175M+ ethically sourced IPs built for the highest reliability.
High-speed, cost-effective proxies built for any scraping workload.
Premium static residential proxies from trusted ASNs for most difficult targets.
Dedicated IPs from premium ASNs for demanding scraping.

AI-powered proxy solution for optimized web scraping performance.

20M+ IP addresses from real mobile devices for precise targeting.

Free Chrome proxy manager extension that works with any proxy provider.

Free Android proxy manager app that works with any proxy provider.

Free community-driven tools to improve your web scraping projects.
Web Scraper API
All-in-one web data collection platform for every stage of web scraping.
Fast Search API
Ultra-fast organic search results scraper tailored for AI workflows.
Headless Browser
Advanced browser automation solution for AI agents and scraping.
AI Studio
A suite of AI-powered tools for various scraping projects.

Documentation
All features, parameters, and integration details, backed by code samples in every coding language.
Tutorials, samples, and guides.
Latest fixes and features.






![]() AI Summary:
AI Summary:
Scraping Etsy data is challenging due to the platform's anti-bot measures. This guide shows you how to avoid them and extract public product or shop data using specialized tools like Oxylabs Web Scraper API and residential proxies. The extracted data can then be saved to a CSV for various analytical purposes, such as price tracking, colelcting reviews, or competitor research.
Etsy is an online marketplace focusing on unique items, such as vintage and hand-crafted goods. While it might not directly compete with e-commerce giants like Amazon or eBay, Etsy has grown exponentially in recent years: as of December 31st, 2022, Etsy had over 5.4M active sellers and 89.4M active buyers.
Etsy’s significant user base enables an ideal opportunity for companies and even Etsy sellers to gain value and boost their operations. Thus, web scraping comes in handy in such a case, allowing you to extract Etsy data for:
Price and product availability tracking
Pricing strategy insights
Finding new product trends
Collecting reviews
Competitor research
Finding new leads and potential customers
In this guide, we'll overview why it's challenging to scrape Etsy and what types of public data you can scrape. Next, we'll show you how to implement Etsy scraping with Oxylabs' Etsy Scraper to get the parsed data and save it to a CSV file.
Difficulties of scraping Etsy's marketplace
Like most websites these days, Etsy employs anti-scraping measures to stop any bot activity on its website. From tracking the website users' actions to implementing CAPTCHAs – handling these Etsy anti-bot measures isn't a cakewalk.
You may need to use a proxy to constantly change your scraping requests’ IP addresses, as well as set up various headers and user agents to configure a standard browser environment. Managing all of this requires a lot of effort and in-depth knowledge, but a dedicated Etsy web scraping tool like Oxylabs’ Etsy Scraper API can immensely ease the process. It takes care of anti-bot measures with proxies, custom headers, user agents, and other features, allowing you to jump straight to further analysis of data.
With the API, you get a maintenance-free web scraping infrastructure with access to a vast proxy pool. You'll get access to E-Commerce Scraper API (part of Web Scraper API), which enables you to utilize dedicated scrapers for top online marketplaces, including Amazon, eBay, Walmart, and many more.
