free Chrome proxy manager extension that works with any proxy provider.

Free Android proxy manager app that works with any proxy provider.

Free community-driven tools to improve your web scraping projects.
Web Scraper API
All-in-one web data collection platform for every stage of web scraping.
Fast Search API
Ultra-fast organic search results scraper tailored for AI workflows.
Headless Browser
Advanced browser automation solution for AI agents and scraping.
AI Studio
A suite of AI-powered tools for various scraping projects.

Documentation
All features, parameters, and integration details, backed by code samples in every coding language.
Tutorials, samples, and guides.
Latest fixes and features.





What are HTTP Headers: Examples and Most Common Types



Mantas Miksenas
Last updated by Agnė Matusevičiūtė
2024-07-10
7 min read
![]() AI Summary:
AI Summary:
HTTP headers are small but powerful pieces of information sent with every web request and response, shaping how data is delivered and interpreted. This article covers the essentials: what HTTP headers are, how they function, and their role in web data collection.
Web scraping or web data collection tools, such as the Web Scraper API, are a thriving method for gathering vast amounts of publicly available intelligence in an automated way. Simply put, the more you know, the more you grow, right? But how much do you know about the web scraping process itself?
When it comes to the technical side of web scraping, which has evolved into an art itself, perhaps the most interesting part is that there is no single correct way to set up a web scraper. However, some approaches are more effective than others.
One such approach is to use and optimize HTTP headers. It can significantly increase chances of maintaining stable access and ensure the data you retrieve is accurate and of high quality. In this article, we’ll discuss what HTTP headers are, how they work, why they matter in web scraping, and how to secure your web app with various HTTP headers.
What are HTTP headers?

