175M+ ethically sourced IPs built for the highest reliability.
High-speed, cost-effective proxies built for any scraping workload.
Premium static residential proxies from trusted ASNs for most difficult targets.
Dedicated IPs from premium ASNs for demanding scraping.

AI-powered proxy solution for optimized web scraping performance.

20M+ IP addresses from real mobile devices for precise targeting.

Free Chrome proxy manager extension that works with any proxy provider.

Free Android proxy manager app that works with any proxy provider.

Free community-driven tools to improve your web scraping projects.
Web Scraper API
All-in-one web data collection platform for every stage of web scraping.
Fast Search API
Ultra-fast organic search results scraper tailored for AI workflows.
Headless Browser
Advanced browser automation solution for AI agents and scraping.
AI Studio
A suite of AI-powered tools for various scraping projects.

Documentation
All features, parameters, and integration details, backed by code samples in every coding language.
Tutorials, samples, and guides.
Latest fixes and features.






![]() AI Summary:
AI Summary:
This article details how to scrape NASDAQ stock data using Python. It explains using Selenium to access data within shadow DOM elements and Beautiful Soup for parsing, along with residential proxies to ensure reliable data collection and avoid detection. This method allows users to gather real-time stock data (name, price, and price changes) for analysis.
If you're into investing or building trading tools, you’ve probably wished you had easier access to live and historical stock data. The good news is that you absolutely can – by learning to build a web scraper and scraping stock data.
NASDAQ is home to some of the biggest names in tech and finance, and scraping its stock market data can unlock valuable insights. Whether you're hunting for new investment opportunities, backtesting a strategy, or tracking trends across industries, this tutorial will walk you through exactly how to collect that data using Python.
To make sure you can scrape stock market data reliably (and without getting blocked), we’ll also use Residential Proxies which will give you a stealthy, effective way to gather financial data at scale.

What is NASDAQ?
NASDAQ (short for the National Association of Securities Dealers Automated Quotations) is one of the world’s biggest stock exchanges – and a major hub for tech companies. It’s where giants like Apple, Microsoft, and Amazon are traded daily. For developers and investors alike, it’s a goldmine of stock data, from live prices to historical market conditions that can help reveal patterns, test strategies, and find smart investment opportunities.
How to scrape NASDAQ?
To scrape NASDAQ with Residential Proxies, you’ll route your data requests through real residential IP addresses, making your traffic appear like it’s coming from everyday users. This helps you avoid IP bans, captchas, and other anti-bot protections on the NASDAQ website, ensuring smoother and more consistent stock data collection.
If you’re wondering what is residential proxy, it’s a type of proxy that uses IPs assigned to real devices by internet service providers – making them much harder to detect and block. Using proxies is especially important when scraping frequently or at scale, as it reduces the chances of getting blocked and keeps your data collection process running reliably.
Setting up the environment
To start off, let’s install all of the pre-requisite libraries that we will be using today with the help of pip.
pip install –upgrade pip
pip install selenium beautifulsoup4 requests setuptools selenium-wireFinding the correct CSS locators
Now that we have the needed libraries, we can focus on finding the essential part of every web scraping operation – CSS locators. We will try to scrape four pieces of information – title, price, absolute price change and percentage price change from our target URL – the NASDAQ page.
First, let’s find the locator for the title element.
