175M+ ethically sourced IPs built for the highest reliability.
High-speed, cost-effective proxies built for any scraping workload.
Premium static residential proxies from trusted ASNs for most difficult targets.
Dedicated IPs from premium ASNs for demanding scraping.

AI-powered proxy solution for optimized web scraping performance.

20M+ IP addresses from real mobile devices for precise targeting.

Free Chrome proxy manager extension that works with any proxy provider.

Free Android proxy manager app that works with any proxy provider.

Free community-driven tools to improve your web scraping projects.
Web Scraper API
All-in-one web data collection platform for every stage of web scraping.
Fast Search API
Ultra-fast organic search results scraper tailored for AI workflows.
Headless Browser
Advanced browser automation solution for AI agents and scraping.
AI Studio
A suite of AI-powered tools for various scraping projects.

Documentation
All features, parameters, and integration details, backed by code samples in every coding language.
Tutorials, samples, and guides.
Latest fixes and features.







![]() AI Summary:
AI Summary:
Want to learn the best ways to scrape web data using PHP today? This hands-on tutorial covers the essentials, from sending simple requests to extracting and storing data, and shows how PHP remains a practical option for straightforward scraping tasks.
PHP is a general-purpose scripting language and one of the most popular options for web development. For example, WordPress, the most common content management system to create websites, is built using PHP.
PHP offers various building blocks required to build a web scraper, although it can quickly become an increasingly complicated task. Conveniently, there are many open-source libraries that can make web scraping with PHP more accessible.
This article will guide you through the step-by-step process of writing various web scraping PHP routines that can extract public data from static and dynamic web pages.
For your convenience, we also prepared a shorter video version of this PHP web scraping tutorial that covers the key points.

Can PHP be used for web scraping?
In short, yes — PHP scraping is absolutely possible. In fact, the rest of this tutorial will walk you through exactly how effective PHP web scraping processes should look in practice.
As a widely used programming language, PHP offers all the core capabilities needed for web scraping. It can send HTTP requests, receive responses, parse them, and extract data from formats like HTML, JSON, and XML. Once collected, that data can be stored in virtually any desired format.
More importantly, PHP has a mature ecosystem of scraping libraries that significantly streamline development. Tools like Guzzle, Goutte, and RoachPHP make programming PHP for scraping both efficient and scalable. Additionally, PHP supports headless browser automation and allows you to implement essential scraping features such as proxies, queues, and retry logic.
It’s also worth noting that PHP remains one of the most widely used server-side programming languages, which adds a strong layer of reliability and community support. Having been around since the 1990s and now in version 8+, PHP benefits from decades of real-world usage, extensive documentation, and well-tested solutions to common problems.
That said, a more nuanced question is whether PHP is the right tool for your specific scraping case. While PHP excels in simplicity and ease of use, this can come with trade-offs. For highly complex, dynamic websites, especially those heavily reliant on JavaScript, other ecosystems may offer performance advantages.
PHP web scraping libraries
When you start with PHP web scraping, you’ll notice that most scraping tools work together. Typically, one library is used to fetch web pages, while another handles parsing and extracting structured data. As you move to more complex, JavaScript-heavy sites, you’ll also need a browser automation tool.
As you’ll see below, PHP has a strong ecosystem of open source libraries and tools, making it much easier to build your own PHP scraping tool or a more advanced web scraper.
HTTP clients
These libraries handle sending HTTP requests and receiving responses:
Guzzle: Modern HTTP client with async support.
Symfony HTTP Client: Symfony's HTTP client component.
cURL: PHP's built-in extension for HTTP requests.
Httpful: Simple, chainable alternative to cURL.
HTML/XML parsers
For handling parsing responses and extracting data, use one of the following:
Symfony DomCrawler: Powerful DOM traversal.
DiDOM: Fast parser with CSS Selectors & XPath.
hQuery: Lightweight parser with jQuery-like selectors.
Embed: Extracts data via OEmbed/OpenGraph.
These older open source libraries are generally not recommended for new projects, but can still be useful in certain cases:
PHP Simple HTML DOM Parser: Simple jQuery-like syntax.
QueryPath: jQuery-style HTML/XML manipulation.
PHPQuery: jQuery port for PHP.
Complete scraping frameworks
If you want an all-in-one PHP scraping tool, here are some frameworks that combine multiple components into a single solution:
Goutte: Combines HTTP client + DOM crawler.
RoachPHP: Modern Scrapy-inspired framework.
PHPScraper: Simple all-in-one scraping solution.
PHP-Spider: Supports BFS/DFS crawling.
Ultimate Web Scraper: Handles complex scraping, incl. WebSockets.
Browser automation
For dynamic websites, these tools allow you to control a real browser and render JavaScript-heavy pages:
Symfony Panther: Real browser automation (Google Chrome/Firefox).
PHP-webdriver: Selenium WebDriver bindings.
PuPHPeteer: Puppeteer (Chromium) wrapper for PHP.
Together, these scraping tools and libraries cover the full spectrum of PHP web scraping, from simple HTTP requests to building a scalable, production-grade web scraper.
Installing prerequisites
Before you start with PHP programming for scraping, you’ll need to set up a basic environment. Don’t worry — this is a one-time setup and only takes a few minutes.
To begin, make sure you have both PHP and Composer installed.
This guide uses PHP 8.3, so it’s a good idea to use that version or newer. If you’re running an older version, consider upgrading, not just for new features, but also for better support and security.
If you’re on Windows, you can visit this link to download PHP from the official builds page or install it using Chocolatey. After installing Chocolatey, run the following command from your terminal:
choco install phpOn macOS, you can install PHP with Homebrew:
brew install phpOnce installed, confirm everything is working by checking the version:
php --versionNext, install Composer. It’s the standard dependency manager for PHP, used to install and manage the required packages.
