175M+ ethically sourced IPs built for the highest reliability.
High-speed, cost-effective proxies built for any scraping workload.
Premium static residential proxies from trusted ASNs for most difficult targets.
Dedicated IPs from premium ASNs for demanding scraping.

AI-powered proxy solution for optimized web scraping performance.

20M+ IP addresses from real mobile devices for precise targeting.

Free Chrome proxy manager extension that works with any proxy provider.

Free Android proxy manager app that works with any proxy provider.

Free community-driven tools to improve your web scraping projects.
Web Scraper API
All-in-one web data collection platform for every stage of web scraping.
Fast Search API
Ultra-fast organic search results scraper tailored for AI workflows.
Headless Browser
Advanced browser automation solution for AI agents and scraping.
AI Studio
A suite of AI-powered tools for various scraping projects.

Documentation
All features, parameters, and integration details, backed by code samples in every coding language.
Tutorials, samples, and guides.
Latest fixes and features.







![]() AI Summary:
AI Summary:
This guide walks through two ways to scrape product data (titles, prices, ratings, and descriptions) from Wayfair using Python. The first approach builds a custom scraper with Requests, Beautiful Soup, and residential proxies. The second uses Oxylabs' Wayfair Scraper API, which handles bot traffic systems like reCAPTCHA automatically. Both methods export results to CSV or JSON for use in pricing intelligence, competitor monitoring, and trend analysis.
Wayfair is a retailer specializing in furniture and home appliances. As a big player in the home appliances business, it’s a major source of public web data, especially for the e-commerce industry.
On the Wayfair website, you can find various product data types – potential targets for analysis. When collected at scale and in real time, such data can be used to forecast trends and check featured data fluctuations.
With Oxylabs Wayfair Scraper API and residential proxies, you can extract structured data to weigh your stance against the competition, position a product at a golden spot to maximize revenues, or simply buy an item at the lowest price. No matter the use case, the API’s maintenance-free infrastructure will save time and effort.
Collecting and analyzing e-commerce data helps maintain a competitive advantage with the following applications:
Pricing intelligence – create a long-term Wayfair price scraping strategy. You can also check our blog post about building a Wayfair price tracker with Python.
Dynamic pricing – adjust your prices according to the competition.
Real-time product monitoring – check various product attributes.
