175M+ ethically sourced IPs built for the highest reliability.
High-speed, cost-effective proxies built for any scraping workload.
Premium static residential proxies from trusted ASNs for most difficult targets.
Dedicated IPs from premium ASNs for demanding scraping.

AI-powered proxy solution for optimized web scraping performance.

20M+ IP addresses from real mobile devices for precise targeting.

Free Chrome proxy manager extension that works with any proxy provider.

Free Android proxy manager app that works with any proxy provider.

Free community-driven tools to improve your web scraping projects.
Web Scraper API
All-in-one web data collection platform for every stage of web scraping.
Fast Search API
Ultra-fast organic search results scraper tailored for AI workflows.
Headless Browser
Advanced browser automation solution for AI agents and scraping.
AI Studio
A suite of AI-powered tools for various scraping projects.

Documentation
All features, parameters, and integration details, backed by code samples in every coding language.
Tutorials, samples, and guides.
Latest fixes and features.






![]() AI Summary:
AI Summary:
The post outlines how to programmatically extract Amazon Best Sellers product information like title, price, and URL using Python with Selenium for browser automation, saving the results to a CSV file. It addresses challenges posed by Amazon's complex web systems and offers a dedicated Amazon Best Sellers Scraper API as a simpler, more reliable solution for data collection.
Amazon is the biggest e-commerce site in the world – with countless products and millions of customers. It's no wonder that retailers are trying to get started and, more importantly, to get noticed in Amazon's marketplace.
The Best Sellers page on Amazon helps those retailers perform market research – it displays the best selling products on Amazon and can act like a guide for what products to stock in your own store. However, shopping sites like Amazon make it challenging to track prices on items, especially specific ones that you might be interested in.
This is where learning how to scrape Amazon comes in handy – it removes all the possible manual labor out of the equation. While you can scroll and write down the products and the prices you think you should remember, you can also use Python and a few additional libraries to automatically scrape Amazon Best Sellers sites into known data formats, like csv. This way, you can use the structured data to analyze, monitor, and track Amazon Best Sellers items to achieve your desired results.
In this tutorial, we’ll be looking at how to scrape Amazon Best Sellers pages with Python and introduce an easier way to scrape any e-commerce website.
What are Amazon Best Sellers?
Amazon offers a unique way of positioning their products – the Amazon Best Sellers Rank or Amazon BSR ranks all products available on the marketplace according to their sales volume. Customers can easily identify the best-selling products worldwide and see the position of the product they are considering to buy. The BSR ranking is displayed in each product’s description page and is updated periodically, showing the most accurate market trends.
In short, the Best Sellers sites are just product pages, and the scraping information on them is not that much different than scraping data from a regular Amazon page. However, Amazon, among other big sites, have mechanisms in place that make it a challenge to access this publicly available data.
With the proper measures in place, your IP address can keep making requests to Amazon so you can continue scraping the site reliably. By implementing a few safety measures in your Python code, you can maintain steady, uninterrupted access to Amazon.