To install Composer, you can visit this link for downloads and instructions.
If you prefer using a package manager, the installation is easier. On macOS, run the following command:
brew install composerOn Windows (with Chocolatey):
choco install composerVerify the installation:
composer --versionNow, it’s time to set up the PHP programming environment for your PHP programming project.
For this, all you need is a code editor. Many developers prefer Visual Studio Code because it’s lightweight and has a wide range of extensions. Visit the official downloads page and run the installer.
For a better PHP programming environment setup, consider installing the PHP Intelephense extension.
You can use the integrated terminal within Visual Studio Code to run commands and keep your PHP programming environment simple.
For the examples in this article, create a new project directory and install Composer inside it:
mkdir php-scraping-demo
cd php-scraping-demo
composer init --no-interaction --require="php:^8.3"Making an HTTP GET request
The first step in PHP web scraping is to load the page you want to scrape web data from.
In this article, we’ll be using books.toscrape.com. It's a dummy bookstore for practicing how to web scrape.
When you open a website in your browser, it sends an HTTP GET request to a web server. The server then responds with HTML, which the browser shows as a web page.
In PHP, we can handle the browser, and send that same HTTP GET request directly to retrieve the HTML. One of the simplest ways to do this in PHP is by using the built-in file_get_contents function. It accepts a file path or URL and returns the contents as a string.
Create a new file, save it as native.php, and open it in Visual Studio Code. Enter the following code to load the HTML page and print the HTML to the terminal:
<?php
$html = file_get_contents('https://books.toscrape.com/');
echo $html;Execute this code from the terminal:
php native.phpThis will output the entire HTML of the page.
For very simple PHP web scraping tasks, file_get_contents() can be enough. However, it comes with limitations: there’s no control over headers, custom user agents, POST requests, redirects, timeouts, or structured error handling.
Because of this, many developers prefer using cURL, which offers much more flexibility in how requests are sent when you scrape web data with PHP. The next section covers this in more detail.
PHP web scraping with cURL: A hands-on guide
For small scraping tasks, file_get_contents() is enough. However, it is very limited in what it can do.
Hypertext Transfer Protocol, or HTTP, is more complex. Apart from GET, there are other types of requests, the second most common being POST. For example, when you submit a form on a web page, that data is typically sent as a POST request.
Moreover, URL requests include headers that carry additional data, such as user agent strings that identify the browser.
Other areas where file_get_contents() falls short include handling errors, setting timeouts, or even following a simple redirect. A better alternative is cURL.
cURL (client for URL) is an alternative to file_get_contents() that provides more functionality and a much greater control over HTTP requests.
Sending GET and POST requests with PHP cURL
Sending GET requests is straightforward and can be handled with ease, while giving you more control when doing PHP web scraping with cURL.
<?php
// Initialize the cURL session
$ch = curl_init();
// Set the URL to scrape
curl_setopt($ch, CURLOPT_URL, "https://books.toscrape.com");
// Set to true to return the result instead of outputting it
curl_setopt($ch, CURLOPT_RETURNTRANSFER, true);
// Set the HTTP method to GET, POST, PUT, DELETE, etc. Optional here, the default is GET
curl_setopt($ch, CURLOPT_HTTPGET, true);
// Follow redirects
curl_setopt($ch, CURLOPT_FOLLOWLOCATION, true);
// Send the request and store the result
$response = curl_exec($ch);
// Check for cURL errors
if ($response === false) {
throw new RuntimeException('cURL error: ' . curl_error($ch));
}
echo 'Response: ' . $response . PHP_EOL;
// Close the cURL session is not needed in PHP 8.0+ as handles are automatically closedSave this file as curl_get_example.php and run it to see the results:
php curl_get_example.phpEven when you are not using POST, this extra setup gives you much more control, which becomes important as soon as you want to scrape web data in more advanced scenarios.
To send a POST request, only the following changes are needed:
set CURLOPT_POST to true
set CURLOPT_POSTFIELDS with the data you want to send
Here is a practical example:
<?php
$ch = curl_init();
// Set the URL to where you want to send a POST request
curl_setopt($ch, CURLOPT_URL, "https://httpbin.org/post");
// Set to true to return the result instead of outputting it
curl_setopt($ch, CURLOPT_RETURNTRANSFER, true);
// Set the HTTP method to POST.
curl_setopt($ch, CURLOPT_POST, true);
// Set POST data (form fields)
curl_setopt($ch, CURLOPT_POSTFIELDS, http_build_query([
'custname' => 'John Doe'
]));
// Follow redirects
curl_setopt($ch, CURLOPT_FOLLOWLOCATION, true);
// Send the POST request and store the result
$response = curl_exec($ch);
// Check for cURL errors
if ($response === false) {
throw new RuntimeException('cURL error: ' . curl_error($ch));
}
echo 'Response: ' . $response . PHP_EOL;The code remains the same, regardless of whether the server returns HTML or JSON.
Setting Headers and User Agents in cURL
Some websites can’t be scraped until you add specific headers. A typical example is when sending JSON data with a POST request — you need to inform the server about the format of the data.
Many websites also rely on the browser the request is coming from. In such cases, your request may be interrupted if you don’t identify as a valid browser. This is where setting a user agent becomes necessary.
If you need to add headers and a user agent, you can set the following options:
// Set the HTTP headers
curl_setopt($ch, CURLOPT_HTTPHEADER, [
'Accept: text/html,application/xhtml+xml',
'Accept-Language: en-US,en;q=0.9',
'Cache-Control: no-cache',
]);
// Set the User-Agent header
curl_setopt($ch, CURLOPT_USERAGENT, 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/146.0.0.0 Safari/537.36
');These options make requests more realistic and configurable for PHP web scraping. However, they do not guarantee that a website will allow scraping. In such cases, you may still need proxies, browser automation, or an API-based approach.