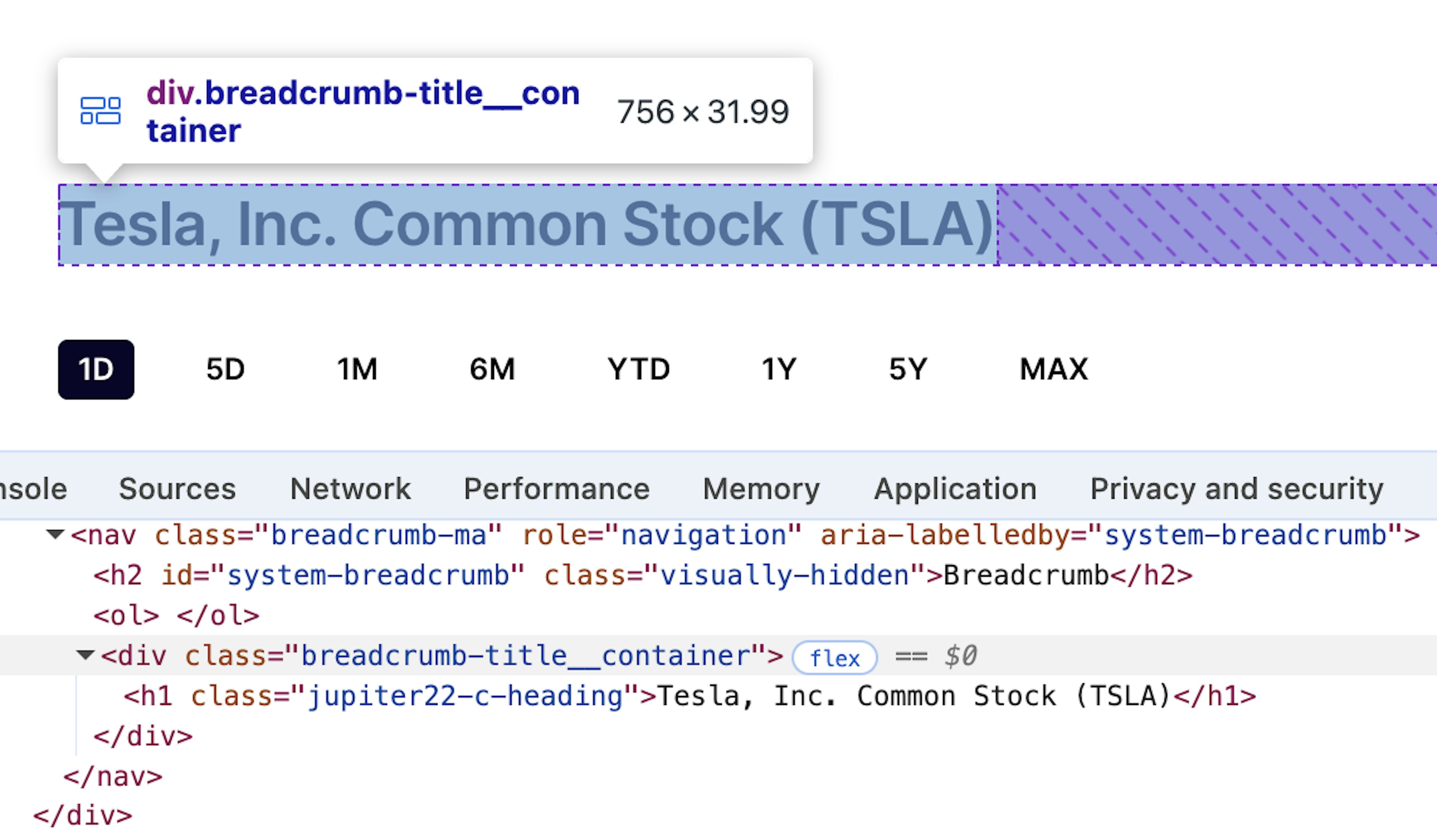
Great, started off pretty simple.
Next up, let’s find the price element. Now here we encounter some difficulties, as we can see that the price element is hidden