175M+ ethically sourced IPs built for the highest reliability.
High-speed, cost-effective proxies built for any scraping workload.
Premium static residential proxies from trusted ASNs for most difficult targets.
Dedicated IPs from premium ASNs for demanding scraping.

AI-powered proxy solution for optimized web scraping performance.

20M+ IP addresses from real mobile devices for precise targeting.

Free Chrome proxy manager extension that works with any proxy provider.

Free Android proxy manager app that works with any proxy provider.

Free community-driven tools to improve your web scraping projects.
Web Scraper API
All-in-one web data collection platform for every stage of web scraping.
Fast Search API
Ultra-fast organic search results scraper tailored for AI workflows.
Headless Browser
Advanced browser automation solution for AI agents and scraping.
AI Studio
A suite of AI-powered tools for various scraping projects.

Documentation
All features, parameters, and integration details, backed by code samples in every coding language.
Tutorials, samples, and guides.
Latest fixes and features.







![]() AI Summary:
AI Summary:
The Web Scraper API is a data collection platform that handles crawling and parsing, delivering data to cloud storage. Users can quickly start by registering, creating an API user, and running a test query, leveraging features like dedicated scrapers, AI assistance, and scheduling for efficient data extraction.
Web Scraper API is an all-in-one web data collection platform equipped with AI-powered features and designed to meet all your needs. It addresses every aspect of web scraping, from crawling URLs and tackling complex web systems to precise data parsing and delivery to your preferred cloud storage. You can extract public data from search engines, e-commerce sites, travel platforms, AI platforms, and any website with exceptional efficiency and simplicity.
While our blog features all kinds of tutorials, such as how to scrape NASDAQ, in this guide, you’ll learn how to start using Web Scraper API and send a first query.
Setting up Web Scraper API
1. Register or log in to the dashboard if you already have an account.
2. After selecting a free trial or a subscription plan, a pop-up window will appear, asking to create an API user. Think of a username and password and create an API user. Store them in a safe and easily accessible location, as they’re crucial for user authentication in all scraping tasks.