Scraping techniques: Regular expressions vs. DOM parsing in PHP
In the previous section, you retrieved raw HTML from the server. The next step in PHP scraping is to locate the data you need and extract it.
There are two common scraping techniques: Regular Expressions (RegEx) and DOM parsing. Both can work, but they operate differently and are suited to different use cases.
Parsing HTML with PHP regular expressions
Regular expressions are part of almost every programming language and provide an efficient way to locate specific text.
One important thing to note is that matching rules are rather strict. As a result, it works best when you want to extract information that does not vary in structure.
Since RegEx handling is part of the core PHP, you don't need to install anything. Simply use preg_match_all(), which performs a global regular expression match.
There are many tools, such as https://regexr.com/, that can help you build a RegEx pattern.
The following code finds all the prices from books.toscrape.com and prints them:
<?php
$html = file_get_contents('https://books.toscrape.com/');
// RegEx pattern to match price values within <p class="price_color"> tags
$pattern = '/<p class="price_color">([^<]+)<\/p>/i';
// extract all price values using regex pattern matching
preg_match_all($pattern, $html, $matches);
// prints the extracted price values
print_r($matches[1]);Save this file as regex_get_price.php and run it using php regex_get_price.php to see an array of all prices on the page.
As you can imagine, extracting only prices is not very useful. A more practical example is to extract all links from the page:
<?php
$html = file_get_contents('https://books.toscrape.com/');
// Regex pattern to match href attribute values within <a> tags
$pattern = '/<a[^>]+href="([^"]+)"/i';
preg_match_all($pattern, $html, $matches);
print_r($matches[1]);This example is useful for data scraping PHP workflows, as it allows you to collect links and then visit those pages to extract additional data.
Why DOM parsing outperforms Regex for web scraping
The main drawback of RegEx is that it treats HTML as simple text files. The result is that regex patterns are very fragile. This makes patterns fragile — they can break with small changes, such as an extra space or an additional tag like <span> to display the same text.
DOM parsing, on the other hand, treats HTML like a browser does. This makes it more reliable for PHP web scraping, as it can handle small structural changes without breaking. It’s also unaffected by whitespace or line breaks.
Here is the same example of extracting prices using DOM parsing:
<?php
$html = file_get_contents('https://books.toscrape.com/');
// Prevent warnings from malformed HTML
libxml_use_internal_errors(true);
// Create a new DOMDocument instance
$dom = new DOMDocument();
// Load the HTML into the DOMDocument
$dom->loadHTML($html);
// Create an XPath DOM object
$xpath = new DOMXPath($dom);
// XPath expression to select price elements
$xpath_expression = '//p[contains(@class, "price_color")]';
// Get all matching price elements
$prices = $xpath->query($xpath_expression);
// Print all prices
foreach ($prices as $price) {
echo trim($price->textContent) . PHP_EOL;
}To summarize, for quick, one-off patterns, RegEx can be enough. But for more robust PHP scraping and scalable projects, DOM parsing is usually the better choice.
Web scraping in PHP with Goutte
Goutte used to be a very popular library for PHP scraping, especially for handling static websites. You will still find it used across many PHP web scraping tutorials. Goutte, pronounced “goot,” is a wrapper around Symfony components such as BrowserKit, CssSelector, DomCrawler, and HttpClient.
Important update: Goutte is now deprecated. The author notes that in its final versions, Goutte was essentially a wrapper over HttpBrowser from the Symfony BrowserKit component. Existing code using Goutte\Client can be replaced with Symfony\Component\BrowserKit\HttpBrowser, and it will continue to work.
Symfony itself is a set of reusable PHP components. The components used by Goutte can be used directly. The same components used by Goutte can be used directly, but Goutte simplifies writing PHP scraping code.
To install Goutte, create a directory where you intend to keep the source code. Navigate to that directory and run:
composer init --no-interaction --require="php:^8.3"
composer require fabpot/goutteMigration note: Since Goutte is deprecated, new code should use the following Symfony packages:
composer require symfony/browser-kit
composer require symfony/dom-crawler
composer require symfony/css-selector
composer require symfony/http-client
composer updateThe first command creates the composer.json file. The second adds the entry for Goutte, downloads and installs the required files. It also creates a composer.lock file.
The composer update command ensures all dependency files are up to date.
Sending HTTP requests with Goutte
The main class used in PHP web scraping with Goutte is the Client, which acts like a browser. Start by creating an object of this class:
$client = new Client();Migration note: Since Goutte is deprecated, you should now create the client like this:
use Symfony\Component\BrowserKit\HttpBrowser;
$client = new HttpBrowser();This object can then be used to send a request. The method to send the request is conveniently called request. It takes the HTTP method and the target URL, and returns an instance of the DOM crawler:
$crawler = $client->request('GET', 'https://books.toscrape.com');This sends a GET request to the HTML page. To print the entire HTML of the page, you can call the html() method.
Putting together everything we’ve built so far, this is how the code file looks like:
<?php
require 'vendor/autoload.php';
use Goutte\Client;
$client = new Client();
$crawler = $client->request('GET', 'https://books.toscrape.com');
echo $crawler->html();Save this new PHP file as books.php and run it from the terminal:
php books.phpThis will print the entire HTML of the page, which is the starting point for PHP scraping. Next, you need to locate specific elements.
Locating HTML elements via CSS Selectors
Goutte uses the Symfony CssSelector component. It facilitates the use of CSS Selectors in locating HTML elements.
The CSS Selector can be supplied to the filter method. For example, to print the title of the page, enter the following line to the books.php file:
echo $crawler->filter('title')->text();Note that title is the CSS Selector that selects the <title> node from the HTML.
In this particular case, text() returns the text contained in the HTML element. In the earlier example, we’ve used html() to return the entire HTML of the selected element.
