175M+ ethically sourced IPs built for the highest reliability.
High-speed, cost-effective proxies built for any scraping workload.
Premium static residential proxies from trusted ASNs for most difficult targets.
Dedicated IPs from premium ASNs for demanding scraping.

AI-powered proxy solution for optimized web scraping performance.

20M+ IP addresses from real mobile devices for precise targeting.

Free Chrome proxy manager extension that works with any proxy provider.

Free Android proxy manager app that works with any proxy provider.

Free community-driven tools to improve your web scraping projects.
Web Scraper API
All-in-one web data collection platform for every stage of web scraping.
Fast Search API
Ultra-fast organic search results scraper tailored for AI workflows.
Headless Browser
Advanced browser automation solution for AI agents and scraping.
AI Studio
A suite of AI-powered tools for various scraping projects.

Documentation
All features, parameters, and integration details, backed by code samples in every coding language.
Tutorials, samples, and guides.
Latest fixes and features.






![]() AI Summary:
AI Summary:
This tutorial provides a comprehensive guide to web scraping in R, detailing environment setup and the use of the `rvest` package. It covers extracting data from both static and JavaScript-rendered web pages, including parsing HTML with CSS/XPath, handling tables, and exporting results to CSV.
In the dynamic digital business landscape, web scraping is a vital method used to extract data and gain insights. Whether using an in-house web scraper or a solution like SERP scraper, public data acquisition undoubtedly enhances various business prospects. Learning a new programming language for web data mining, especially with R, can be challenging for beginners compared to Python. However, you shouldn't overlook R since it's geared towards statisticians and offers powerful libraries that make R for web scraping highly efficient.
This web scraping tutorial simplifies web scraping in R and covers the basics, from scraping static pages to dynamic websites that use JavaScript for content rendering. We'll explore R programming for web scraping using both rvest and RSelenium, with practical examples of data scraping in R throughout. For your convenience, the original tutorial is also available in video format:

Installing requirements
The installation of the required components can be broken down into two sections – Installing R and RStudio and Installing the libraries.
1. Installing R and RStudio
The first stage is to prepare the development environment for R. Two components will be needed – R and RStudio.
To download and install R, visit this page. Installing the base distribution is enough.
Alternatively, you can use package managers such as Homebrew for Mac or Chocolatey for Windows.
For macOS, run the following:
brew install rFor Windows, run the following:
choco install r.projectNext, download and install RStudio by visiting this page. The free version, RStudio Desktop, is enough.
If you prefer package managers, the following are the commands for macOS using Homebrew and for Windows using Chocolatey:
For macOS, run the following:
brew install --cask rstudioFor Windows, run the following:
choco install r.studioOnce installed, launch RStudio.
Launching RStudio
2. Installing required libraries
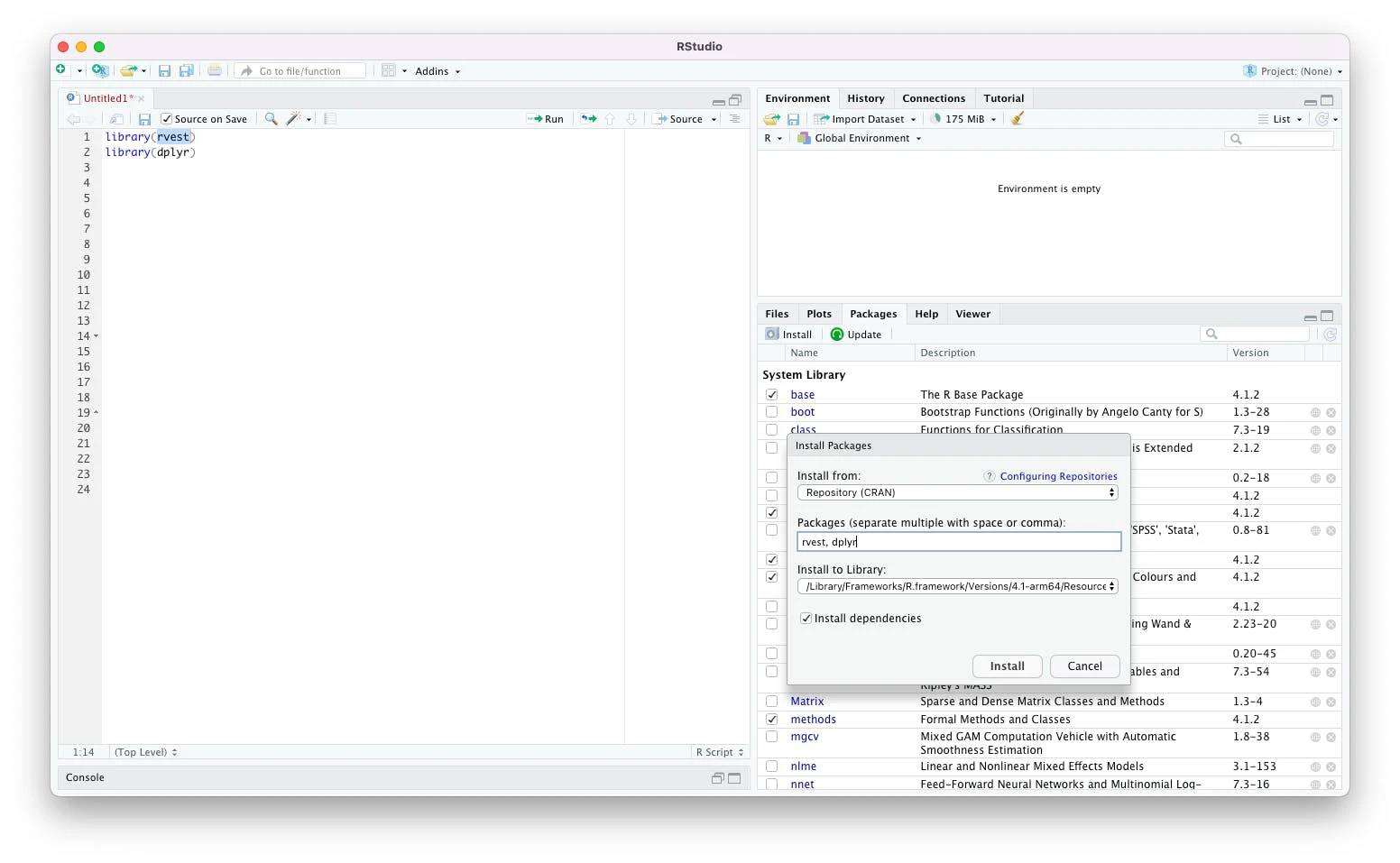
There are two ways to install the required libraries. The first is using the user interface of RStudio. Locate the Packages tab in the Help section. Select the Packages tab to activate the Packages section. In this section, click the Install button.
The Install Package dialog is now open. Enter the package names in the text box for Packages. Lastly, click Install.
For the first section of the tutorial, the package that we'll use is rvest. We also need the dplyr package to allow the use of the pipe operator. Doing so makes the code easier to read.
Enter these two package names, separated with a comma, and click Install.

