175M+ ethically sourced IPs built for the highest reliability.
High-speed, cost-effective proxies built for any scraping workload.
Premium static residential proxies from trusted ASNs for most difficult targets.
Dedicated IPs from premium ASNs for demanding scraping.

AI-powered proxy solution for optimized web scraping performance.

20M+ IP addresses from real mobile devices for precise targeting.

Free Chrome proxy manager extension that works with any proxy provider.

Free Android proxy manager app that works with any proxy provider.

Free community-driven tools to improve your web scraping projects.
Web Scraper API
All-in-one web data collection platform for every stage of web scraping.
Fast Search API
Ultra-fast organic search results scraper tailored for AI workflows.
Headless Browser
Advanced browser automation solution for AI agents and scraping.
AI Studio
A suite of AI-powered tools for various scraping projects.

Documentation
All features, parameters, and integration details, backed by code samples in every coding language.
Tutorials, samples, and guides.
Latest fixes and features.






![]() AI Summary:
AI Summary:
This tutorial shows how to build a Python price tracker that scrapes product prices from e-commerce sites, saves results to CSV, and sends email alerts when prices drop below a set threshold. It uses Requests, BeautifulSoup, and Pandas. The article also demonstrates a no-code alternative using AI Studio's AI-Scraper for quick price comparisons.
Building a price tracker is a great way to learn Python automation. It’s a particularly convenient project for beginners as the resulting script can be used right away.
This article explains how to build a scalable Python price tracker for any website and immediately deploy it to various eCommerce sites.
For your convenience, we also prepared this tutorial in a video format:

What is a price tracker?
A price tracker is a program that periodically scrapes product pricings on eCommerce sites and extracts the changes, like a simple form of web scraping price monitoring used by competitive businesses.
Apart from the basic function of web scraping, price tracking can include additional functionalities such as sending an email alert when the product prices fall below a certain threshold.
A simple Python price tracker script could be used for personal tasks, while more complex price tracker API solutions are employed to track the prices of millions of products. If you're wondering what it takes to build a data-gathering tool for a major e-commerce platform, feel free to check out our various tutorials, like how to web scrape Amazon with Python, web scraping Etsy, scraping AliExpress, scraping Walmart, and scraping Wayfair.
Reasons to monitor prices
There are countless benefits of price monitoring. For example, you may be able to buy a desirable product at the lowest price.
The reasons for a company to monitor competitors’ prices would be more substantial. For example, detecting when a competitor is running a sale on the same product or positioning your offerings at a price that returns the best profit margins. Price monitoring would allow you to adjust prices just the right amount.
Building the price monitoring script
This section will showcase how to make a price tracker with a Python script performing price tracking for multiple products. We’ll use web scraping techniques to extract the product data and automated emails to send notification alerts about price changes.
Project requirements
The following price monitoring script works with Python version 3.6 and above. The recommended libraries are as follows:
Requests – for sending HTTP requests. In other words, for downloading web pages without a browser. It’s the essential library for the upcoming price monitoring script.
BeautifulSoup – for querying the HTML for specific elements. It’s a wrapper over a parser library.
lxml – for parsing the HTML. An HTML retrieved by the Requests library is a string that requires parsing into a Python object before querying. Instead of directly using this library, we’ll use BeautifulSoup as a wrapper for a more straightforward API.
Price-parser – a library useful for every price monitoring script. It helps to extract the price component from a string that contains it.
smtplib – for sending emails.
Pandas – for filtering product data and reading and writing CSV files.
Optionally, creating a virtual environment will keep the whole process more organized:
$ python3 -m venv .venv
$ source .venv/bin/activateTo install the dependencies, open the terminal and run the following command:
$ pip install pandas requests beautifulsoup4 price-parser lxmlNote that the smtlib library is part of the Python Standard Library and doesn’t need to be installed separately.
Once the installation is complete, create a new Python file and add the following imports:
import smtplib
import pandas as pd
import requests
from bs4 import BeautifulSoup
from price_parser import PriceAdditionally, add the following lines for initial configuration:
PRODUCT_URL_CSV = "products.csv"
SAVE_TO_CSV = True
PRICES_CSV = "prices.csv"
SEND_MAIL = TrueThe CSV that contains the target URLs is supplied as PRODUCT_URL_CSV.
If the SAVE_TO_CSV flag is set to True, the fetched prices will be saved to the CSV file specified as PRICES_CSV.
SEND_MAIL is a flag that can be set to True to send email alerts.
Reading a list of product URLs
The easiest way to store and manage the product URLs is to keep them in a CSV or JSON file. This time we’ll use CSV as it’s easily updatable using a text editor or spreadsheet application.
The CSV should contain at least two fields — url and alert_price. The product’s title can be extracted from the product URL or stored in the same CSV file. If the price monitor finds product price dropping below a value of the alert_price field, it’ll trigger an email alert.