If you prefer to work with XPath, use the filterXPath() instead. The following line of code produces the same output:
echo $crawler->filterXPath('//title')->text();Now, let’s move on to extracting book titles and prices.
Extracting the elements
Open https://books.toscrape.com in Chrome, right-click on a book and select Inspect. Before we write the PHP scraping code, we need to analyze the HTML of our page first.
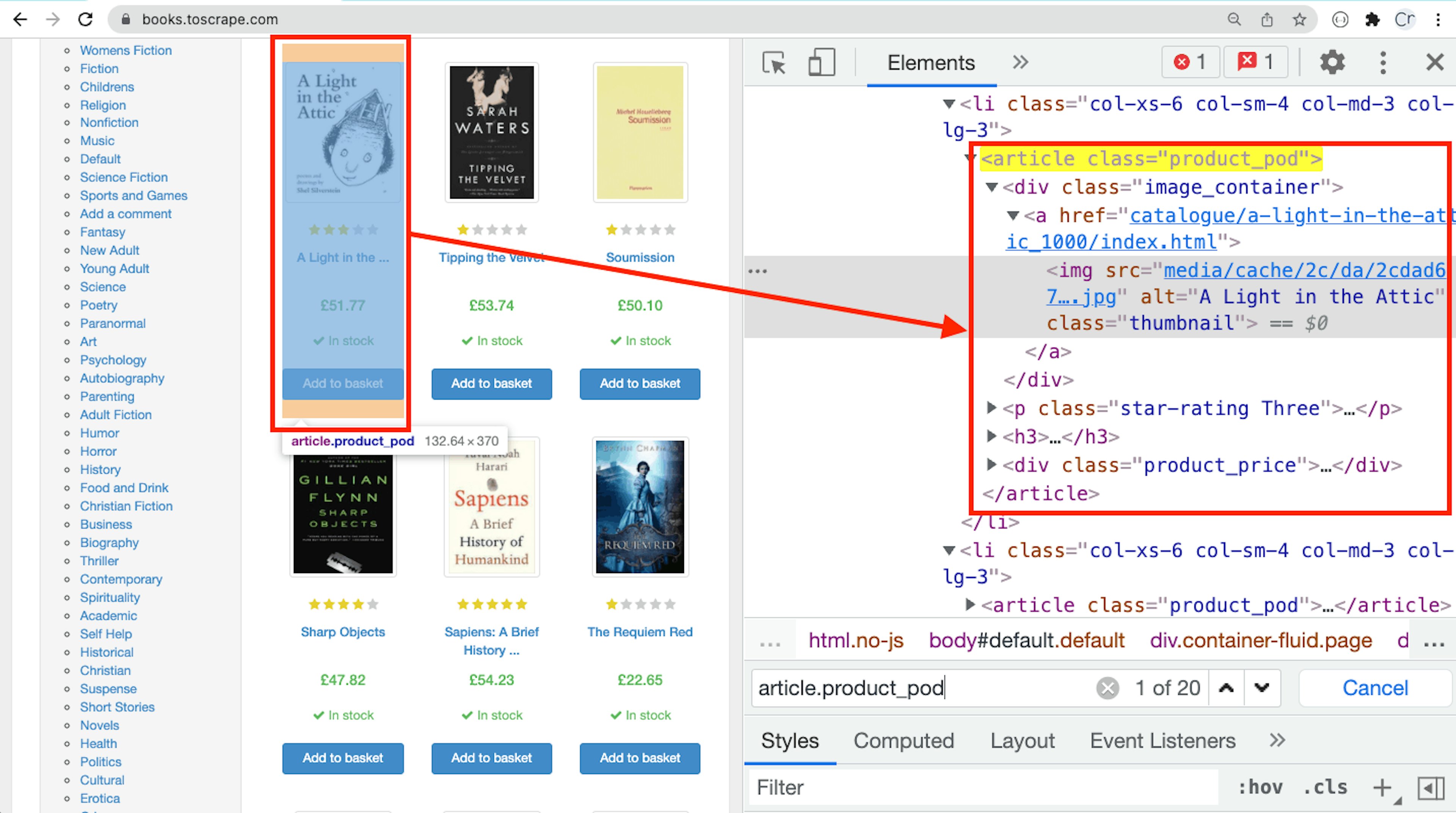
The books are located in the <article> tags
Upon examining the HTML of the target web page, we can see that each book is contained in an article tag with the class product_pod. Here, the CSS Selector would be .product_pod.
In each article tag, the complete book title is located in the thumbnail image as an alt attribute value. The CSS Selector for the book title would be .image_container img.
Finally, the CSS Selector for the book price would be .price_color.
To get all of the titles and prices from this page, first we need to locate the container and then run the each loop.
In this loop, an anonymous function will extract and print the title along with the price as follows:
function scrapePage($url, $client){
$crawler = $client->request('GET', $url);
$crawler->filter('.product_pod')->each(function ($node) {
$title = $node->filter('.image_container img')->attr('alt');
$price = $node->filter('.price_color')->text();
echo $title . "-" . $price . PHP_EOL;
});
}The functionality of web data extraction is isolated in a function. This function keeps the extraction logic separate, making it easier to extend and maintain your PHP scraper.
Handling pagination
At this stage, our PHP web scraping script only processes one page, performing data extraction from a single URL. In real web scraping scenarios, you’ll need to handle multiple pages.
In this particular site, the pagination is controlled by a “Next” link (button). The CSS Selector for the Next link is .next > a.
Update the scrapePage function:
try {
$next_page = $crawler->filter('.next > a')->attr('href');
} catch (InvalidArgumentException) { //Next page not found
return null;
}
return "https://books.toscrape.com/catalogue/" . $next_page;This code uses the CSS Selector to locate the Next button and to extract the value of the href attribute, returning the relative URL of the subsequent page. On the last page, this line of code will raise the InvalidArgumentException.