Installing libraries
The second way is to install these packages using a console. To proceed, run the following commands in the console:
install.packages("rvest")
install.packages("dplyr")The libraries are now installed. The next step is to scrape data.
Web scraping with rvest
The most popular library for automatic data extraction from any public web page in R is rvest. It provides functions to access a public web page and query-specific elements using CSS selectors and XPath. The library is a part of the Tidyverse collection of packages for data science, meaning that the coding conventions are the same across all of Tidyverse's libraries.
Let's initiate a web scraping operation using rvest. The first step in any R scraping workflow is to send an HTTP GET request to a target web page. We'll be working with many rvest examples.
This section is written as an rvest cheat sheet. You can jump to any section that you need help with.
1. Sending a GET request
Begin with loading the rvest library by entering the following in the Source area:
library(rvest)All of the commands entered in the source areas can be executed by simply placing the cursor in the desired line, selecting it, and then clicking the Run button on the top right of the Source area.
Alternatively, depending on your operating system, you can press Ctrl + Enter or Command + Enter.
In this example, we'll scrape publicly available data from a web page that lists ISO Country Codes. The hyperlink can be stored in a variable:
link = "https://en.wikipedia.org/wiki/List_of_ISO_3166_country_codes"To send an HTTP GET request to this page, a simple function read_html() can be used.
This function needs one mandatory argument: a path or a URL. Note that this function can also read an HTML code string:
page = read_html(link)The function above sends the HTTP GET request to the URL, retrieves the web page, and returns an object of html_document type.
The html_document object contains the desired public data in the raw HTML document. Many rvest functions are available to query and extract specific HTML file elements.
Note that if you need to use a rvest proxy, run the following to set the proxy in your script:
Sys.setenv(http_proxy="http://proxyserver:port")2. Controlling timeouts
The read_html doesn't provide any way to control the time out. To handle rvest read_html timeouts, you can use the httr library. The GET function from this library and tryCatch can help you handle the time-out errors.
Alternatively, you can use the session object from rvest as follows:
library(httr)
url <- "https://quotes.toscrape.com/api/quotes?page=1"
page<-read_html(GET(url, timeout(10))) # Method 1
page <- session(url,timeout(10)) #Method 23. Parsing HTML content
The rvest package provides a convenient way to select HTML elements using CSS and XPath selectors.
Select the elements using html_elements() function. The syntax of this function is as follows:
page %>% html_elements(css="")
page %>% html_elements(xpath="")An important aspect to note is the plural variation, which will return a list of matching elements. There's a singular variation of this function that returns only the first matching HTML element:
page %>% html_element()If the selector type isn't specified, it's assumed to be a CSS Selector. For example, this Wiki web page contains the desired public data in a table.