MAP monitoring – track MAP violators to enforce policy agreements.
The following tutorial will explore how to scrape Wayfair to extract data. Read on for the page layout overview, project environment preparation, Wayfair product data extraction, and export to CSV or JSON format.
Overview of Wayfair page layout
Before getting technical, let’s analyze the Wayfair page layout. Here are some of the most relevant types.
Search result page
The search result page appears when searching for products. For example, if you search Wayfair for the term Sofa, the search result will be similar to the one below:
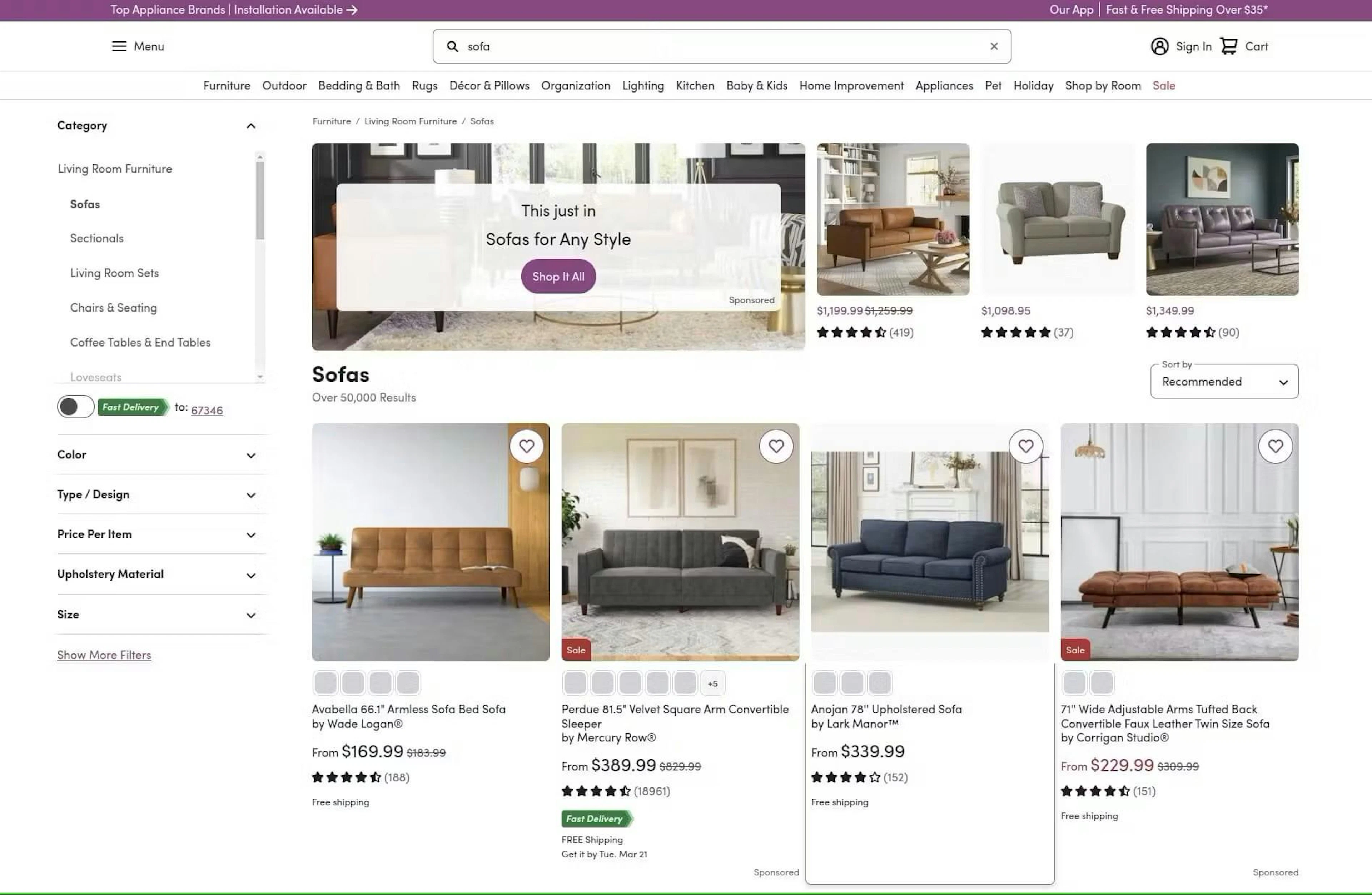
Search results page
You can extract all the products listed for the search term “Sofa” as well as their links, titles, prices, ratings, and images.
Product listing page
Product listing appears when you click on a product to see the details. It shows all the product information in addition to the main data already visible on the search result page.
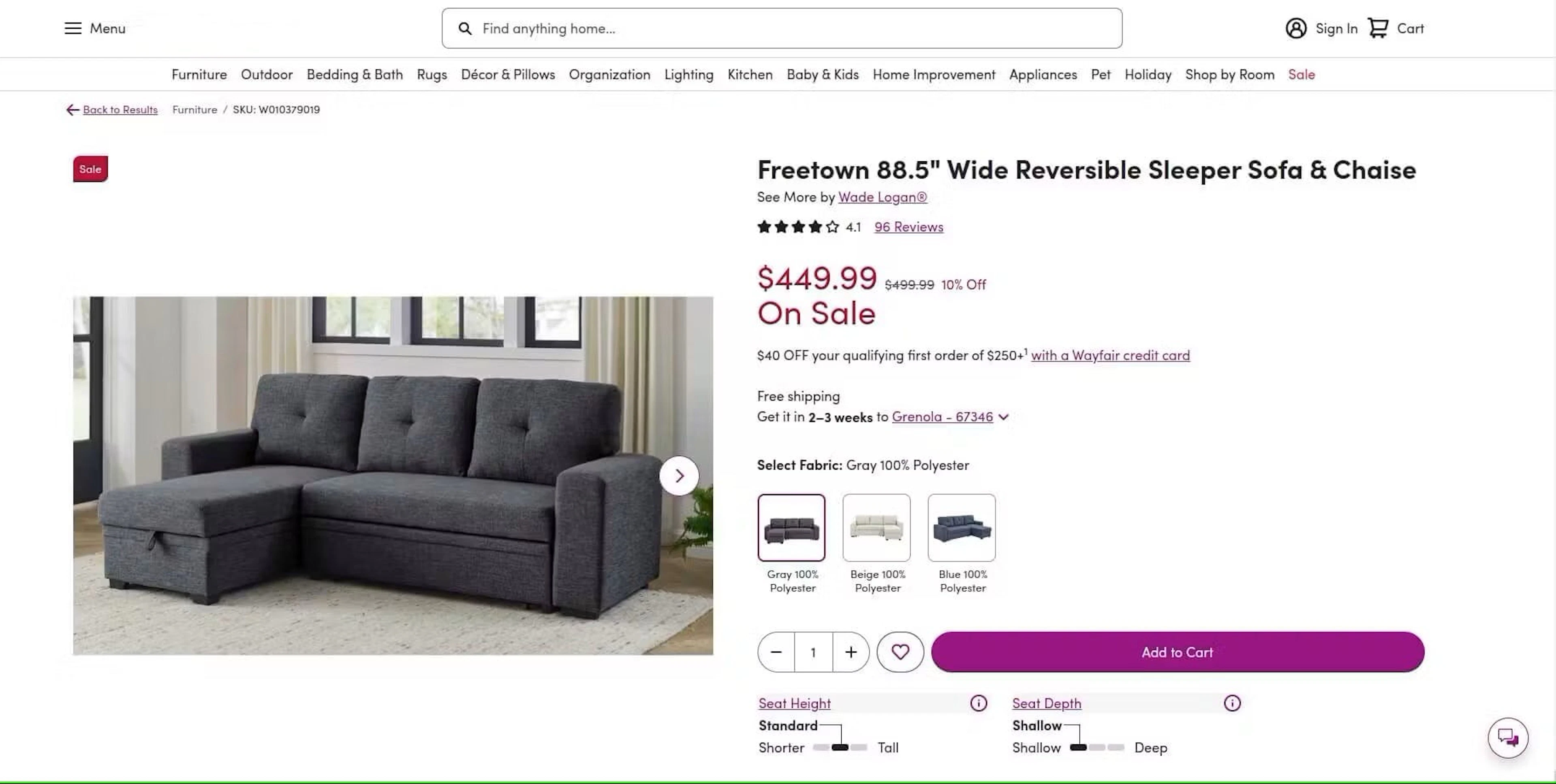
Product listing page
reCAPTCHA protection page
The reCAPTCHA protection page appears when Wayfair detects unusual browsing behavior, such as repeated or too-fast (for an organic user) navigation from page to page, indicating the use of automated scripts such as scrapers. The page looks similar to the one below:
reCAPTCHA protection page
Handling Wayfair scraping challenges
Elaborate request management systems and an ever-changing web layout make automated data extraction difficult. As a consequence, when collecting data from Wayfair at scale, your IPs can get flagged, not to mention constantly micromanaging the script to fix code breaks.
Wayfair is using Google’s reCAPTCHA service to monitor for automated scrapers. It is an anti-bot protection service that uses fingerprinting algorithms and behavioral pattern recognition.
Oxylabs Wayfair API provides out-of-the-box tool for handling such bot traffic management systems by providing proxy solutions, custom headers, user agents, and other features. This immensely eases the process and simplifies the scraper you would have to build.
Compared to regular scrapers, Wayfair Scraper API has multiple advantages, including:
ML-driven proxy management
Dynamic browser fingerprinting
JavaScript rendering
Claim your free trial
Get a free trial to test our Web Scraper API for your use case.
Up to 2K results
No credit card required
Set up the project environment
Install Python
This tutorial is written using Python 3.13.2. However, it should also work with the older or latest version of Python 3. Then, set up a Python virtual environment in a new folder and activate it:
python -m venv .venv