If the next page is found, this function will return its URL. Otherwise, it will return null.
From this point onwards, we’ll be initiating each scraping cycle with a different URL. This will make converting relative URLs to absolute URLs easier when scraping PHP data across multiple pages.
Lastly, we can use a while loop to call this function:
$client = new Client();
$nextUrl = "https://books.toscrape.com/catalogue/page-1.html";
while ($nextUrl) {
$nextUrl = scrapePage($nextUrl, $client);
}The web scraping code is almost complete.
Writing data to a CSV file
The final step in PHP scraping is storing the extracted data. PHP’s built-in fputcsv function can be used to export the data to a CSV file.
First, open the CSV file in write or append mode and store the file handle in a variable.
Next, send the variable to the scrapePage function. Then, call the fputcsv function for each book to write the title and price in one row.
Lastly, after the while loop, close the file by calling fclose.
The final code file will be as follows:
<?php
require 'vendor/autoload.php';
use Goutte\Client;
function scrapePage($url, $client, $file)
{
$crawler = $client->request('GET', $url);
$crawler->filter('.product_pod')->each(function ($node) use ($file) {
$title = $node->filter('.image_container img')->attr('alt');
$price = $node->filter('.price_color')->text();
fputcsv($file, [$title, $price]);
});
try {
$next_page = $crawler->filter('.next > a')->attr('href');
} catch (InvalidArgumentException) { //Next page not found
return null;
}
return "https://books.toscrape.com/catalogue/" . $next_page;
}
$client = new Client();
$file = fopen("books.csv", "a");
$nextUrl = "https://books.toscrape.com/catalogue/page-1.html";
while ($nextUrl) {
echo "<h2>" . $nextUrl . "</h2>" . PHP_EOL;
$nextUrl = scrapePage($nextUrl, $client, $file);
}
fclose($file);Run this file from the terminal:
php books.phpThis will create a books.csv file with 1,000 rows of data.
Web scraping with Guzzle, XML, and XPath
Guzzle is a PHP library that sends HTTP requests to web pages to get a response. In other words, Guzzle is a PHP HTTP client that allows you to access server responses for PHP data extraction.
Guzzle is especially useful when you want a clear separation between the request layer and the parsing layer.
For parsing the response, the key concepts are XML and XPath. XML stands for eXtensible Markup Language, while XPath stands for XML Path and is used for navigating and selecting XML nodes.
HTML files are very similar to XML files. In some cases, a parser is needed to handle minor differences and make HTML more compliant with XML standards. Importantly, some parsers can process even poorly formatted HTML.
These parsers make the necessary adjustments so you can use XPath to query and navigate the HTML, which is essential for efficient web data extraction.
Setting up a Guzzle Project
To install Guzzle, create a directory where you intend to keep the source code. Navigate to the directory and enter these commands:
composer init --no-interaction --require="php:^8.3"
composer require guzzlehttp/guzzleIn addition to Guzzle, we’ll also use a library for parsing HTML code. There are several PHP libraries available, such as simple HTML DOM Parser and Symfony DOMCrawler.
In this tutorial, Symfony DOMCrawler is used because its syntax is similar to Goutte, making it easier to apply what you’ve already learned. Another advantage is that it handles invalid HTML well.
Install DomCrawler using:
composer require symfony/dom-crawlerThese commands will download all the necessary files. The next step is to create a new file and save it as scraper.php.
Sending HTTP requests with Guzzle
Similar to Goutte, the most important class in Guzzle is Client. Create a new file scraper.php and enter the following lines of PHP code:
<?php
require 'vendor/autoload.php';
use GuzzleHttp\Client;
use Symfony\Component\DomCrawler\Crawler;Now, you are ready to create an object of the Client class:
$client = new Client();The client object can then be used to send a request. The method to send the request is conveniently called request. It takes two parameters — the HTTP method and the target URL, and returns a response:
$response = $client->request('GET', 'https://books.toscrape.com');From this response, extract the web page's HTML:
$html = $response->getBody()->getContents();
echo $html;In this example, the response contains HTML code. If you are working with a web page that returns JSON, you can save it and stop the script. The next steps apply only if the responses contain HTML or XML data.
Continuing, we will use the DomCrawler to extract specific elements from this web page.
Locating HTML elements via XPath
Import the Crawler class and create an instance:
use Symfony\Component\DomCrawler\Crawler;You can create an instance of the crawler class as follows:
$crawler = new Crawler($html);Now we can use the filterXPath method to extract any XML node. For example, the following line prints only the title of the page:
echo $crawler->filterXPath('//title')->text();Note: In XML, everything is a node — an element is a node, an attribute is a node, and text is also a node. The filterXPath method returns a node. Therefore, to extract the text from an element, even if you use the text() function in XPath, you still need to call the text() method to extract the text as a string.
In other words, both of the following lines return the same value:
echo $crawler->filterXPath('//title')->text();
echo $crawler->filterXPath('//title/text()')->text();Now, let's move on to extracting the book titles and prices.
Extracting the elements
Before we write PHP scraping code, let’s start by analyzing the HTML of the page.
Open https://books.toscrape.com in Chrome, right-click on a book and select Inspect.
The books are located in <article> elements with the class attribute set to product_pod. The XPath to select these nodes is:
//*[@class="product_pod"]In each article tag, the complete book title is located in the thumbnail image as an alt attribute value. The XPath for the book title and book price is:
//*[@class="image_container"]/a/img/@alt
//*[@class="price_color"]/text()To get all of the titles and prices from this page, you first need to locate the container and then use a loop to iterate over each element containing the needed data.