What are HTTP headers?
The purpose of HTTP headers is to enable both the client and server to transfer further details within the request or response. These headers carry details that help the client and server understand how to handle the request or response properly.
HTTP stands for HyperText Transfer Protocol, which on the internet manages how communication is structured and transferred, as well as how web servers (such as websites) and browsers (e.g., Chrome, Firefox, or Safari) should respond to different requests.
Generally, the user sends a request that includes a header. HTTP headers contain additional information for the web server. Web servers then respond by sending over specified data back to the client. Some request headers may influence how the server formats or customizes the response.
How do HTTP headers work?
HTTP headers work by attaching extra information to the request or response messages exchanged between a client (like a browser or scraper) and a web server. When a client sends a request, it includes request headers that inform the server about the following:
The type of content it accepts.
The preferred language.
The software being used.
In return, the server sends back response headers with the details about:
The content.
The server.
How the client should handle the response.
These headers don’t contain the main content (like the actual web page), but they play a vital role in how that content is delivered, displayed, and secured.
List of HTTP headers
The HTTP headers list can be grouped based on their context:
HTTP request header
The HTTP request header is sent by the client i.e., internet browser, in an HTTP transaction. HTTP request headers send many details about the source of the request, such as the type of browser (or application in general) being used and its version.
HTTP request headers are a crucial part of any HTTP communication. Websites tailor their layouts and designs to the type of machine, operating system, and application making the request. A collection of information on the software and hardware of the source is sometimes referred to as a “user agent.” Otherwise, content might be displayed incorrectly.
If the website in question does not recognize the user agent, it will often default to one of these two actions. Some websites will display a default HTML version they have prepared for cases like these, while others will block the HTTP request entirely.
HTTP response header
Response headers are sent by a web server in HTTP transaction responses. Response headers often contain information on whether the initial request was successful, the type of connection, encoding, and other details. If the request is not successful, the HTTP response headers will contain an error code. HTTP header error codes are divided into specific categories:
1xx – Informational
2xx – Success
3xx – Redirection
4xx – Client Error
5xx – Server Error
Each category has many situation-specific responses. A full list of HTTP header error codes is available on various websites.
General HTTP header
General headers apply to both requests and responses, but don’t apply to the content itself. These headers can be present in any HTTP request or response message.
The most common general headers are Connection, Cache-Control, and Date.
HTTP entity header
Entity headers contain information about the body of the resource. Each entity tag is represented as a pair, for example, Content-Language or Content-Length.
Note that “entity headers” is a legacy term and may not appear in newer protocol specifications – you may find “representation headers” instead.
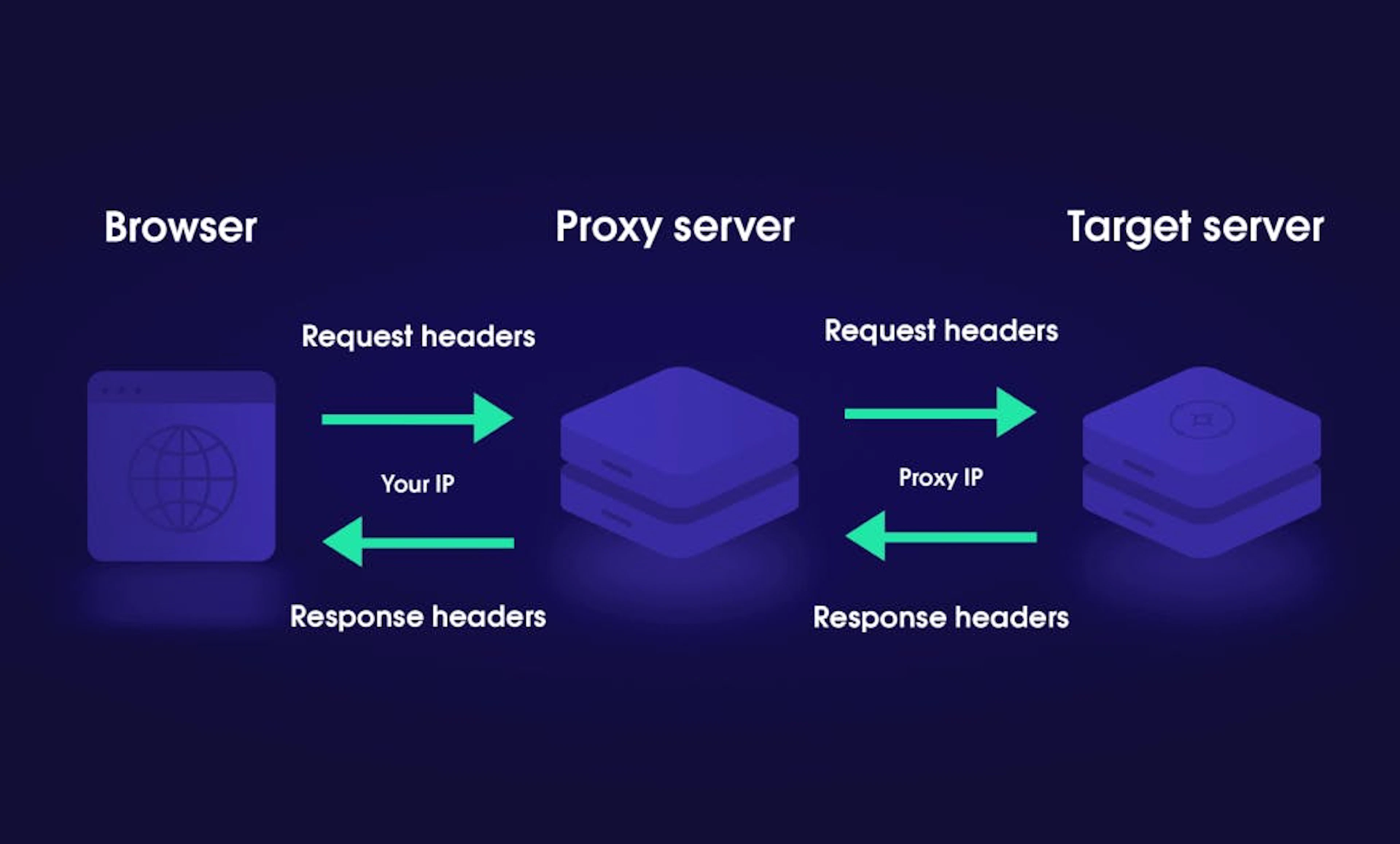
Understanding HTTP headers
The most common HTTP headers to use in web scraping
When scraping websites, using the correct HTTP headers can make the difference between successful and unsuccessful web data extraction. Here are the most commonly used HTTP headers that web scrapers rely on to maintain stable access and retrieve accurate data:
| Header | Example value |
|---|---|
| HTTP header User-Agent | Mozilla/5.0 (X11; Linux x86_64; rv:12.0) Gecko/20100101 Firefox/12.0 |
| HTTP header Accept-Language | en-US |
| HTTP header Accept-Encoding | gzip, deflate |
| HTTP header Accept | text/html |
| HTTP header Referer | http://www.google.com/ |
| HTTP header Host | www.google.com |
| HTTP header Connection | Common values: keep-alive, close |
HTTP header User-Agent
Identifies the browser, device, or application making the request. Servers use this to tailor responses.
HTTP header Accept-Language
Tells the server which languages the client prefers. This helps serve content in the user's preferred language.
