175M+ ethically sourced IPs built for the highest reliability.
High-speed, cost-effective proxies built for any scraping workload.
Premium static residential proxies from trusted ASNs for most difficult targets.
Dedicated IPs from premium ASNs for demanding scraping.

AI-powered proxy solution for optimized web scraping performance.

20M+ IP addresses from real mobile devices for precise targeting.

Free Chrome proxy manager extension that works with any proxy provider.

Free Android proxy manager app that works with any proxy provider.

Free community-driven tools to improve your web scraping projects.
Web Scraper API
All-in-one web data collection platform for every stage of web scraping.
Fast Search API
Ultra-fast organic search results scraper tailored for AI workflows.
Headless Browser
Advanced browser automation solution for AI agents and scraping.
AI Studio
A suite of AI-powered tools for various scraping projects.

Documentation
All features, parameters, and integration details, backed by code samples in every coding language.
Tutorials, samples, and guides.
Latest fixes and features.






![]() AI Summary:
AI Summary:
A practical guide to locating HTML elements with Selenium in Python. Covers the difference between `findElement` and `findElements`, then walks through locator strategies including ID, Name, Class Name, Link Text, Partial Link Text, Tag Name, XPath, and CSS selectors. Also addresses advanced scenarios like dynamic IDs, hidden elements, and iframes, with a brief section on best practices.
Selenium is a web automation tool that enables users to perform tasks like web application testing, scraping, workflow automation, and more. In this article, we’ll try to focus on and outline some key points on finding HTML elements while using Selenium for scraping and doing it all in Python.
findElement vs findElements
First off, Selenium offers us two ways of locating web elements inside of pages: findElement and findElements.
findElement
Finds and returns the first element by the provided locator.
Throws an exception if it cannot find an element.
Is used when trying to locate a single specific element within a page.
For example:
driver = webdriver.Chrome()
driver.get("https://sandbox.oxylabs.io/products")
search_box=driver.find_element(By.XPATH, "//input[1]")Here, we would get the first web element within the web page that would match the provided XPath descriptor or receive a selenium.common.exceptions. NoSuchElementException exception if there are none.
findElements
Finds and returns multiple elements that match the provided locator.
Returns an empty array if it cannot locate elements.
Used when you need to locate and interact with multiple objects within a web page.
For example:
driver = webdriver.Chrome()
driver.get("https://sandbox.oxylabs.io/products")
search_boxes = driver.find_elements(By.XPATH, "//input")The code above retrieves multiple elements that match the provided descriptor and stores them as a list in the variable search_boxes. If there are none, the list will be empty.
When looking to find an element by text in Selenium, double check which of the methods would be better for your specific case.
Strategies for locating elements
Now that this is cleared up, let’s go over the ways you can try and locate elements by utilizing the methods Selenium provides you with. We will be using https://sandbox.oxylabs.io/products as an example.
Locating elements by ID attribute
ID is a unique identifier for a web element, meaning that it should always uniquely identify a single element within a page.
Let’s look at an example of a web element that can be located by ID attribute:

The code for fetching this element on Selenium by ID would look like this:
driver = webdriver.Chrome()
driver.get("https://sandbox.oxylabs.io/products")
element = driver.find_element(By.ID, "__next-route-announcer__")Locating elements by Name
Name, unlike ID, is not required to be unique and can return duplicates. Otherwise, everything remains the same.