within a #shadow-root. This means that we will have to employ the help of selenium here to retrieve the shadow-root first and only then try to access the HTML elements within:
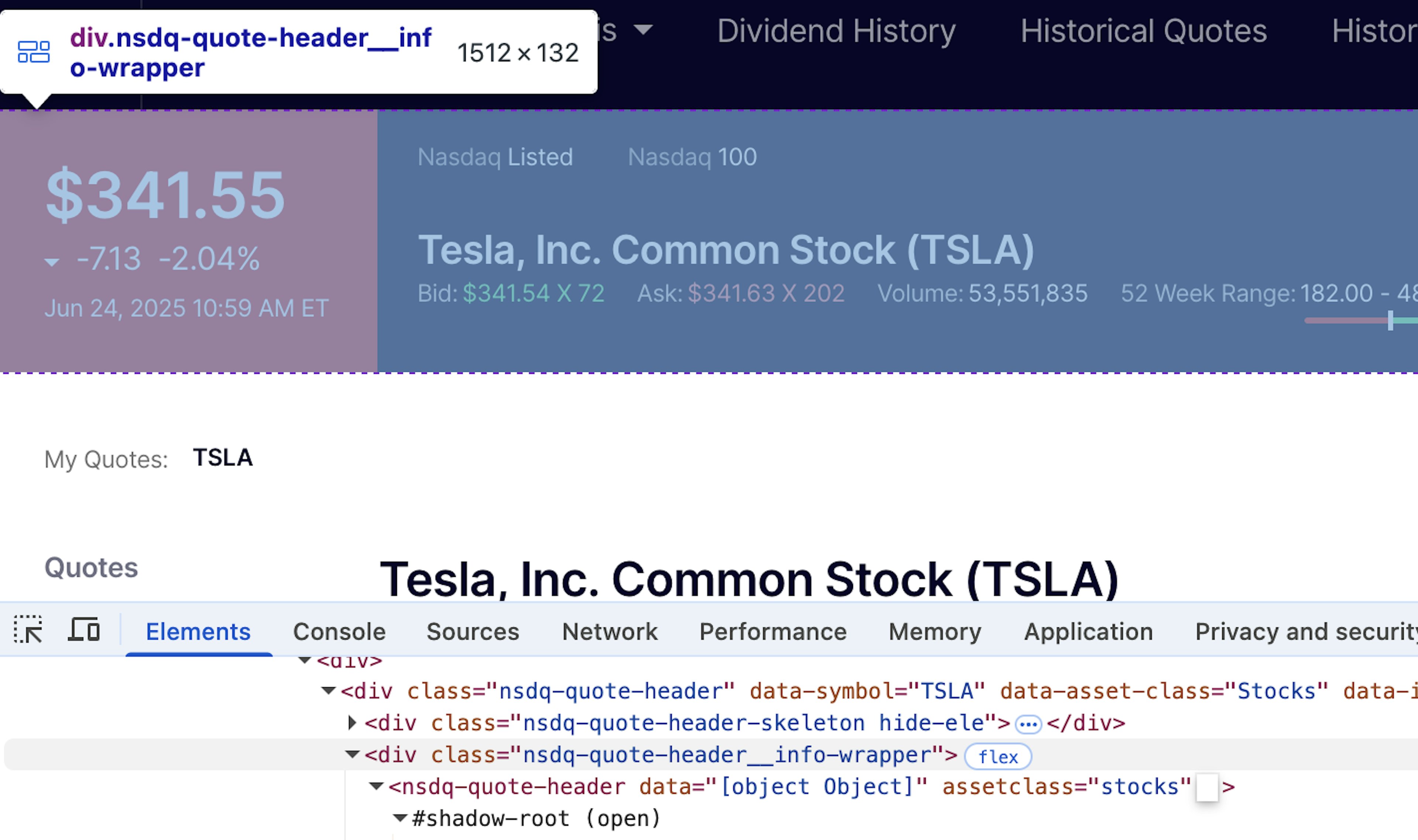