source .venv/bin/activateIf you’re using a Windows device, you can activate the .venv with your command prompt like shown below:
.venv\Scripts\activate.batInstall dependencies
Next, install the following dependencies in the activated .venv by executing the following pip command:
pip install requests bs4 pandasThis command will install the Requests, Beautiful Soup, and Pandas libraries. These modules will help you send requests, parse Wayfair product data, and store it in CSV and JSON formats.
How to scrape Wayfair with proxies
Without proxy servers and a sophisticated scraping approach, you’re likely to run into various blocks, such as Wayfair returning 429 status codes and no data. For this reason, we’ll show you how to utilize residential proxies with a custom scraping solution. You may also utilize other proxy products.
1. Set the target URL and HTTP headers
Let’s begin by importing the Requests, Beautiful Soup, and Pandas libraries in a new Python file:
import requests
from bs4 import BeautifulSoup
import pandas as pdNext, add the Wayfair product URL you want to scrape. For example, let’s use this Wayfair product page:
url = (
'https://www.wayfair.com/furniture/pdp/'
'serta-monroe-full-size-convertible-sofa-zpcd2290.html'
)Then, define the HTTP headers dictionary to mimic a real web browser request:
headers = {
'User-Agent': (
'Mozilla/5.0 (Macintosh; Intel Mac OS X 14.7; rv:138.0) '
'Gecko/20100101 Firefox/138.0'
),
'Accept': (
'text/html,application/xhtml+xml,application/xml;'
'q=0.9,image/avif,image/webp,image/apng,*/*;'
'q=0.8,application/signed-exchange;v=b3;q=0.7'
),
'Accept-Language': 'en-US,en;q=0.9',
'DNT': '1',
'Connection': 'keep-alive',
'Upgrade-Insecure-Requests': '1'
}When scaling your scraping operations, you may want to switch the User-Agent string with each request, or, ideally, rotate different sets of HTTP header.
2. Configure proxies
The below code will ensure your Wayfair scraper will make requests through a residential IP address based in the United States. Feel free to modify the proxy address to suit your needs.
USERNAME, PASSWORD = 'PROXY_USERNAME', 'PROXY_PASSWORD'
proxies = {
'http': f'https://{USERNAME}:{PASSWORD}@us-pr.oxylabs.io:10000',
'https': f'https://{USERNAME}:{PASSWORD}@us-pr.oxylabs.io:10000'
}3. Send a request
Let’s bring all the request settings together by making a GET request to the target URL:
try:
response = requests.get(url=url, headers=headers, proxies=proxies)
response.raise_for_status()
except Exception as e:
print(e)4. Parse Wayfair data
Once the Requests library returns the HTML from the Wayfair page, you can use Beautiful Soup to extract the specific data you need:
soup = BeautifulSoup(response.text, 'html.parser')Extract the title