A sample of product URLs in CSV
The CSV file can be read and converted to a dictionary object using Pandas. Let’s wrap this up in a simple function:
def get_urls(csv_file):
df = pd.read_csv(csv_file)
return dfThe function will return a Pandas’ DataFrame object that contains three columns — product, URL, and alert_price (see the image above).
Scraping the prices
The initial step is to loop over the target URLs.
Note that the get_urls() returns a DataFrame object.
To run a loop, first use the to_dict() method of Pandas. When the to_dict method is called with the parameter as records, it converts the DataFrame into a list of dictionaries.
Run a loop over each dictionary as follows:
def process_products(df):
for product in df.to_dict("records"):
# product["url"] is the URLWe’ll revisit this method after writing two additional functions. The first function is to get the HTML and the second function is to extract the price from it.
To get the HTML from response for each URL, run the following function:
def get_response(url):
response = requests.get(url)
return response.textNext, create a BeautifulSoup object according to the response and locate the price element using a CSS selector. Use the Price-parser library to extract the price as a float for comparison with the alert price. If you want to better understand how the Price-parser library works, head over to our GitHub repository for examples.
The following function will extract the price from the given HTML, returning it as a float:
def get_price(html):
soup = BeautifulSoup(html, "lxml")
el = soup.select_one(".price_color")
price = Price.fromstring(el.text)
return price.amount_floatNote that the CSS selector used in this example is specific to the scraping target. If you are working with any other site, this is the only place where you would have to change the code.
We’re using BeautifulSoup to locate an element containing the price via CSS selectors. The element is stored in the el variable. The text attribute of the el tag, el.text, contains the price and currency symbol. Price-parser parses this string to extract the price as a float value.
There is more than one product URL in the DataFrame object. Let’s loop over all the rows and update the DataFrame with new information.
The easiest approach is to convert each row into a dictionary. This way, you can read the URL, call the get_price() function, and update the required fields.
We’ll add two new keys — the extracted price (price) and a boolean value (alert), which filters rows for sending an email.
The process_products() function can now be extended to demonstrate the aforementioned sequence:
def process_products(df):
updated_products = []
for product in df.to_dict("records"):