In this loop, an anonymous function extracts and prints the title along with the price, as shown below:
$crawler->filterXPathfilterXpath('//*[@class="product_pod"]')->each(function ($node) {
$title = $node->filterXPathfilterXpath('.//*[@class="image_container"]/a/img/@alt')->text();
$price = $node->filterXPath('.//*[@class="price_color"]/text()')->text();
echo $title . "-" . $price . PHP_EOL;
});This is a simple demonstration of web data extraction using Guzzle and DomCrawler parsers. Note that this method will not work with dynamic websites. These websites use JavaScript that cannot be handled by DomCrawler. In such cases, you will need to use Symfony Panther.
The next step after extracting data is to save it.
Saving extracted data to a file
To store the extracted data, you can modify the script to use built-in PHP functions and create a CSV file.
Write the following PHP code:
$file = fopen("books.csv", "a");
$crawler->filterXPathfilterXpath('//*[@class="product_pod"]')->each(function ($node) use ($file) {
$title = $node->filterXPathfilterXpath('.//*[@class="image_container"]/a/img/@alt')->text();
$price = $node->filterXPath('.//*[@class="price_color"]/text()')->text();
fputcsv($file, [$title, $price]);
});
fclose($file);This code, when run, will save all the extracted data to the books.csv file.
Web scraping with Symfony Panther
Dynamic websites use JavaScript to render content. For such websites, Goutte is not a suitable option. In these cases, the solution is to use a browser to render the page.
Headless browsers are browsers that are invoked by code that operate in the background without a user interface. These browsers can be full browsers such as Google Chrome, or lightweight alternatives such as Chromium.
Similar to standard browsers, they are capable of fully rendering web pages, including the execution of all JavaScript code used by dynamic websites.
In PHP, this can be done using another Symfony component — Panther. Panther is a standalone PHP library for web data extraction using real browsers. It uses the W3C standard protocol and can drive browsers such as Chrome and Firefox.
In this section, we’ll scrape quotes and authors from https://quotes.toscrape.com/js. This is a dummy website that uses JavaScript for rendering data, making it useful for learning how to scrape dynamic pages.
Installing Panther and its dependencies
To install Panther, open the terminal, navigate to your project directory, and run:
composer init --no-interaction --require="php:^8.3"
composer require symfony/panther
composer updateThese commands create a new composer.json file and install Panther.
You will also need a browser and a driver. Common browser options include Chrome and Firefox, which are often already installed.
The driver for your browser can be downloaded using any of the package managers.
On Windows:
choco install chromedriverOn macOS:
brew install chromedriverSending HTTP requests with Panther
Panther uses the Client class to expose the get() method. This method can be used to load URLs, or, in other words, send HTTP requests.
The first step is to create the Chrome Client. Create a new PHP file and add:
<?php
require 'vendor/autoload.php';
use \Symfony\Component\Panther\Client;
$client = Client::createChromeClient();The $client object can then be used to load the web page:
$client->get('https://quotes.toscrape.com/js/');This loads the page in a headless Chrome browser.
Locating HTML elements via CSS Selectors
To locate the elements, first get a reference for the crawler object. You can do this by waiting for a specific element using the waitFor() method.
$crawler = $client->waitFor('.quote');This waits for the element to appear and then returns a crawler instance.
The rest of the process is similar to Goutte, as both use Symfony’s CssSelector component.
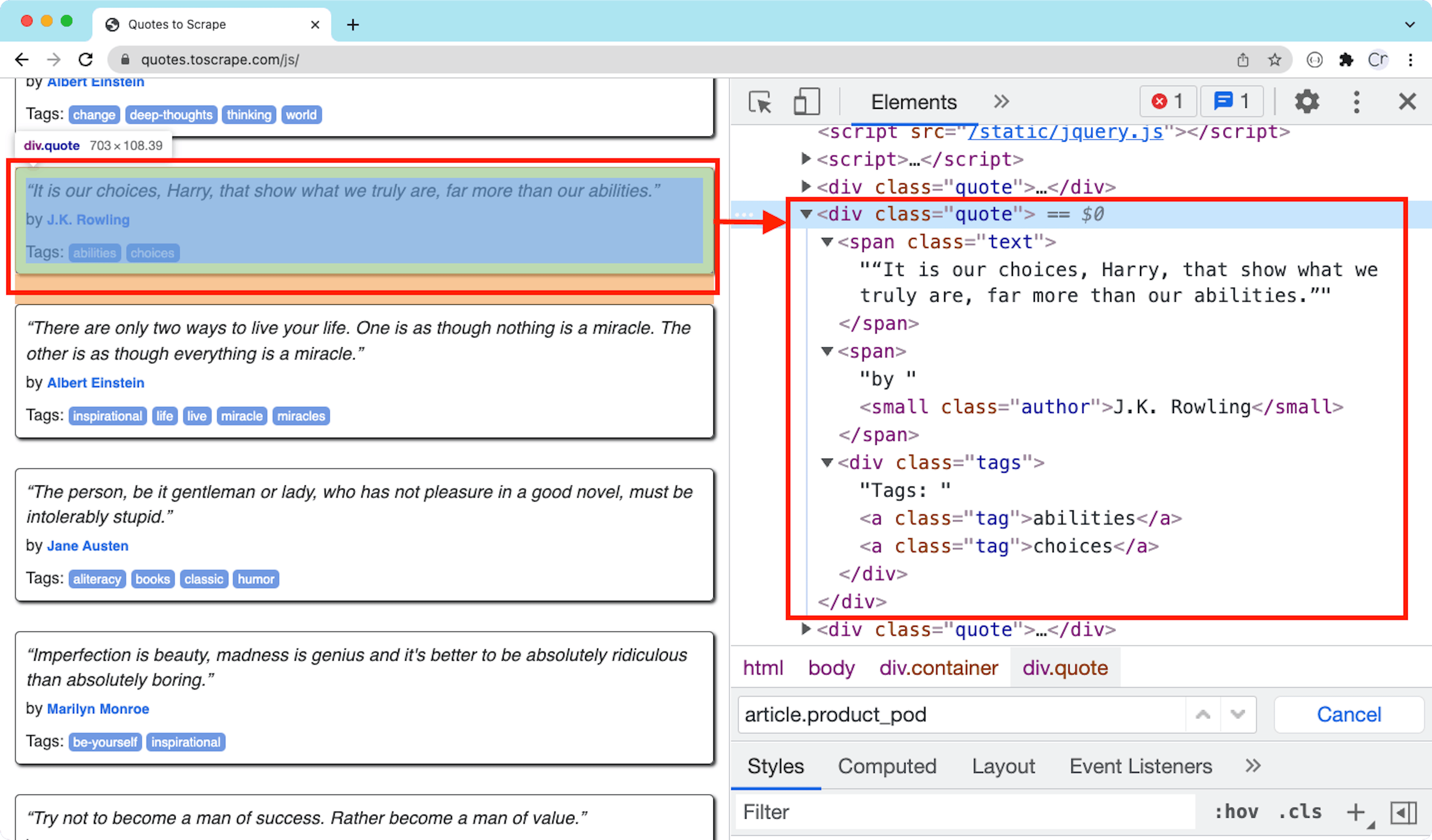
The container HTML element of a quote
First, the filter method is supplied with a CSS Selector to get all of the quote elements. Then, an anonymous function is applied to each quote to extract the author and the text:
$crawler->filter('.quote')->each(function ($node) {
$author = $node->filter('.author')->text();
$quote = $node->filter('.text')->text();
echo $author." - ".$quote;
});Handling pagination
To scrape data from all of the subsequent pages of this website, you can simply click the “Next” button. To follow links, the clickLink() method can be used. This method works directly with the link text.
On the last page, the link won’t be present, and calling this method will throw an exception. This can be handled using a try-catch section:
while (true) {
$crawler = $client->waitFor('.quote');
…
try {
$client->clickLink('Next');
} catch (Exception) {
break;
}
}Writing data to a CSV file
Writing the data to a CSV file is straightforward when using PHP’s fputcsv() function. Open the CSV file before the while loop, write each row using fputcsv(), and close the file after the loop.
Putting everything together, here is the final code:
$file = fopen("quotes.csv", "a");
while (true) {
$crawler = $client->waitFor('.quote');
$crawler->filter('.quote')->each(function ($node) use ($file) {
$author = $node->filter('.author')->text();
$quote = $node->filter('.text')->text();
fputcsv($file, [$author, $quote]);
});
try {
$client->clickLink('Next');
} catch (Exception) {
break;
}
}
fclose($file);Once you execute this PHP scraper, the script will generate a quotes.csv file with all the quotes and authors, completing the PHP scraping process and making the data ready for further analysis.
PHP data extraction and scraping best practices
In this article, we have gone through various methods of building a PHP web scraping workflow. However, it is important to build a scraper that is robust, can manage common bot detection, and does not break easily with minor changes to websites.
Respect robots.txt and terms of service
Most sites publish a robots.txt, and many also publish a terms of services page. It goes without saying that these terms should be respected.
robots.txt are hidden files meant for scrapers or crawlers. You can use one of the many PHP libraries to parse these files or write a few lines of your own to ensure your web scraping PHP setup follows the rules.
Implement rate limiting
If you send too many requests too quickly, websites will likely restrict you. The solution is to implement rate limiting. Here is a simple example:
<?php
foreach ($urls as $url) {
scrapePage($url);
// Wait between 0.8 and 1.5 seconds
usleep(random_int(800000, 1500000));
}Rotate User-Agents to avoid detection
A default or missing user agent is one of the easiest ways for a server to identify bot traffic. Many libraries covered in this article, including cURL, allow you to send custom user agents:
curl_setopt($ch, CURLOPT_USERAGENT, 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/146.0.0.0 Safari/537.36');You can maintain a pool of user agents and rotate them with each request.
Use proxies for large-scale scraping
For smaller projects, sending all the requests from a single IP address may be enough. However, when you scale your PHP web scraping, you will likely be restricted unless you use a pool of proxies.
Oxylabs offers a variety of proxy services, such as data center proxies, residential proxies, and a ready-to-use Web Scraper API. Choose the solution that fits your needs.
Handle errors gracefully
Your scrapers will inevitably encounter failures, such as client errors (4xx) or server errors (5xx).
Client errors often include 429 (too many requests) or 404 (not found), while servers may return 500 errors.
Your code should be able to log the errors and retry later if the page is important for PHP data extraction.
Most modern libraries can help capture errors. Here is an example with Guzzle:
<?php
require 'vendor/autoload.php';
use GuzzleHttp\Client;
use GuzzleHttp\Exception\RequestException;
$client = new Client(['timeout' => 15]);
try {
$response = $client->request('GET', 'https://books.toscrape.com/');
echo (string) $response->getBody();
} catch (RequestException $e) {
error_log('Request failed: ' . $e->getMessage());
}You can then decide whether to retry or skip failed requests.
Cache responses to avoid repeated requests
You can reduce the number of requests sent to a web server by avoiding repeated requests to the same page. For more advanced caching, you can use tools like Redis or similar solutions.
Use headless browsers only when necessary
Headless browsers can load any site, but since they are complete browsers, they consume more resources, take longer to parse, and place additional load on the target server.
In most cases, you only need the HTML and not images or CSS. Sometimes, the data you need may be hidden in JSON. It’s always a good idea to understand the target website before building your PHP scrape tool.
Monitor for website structure changes
Website structures change frequently, should account for this when building your scraper PHP solution.
Your measures can be as simple as not relying on RegEx and building sturdier CSS or XPath selectors. Even if this does not work, you can log which selector was not found and then log it for examination later.