3. You'll see a pop-up with three tabs for Amazon, Google, and Other websites, each containing a cURL test query. To test, copy the provided code to your terminal, Postman, or any other setup, insert your API user credentials, and run the query. Here’s the code using the universal source for scraping sandbox.oxylabs.io/products:
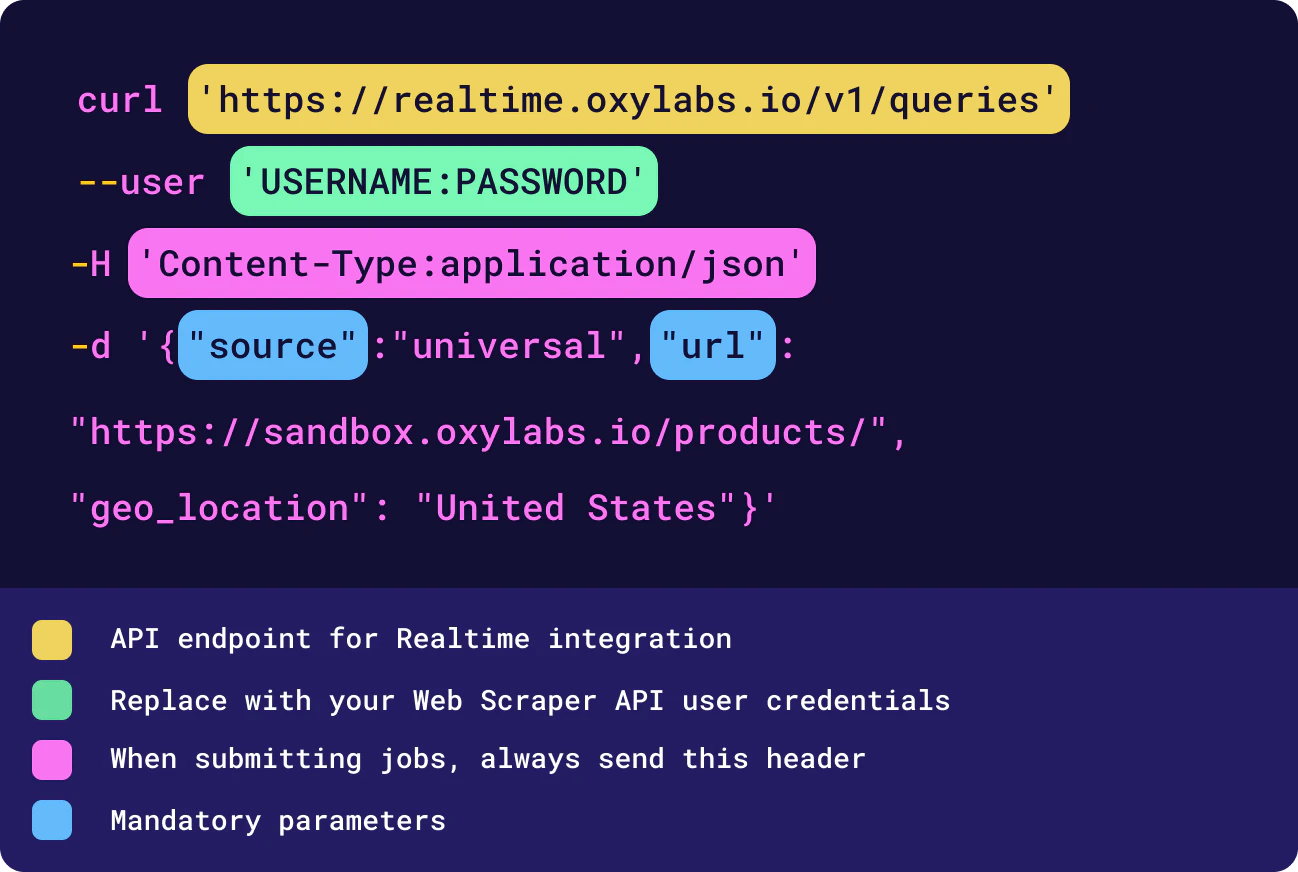
A test query
You can use the following queries with different sources and some additional parameters for testing:
Amazon
curl 'https://realtime.oxylabs.io/v1/queries' --user "USERNAME:PASSWORD" -H "Content-Type: application/json" -d '{"source": "amazon_product", "query": "B07FZ8S74R", "geo_location": "90210", "parse": true}'curl 'https://realtime.oxylabs.io/v1/queries' --user 'USERNAME:PASSWORD' -H 'Content-Type: application/json' -d '{"source": "google_search", "query": "adidas", "geo_location": "California,United States", "parse": true}'Universal
curl 'https://realtime.oxylabs.io/v1/queries' --user 'USERNAME:PASSWORD' -H 'Content-Type: application/json' -d '{"source": "universal", "url": "https://sandbox.oxylabs.io/"}'The response output will include results and job information. For reference, take a look at these full output examples for Amazon, Google, and Universal.
For a visual representation of how to set up and manually test Web Scraper API, check the video below.