html = get_response(product["url"])
product["price"] = get_price(html)
product["alert"] = product["price"] < product["alert_price"]
updated_products.append(product)
return pd.DataFrame(updated_products)This function will return a new DataFrame object containing the product URL and a name read from the CSV. Additionally, it includes the price and alert flag used to send an email on a price drop.
Saving the output
The final DataFrame containing the updated product data can be saved as CSV using a simple call to the to_csv() function.
Additionally, we’ll check the SAVE_TO_CSV flag as follows:
if SAVE_TO_CSV:
df_updated.to_csv(PRICES_CSV, mode="a")You’ll notice that the mode is set to "a", which stands for “append” to ensure new data is appended if the CSV file is present.
Sending email alerts
Optionally, you can send an email alert on price drop based on the alert flag. First, create a function that filters the data frame and returns email’s subject and body:
def get_mail(df):
subject = "Price Drop Alert"
body = df[df["alert"]].to_string()
subject_and_message = f"Subject:{subject}\n\n{body}"
return subject_and_messageNow, using smtplib, create another function that sends alert emails:
def send_mail(df):
message_text = get_mail(df)
with smtplib.SMTP("smtp.server.address", 587) as smtp:
smtp.starttls()
smtp.login(mail_user, mail_pass)
smtp.sendmail(mail_user, mail_to, message_text)This code snippet assumes that you’ll set the variables mail_user, mail_pass, and mail_to.
Putting everything together, this is the main function:
def main():
df = get_urls(PRODUCT_URL_CSV)
df_updated = process_products(df)
if SAVE_TO_CSV:
df_updated.to_csv(PRICES_CSV, index=False, mode="a")
if SEND_MAIL:
send_mail(df_updated)Add the lines shown below to execute this function and run the entire code:
if __name__ == "__main__":
main()If you wish to run this automatically at certain intervals, use cronjob on macOS/Linux or Task Scheduler on Windows.
Alternatively, you can also deploy this price monitoring script on any cloud service environment.
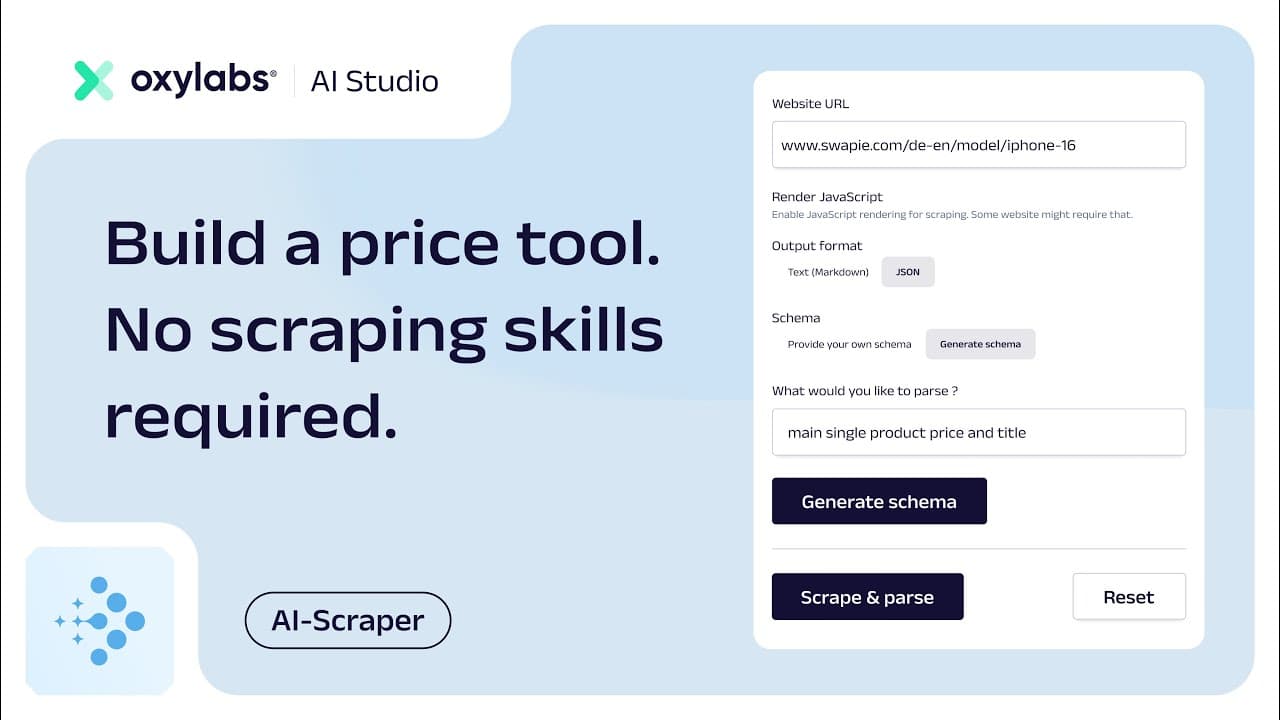
Building a price comparison tool with AI Studio's AI-Scraper
Now, let’s look at how you can build a price comparison tool using simple, plain English with AI Studio’s AI-Scraper – an easy-to-use tool that takes care of both scraping and parsing processes and allows you to extract structured data from even hard-to-scrape websites.
For this example, we’ll build an iPhone 16 price comparison tool by using the app’s user interface and by implementing it with the Python SDK.
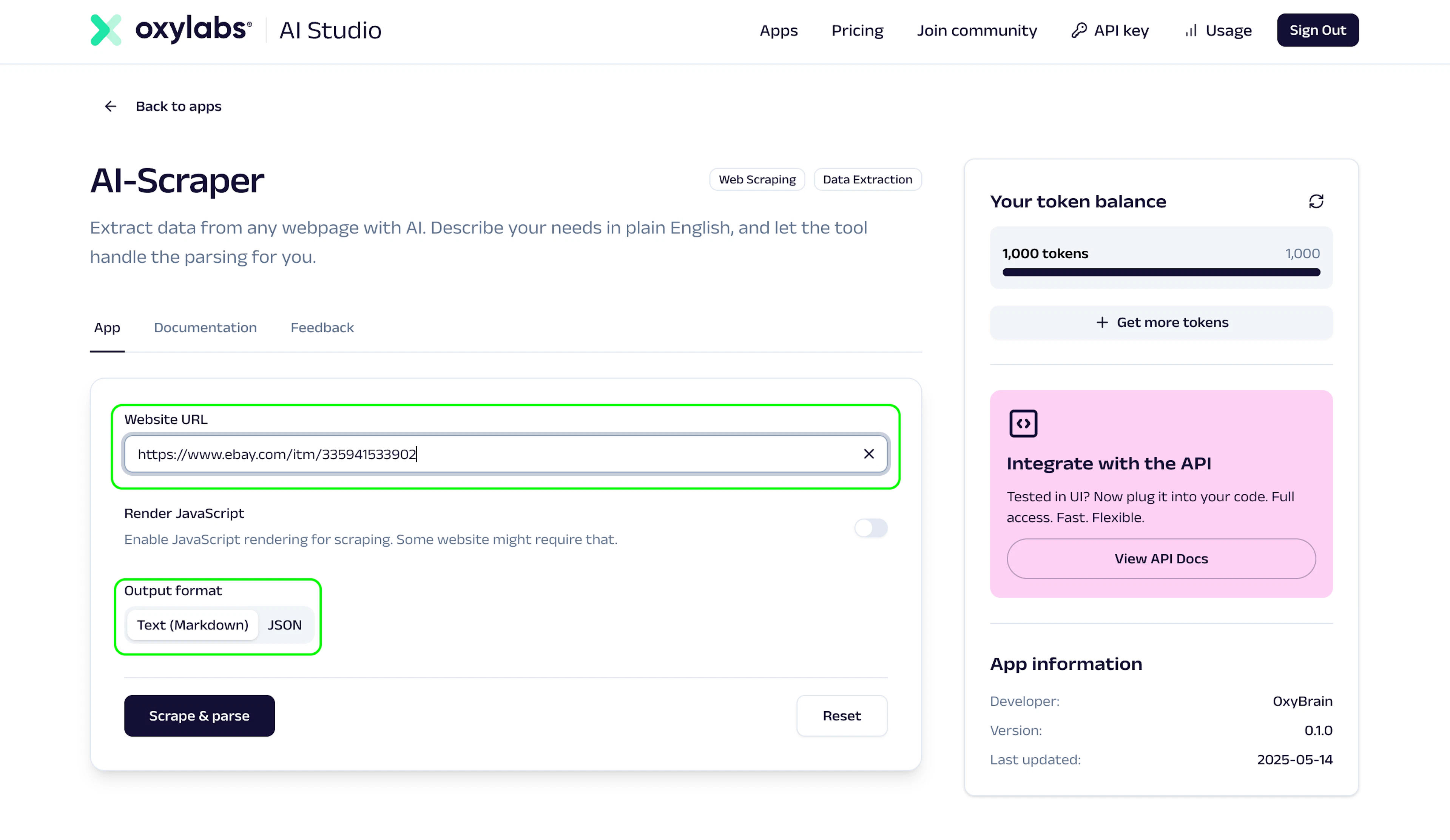
Provide a URL