To locate elements by Name, a code like this should be used:
driver = webdriver.Chrome()
driver.get("https://sandbox.oxylabs.io/products")
element = driver.find_element(By.NAME, "next-head-count")Locating elements by Class Name
Next, let's explore class names. This attribute can assign one or more classes to an element and is typically used by JavaScript and CSS to select and manipulate specific elements within a web page.
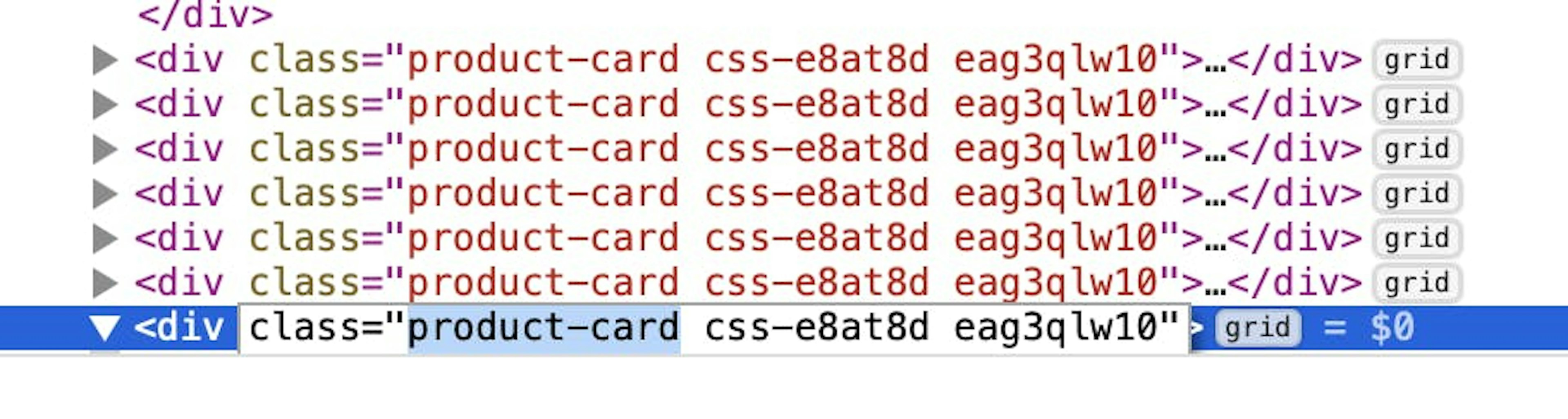
Let’s write a code that would return all these product-card class elements by utilizing the findElements method:
driver = webdriver.Chrome()
driver.get("https://sandbox.oxylabs.io/products")
elements = driver.find_elements(By.CLASS_NAME, "product-card")Locating elements by Link Text
Finding web elements by link text is useful for identifying hyperlinks by the text they display. Keep in mind that this method is case-sensitive.
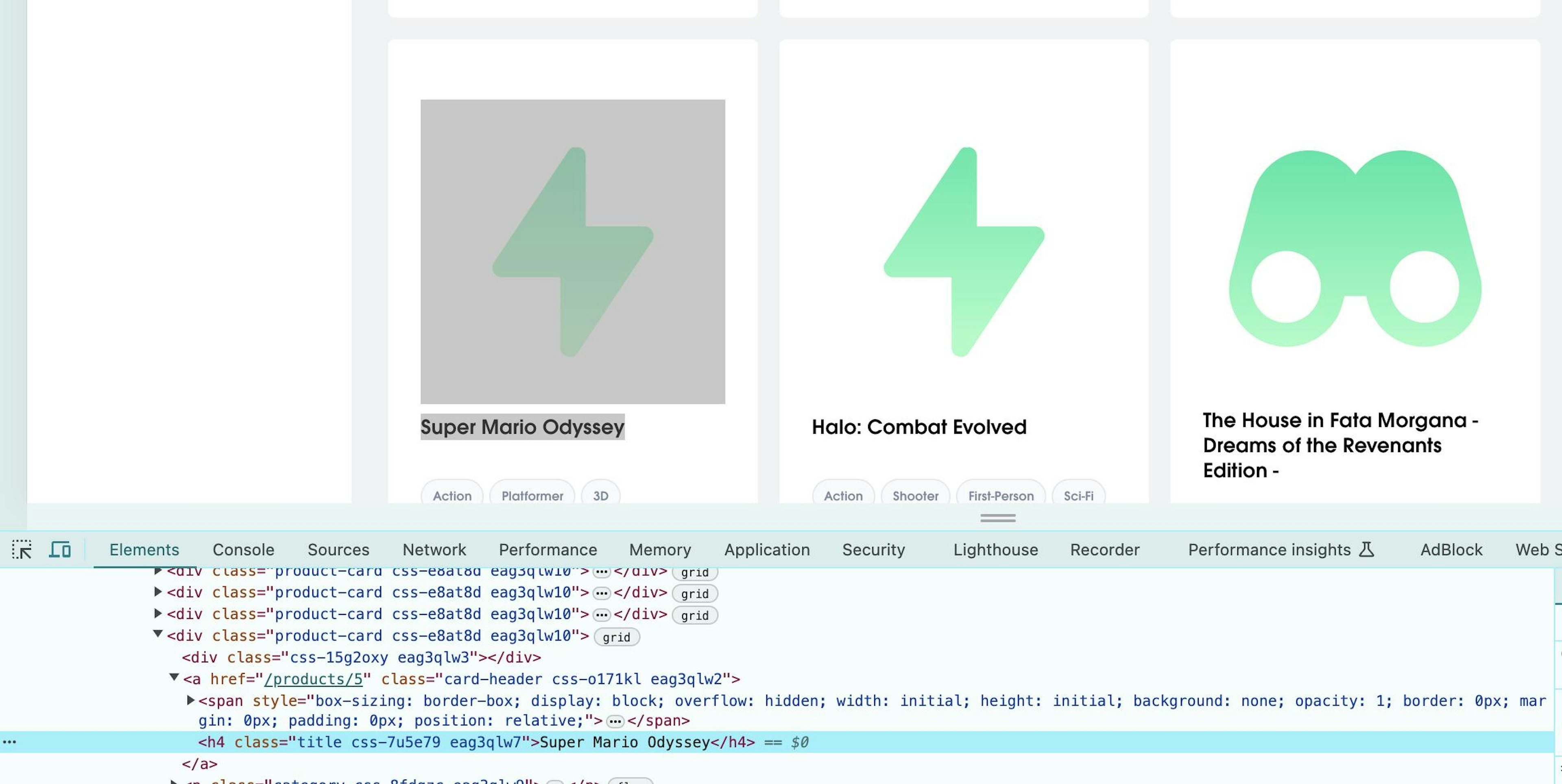
Locating links by text
So, to find this a element that has a href attribute, we will need to specify the text Super Mario Odyssey:
driver = webdriver.Chrome()
driver.get("https://sandbox.oxylabs.io/products")