HTTP header Accept-Encoding
Indicates the encoding formats the client can handle, like gzip or deflate. Used to compress data for faster transfers.
HTTP header Accept
Specifies the content types (MIME types) the client expects in the response.
HTTP header Referer
Shows the URL of the previous page that led to the current request. Often used for analytics or access control.
HTTP header Host
Specifies the domain name of the server to which the client wants to connect. Essential for websites sharing the same IP address.
HTTP header Connection
Controls whether the network connection stays open after the current request.
Examples of HTTP headers
GET /URL/destination/to/get/ HTTP/1.1
Host: targetwebsite.com
User-Agent: Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US; rv:1.9.1.5)
Gecko/20091102 Firefox/3.5.5 (.NET CLR 3.5.30729)
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
Accept-Language: en-us,en;q=0.5
Accept-Encoding: gzip,deflate
Accept-Charset: ISO-8859-1,utf-8;q=0.7,*;q=0.7
Keep-Alive: 300
Connection: keep-alive
Cookie: PHPSESSID=r2t5uvjq435r4q7ib3vtdjq120
Pragma: no-cache
Cache-Control: no-cacheAs mentioned, the User-Agent header is one of the most essential headers that can determine whether your request will be successful or not. Most common user agents should be used to make sure you maintain stable connections while web scraping.
Some HTTP headers can be grouped according to how a proxy handles them. We have already written about HTTP Proxies and their configuration. Here are some headers that interact with proxies:
Connection – a general header that controls if the network connection stays open after the current transaction finishes.
Keep-Alive – allows the client to indicate how the connection may be used to set a maximum amount of requests and a timeout. For this header to be valid, the Connection header must be set to "Keep-Alive."
Proxy-Authenticate – a response header that defines the authentication method for gaining access to a resource behind a proxy server. This header authenticates the request to the proxy server, allowing it to transmit the request further.
Proxy-Authorization – a request header that includes the credentials to authenticate a user agent to a proxy server.
Trailer – a response header that allows the sender to include additional fields at the end of chunked messages. For example, a message integrity check, post-processing status, or digital signature.
Transfer-Encoding – specifies the form of encoding used to safely transfer the payload body to the client (receiver). This header is applied to a message between two nodes, not to a resource itself.
These are just a few examples of headers — listing all of the possible variations is nearly impossible. HTTP headers can send various types of requests, such as specifying languages and encoding.
Why use and optimize HTTP headers?
Increase the web scraper’s success rates when collecting web data
Increase the quality of data retrieved from the target server
Simply put, the use of HTTP headers will have a direct impact on the type of data retrieved from web servers and define its quality. What’s more, if you use them accordingly, it will allow you to substantially reduce the chances of interruptions by web servers.
As mentioned before, HTTP headers carry additional information to web servers, and by optimizing the content of this message, it is possible to emulate standard browser behavior with your internet requests. Such traffic to web servers increases the success rates of your web data gathering.
How to secure your web app with HTTP headers?
While web scrapers can use HTTP headers to maintain stable access, they can also be employed by web servers for web security purposes. Simply put, HTTP security headers are a contract between the browser and the developer. This contract is defined by HTTP response headers that set the level of security for the website.
Here are some of the most common headers that allow you to secure your web applications:
Content-Security-Policy header – provides an additional layer of security. It helps prevent various attacks, including Cross Site Scripting (XSS) and other code injection attacks. The policy defines approved content sources and allows the browser to load them.
Permissions-Policy header – allows web administrators to control access to browser features, such as geolocation, camera, or fullscreen.
X-Frame-Options header – protects website visitors from clickjacking attacks.
X-XSS-Protection header – formerly used to configure the built-in reflective XSS protection. It’s now deprecated and has no effect in modern browsers like Chrome, Edge, or Safari.