An HTML markup of the table
The HTML markup of this table is as follows:
<table class="wikitable sortable jquery-tablesorter">The only class needed to create a unique selector is the sortable class. It means that the CSS selector can be as simple as table.sortable. Using this selector, the function call will be as follows:
htmlElement <- page %>% html_element("table.sortable")It stores the resulting html_element in a variable htmlElement.
The next step of our web scraping in R project is to convert the public data contained in html_element into a data frame.
4. Getting HTML element attributes with rvest
In the previous section, we discussed selecting an element using the html_element function.
This function makes it easy to use the rvest select class. For example, if you want to select an element that has the class heading, all you need to write is the following line of code:
heading <- page %>% html_element(".heading")Another use case is the rvest div class. If you want to use rvest to select a div, you can use something like:
page %>% html_element("div")If you also use rvest to select div with a class:
page %>% html_element("div.heading")You may come across to select HTML file nodes is the html_node() function. Note that this way of selecting HTML nodes in rvest is now obsolete. Instead, you should be using html_element() and html_elements().
From this element, you can extract text by calling the function html_text() as follows:
heading %>% html_text()Alternatively, if you're looking for an attribute, you can use the rvest html_attr function. For example, the following code will extract the src attribute of an element:
element %>% html_attr("src")You can use the rvest read table function if you're working with HTML tables. This function takes an HTML that contains <table> elements and returns a data frame.
html_table(htmlElement)You can use this to build rvest extract table code:
page %>% html_table()As you can see, we can send the whole page and rvest reads tables, all of them.
5. Scraping a JavaScript page with rvest
If the page you are scraping uses JavaScript, there are two ways to scrape it. The first method is to use RSelenium. This approach is covered at length in the next section of this article.
In this section, let's talk about the second approach. This approach involves finding the hidden API that contains the data.
This is an excellent example to learn how rvest JavaScript works. This site uses infinite scroll.
Open this site in Chrome, press F12, and go to the network tab. Once we have network information, we can implement rvest infinite scrolling easily.
Scroll down to load more content and watch the network traffic. You'll notice that every time a new set of quotes are loaded, a call to the URL is sent, where the page number keeps on increasing.
Another thing to note is that the response is returned in JSON. There's an easy way to build a rvest JSON parser.
First, read the page.Then look for the <p> tag. This will contain the JSON data in text format.
page <- read_html("https://quotes.toscrape.com/api/quotes?page=1")
json_as_text <- page %>% html_element("p") %>% html_text()To parse this JSON text into an R object, we need to use another library – jsonlite:
library(jsonlite)Now, use the fromJSON method to convert this rvest JSON text into a native R object.
r_object <- json_as_text %>% fromJSON()You can use a loop to parse rvest javascript for a page with infinite scroll. In the following example, we're running this loop ten times:
for (x in 1:10) {
url <- paste("https://quotes.toscrape.com/api/quotes?page=",x, sep = '')
page <- read_html(url)
# parse page to get JSON
}You can modify this code as per your specific requirements.
6. Saving data to a data frame
Data frames are fundamental data storage structures in R. They resemble matrices but feature some critical differences. Data frames are tightly coupled collections of variables, where each column can be of a different data type. It's a powerful and efficient way of storing a large dataset, and they integrate well with broader data management workflows.
Most data and statistical analysis methods require data stored in data frames.
To convert the data stored in html_element, the function html_table can be used:
df <- html_table(htmlEl, header = FALSE)The variable df is a data frame.
Note the use of an optional parameter header = FALSE. This parameter is only required in certain scenarios. In most cases, the default value of TRUE should work.
For the Wiki table, the header spawns two rows. Out of these two rows, the first row can be discarded, making it a three-step process.
The first step is to disable the automatic assignment of headers, which we have already done.
The next step is to set the column names with the second row:
names(df) <- df[2,]3. The third step is to delete the first two rows from the body.
df = df[-1:-2,]It's now ready for further analysis.
7. Exporting data frame to a CSV file
Finally, the last step to scrape data from the HTML document is to save the data frame to a CSV file.
To export it, use the write.csv function. This function takes two parameters – the data frame instance and the name of the CSV file:
write.csv(df, "iso_codes.csv")The function will export the data frame to a file iso_codes.csv in the current directory.
How to download image using rvest
Images are easy to download with rvest. This involves a three-step process:
Downloading the page;
Locating the element that contains the URL of the desired image and extracting the URL of the image;
Downloading the image.
Let's begin by importing the packages.
library(rvest)
library(dplyr)We'll download the first image from the Wikipedia page in this example. Download the page using the read_htmlI() function and locate the <img> tag that contains the desired image.