Prepare the Environment
You can download the latest version of Python from the official website.
To store your Python code, run the following command to create a new Python file in your current directory.
touch main.py Choosing and installing dependencies
Next, set up the dependencies required for scraping.
For more reliable results when working with Amazon, we'll be using Selenium, a browser automation tool that closely replicates a genuine browser environment.
Amazon, like other major sites, has well-established systems for distinguishing traffic sources. These systems can often tell whether a request comes from, let's say, a plain Python application rather than a full browser – so using Selenium helps your requests resemble standard browsing environment.
Therefore, if you attempt to send a basic HTTP request with something like the requests library, it’s likely that you will receive a response with a status code beginning with 500 or 400, indicating that the request is unsuccessful.
One of the most common ways to navigate these restrictions is to send a request with headers that a browser normally uses. This is usually sufficient enough, but to get consistent results, it does require using different headers from time to time.
Another way to scrape Amazon more consistently is to use a browser automation tool such as Selenium.
Selenium is typically used to manipulate a browser window programmatically – it can be used in different use cases, such as automated testing, or in our case, a web scraping project.
In this case, the benefit of using a tool like Selenium is that it reduces the need to manually emulate browser behavior. Choosing between crafting requests manually and a browser automation tool like Selenium is mostly a matter of preference. Still, we’ll be using Selenium and the Chrome web driver for this tutorial.
We’ll also be using webdriver-manager, which automatically installs the necessary drivers for using the browser automation.
Lastly, pandas will be used to store our extracted data to a file.
So, to start, you will need to run the command below to install the mentioned dependencies.
pip install selenium webdriver-manager pandasScraping Amazon Best Sellers Data
With our environment ready, we can start with setting up the code needed to scrape Amazon.
In this tutorial, we’ll extract product data with these attributes from any given Amazon Best Sellers page:
Product title
Product price
The URL of the product.
While you can find whichever Best Sellers page you’d like to scrape, in this tutorial, we’ll be scraping items from the Kitchen and Dining category on Amazon.
Open up the previously created Python file and create a variable named URL. Then, store the retrieved Best Sellers page URL in that variable.
URL = "https://www.amazon.com/Best-Sellers-Home-Kitchen-Kitchen-Dining/zgbs/home-garden/284507/ref=zg_bs_unv_home-garden_2_289668_1"Setting up Selenium
Next, it’s necessary to write a function to set up the Selenium browser.
You’ll need to import what’s necessary for Selenium by adding these imports to your Python file:
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from selenium.webdriver.remote.webelement import WebElement
from selenium.common.exceptions import NoSuchElementException
from selenium import webdriver
from webdriver_manager.chrome import ChromeDriverManagerSome of these will be used later on in the code, but most are necessary for initializing the chrome web driver.
Then, create a function called init_chrome_driver. It will be used for initializing the driver for the automated browser, which will then be used to scrape the Best Seller data.
The function should look like this:
def init_chrome_driver() -> webdriver.Chrome:
chrome_options = Options()