As we can see, the shadow root is inside the nsdq-quote-header element. Then, we can fetch the actual price:
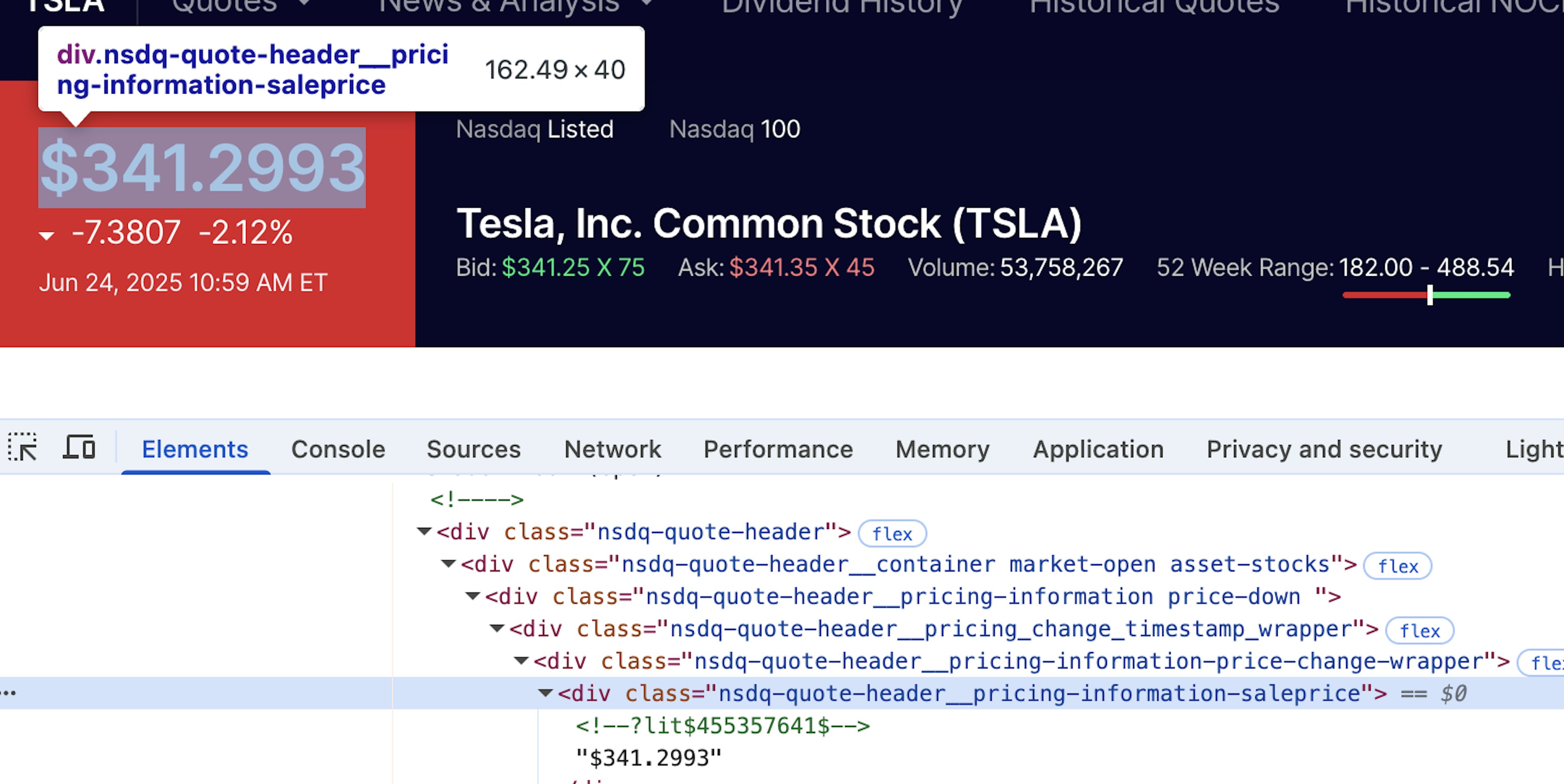
The same goes for absolute price