You can target the product’s title with a simple CSS selector: header > h1.
title = soup.select_one('header > h1')Extract the price

Getting the product’s price requires a more sophisticated selector: .SFPrice > div:first-child > span:first-child.
price = soup.select_one('.SFPrice > div:first-child > span:first-child')Extract the rating

The product rating value is accessible via the .ProductRatingNumberWithCount-rating selector.
rating = soup.select_one('.ProductRatingNumberWithCount-rating')Extract the description
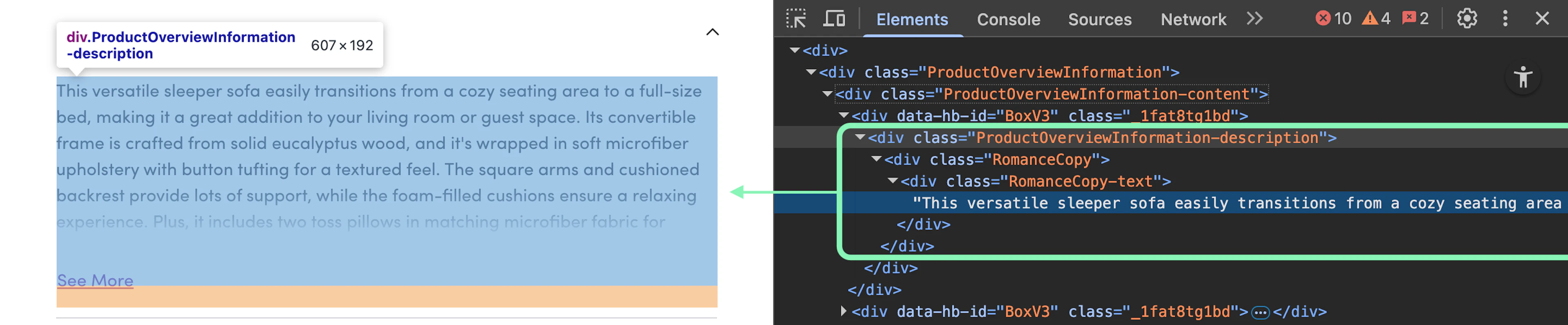
You can grab the product description using the .ProductOverviewInformation-description selector.
description = soup.select_one('.ProductOverviewInformation-description')After that, save all the Wayfair product data to a list and extract the actual text from each element:
data = [{
'title': title.get_text().strip(),
'price': price.get_text().strip(),
'rating': rating.get_text().strip(),
'description': description.get_text().strip()
}]5. Store results to a file
You can finalize your Wayfair scraper by creating a data frame object and storing the relevant data to CSV file using the Pandas library:
df = pd.DataFrame(data)
df.to_csv('wayfair_data.csv', index=False)You may also easily save the parsed data to a JSON format. Make sure to pass an additional parameter, orient, to indicate the need for JSON data in records format:
df.to_json('product_data.json', orient='records')Full code sample
import requests
from bs4 import BeautifulSoup
import pandas as pd
url = (
'https://www.wayfair.com/furniture/pdp/'
'serta-monroe-full-size-convertible-sofa-zpcd2290.html'
)
headers = {
'User-Agent': (
'Mozilla/5.0 (Macintosh; Intel Mac OS X 14.7; rv:138.0) '
'Gecko/20100101 Firefox/138.0'
),
'Accept': (
'text/html,application/xhtml+xml,application/xml;'
'q=0.9,image/avif,image/webp,image/apng,*/*;'
'q=0.8,application/signed-exchange;v=b3;q=0.7'
),
'Accept-Language': 'en-US,en;q=0.9',
'DNT': '1',
'Connection': 'keep-alive',
'Upgrade-Insecure-Requests': '1'
}
USERNAME, PASSWORD = 'PROXY_USERNAME', 'PROXY_PASSWORD'
proxies = {
'http': f'https://{USERNAME}:{PASSWORD}@us-pr.oxylabs.io:10000',
'https': f'https://{USERNAME}:{PASSWORD}@us-pr.oxylabs.io:10000'
}
try:
response = requests.get(url=url, headers=headers, proxies=proxies)
response.raise_for_status()
except Exception as e:
print(e)
soup = BeautifulSoup(response.text, 'html.parser')
title = soup.select_one('header > h1')
price = soup.select_one('.SFPrice > div:first-child > span:first-child')
rating = soup.select_one('.ProductRatingNumberWithCount-rating')
description = soup.select_one('.ProductOverviewInformation-description')
data = [{
'title': title.get_text().strip(),
'price': price.get_text().strip(),
'rating': rating.get_text().strip(),
'description': description.get_text().strip()
}]
df = pd.DataFrame(data)
df.to_csv('wayfair_data.csv', index=False)When executed, you should see a wayfair_data.csv file saved in your project’s directory while the data itself should look like this:

How to scrape Wayfair product data with API
Now, let’s see how to use Oxylabs Wayfair API to extract data from the Wayfair product page. Make sure to create an Oxylabs account on the dashboard and claim a free trial.
1. Import modules and set the target URL
You’ll only need the Requests and Pandas libraries, while the target URL remains the same as previously:
import requests
import pandas as pd
url = (
'https://www.wayfair.com/furniture/pdp/'
'serta-monroe-full-size-convertible-sofa-zpcd2290.html'
)2. Set the request payload with a parsing logic
Instead of relying on Beautiful Soup for data extraction, you can take advantage of the API’s Custom Parser feature. We also have an AI-powered scraping assistant that lets you generate the same parsing instructions by using English prompts (see prompt examples here).
Let’s start by defining the selectors dictionary that uses the same CSS selectors we’ve configured previously:
selectors = {
'title': 'header > h1',
'price': '.SFPrice > div:first-child > span:first-child',
'rating': '.ProductRatingNumberWithCount-rating',
'description': '.ProductOverviewInformation-description'
}Next, you can set the request payload that tells Wayfair Scraper API how to handle the network request for Wayfair data scraping. We’ve set the geo_location parameter to United States and defined the parsing_instructions logic:
payload = {
'source': 'universal',
'url': url,
'geo_location': 'United States',
'parse': True,
'parsing_instructions': {
field: {
'_fns': [
{'_fn': 'css_one', '_args': [selector]},
{'_fn': 'element_text'}
]
}
for field, selector in selectors.items()
}
}Since all of the parsing instructions use the same structure, you can easily make a loop that picks the field name and selector for each entry in the selectors dict.
3. Send a scraping request
Make sure to enter your Web Scraper API user credentials. The Requests library helps us send a POST request to the API:
USERNAME, PASSWORD = 'API_USERNAME', 'API_PASSWORD'
response = requests.post(
'https://realtime.oxylabs.io/v1/queries',
auth=(USERNAME, PASSWORD),
json=payload
)
response.raise_for_status()4. Save Wayfair data to a file
Once the API processes your request, it will send back a response which holds the scraped data in ['results'][0]['content']. You can access this directly from the response.json() and pass it over to Pandas to save it all into a CSV file:
data = [response.json()['results'][0]['content']]
df = pd.DataFrame(data)
df.to_csv('wayfair_data_API.csv', index=False)Full code sample
import requests
import pandas as pd
url = (
'https://www.wayfair.com/furniture/pdp/'
'serta-monroe-full-size-convertible-sofa-zpcd2290.html'
)
selectors = {
'title': 'header > h1',
'price': '.SFPrice > div:first-child > span:first-child',
'rating': '.ProductRatingNumberWithCount-rating',
'description': '.ProductOverviewInformation-description'
}
payload = {
'source': 'universal',
'url': url,
'geo_location': 'United States',
'parse': True,
'parsing_instructions': {
field: {
'_fns': [
{'_fn': 'css_one', '_args': [selector]},
{'_fn': 'element_text'}
]
}
for field, selector in selectors.items()
}
}
USERNAME, PASSWORD = 'API_USERNAME', 'API_PASSWORD'
response = requests.post(
'https://realtime.oxylabs.io/v1/queries',
auth=(USERNAME, PASSWORD),
json=payload
)
response.raise_for_status()
data = [response.json()['results'][0]['content']]
df = pd.DataFrame(data)
df.to_csv('wayfair_data_API.csv', index=False)When you run the code, it will store results to the wayfair_data_API.csv file:

Comparing different scraping methods
| Scraping Approach | Pros | Cons |
|---|---|---|
| No Proxies | Simple setup and no proxy-related costs | Frequent connection interruptions, CAPTCHAs, inability to scrape region-exclusive data, limited scalability |
| With Proxies | Reduced risk of IP flagging, access to geo-targeted data, improved scalability | Additional costs for proxies, requires management of proxy infrastructure (unless outsourced) |
| Using a Scraping API | Built-in IP rotation and CAPTCHA handling, scalable for enterprise use, includes browser emulation, fast setup and deployment | Subscription-based pricing, risk of vendor lock-in, possible limitations in specific data scraping scenarios |
| Custom Solutions (Selenium, Playwright) | Highly customizable, effective on dynamic, JavaScript-driven sites, self-hosting avoids recurring fees | Requires significant technical skill, developer must handle anti-blocking measures, typically slower performance than dedicated solutions |
Conclusion
Building a scraper that can send requests as an actual browser and produce authentic user behaviour is quite difficult. Also, you would have to maintain it and keep it up to date with constant changes. Such micromanagement requires in-depth knowledge and extensive scraping experience. If you're looking to streamline this process, you can buy proxy solutions or choose a reliable free proxy list to ensure smoother scraping operations.
With Wayfair Scraper API, you can shift your focus where it matters most – data analysis – instead of dealing with technicalities. The API comes with various features, including JavaScript rendering, batch requests for scraping multiple pages, as well as Google Cloud Storage and Amazon S3 support.
For more e-commerce scraping targets, follow Amazon, Etsy, and Walmart scraping guides. Oxylabs E-Commerce Scraper API (part of Web Scraper API) enables you to quickly extract data from the top 50 marketplaces.
If you have questions or face issues, get in touch via the 24/7 live chat on our homepage or email us at support@oxylabs.io.
About the author

Augustas Pelakauskas
Former Senior Technical Copywriter
Augustas Pelakauskas was a Senior Technical Copywriter at Oxylabs. Coming from an artistic background, he is deeply invested in various creative ventures - the most recent being writing. After testing his abilities in freelance journalism, he transitioned to tech content creation. When at ease, he enjoys the sunny outdoors and active recreation. As it turns out, his bicycle is his fourth-best friend.
All information on Oxylabs Blog is provided on an "as is" basis and for informational purposes only. We make no representation and disclaim all liability with respect to your use of any information contained on Oxylabs Blog or any third-party websites that may be linked therein. Before engaging in scraping activities of any kind you should consult your legal advisors and carefully read the particular website's terms of service or receive a scraping license.
Related articles






Free proxies for web scraping
Get 5 IPs for FREE by registering on the Oxylabs dashboard.
Premium proxies
Forget about IP blocks and CAPTCHAs with 175M+ premium proxies located in 195 countries.

Get the latest news from data gathering world
Scale up your business with Oxylabs®
Proxies
Advanced proxy solutions
Data Collection
Datasets
Resources
Innovation hub
Free proxies for web scraping
Get 5 IPs for FREE by registering on the Oxylabs dashboard.
Premium proxies
Forget about IP blocks and CAPTCHAs with 175M+ premium proxies located in 195 countries.