chrome_options.add_argument("--headless")
service = Service(ChromeDriverManager().install())
driver = webdriver.Chrome(service=service, options=chrome_options)
return driverIn the function code, we’re utilizing the previously installed webdriver-manager package. Usually, you’d have to manually download a Selenium webdriver and point your code to the path in your device. However, this package allows for a simpler setup.
The argument –headless passed to the chrome_options object indicates that the browser window will not be visible upon running the code. This allows for automations in non-desktop environments, such as servers. In this case, it’s used for a cleaner scraping process.
Implementing product parsing function
Next, implement HTML parsing using Selenium.
Create another function called get_products_from_page. This function will retrieve and parse all elements in a page for a given URL.
def get_products_from_page(url: str, driver: webdriver.Chrome) -> List[dict]:After that, check the HTML source code on the Amazon page to see how you can select all products from a page. Once you open up an Amazon Best Sellers page in your browser, right-click on a product and click Inspect Element. This should open up the HTML of the Amazon page.
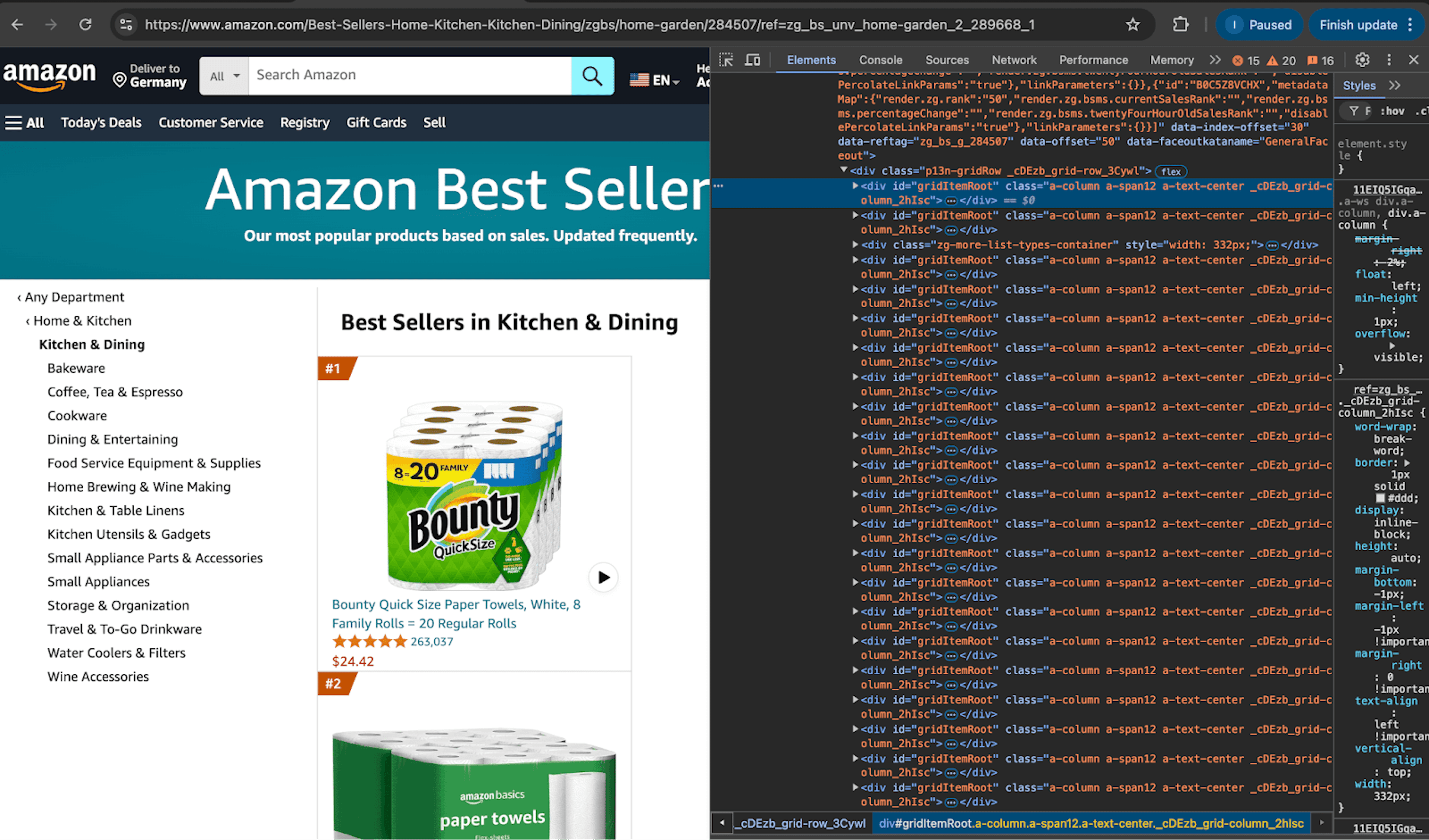
HTML of Amazon Best Sellers page
Notice that each div tag that represents a product, has an ID of gridItemRoot . We can use this ID to select every product from the page.
Add these lines to the created function:
driver.get(url)
time.sleep(3)
product_elements = driver.find_elements(By.ID, "gridItemRoot")
parsed_products = []Using the Selenium driver to open the page for the URL, wait for it to load by using time.sleep (or using other methods in our waiting until element is visible in Selenium tutorial), and select all elements with the find_elements method.
After this, we can create another function called parse_product_data as so:
def parse_product_data(product: WebElement) -> dict:We’ll get back to implementing this function in a bit, but for now, let’s iterate over the retrieved product elements in the get_products_from_page function, use the newly defined function to parse them and save them to our created list.
We should also wrap the parse_product_page function in a try/except block in case some parsing goes wrong.
The code should look like this:
for product in product_elements:
try:
parsed_product = parse_product_data(product)
except Exception as e:
print(f"Unexpected error when parsing data for product: {e} Skipping..")
continue
else:
parsed_products.append(parsed_product)After this, you’ll have the full get_products_from_page function implemented. Here’s how it should look:
def get_products_from_page(url: str, driver: webdriver.Chrome) -> List[dict]:
driver.get(url)
time.sleep(3)
product_elements = driver.find_elements(By.ID, "gridItemRoot")
parsed_products = []
for product in product_elements:
try:
parsed_product = parse_product_data(product)
except Exception as e:
print(f"Unexpected error when parsing data for product: {e} Skipping..")
continue
else:
parsed_products.append(parsed_product)
return parsed_productsExtracting values from HTML
Then you will need to implement the previously declared parse_product_data function. This function should perform data extraction from the HTML of a single product and return it as a dictionary.
You can use the same procedure as before by right-clicking on the product on the Amazon page and selecting Inspect Element.
If you take a look at the HTML again, you can see that the element containing the title of the item has a class named cDEzbp13n-sc-css-line-clamp-3_g3dy1. Let’s use that to find the title of the product:
title_element = product.find_element(
By.CLASS_NAME, "_cDEzb_p13n-sc-css-line-clamp-3_g3dy1"