You can also check how Web Scraper API works in our Web Scraper API Playground, which is accessible via the dashboard.
Integration methods
The examples above implement the Realtime integration method. With Realtime, you can send your request and receive data back on the same open HTTPS connection straight away.
You can integrate Web Scraper API using one of the three methods:
Realtime
Push-Pull
Proxy Endpoint
Read more about integration methods and how to choose one here. In essence, these are the main differences.
| Push-Pull | Realtime | Proxy Endpoint | |
|---|---|---|---|
| Type | Asynchronous | Synchronous | Synchronous |
| Job query format | JSON | JSON | URL |
| Job status check | Yes | No | No |
| Batch query | Yes | No | No |
| Upload to storage | Yes | No | No |
| Multi-format output | Yes | Yes | No |
The Batch Query method allows you to submit up to 5,000 query or url parameter values within a single batch request. For full examples of Push-Pull and Proxy Endpoint integration methods, please see our GitHub and documentation.
Dedicated scrapers
Web Scraper API comes with dedicated scrapers designed to target specific search engines, e-commerce marketplaces, and their page types. Here's a table showing all available dedicated scrapers:
| Domain | Sources |
|---|---|
googlegoogle_searchgoogle_adsgoogle_lensgoogle_travel_hotelsgoogle_trends_exploregoogle_ai_mode |
|
| Bing |
bingbing_search
|
| Amazon |
amazonamazon_bestsellersamazon_pricingamazon_productamazon_searchamazon_sellers
|
| ChatGPT |
chatgpt |
| Perplexity |
perplexity |
| eBay |
ebay_searchebay_product |
| Etsy |
etsy_searchetsy_product |
| Walmart |
walmart_searchwalmart_product |
| Best Buy |
bestbuy_searchbestbuy_product |
| Target |
target_searchtarget_producttarget_category |
| Lowe’s |
lowes_searchlowes_product |
| Kroger |
kroger_searchkroger_product |
| Other websites | universal |
These are just a few of our dedicated scrapers for the most popular websites. You can find the full list of our dedicated scrapers in the Web Scraper API documentation.
Dedicated parsers
For some sources, we’ve developed dedicated parsers that extract specific data points. To get structured results, use the parse parameter and set it to true in your requests to the API. See the table below for more details:
| Target | Sources | Types |
|---|---|---|
| Amazon | amazonamazon_searchamazon_productamazon_pricingamazon_bestsellersamazon_sellers
|
Search Product Offer listing Best sellers Sellers |
googlegoogle_searchgoogle_ai_modegoogle_adsgoogle_lens |
Web search Image search News search AI Mode Lens search |
|
| ChatGPT | chatgpt |
Chat |
| Perplexity | perplexity |
Chat |
| Bing | bingbing_search |
Search |
| Walmart |
walmartwalmart_searchwalmart_product |
Search Product |
| Best Buy | bestbuy_product |
Product |
| Etsy | etsyetsy_product |
Product |
| Target | targettarget_searchtarget_product |
Search Product |
Parameters
Below are the main query parameters. For more details and additional parameters, such as handling specific context types, visit our documentation.
| Parameter | Description |
|---|---|
source |
Sets the scraper to process your request. |
url |
Direct URL (link) to the target page. |
query |
Depending on the target you want to scrape, accepts a UTF-encoded search keyword, or Amazon ASIN number. |
parse |
Returns parsed data when set to true.The default value is false. |
geo_location |
For Google, it localizes SERP results. For Amazon, it picks the “deliver to” location. For all other targets, it picks the location of a proxy server for scraping. |
render |
Enables JavaScript rendering when set to html. Another available value is png, which returns a Base64-encoded screenshot of the rendered page. |
xhr |
Returns a list of XHR/Fetch requests made during page loading when set to true. |
markdown |
Returns a markdown format results when set to true. |
user_agent_type |
Sets the device type and browser. The default value is desktop. |
callback_url |
URL to your callback endpoint. |
sort_by |
Sorts amazon_search results by chosen criteria (price, relevance, customer ratings) |
refinements |
Filters amazon_search results, corresponds to Amazon's native filtering options (e.g., brand, price range, features) |
Response codes
Below are the most common response codes you can encounter using Web Scraper API. Please contact technical support if you receive a code not found in our documentation.
| Response | Error message | Description |
|---|---|---|
200 |
OK | All went well. |
202 |
Accepted | Your request was accepted. |
204 |
No content | You’re trying to retrieve a job that hasn’t been completed yet. |
400 |
Multiple error messages | Wrong request structure. Could be a misspelled parameter or an invalid value. The response body will have a more specific error message. |
401 |
Authorization header not provided / Invalid authorization header / Client not found | Missing authorization header or incorrect login credentials. |
403 |
Forbidden | Your account doesn't have access to this resource. |
404 |
Not found | The job ID you're looking for is no longer available. |
422 |
Unprocessable entity | There's something wrong with the payload. Make sure it's a valid JSON object. |
429 |
Too many requests | Exceeded rate limit. Please contact your account manager to increase limits. |
500 |
Internal server error | We're facing technical issues, please retry later. We may already be aware, but feel free to report it anyway. |
524 |
Timeout | Service unavailable. |
612 |
Undefined internal error | Job submission failed. Retry at no extra cost with faulted jobs, or reach out to us for assistance. |
613 |
Faulted after too many retries | Job submission failed. Retry at no extra cost with faulted jobs, or reach out to us for assistance. |
Using API features
Web Scraper API has a range of smart built-in features.
Scheduler automates recurring web scraping and parsing jobs by scheduling them. You can schedule at any interval – every minute, every five minutes, hourly, daily, every two days, and so on. With Scheduler, you don’t need to repeat requests with the same parameters. Read more for tech details.
Custom Parser lets you extract structured JSON data from any website using XPath or CSS selectors. You can also employ reusable parsing instructions by creating custom Parser Presets, which can automatically adjust themselves using self-healing and adapt as websites change. Read more for tech details.
OxyCopilot is an AI-driven web scraping assistant designed to generate API scraping requests and custom parsing instructions using plain English language. It identifies complex parsing patterns on any website and eliminates the need for manual coding, significantly accelerating and simplifying web scraping and parsing tasks. You can access OxyCopilot through the dashboard. Read more for tech details.
Cloud integration allows you to get your data delivered to a preferred cloud storage bucket, whether it's Amazon S3, GCS, Alibaba Cloud OSS, or other S3-compatible storage. This eliminates the need for additional requests to fetch results – data goes directly to your cloud storage. Read more for tech details.
Result Aggregator merges scraped results into aggregate files for cloud storage, solving the problem of managing millions of small files. This cuts storage and transfer costs, eliminates processing bottlenecks, and simplifies data pipeline integration. Read more for tech details.
XHR request capturing allows you to extract data directly from Fetch/XHR requests made by the browser while loading a page. Instead of parsing HTML, you can capture network calls that return structured JSON data, especially useful when a site loads content dynamically via JavaScript. Read more for tech details.
Markdown output returns markdown type results in addition to HTML or parsed JSON. These responses provide an easy-to-read format, simplifying result integration into various content workflows and AI tools. Read more for tech details.
Multi-format output lets you retrieve parsed data, Markdown, screenshots, XHR, and raw results in a single API response. Read more for tech details.
Dashboard statistics
In the Oxylabs dashboard, you can follow your usage. Within the Statistics section, you’ll be able to see total statistics or categorized by domain. Filters include rendered/non-rendered, domains, users, increased speed, and scraper data. Additionally, you can filter your usage data based on the past 90 days.