Referrer-Policy header – controls how much referrer information, sent via the Referrer header, ought to be included with requests.
X-Content-Type-Options response header – a marker used by the server. This marker indicates that the MIME types advertised in the Content-Type headers should be followed, not changed.
You can easily check your HTTP header security online. Various tools allow you to check which HTTP security headers are currently in use on your website; you simply need to provide a URL you want to check.
Other successful web scraping techniques
While there’s no universal recipe for building a perfect scraper, there are proven resources and techniques that can improve your odds, such as HTTP headers optimization. Another example would be the use of a proxy server, with which you can practice IP rotation (also known as rotating proxies) that will substantially increase your chances of being successful at web scraping.
You can also use headless browsers, such as Puppeteer, Playwright, and Selenium, which emulate standard browser behavior by executing JavaScript and rendering pages as an actual browser would. This approach is effective for scraping modern websites that heavily rely on JavaScript for dynamic content.
Finally, don’t forget about the robots.txt file. You should always check it to find out what areas are allowed or disallowed for web scraping. Respecting the robots.txt is naturally a good practice and reduces legal risks.
It’s a wrap
Hopefully, by now, you have a decent understanding of what an HTTP header is, its purpose, and how it comes into play in the web scraping world. We also briefly touched on HTTP security headers and their functionality.
Of course, it’s only the tip of the iceberg, and there are quite a few headers that need to be taken into account when web scraping. We have covered 5 essential HTTP headers that every web scraper must use and optimize. You can also buy HTTP proxies for your web scraping projects or explore various proxy types, including datacenter IPs, residential proxies, and free proxies. Check out the Web Scraper API to simplify data extraction at scale. Happy scraping!
About the author
Mantas Miksenas
Former Inbound Sales Team Lead
Mantas Miksenas was an Inbound Sales Team Lead who believes he needs to keep moving forward by pushing the limits. The tech industry compliments the latter aim as it expands boundaries and helps to build the future. While he pushes his limits, he likes to put on a soundtrack of smooth Jazz and improvisational music to keep himself energized.
All information on Oxylabs Blog is provided on an "as is" basis and for informational purposes only. We make no representation and disclaim all liability with respect to your use of any information contained on Oxylabs Blog or any third-party websites that may be linked therein. Before engaging in scraping activities of any kind you should consult your legal advisors and carefully read the particular website's terms of service or receive a scraping license.
Accelerate your projects with free proxies
Discover the benefits of using Oxylabs’ top-notch proxy services for free.
Residential Proxies for hassle-free web scraping
Manage geo-restrictions maintain stable access with our premium Residential Proxies.
Frequently asked questions
What are the 4 types of headers?
HTTP headers can be grouped into four types:
General headers – apply to both requests and responses, but don’t apply to the content itself. General HTTP header example: Cache-Control.
Request headers – sent by the client (usually a browser) to provide details about the source of the request. HTTP request header example: User-Agent.
Response headers are sent by a web server to provide information about the response or the server itself. HTTP response header example: Server.
Entity headers provide details about the body of the message. HTTP entity header example: Content-Language.
What are the 7 most used headers?
Where can I find HTTP headers?
Related articles

List Crawling in Python: Tools, Tips, and Techniques

Danielė Virinaitė
2026-06-17

Top 7 Web Price Scraping Software and Tools for 2026

Shinthiya Nowsain Promi
2026-06-11

Web Scraping Best Practices: Complete 2026 Guide

Dovydas Vėsa
2026-06-01

Get the latest news from data gathering world
Scale up your business with Oxylabs®
Proxies
Advanced proxy solutions
Data Collection
Datasets
Resources
Innovation hub
Accelerate your projects with free proxies
Discover the benefits of using Oxylabs’ top-notch proxy services for free.
Residential Proxies for hassle-free web scraping
Manage geo-restrictions maintain stable access with our premium Residential Proxies.