)
title = title_element.text if title_element else NoneWe can do the same for the price and the URL. The URL element contains a class name of a-link-normal, whereas the price has a class named cDEzbp13n-sc-price_3mJ9Z. Let’s use these values to get the URL and price of the product.
url_element = product.find_element(By.CLASS_NAME, "a-link-normal")
url = url_element.get_attribute("href") if url_element else None
try:
price_element = product.find_element(
By.CLASS_NAME, "_cDEzb_p13n-sc-price_3mJ9Z"
)
except NoSuchElementException:
price_element = None
price = price_element.text if price_element else NoneSince some items can be out of stock, it’s best to capture the NoSuchElementException, in case the price doesn’t exist.
After that, return these values as a single dictionary:
return {
"title": title,
"url": url,
"price": price,
}The full code for the function should look like this:
def parse_product_data(product: WebElement) -> dict:
title_element = product.find_element(
By.CLASS_NAME, "_cDEzb_p13n-sc-css-line-clamp-3_g3dy1"
)
title = title_element.text if title_element else None
url_element = product.find_element(By.CLASS_NAME, "a-link-normal")
url = url_element.get_attribute("href") if url_element else None
try:
price_element = product.find_element(
By.CLASS_NAME, "_cDEzb_p13n-sc-price_3mJ9Z"
)
except NoSuchElementException:
price_element = None
price = price_element.text if price_element else None
return {
"title": title,
"url": url,
"price": price,
}Saving to CSV
After we have the data, we should store it in a well-known format, such as CSV, for later data retention purposes.
We can use pandas here, by converting our retrieved list of dictionaries to a pandas dataframe and using it to create a CSV file.
To do so, implement a function called save_to_csv.
def save_to_csv(data: List[dict]) -> None:
df = pd.DataFrame(data)
df.to_csv("amazon_products.csv")Putting it together
After implementing all three functions, we can combine them to have a working Python application that scrapes Amazon Best Sellers.
Let’s implement a main function that looks like this:
def main():
driver = init_chrome_driver()
try:
products = get_products_from_page(URL, driver)
finally:
driver.quit()
save_to_csv(products)
if __name__ == "__main__":
main()In the main function, we initialize the Selenium driver, use it to retrieve the products and save them to a CSV file.
The get_products_from_page function is wrapped inside a try/finally block, to shutdown the driver in case of any exception that might occur.
Reviewing Full Code
Putting everything together, here’s the full code:
import time
from typing import List
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from selenium.webdriver.remote.webelement import WebElement
from selenium.common.exceptions import NoSuchElementException
from selenium import webdriver
from webdriver_manager.chrome import ChromeDriverManager
import pandas as pd
URL = "https://www.amazon.com/Best-Sellers-Home-Kitchen-Kitchen-Dining/zgbs/home-garden/284507/ref=zg_bs_unv_home-garden_2_289668_1"
def init_chrome_driver() -> webdriver.Chrome:
chrome_options = Options()
chrome_options.add_argument("--headless")
service = Service(ChromeDriverManager().install())
driver = webdriver.Chrome(service=service, options=chrome_options)
return driver
def parse_product_data(product: WebElement) -> dict:
title_element = product.find_element(
By.CLASS_NAME, "_cDEzb_p13n-sc-css-line-clamp-3_g3dy1"
)
title = title_element.text if title_element else None
url_element = product.find_element(By.CLASS_NAME, "a-link-normal")
url = url_element.get_attribute("href") if url_element else None
try:
price_element = product.find_element(
By.CLASS_NAME, "_cDEzb_p13n-sc-price_3mJ9Z"
)
except NoSuchElementException:
price_element = None
price = price_element.text if price_element else None
return {
"title": title,
"url": url,
"price": price,
}
def get_products_from_page(url: str, driver: webdriver.Chrome) -> List[dict]:
driver.get(url)
time.sleep(3)
product_elements = driver.find_elements(By.ID, "gridItemRoot")
parsed_products = []
for product in product_elements:
try:
parsed_product = parse_product_data(product)
except Exception as e:
print(f"Unexpected error when parsing data for product: {e} Skipping..")
continue
else:
parsed_products.append(parsed_product)
return parsed_products
def save_to_csv(data: List[dict]) -> None:
df = pd.DataFrame(data)
df.to_csv("amazon_products.csv")
def main():
driver = init_chrome_driver()
try:
products = get_products_from_page(URL, driver)
finally:
driver.quit()
save_to_csv(products)
if __name__ == "__main__":
main()Easier way of scraping Amazon Best Sellers data
Scraping Amazon data using the described method can work as a short-term solution, but it won’t do any good in the long run. There's a good chance Amazon will limit your IP address if you scrape data too often. To keep things running smoothly, you'll need to rotate through different IP addresses regularly, which is difficult without additional resources.
Luckily, the Amazon Best Sellers Scraper API is a solution that’s designed to solve this very issue. Similar to the Amazon Reviews and Amazon Books Scraper APIs, the main goal is to simplify the data collection and delivery in bulk.
As detailed in the API’s documentation, it includes various scraping features, such as:
Searching for a product based on a query
Listing product pricing data
Getting already parsed results
Getting results for a specified geo-location
Plus, you can use the API to extract data with much less effort than using a browser automation tool and parsing it yourself – even if it concerns Amazon ASIN data.
Here’s an example of how to get Amazon Best Sellers data using Amazon Best Sellers Scraper API:
import requests
from pprint import pprint
# Structure payload.
payload = {
"source": "amazon_bestsellers",
"domain": "com",
"query": "284507",
"render": "html",
"start_page": 1,
"parse": True,
}
# Get response
response = requests.request(
"POST",
"https://realtime.oxylabs.io/v1/queries",
auth=("USERNAME", "PASSWORD"),
json=payload,
)
# Print prettified response to stdout.
pprint(response.json())As you can see, we used the category ID from the URL we used before in the payload of the request. We then had to simply define the rest of the parameters to get the fully parsed result from the API. Because the parse parameter was set to True , the response looks like this:
Amazon Best Sellers Scraper API response
Instead of going through the hassle of parsing each HTML element, Amazon Scraper API provides fully parsed results that you can immediately use.
Let’s also add the pandas library and the method we used before to the script to save the pre-parsed data to a CSV file.
Here’s what it can look like:
import requests
import pandas as pd
# Structure payload.
payload = {
"source": "amazon_bestsellers",
"domain": "com",
"query": "284507",
"render": "html",
"start_page": 1,
"parse": True,
}
# Get response
response = requests.request(
"POST",
"https://realtime.oxylabs.io/v1/queries",
auth=("USERNAME", "PASSWORD"),
json=payload,
)
# Get results
data = response.json()
results = data["results"][0]["content"]["results"]
# Save to CSV
df = pd.DataFrame(results)
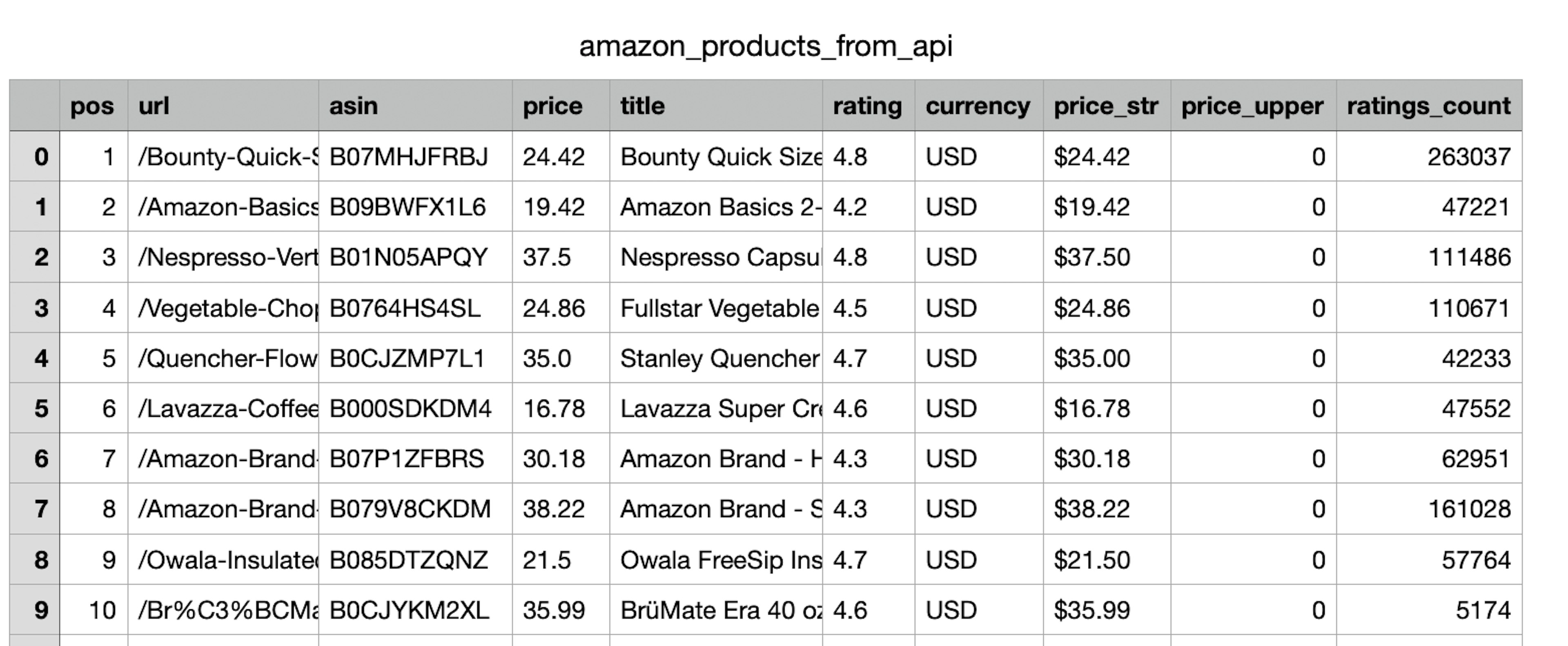
df.to_csv("amazon_products_from_api.csv")If we compare the two generated CSV files, we can see that the data retrieved from the Amazon Scraper API includes more fields without any additional effort.
Here’s what the data from the first script looks like:

And to compare, here’s what the data looks like when retrieved from the Amazon Scraper API:
But that doesn't concern only the Best Sellers page – to have a broader amount of possibilities, you can take a look at the Amazon Scraper API, which allows you to scrape and parse various types of data from Amazon, including Search, Offer listings, and more.
Conclusion
While there are several ways of scraping Amazon Best Sellers pages, using Python and Selenium can be a bit of a challenge if you're not using top Amazon Scraper APIs. It achieves its purpose, but requires some effort to get it done. You do need to manually set up the browser automation to get it to work, as well as parse out the fields from the retrieved HTML.
But, you can always consider using a ready-made scraping tool such as Amazon Best Sellers Scraper API that achieves the goal of scraping data from Amazon Best Sellers sites with minimal effort.
About the author

Akvilė Lūžaitė
Former Technical Copywriter
With a background in Linguistics and Design, Akvilė focuses on crafting content that blends creativity with strategy.
All information on Oxylabs Blog is provided on an "as is" basis and for informational purposes only. We make no representation and disclaim all liability with respect to your use of any information contained on Oxylabs Blog or any third-party websites that may be linked therein. Before engaging in scraping activities of any kind you should consult your legal advisors and carefully read the particular website's terms of service or receive a scraping license.
Related articles

Cheerio vs. Puppeteer: Which Should You Use for Web Scraping?

Shinthiya Nowsain Promi
2026-06-23



List Crawling in Python: Tools, Tips, and Techniques

Danielė Virinaitė
2026-06-17
177M+ high-quality proxies for anonymity online
Access the largest proxy pool to enhance your privacy online.

Get the latest news from data gathering world
Scale up your business with Oxylabs®
Proxies
Advanced proxy solutions
Data Collection
Datasets
Resources
Innovation hub
177M+ high-quality proxies for anonymity online
Access the largest proxy pool to enhance your privacy online.