Simple measures include avoiding fragile RegEx patterns and using more stable CSS or XPath selectors. If a selector fails, you can log it for examination later.
PHP web scraping with APIs and AI-powered extraction
Writing code for smaller-scale projects works well, but as soon as you move to large-scale PHP web scraping, you may face issues such as slower request rates, IP interruptions, and increased maintenance.
For easier web data scraping, consider integrating Oxylabs Web Scraper API integration with PHP. This scraper API automatically handles proxies, CAPTCHA, and JavaScript rendering out of the box.
When working with PHP, one key advantage is that integration remains simple. You make an HTTP POST request, and all the heavy lifting is handled by the scraper API behind the scene.
For many websites, the integrations are ready to use. Here is an example optimized for Amazon:
<?php
$ch = curl_init('https://realtime.oxylabs.io/v1/queries');
curl_setopt($ch, CURLOPT_RETURNTRANSFER, true);
curl_setopt($ch, CURLOPT_POST, true);
curl_setopt($ch, CURLOPT_USERPWD, 'USERNAME:PASSWORD');
curl_setopt($ch, CURLOPT_HTTPHEADER, ['Content-Type: application/json']);
curl_setopt($ch, CURLOPT_POSTFIELDS, json_encode([
'source' => 'amazon_product',
'query' => 'B07FZ8S74R',
'geo_location' => '90210',
'parse' => true,
]));
$response = curl_exec($ch);
echo $response;With minimal changes, the same API works for Google Search:
curl_setopt($ch, CURLOPT_POSTFIELDS, json_encode([
'source' => 'google_search',
'query' => 'adidas',
'geo_location' => 'California,United States',
'parse' => true,
]));For other sources, you can change the source parameter to universal. See the documentation for more options.
When to use a scraping API vs. building your own PHP scraper
If your target website is small and straightforward, or you want full control over scraping logic, going with your own scraper may still be worth it.
For most PHP scraping use cases, however, using a scraper API simplifies the process. It reduces complexity, minimizes maintenance, and allows you to focus on data scraping and extraction rather than infrastructure.
| Scenario | Web Scraper API | Your own scraper stack |
|---|---|---|
| Proxy and IP rotation | Proxies and routing handled seamlessly | Choose providers, rotate IPs, and manage failures |
| CAPTCHAs & interruptions | Automatic CAPTCHA handling and smart retries built in | Write code to handle errors, retries, and CAPTCHA workarounds |
| JavaScript-heavy sites | Rendering support is built-in | Maintain and run headless browsers manually |
| Integration with PHP | Simple with any library that can send HTTP POST requests | Handle request logic, parsing, retries, and maintain infrastructure |
| Long-term maintenance | All taken care of | Manual maintenance of browsers, proxies, monitoring, and updates |
Conclusion
PHP is still a practical language for web scraping. It's well supported, with a wide range of libraries for different scenarios.
For quickly fetching a page or a file, file_get_contents() does the job.
If you need more control over headers, user agents, and redirects, cURL is the next step. If you need a more structured HTTP client, Guzzle is a strong option. For selector-based crawling, Goutte was a popular choice, but new projects should use Symfony HttpBrowser and related components.
If target websites require rendering, Symfony Panther can handle it using real browsers such as Chrome, Chromium, and Firefox.
If your challenge is infrastructure, an API-based approach such as our Web Scraper API can be the perfect solution.
Lastly, if you want to learn more about web scraping PHP or other languages, check out similar articles, such as web scraping with C++, JavaScript, Java, R, Ruby, Golang, cURL in PHP, and Python on our blog. And don’t forget to try our general-purpose scraping tool Web Scraper API for free.
Frequently asked questions
What is web scraping with PHP?
Web scraping is, in simple terms, the automatic collection of data in a structured format such as JSON or CSV from web pages, without manual copy-paste. It is most commonly done using code.
While it is possible to use a number of programming languages to achieve this, almost everything can be done using PHP. PHP makes the most sense if you already have another project running in PHP where this data needs to be processed further, or if your programming skills are stronger in PHP.
How do you scrape a website using PHP and cURL?
What is the difference between Goutte and Guzzle for PHP scraping?
Can PHP handle large-scale web data extraction?
What is Symfony Panther and how is it used for scraping?
Is PHP or Python better for web scraping?
Is web scraping with PHP legal?
How can I avoid getting interrupted while scraping websites with PHP?
Can PHP scrape JavaScript-rendered websites?
About the author

Augustas Pelakauskas
Former Senior Technical Copywriter
Augustas Pelakauskas was a Senior Technical Copywriter at Oxylabs. Coming from an artistic background, he is deeply invested in various creative ventures - the most recent being writing. After testing his abilities in freelance journalism, he transitioned to tech content creation. When at ease, he enjoys the sunny outdoors and active recreation. As it turns out, his bicycle is his fourth-best friend.
All information on Oxylabs Blog is provided on an "as is" basis and for informational purposes only. We make no representation and disclaim all liability with respect to your use of any information contained on Oxylabs Blog or any third-party websites that may be linked therein. Before engaging in scraping activities of any kind you should consult your legal advisors and carefully read the particular website's terms of service or receive a scraping license.
Related articles

Cheerio vs. Puppeteer: Which Should You Use for Web Scraping?

Shinthiya Nowsain Promi
2026-06-23



List Crawling in Python: Tools, Tips, and Techniques

Danielė Virinaitė
2026-06-17
Web Scraper API for smooth scraping
Enjoy efficient web scraping while avoiding CAPTCHA and IP restrictions.

Get the latest news from data gathering world
Scale up your business with Oxylabs®
Proxies
Advanced proxy solutions
Data Collection
Datasets
Resources
Innovation hub
Web Scraper API for smooth scraping
Enjoy efficient web scraping while avoiding CAPTCHA and IP restrictions.