elements = driver.find_element(By.LINK_TEXT, "Super Mario Odyssey")Locating elements by Partial Link Text
Sometimes, finding all the linked web elements that mention a specific keyword can be helpful. Conveniently, there's a method for getting partial link text matches. As before, they still have to be case-sensitive.
Using the same Super Mario Odyssey example, we can omit the Super part and still find our element like this:
driver = webdriver.Chrome()
driver.get("https://sandbox.oxylabs.io/products")
elements = driver.find_element(By.PARTIAL_LINK_TEXT, "Mario Odyssey")Locating elements by Tag Name
While using Tag Names usually results in a very vague object selection, this can be useful when you want to get all HTML elements of a certain type.
For example, the code below will find all the span elements within a page:
driver = webdriver.Chrome()
driver.get("https://sandbox.oxylabs.io/products")
elements = driver.find_elements(By.TAG_NAME, "span")Locating elements by XPath
XPath is a powerful query language used to select nodes in an XML document that can be utilized for selecting elements in an HTML document.
To learn how to find XPath in Chrome, let’s look at an example XPath query, which selects the same span elements as before:
driver = webdriver.Chrome()
driver.get("https://sandbox.oxylabs.io/products")
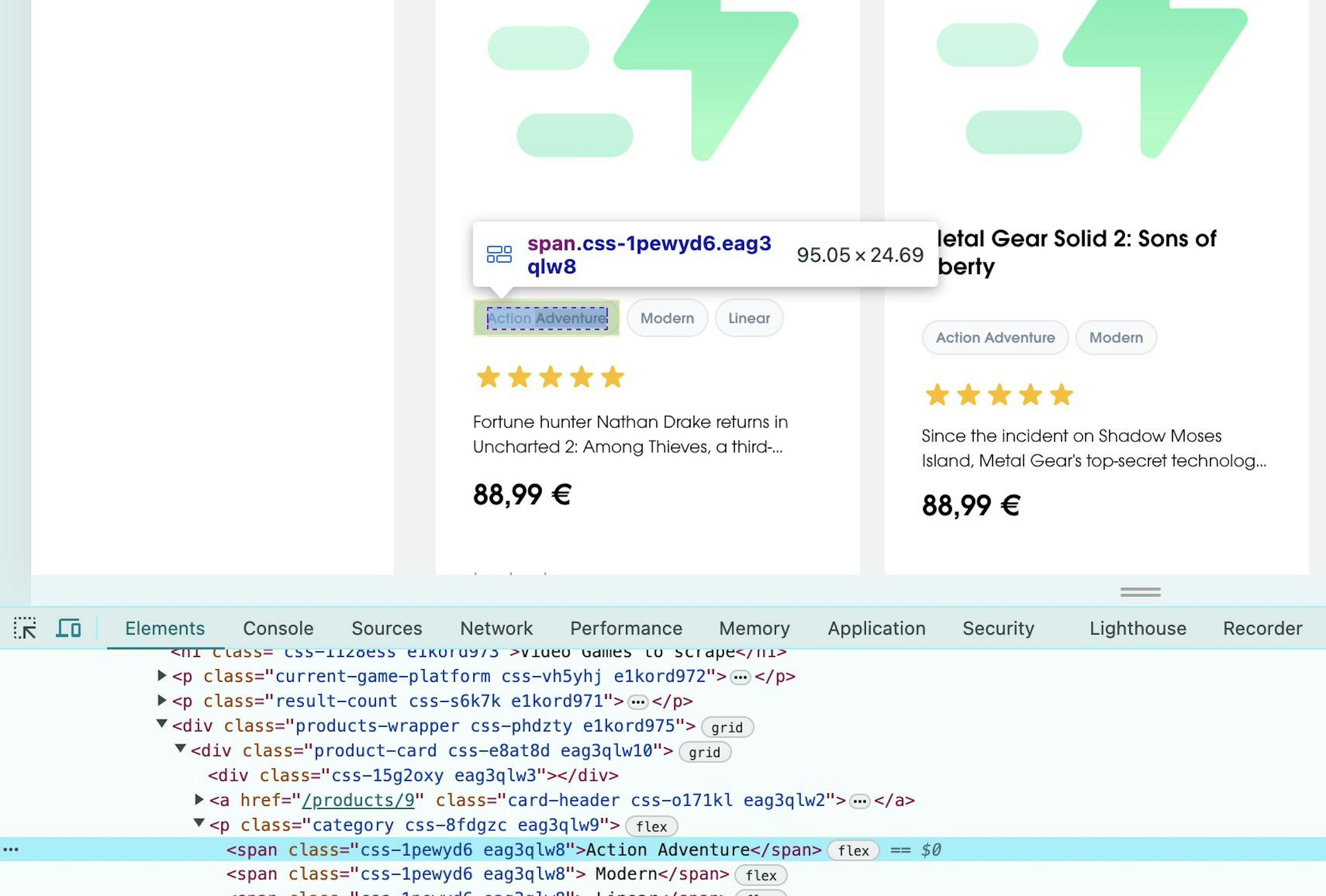
elements = driver.find_elements(By.XPATH, "//span")Now, let’s imagine that we only want span elements that have the text Action Adventure in them. That's how you'd do it:
driver = webdriver.Chrome()
driver.get("https://sandbox.oxylabs.io/products")
elements = driver.find_elements(By.XPATH, "//span[text()='Action Adventure']")To learn more how to select different types of elements, such as the sibling elements in XPath or as in this example, how to select elements by text, take a look at out resources.
Locating elements by CSS Selector
While CSS is primarily a language that defines how our HTML pages are presented to users, it provides us with a very useful tool to locate elements within a page – CSS selectors.
CSS selectors are quite powerful and can get very complex, but for the sake of our tutorial, let’s take a look at a simple example from before:

driver = webdriver.Chrome()
driver.get("https://sandbox.oxylabs.io/products")
elements = driver.find_elements(By.CSS_SELECTOR, "span")Advanced techniques
When using Selenium, XPath and CSS selectors are essential tools for locating elements in more advanced scenarios. Let's take a look at some of them.
Dynamic element IDs
Since most pages are built using modern JavaScript frameworks and new development practices, elements often have dynamic IDs, complex attribute structures, or dynamic class name systems, and sometimes lack IDs altogether.
Let’s say we want to target this h4 element specifically.

We can see that it has no ID, but we can still pin it down using a parent–child relation by specifying CSS selector:
driver = webdriver.Chrome()
driver.get("https://sandbox.oxylabs.io/products")
elements = driver.find_element(By.CSS_SELECTOR, "a[href='/products/5'] > h4.title")Here, we specify the element with a parent by an attribute and get the element we specifically need.
Hidden/invisible elements
Handling hidden/invisible elements can be different from case to case, but general guidelines would be:
Locating the elements via their hidden attribute with the help of CSS selectors
Consider leveraging Selenium with JavaScript to simulate user input and access initially hidden elements on the page.
Iframes
Another thing to worry about could be Iframes. To access elements within them using CSS selectors or XPath queries with Selenium, you must first switch to the iframe element using the Selenium driver. This step ensures your element locating methods function correctly. That's how you can do it:
iframe = driver.find_element(By.CSS_SELECTOR, "#modal > iframe")
driver.switch_to.frame(iframe)Best practices
When scraping with Selenium in Python, use tools like XPath Finder or Selenium IDE for accurate element location and explicit waits for dynamic content. Avoid common mistakes such as neglecting resource management and not using headless mode in production.
Conclusion
In this blog post, we discussed various techniques for locating HTML elements using Selenium in Python, which is crucial for tasks like web scraping and automation. By leveraging methods such as findElement and findElements and utilizing diverse strategies, including IDs, class names, link texts, and XPath queries in Selenium, users can efficiently target elements within web pages.
We also explored advanced techniques for handling dynamic IDs, hidden elements, and iframes, highlighting the versatility and power of Selenium. Whether you're automating workflows or scraping data, understanding these element locating methods will enhance your ability to interact with web pages effectively and robustly.
Read similar blog posts like Selenium comparisons with Puppeteer and Scrapy, or check out our resources pages to find out the best practices with other coding languages, such as finding elements with XPath in JavaScript, or how to get class names in Python. Also, you can learn more about Selenium vs. BeautifulSoup for web scraping.
Frequently asked questions
Can Selenium be used with proxies?
Yes, proxies can be integrated. Read our blog post to learn more about using proxies in Selenium.
About the author

Enrika Pavlovskytė
Former Copywriter
Enrika Pavlovskytė was a Copywriter at Oxylabs. With a background in digital heritage research, she became increasingly fascinated with innovative technologies and started transitioning into the tech world. On her days off, you might find her camping in the wilderness and, perhaps, trying to befriend a fox! Even so, she would never pass up a chance to binge-watch old horror movies on the couch.
All information on Oxylabs Blog is provided on an "as is" basis and for informational purposes only. We make no representation and disclaim all liability with respect to your use of any information contained on Oxylabs Blog or any third-party websites that may be linked therein. Before engaging in scraping activities of any kind you should consult your legal advisors and carefully read the particular website's terms of service or receive a scraping license.
Related articles





Try Web Scraper API
Choose Oxylabs' Web Scraper API to gather real-time public data hassle-free.

Get the latest news from data gathering world
Scale up your business with Oxylabs®
Proxies
Advanced proxy solutions
Data Collection
Datasets
Resources
Innovation hub
Try Web Scraper API
Choose Oxylabs' Web Scraper API to gather real-time public data hassle-free.