Additional resources
You can try our Web Scraper API for free – get up to 2,000 results for unlimited time and test how our product works for yourself. If you have any questions, please get in touch with us via our live chat or email us at support@oxylabs.io
For more tutorials and tips on all things web data extraction, stay engaged:
Frequently asked questions
What are Web Scraper API rate limits?
Every user account has a rate limit corresponding to their monthly subscription plan. The rate limit should be more than enough based on the expected volume of scraping jobs.
How to download images using Web Scraper API?
Can I get a free trial for Web Scraper API?
What are the pricing options of Web Scraper API?
How does billing for Web Scraper API work?
About the author

Augustas Pelakauskas
Former Senior Technical Copywriter
Augustas Pelakauskas was a Senior Technical Copywriter at Oxylabs. Coming from an artistic background, he is deeply invested in various creative ventures - the most recent being writing. After testing his abilities in freelance journalism, he transitioned to tech content creation. When at ease, he enjoys the sunny outdoors and active recreation. As it turns out, his bicycle is his fourth-best friend.
All information on Oxylabs Blog is provided on an "as is" basis and for informational purposes only. We make no representation and disclaim all liability with respect to your use of any information contained on Oxylabs Blog or any third-party websites that may be linked therein. Before engaging in scraping activities of any kind you should consult your legal advisors and carefully read the particular website's terms of service or receive a scraping license.
Related articles






Web Scraper API for effortless data gathering
Extract data even from the most complex websites without hassle.

Get the latest news from data gathering world
Scale up your business with Oxylabs®
Proxies
Advanced proxy solutions
Data Collection
Datasets
Resources
Innovation hub
Web Scraper API for effortless data gathering
Extract data even from the most complex websites without hassle.