change, which is also inside the shadow-root:
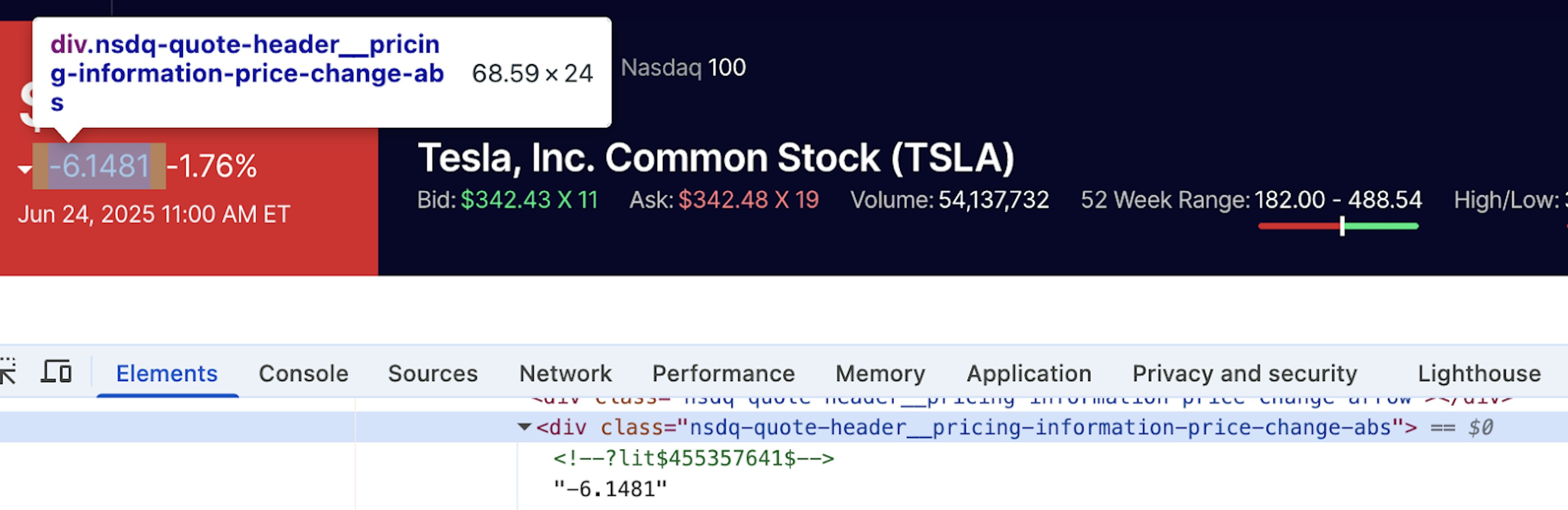
And the percent price change:
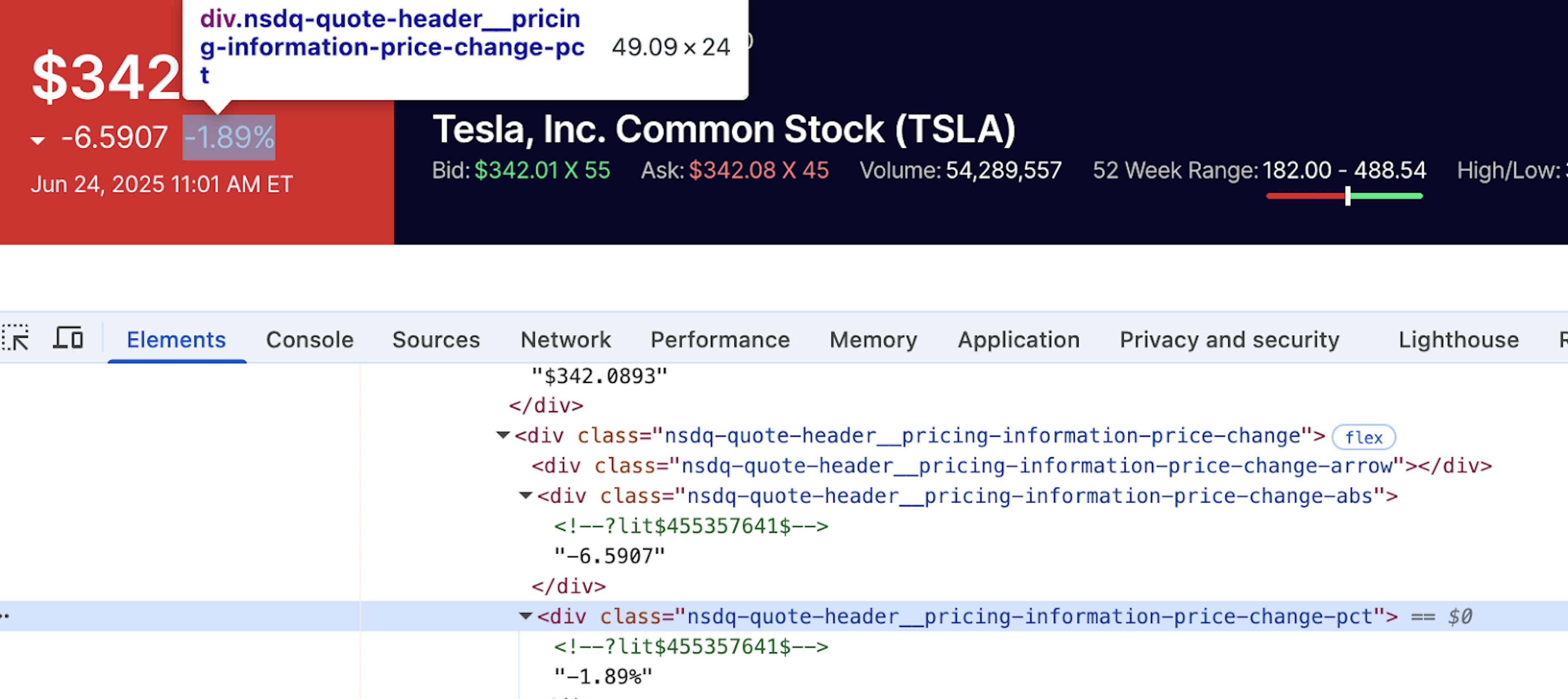
That concludes the search for the locators.