url = "https://en.wikipedia.org/wiki/Eiffel_Tower"
page <- read_html(url)To locate the image, use the CSS selector ".infobox-image img".
image_element <- page %>% html_element(".infobox-image img")The next step is to get the actual URL of the image, which is embedded in the src attribute. The rvest function html_attr() comes handy here.
image_url <- image_element %>% html_attr("src")This URL is a relative URL. Let's convert this to an absolute URL. This can be done easily using one of the rvest functions — url_absolute() as follows:
image_url <- url_absolute(image_url, url)Finally, use another rvest function — download() to download the file as follows:
download.file(image_url, destfile = basename("paris.jpg"))Web scraping in R: rvest vs. BeautifulSoup
The most popular languages for public data analysis are Python and R. To analyze data, first, we need to collect publicly available data. The most common technique for collecting public data is web scraping. Thus, Python and R are suitable languages for web scraping, especially when the data needs to undergo analysis.
In this section, we'll quickly look at rvest vs beautifulsoup.
The BeautifulSoup library in Python is one of the most popular web scraping libraries because it provides an easy-to-use wrapper over the more complex libraries such as lxml. Rvest is inspired by BeautifulSoup. It's also a wrapper over more complex R libraries such as xml2 and httr.
Both Rvest and BeautifulSoup can query the document DOM using CSS selectors.
Rvest provides additional functionality to use Xpath, which BeautifulSoup lacks. BeautifulSoup instead uses its functions to compensate for the lack of XPath. Note that XPath allows traversing up to the parent node, while CSS cannot do that.
BeautifulSoup is only a parser. It's helpful for searching elements on the page but can't download web pages. You would need to use another library such as Requests for that.
Rvest, on the other hand, can fetch the web pages.
Eventually, the decision of rvest vs BeautifulSoup would depend on your familiarity with the programming language. If you know Python, use BeautifulSoup. If you know R, use Rvest for your web scraping in R projects.
Web scraping with RSelenium
While the rvest library works for most static websites, some dynamic websites use JavaScript to render the content. For such websites, a browser-based rendering solution comes into play.
Selenium is a popular browser-based rendering solution that can be used with R. Among the many great features of Selenium are taking screenshots, scrolling down pages, clicking on specific links or parts of the page, and inputting any keyboard stroke onto any part of a web page. It's the most versatile when combined with classic web scrapers and web crawling techniques.
The library that allows dynamic page scraping is RSelenium. It can be installed using the RStudio user interface as explained in the first section of this article, or by using the following command:
install.packages("RSelenium")Once the package is installed, load the library using the following command:
library(RSelenium)The next step is to start the Selenium server and browser.
1. Starting Selenium
There are two ways of starting a Selenium server and getting a client driver instance.
The first is to use RSelenium only, while the second way is to start the Selenium server using Docker and then connect to it using RSelenium. Let's delve deeper into how the first method works.
For the first method, download and install ChromeDriver.
RSelenium allows to setup the Selenium server and browser using the following function calls:
rD <- rsDriver(browser="chrome", port=9515L, verbose=FALSE)
remDr <- rD[["client"]]This will download the required binaries, start the server, and return an instance of the Selenium driver.
Alternatively, you can use Docker to run the Selenium server and connect to this instance.
Install Docker and run the following command from the terminal.
docker run -d -p 4445:4444 selenium/standalone-firefoxThis will download the latest Firefox image and start a container. Apart from Firefox, Chrome and PhantomJS can also be used.
Once the server has started, enter the following in RStudio to connect to the server and get an instance of the driver:
remDr <- remoteDriver(
remoteServerAddr = "localhost",
port = 4445L,
browserName = "firefox"
)
remDr$open()These commands will connect to Firefox running in the Docker container and return an instance of the remote driver. If something isn't working, examine both the Docker logs and RSelenium error messages.
2. Working with elements in Selenium
Note that after visiting a website and before moving on to the parsing functions, it might be essential to let a considerable amount of time pass. There's a possibility that data won't be loaded yet, and the entire parsing algorithm will crash. The specific functions could be employed that wait for the particular HTML elements to load fully.
The first step is navigating the browser to the desired page. As an example, we'll scrape the name, prices, and stock availability for all books in the science fiction genre. The target is a dummy book store for practicing web scraping.
To navigate to this URL, use the navigate function:
remDr$navigate("https://books.toscrape.com/catalogue/category/books/science-fiction_16")To locate the HTML elements, use findElements() function. This function is flexible and can work with CSS Selectors, XPath, or even with specific attributes, such as an id, name, name tag, etc. For a detailed list, see the official documentation.
In this example, we'll work with XPath.
The book titles are hidden in the alt attribute of the image thumbnail.