Head to AI-Scraper’s page and provide a website link you wish to scrape. From there, you can either retrieve a markdown output or get structured JSON data.
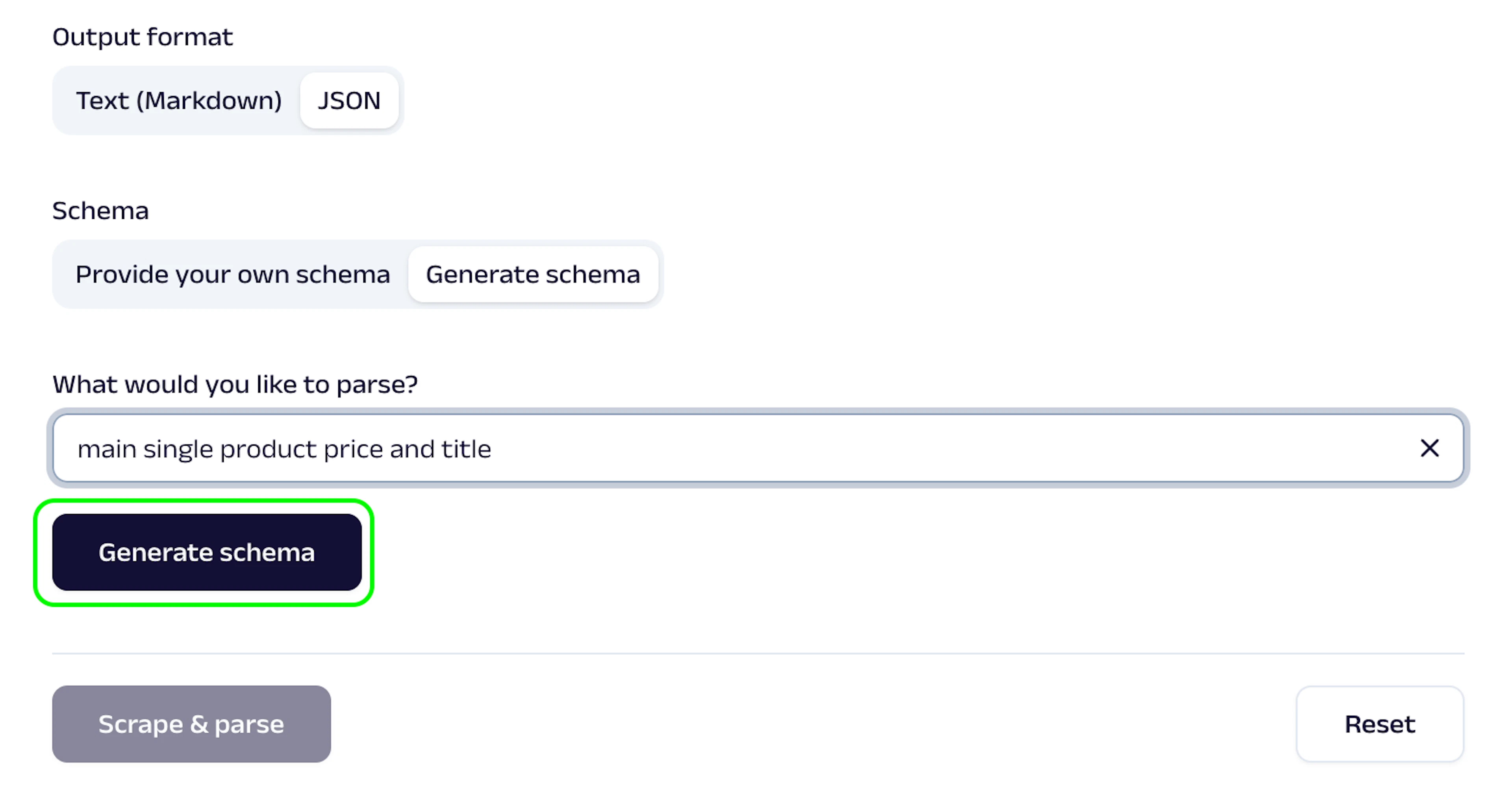
Define a schema
If you select the JSON output option, you will be prompted to define a schema that will be used to parse the data from the website. After clicking on Generate schema, AI will generate the schema, and you’ll be able check if everything is correct. If not, you can make adjustments manually or regenerate the schema.
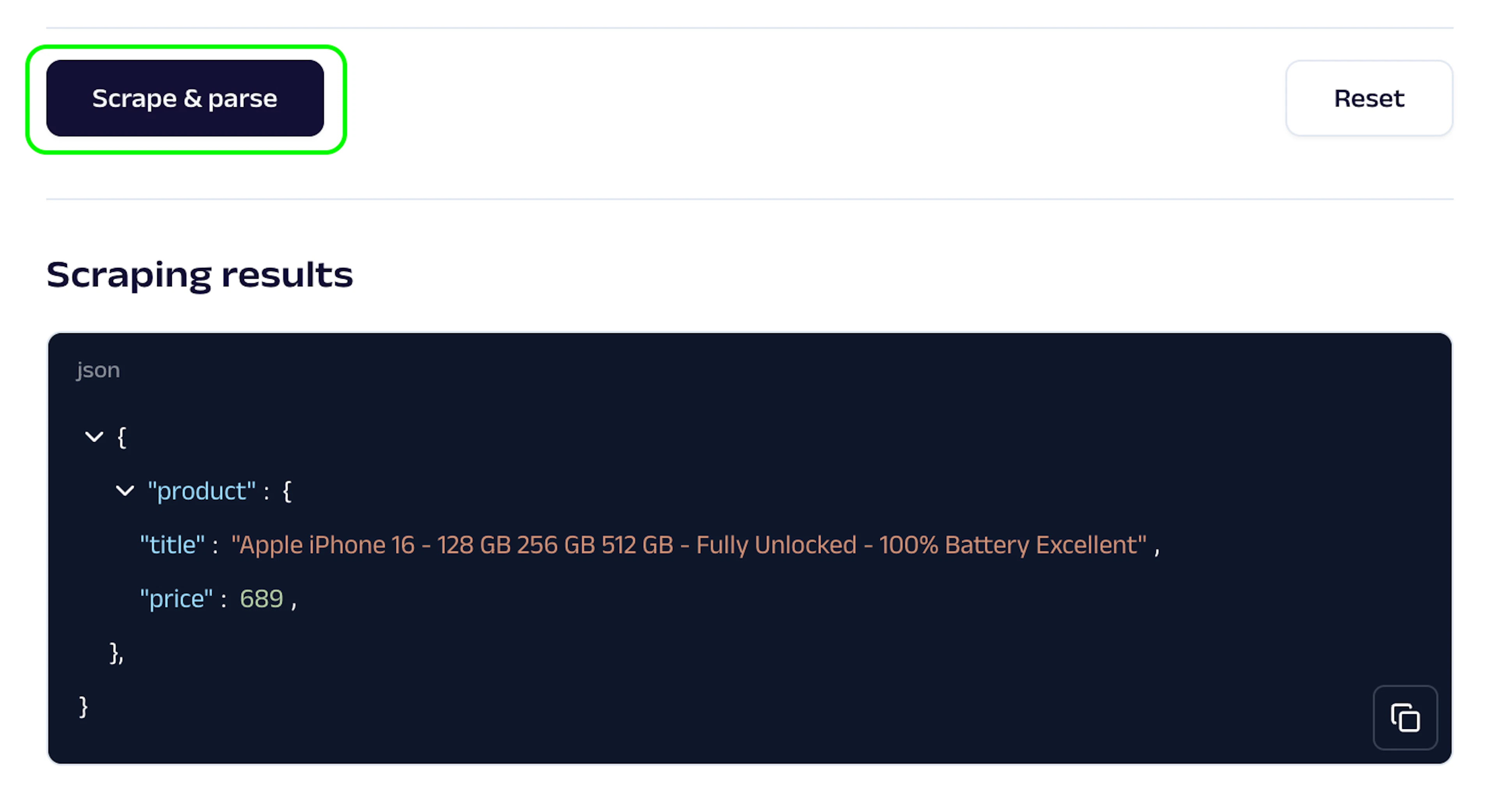
Scrape & parse
Then, click on the Scrape & parse button and in just a few seconds you’ll see the retrieved title and price of the product.
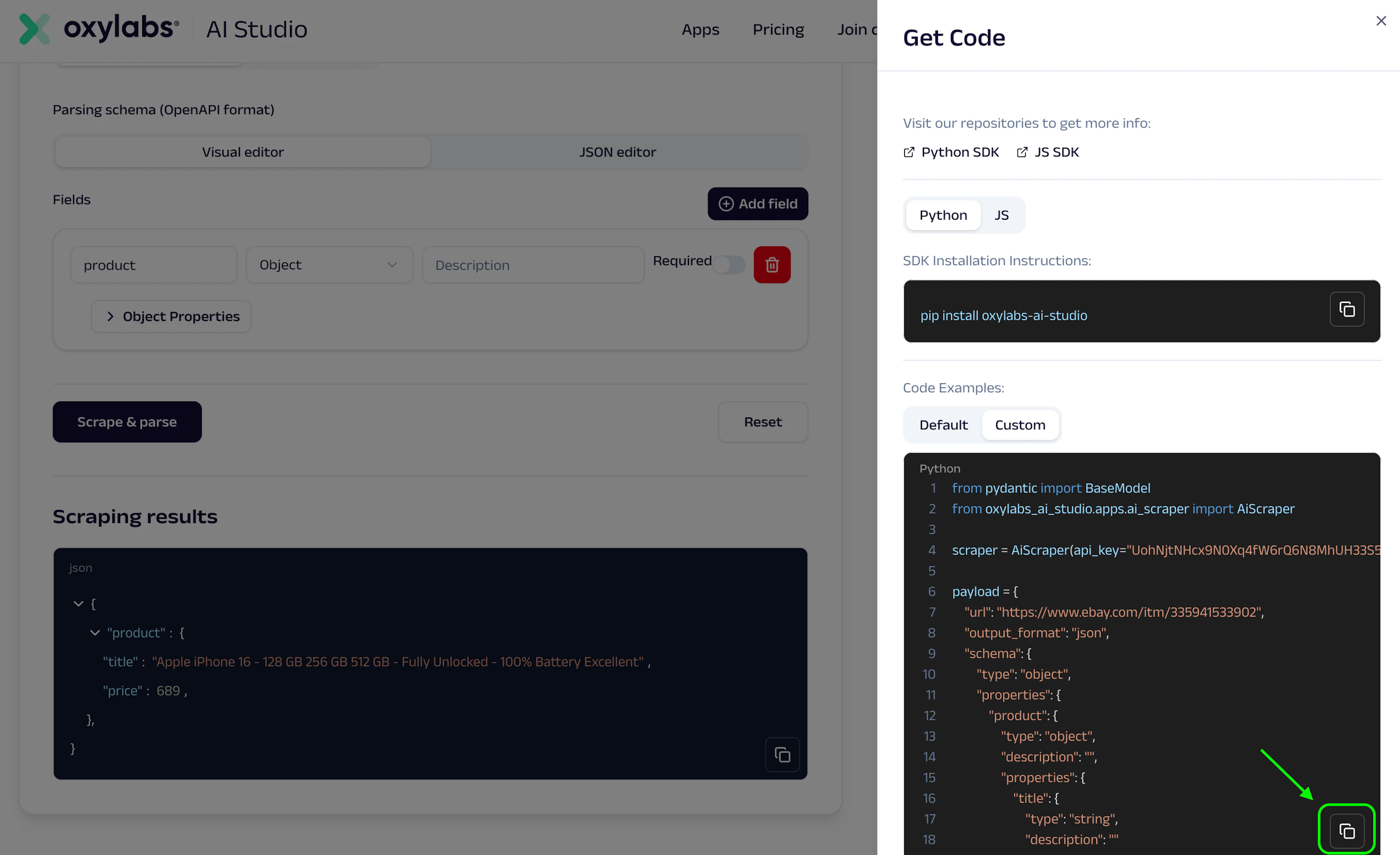
Get code
Done! Now, you’re ready to integrate the output into your data gathering processes on a larger scale. Simply copy the Python code we’ve already prepared for you based on the data you just entered in the user interface.
To see the rest of the tutorial on how to implement and run the code with the Python SDK, check out our full video walkthrough:
Conclusion
The Python prices tracking script showcased in this article can fetch product prices and other product data from any number of product URLs. The functionality of this price monitor can be expanded further according to your preferences. For example, instead of saving to a CSV, you can save the information to a database.
Furthermore, you can modify the same code to build a specialized Python Amazon price tracker or adapt it as an eBay price tracker in just a few additional steps.
If you’re running a price monitoring script at scale, you’re likely to require reliable Residential Proxies. You can also check our complete solutions for price monitoring: Amazon Product Data API, Target Scraper API, Walmart Product API, Lowe's Scraper API, and Etsy Scraper API.
For complete code samples, see our GitHub repository. Check our blog for more tutorials on web scraping with Python, PHP, and Ruby, or take a look at a more detailed guide on how to avoid blocks when web scraping.
Frequently asked questions
Is there a way to track prices?
Yes, you can track prices by manually checking websites, but it's more efficient to use an automated price tracker software or a dedicated price monitoring API. These tools, which can be custom-built or used as pre-made price tracking software solutions, automatically monitor products and alert you about price changes.
How to make a price spreadsheet?
How to build an Amazon price tracker?
Try out Residential Proxies today
Forget about IP blocks and CAPTCHAs with 175M+ premium proxies located in 195 countries.
High-quality proxy servers
Discover the benefits of using Oxylabs' high-quality services.
About the author