Setting up Oxylabs Residential Proxy
Moving on, let’s configure the use of Oxylabs Residential Proxy with selenium, so that we can be sure to evade detection. We can do that by defining a simple function that would configure the selenium driver for us.
def chrome_proxy(user: str, password: str, endpoint: str) -> dict:
"""Configure Chrome proxy settings for Oxylabs residential proxies"""
wire_options = {
"proxy": {
"http": f"http://{user}:{password}@{endpoint}",
"https": f"https://{user}:{password}@{endpoint}",
}
}
return wire_optionsHere we would just pass our Oxylabs Residential Proxy credentials and get back the proxy configuration.
Let’s also write a test function that would always check if we can successfully access the proxy:
def test_proxy_connection():
"""Test the proxy connection by visiting ip.oxylabs.io"""
chrome_options = Options()
chrome_options.add_argument("--headless")
chrome_options.add_argument("--no-sandbox")
chrome_options.add_argument("--disable-dev-shm-usage")
proxies = chrome_proxy(USERNAME, PASSWORD, ENDPOINT)
driver = None
try:
driver = webdriver.Chrome(options=chrome_options, seleniumwire_options=proxies)
driver.get("https://ip.oxylabs.io/")
# Extract IP information
import re
ip_match = re.search(r"[0-9].{2,}", driver.page_source)
if ip_match:
return f"Your proxy IP is: {ip_match.group()}"
else:
return "Could not extract IP from response"
except Exception as e:
return f"Error testing proxy: {e}"
finally:
if driver:
driver.quit()
Core scraping logic
Having all of the configuration out of the way, we can finally get to making the main logic of our scraper. Basic outline of our script will be:
Configure and initialize selenium with the residential proxies.
Get the HTML and the shadow-root of the page using selenium.
Use Beautiful Soup, specifically beautifulsoup4, to extract the desired information from the HTML.
This is what it would look like fleshed out in code:
def scrape_nasdaq_stock_info(symbol="TSLA"):
"""Scrape stock information from NASDAQ website using Oxylabs residential proxies"""
url = f"https://www.nasdaq.com/market-activity/stocks/{symbol.lower()}"
# Setup Chrome options
chrome_options = Options()
chrome_options.add_argument("--no-sandbox")
chrome_options.add_argument("--disable-dev-shm-usage")
chrome_options.add_argument("--user-agent=Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36")
# Configure proxy settings
proxies = chrome_proxy(USERNAME, PASSWORD, ENDPOINT)
driver = None
try:
# Create driver with proxy configuration
driver = webdriver.Chrome(options=chrome_options, seleniumwire_options=proxies)
driver.get(url)
# Wait for page to load
wait = WebDriverWait(driver, 10)
wait.until(EC.presence_of_element_located((By.TAG_NAME, "body")))
time.sleep(3)
# Get the fully rendered HTML
html_source = driver.page_source
# Get the shadow root
shadow_root_raw = driver.find_element(By.CSS_SELECTOR, "div.nsdq-quote-header__info-wrapper > nsdq-quote-header")
shadow_root = driver.execute_script('return arguments[0].shadowRoot', shadow_root_raw)
shadow_root_html = shadow_root.find_element(By.CSS_SELECTOR, "div.nsdq-quote-header").get_attribute('innerHTML')
# Parse with BeautifulSoup
soup = BeautifulSoup(html_source, 'html.parser')
shadow_root_soup = BeautifulSoup(shadow_root_html, 'html.parser')
# Extract stock data using BeautifulSoup
stock_data = {}
# Stock name
try:
name_element = soup.select_one("div.breadcrumb-title__container")
if name_element:
stock_data['name'] = name_element.get_text(strip=True)
else:
stock_data['name'] = f"{symbol.upper()} Stock"
except:
stock_data['name'] = f"{symbol.upper()} Stock"
# Current price
try:
price_element = shadow_root_soup.select_one("div.nsdq-quote-header__pricing-information-saleprice")
if price_element:
stock_data['price'] = price_element.get_text(strip=True)
else:
stock_data['price'] = "N/A"
except:
stock_data['price'] = "N/A"
# Current abs price change
try:
abs_price_change = shadow_root_soup.select_one("div.nsdq-quote-header__pricing-information-price-change-abs")
if abs_price_change:
stock_data['abs_price_change'] = abs_price_change.get_text(strip=True)
else:
stock_data['abs_price_change'] = "N/A"
except:
stock_data['abs_price_change'] = "N/A"
# Current percent price change
try:
percent_price_change = shadow_root_soup.select_one("div.nsdq-quote-header__pricing-information-price-change-pct")
if percent_price_change:
stock_data['percent_price_change'] = percent_price_change.get_text(strip=True)
else:
stock_data['percent_price_change'] = "N/A"
except:
stock_data['percent_price_change'] = "N/A"
return stock_data
except Exception as e:
print(f"Error: {e}")
return None
finally:
if driver:
driver.quit()Complete code
To see how our web scraper works, let’s gather all that we have done up until now into one place and run it:
#!/usr/bin/env python3
import time
from seleniumwire import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from bs4 import BeautifulSoup
# Oxylabs Residential Proxy Configuration
USERNAME = "USERNAME" # Replace with your Oxylabs username
PASSWORD = "PASSWORD" # Replace with your Oxylabs password
ENDPOINT = "pr.oxylabs.io:7777" # Residential proxy endpoint
def chrome_proxy(user: str, password: str, endpoint: str) -> dict:
"""Configure Chrome proxy settings for Oxylabs residential proxies"""
wire_options = {
"proxy": {
"http": f"http://{user}:{password}@{endpoint}",
"https": f"https://{user}:{password}@{endpoint}",
}
}
return wire_options
def scrape_nasdaq_stock_info(symbol="TSLA"):
"""Scrape stock information from NASDAQ website using Oxylabs residential proxies"""
url = f"https://www.nasdaq.com/market-activity/stocks/{symbol.lower()}"
# Setup Chrome options
chrome_options = Options()
#chrome_options.add_argument("--headless")
chrome_options.add_argument("--no-sandbox")
chrome_options.add_argument("--disable-dev-shm-usage")
chrome_options.add_argument("--user-agent=Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36")
# Configure proxy settings
proxies = chrome_proxy(USERNAME, PASSWORD, ENDPOINT)
driver = None
try:
# Create driver with proxy configuration
driver = webdriver.Chrome(options=chrome_options, seleniumwire_options=proxies)
driver.get(url)
# Wait for page to load
wait = WebDriverWait(driver, 10)
wait.until(EC.presence_of_element_located((By.TAG_NAME, "body")))
time.sleep(3)
# Get the fully rendered HTML
html_source = driver.page_source
# Get the shadow root
shadow_root_raw = driver.find_element(By.CSS_SELECTOR, "div.nsdq-quote-header__info-wrapper > nsdq-quote-header")
shadow_root = driver.execute_script('return arguments[0].shadowRoot', shadow_root_raw)
shadow_root_html = shadow_root.find_element(By.CSS_SELECTOR, "div.nsdq-quote-header").get_attribute('innerHTML')
# Parse with BeautifulSoup
soup = BeautifulSoup(html_source, 'html.parser')
shadow_root_soup = BeautifulSoup(shadow_root_html, 'html.parser')
# Extract stock data using BeautifulSoup
stock_data = {}
# Stock name
try:
name_element = soup.select_one("div.breadcrumb-title__container")
if name_element:
stock_data['name'] = name_element.get_text(strip=True)
else:
stock_data['name'] = f"{symbol.upper()} Stock"
except:
stock_data['name'] = f"{symbol.upper()} Stock"
# Current price
try:
price_element = shadow_root_soup.select_one("div.nsdq-quote-header__pricing-information-saleprice")
if price_element:
stock_data['price'] = price_element.get_text(strip=True)
else:
stock_data['price'] = "N/A"
except:
stock_data['price'] = "N/A"
# Current abs price change
try:
abs_price_change = shadow_root_soup.select_one("div.nsdq-quote-header__pricing-information-price-change-abs")
if abs_price_change:
stock_data['abs_price_change'] = abs_price_change.get_text(strip=True)
else:
stock_data['abs_price_change'] = "N/A"
except:
stock_data['abs_price_change'] = "N/A"
# Current percent price change
try:
percent_price_change = shadow_root_soup.select_one("div.nsdq-quote-header__pricing-information-price-change-pct")
if percent_price_change:
stock_data['percent_price_change'] = percent_price_change.get_text(strip=True)
else:
stock_data['percent_price_change'] = "N/A"
except:
stock_data['percent_price_change'] = "N/A"
return stock_data
except Exception as e:
print(f"Error: {e}")
return None
finally:
if driver:
driver.quit()
def test_proxy_connection():
"""Test the proxy connection by visiting ip.oxylabs.io"""
chrome_options = Options()
chrome_options.add_argument("--headless")
chrome_options.add_argument("--no-sandbox")
chrome_options.add_argument("--disable-dev-shm-usage")
proxies = chrome_proxy(USERNAME, PASSWORD, ENDPOINT)
driver = None
try:
driver = webdriver.Chrome(options=chrome_options, seleniumwire_options=proxies)
driver.get("https://ip.oxylabs.io/")
# Extract IP information
import re
ip_match = re.search(r"[0-9].{2,}", driver.page_source)
if ip_match:
return f"Your proxy IP is: {ip_match.group()}"
else:
return "Could not extract IP from response"
except Exception as e:
return f"Error testing proxy: {e}"
finally:
if driver:
driver.quit()
def main():
"""Main function"""
print("Testing Oxylabs proxy connection...")