Locating book titles
The XPath for these image tags will be //article//img. The following line of code will extract all of these elements:
titleElements <- remDr$findElements(using = "xpath", "//article//img")To extract the value of the alt attribute, we can use the getElementAttribute() function. However, in this particular case we have a list of elements.
To extract the attribute from all elements of the list, a custom function can be applied using the sapply function of R:
titles <- sapply(titleElements, function(x){x$getElementAttribute("alt")[[1]]})Note that this function will return the attribute value as a list. That's why we're using [[1]] to extract only the first value.
Moving on to extracting price data, the following is an HTML markup of the HTML element containing price:
<p class="price_color">£37.59</p>The XPath to select this will be //*[@class='price_color']. Also, this time we'll use the getElementText() function to get the text from the HTML element. This can be done as follows:
pricesElements <- remDr$findElements(using = "xpath", "//*[@class='price_color']")
prices <- sapply(pricesElements, function(x){x$getElementText()[[1]]})Lastly, the lines that extract stock availability will be as follows:
stockElements <- remDr$findElements(using = "xpath", "//*[@class='instock availability']")
stocks <- sapply(stockElements, function(x){x$getElementText()[[1]]})3. Creating a data frame
At this point, there are three variables. Every variable is a list that contains a required data point.
Data points can be used to create a data frame:
df <- data.frame(titles, prices, stocks)Once the data frame is created, it can be used for further analysis.
Moreover, it can be easily exported to CSV with just one line:
write.csv(df, "books.csv")You can click here to find the complete code used in this article for your convenience.
Conclusion
Web scraping with R is a relatively uncomplicated and straightforward process for anyone familiar with the R language or programming in general. Whether your goal is R data scraping for analytics or extracting data in R to build a one-off dataset, the right library makes scraping data in R efficient and reliable. For most static web pages, the rvest library provides enough functionality, and you shouldn't run into major setbacks. However, if any kind of dynamic elements come into play, a typical HTML extraction won't be up to the task. If so, more often than not, RSelenium is the right solution to alleviate a more complicated load. When it gets too challenging – for instance when you need to scrape in R at scale or perform a heavy data scrape in R across many sites – a dedicated and advanced web scraping API can save the day. For general web scraping, be sure to check out one of our Scraper API options or read a comparison article on no-code scraper solutions.
If you want to find out more on how to scrape the web using other programming languages, check our articles, such as Web Scraping with JavaScript, Web Scraping with Java, Web Scraping Using C#, Python Web Scraping Tutorial, What is Jupyter Notebook: Introduction, and many more.
Frequently Asked Questions
Is R good for web scraping?
R is a popular choice for public data web scraping, and deservedly so. It's open-source, has powerful libraries, and is relatively easy to use. Since R has built-in data analysis functionalities, it's commonly used for statistical analysis. Thus, R is indeed good for web scraping; however, it all depends on your use case and requirements. For instance, if your project requires dealing with complex data visualization and analysis, then you might be better off using R instead of a programming language like Python.
Is web scraping easier in Python or R?
What is the best R package for web scraping?
Why is essential to understand html and css deeply before web scraping with R?
Why is extracting data in R so popular among data analysts?
Forget about complex web scraping processes
Choose Oxylabs' advanced web intelligence collection solutions to gather real-time public data hassle-free.
About the author

Augustas Pelakauskas
Former Senior Technical Copywriter
Augustas Pelakauskas was a Senior Technical Copywriter at Oxylabs. Coming from an artistic background, he is deeply invested in various creative ventures - the most recent being writing. After testing his abilities in freelance journalism, he transitioned to tech content creation. When at ease, he enjoys the sunny outdoors and active recreation. As it turns out, his bicycle is his fourth-best friend.
All information on Oxylabs Blog is provided on an "as is" basis and for informational purposes only. We make no representation and disclaim all liability with respect to your use of any information contained on Oxylabs Blog or any third-party websites that may be linked therein. Before engaging in scraping activities of any kind you should consult your legal advisors and carefully read the particular website's terms of service or receive a scraping license.
Related articles

Cheerio vs. Puppeteer: Which Should You Use for Web Scraping?

Shinthiya Nowsain Promi
2026-06-23



List Crawling in Python: Tools, Tips, and Techniques

Danielė Virinaitė
2026-06-17

Get the latest news from data gathering world
Scale up your business with Oxylabs®
Proxies
Advanced proxy solutions
Data Collection
Datasets
Resources
Innovation hub
Forget about complex web scraping processes
Choose Oxylabs' advanced web intelligence collection solutions to gather real-time public data hassle-free.