Augustas Pelakauskas
Former Senior Technical Copywriter
Augustas Pelakauskas was a Senior Technical Copywriter at Oxylabs. Coming from an artistic background, he is deeply invested in various creative ventures - the most recent being writing. After testing his abilities in freelance journalism, he transitioned to tech content creation. When at ease, he enjoys the sunny outdoors and active recreation. As it turns out, his bicycle is his fourth-best friend.
All information on Oxylabs Blog is provided on an "as is" basis and for informational purposes only. We make no representation and disclaim all liability with respect to your use of any information contained on Oxylabs Blog or any third-party websites that may be linked therein. Before engaging in scraping activities of any kind you should consult your legal advisors and carefully read the particular website's terms of service or receive a scraping license.
Related articles

Guide to Using Google Sheets for Basic Web Scraping

Vytenis Kaubrė
2025-07-18

Web Crawler vs Web Scraper: The Differences

Gabija Fatėnaitė
2024-10-04
![Automated Web Scraper With Python AutoScraper [Guide]](https://oxylabs.io/oxylabs-web/ZpBhlx5LeNNTxEcW_eba26704-d9e7-4562-aaf4-0375a6bb9693_Python-Web-Scraping-1200x600.png?auto=format%2Ccompress&rect=0%2C0%2C1200%2C600&w=3840&h=600&q=75)


Get the latest news from data gathering world
Scale up your business with Oxylabs®
Proxies
Advanced proxy solutions
Data Collection
Datasets
Resources
Innovation hub
Try out Residential Proxies today
Forget about IP blocks and CAPTCHAs with 175M+ premium proxies located in 195 countries.
High-quality proxy servers
Discover the benefits of using Oxylabs' high-quality services.