proxy_test = test_proxy_connection()
print(proxy_test)
print("\nScraping NASDAQ stock information...")
stock_info = scrape_nasdaq_stock_info("TSLA")
if stock_info:
print("\nStock Information:")
print("-" * 40)
for key, value in stock_info.items():
print(f"{key.title()}: {value}")
else:
print("Failed to scrape stock information.")
if __name__ == "__main__":
main()And if we run the code, we should see the results printed out:
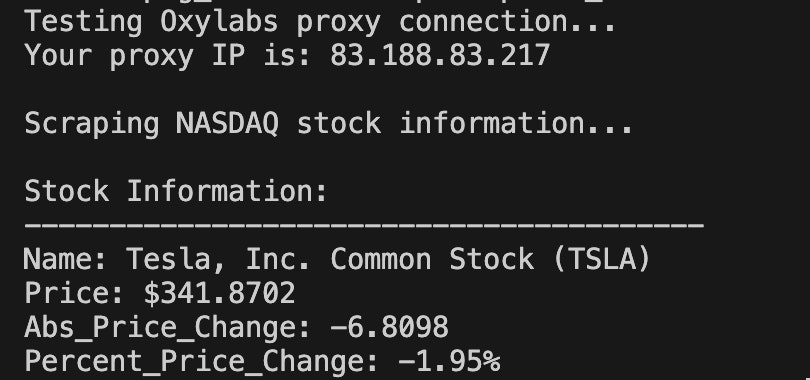
Conclusion
Web scraping stock market data can open the door to deeper insights and smarter decisions. With the right tools and a reliable setup using residential proxies, you’re now ready to use your NASDAQ scraper and get the stock market data points that you need.
If you’re looking to expand beyond NASDAQ, consider using Web Scraper API – it simplifies scraping complex sites and makes it possible to scrape Google Finance as well as detailed in our blog post How to Scrape Google Finance with Python. Web Scraper API is a powerful option for targeting other financial and stock data sources quickly and reliably.
Frequently asked questions
Why use Python to scrape NASDAQ?
Python is a practical choice for scraping stock market data due to its simplicity and powerful libraries. With tools like requests, BeautifulSoup, and pandas, you can easily extract stock prices from the NASDAQ website and structure it for further analysis. It’s a great way to turn raw financial data into something useful for data-driven decisions.
Can you scrape stock market data?
What’s the best way to scale financial data scraping across multiple sources?
What kind of stock market data can I get by scraping NASDAQ?
About the author

Akvilė Lūžaitė
Former Technical Copywriter
With a background in Linguistics and Design, Akvilė focuses on crafting content that blends creativity with strategy.
All information on Oxylabs Blog is provided on an "as is" basis and for informational purposes only. We make no representation and disclaim all liability with respect to your use of any information contained on Oxylabs Blog or any third-party websites that may be linked therein. Before engaging in scraping activities of any kind you should consult your legal advisors and carefully read the particular website's terms of service or receive a scraping license.
Related articles

Cheerio vs. Puppeteer: Which Should You Use for Web Scraping?

Shinthiya Nowsain Promi
2026-06-23



List Crawling in Python: Tools, Tips, and Techniques

Danielė Virinaitė
2026-06-17

Get the latest news from data gathering world
Scale up your business with Oxylabs®
Proxies
Advanced proxy solutions
Data Collection
Datasets
Resources
Innovation hub