Overview of Etsy’s page types
There are three main types of Etsy web pages:
Product pages
This is where all the products are listed based on a search term. Etsy product pages include product information, such as:
The product image
The title
Ratings and the number of votes
Price, discount, and the discount end date
And the seller’s name
There you can also find specific tags, like “Star Seller”, “FREE shipping”, “Bestseller”, “Popular now”, and “Etsy’s pick”.
Product listings
This is a page where you can find all the information about a specific product listing. Product listings include the same information as the product pages, but you’ll also find:
More product images
More information about the seller and the number of sales made
Product highlights
Descriptions
Detailed ratings
Customer reviews
And detailed shipping information
Shop pages
Here, you’ll find more information about the seller and their items. Shop pages include details, like:
The shop title
Short description
Ratings
The number of sales
The profile of the shop’s owner
An announcement
All the items the shop sells
All the customer reviews
A detailed section about the shop
And the shop policies section
Using a web scraping tool, you can scrape Etsy product data as it's publicly available. So, let’s get into it.
Try for free
Get a free trial to test out Web Scraper API for your project needs.
Up to 2K results
No credit card required
How to scrape Etsy product data
Step 1: Sign up for an Oxylabs account
You must register for an account on the Oxylabs dashboard to use Etsy Scraper API. You can try out the API for 1-week at no cost, but if you’ve already made up your mind – choose a pricing plan that best suits your needs, and follow the steps to sign up and create an account.
Once you create an account, you’ll receive the API credentials from us. You’ll have to use them within your requests.
Step 2: Set up your web scraper
For demonstration purposes, we’ll use one of the product listings to scrape Etsy product data like the price, title, quantity, etc. The web page looks as follows:
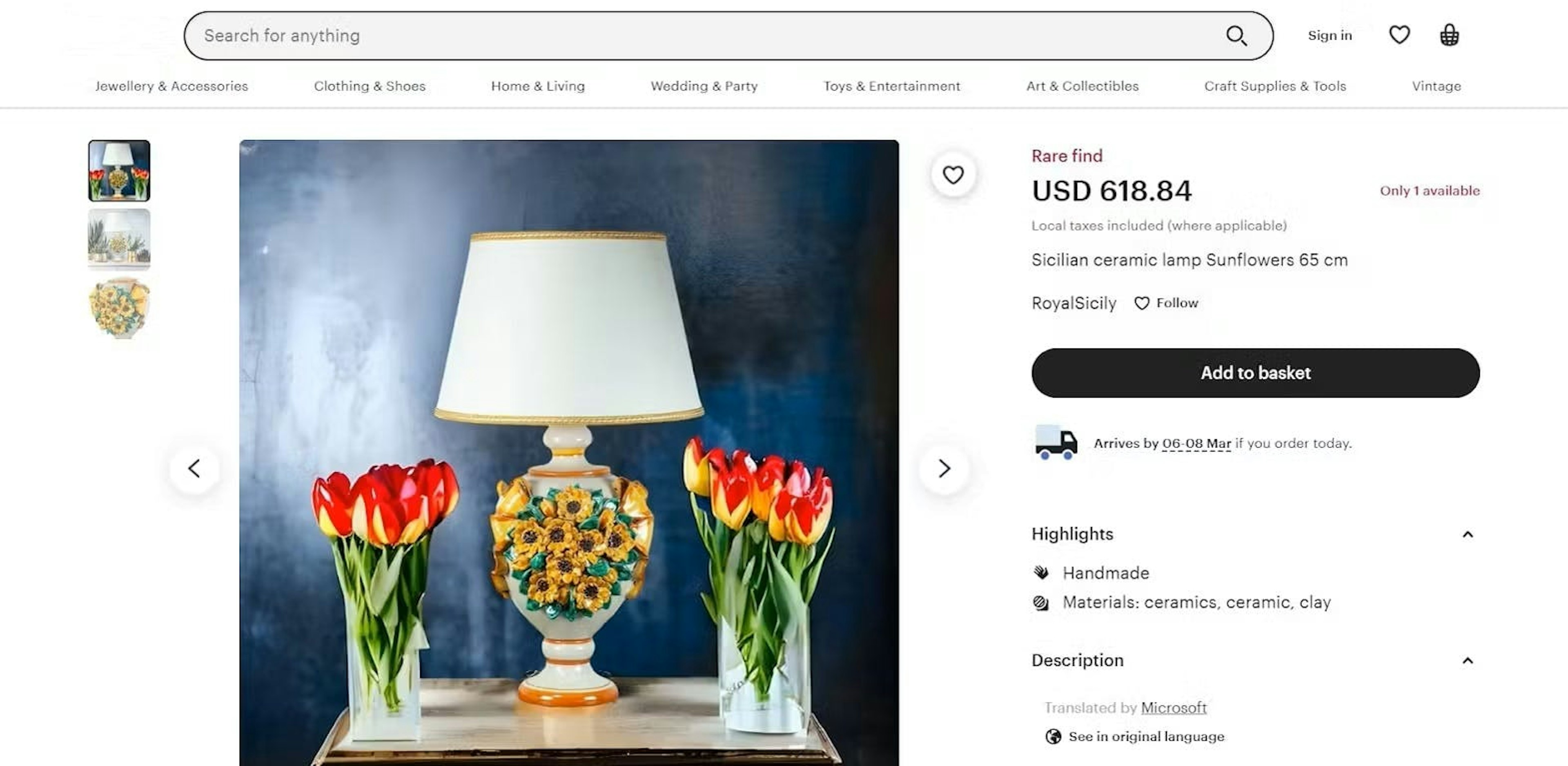
In this tutorial, we’ll use Python and its modules, like requests, csv, and pprint, to make an HTTP request to the API. First, open your terminal and install the requests module:
pip install requestsStep 3: Send the request
Create a new Python file and add the following code:
import requests, csv
from pprint import pprint
payload = {
'source': 'universal',
'url': 'https://www.etsy.com/listing/1423148329',
'geo_location': 'United States',
'user_agent_type': 'mobile',
'parse': True,
}
# Get the response.
response = requests.post(
'https://realtime.oxylabs.io/v1/queries',
auth=('user', 'pass'),
json=payload,
)
pprint(response.json())Replace the url value with the web page you want to scrape data from and the geo_location with the country from which you want to access Etsy. You can set the user_agent_type parameter to any other device of your choice. You can find a list of available user agent parameters in our documentation.
In addition, replace user and pass with the username and password you’ve created in the dashboard. If you wish to add more parameters to your code, visit our documentation for more information. When you run the code, it’ll make a request to the API and return a parsed JSON response:
{
"results": [
{
"content": {
"categories": [
{
"title": "All categories"
},
{
"title": "Art & Collectibles"
},
{
"title": "Fine Art Ceramics"
}
],
"currency": "USD",
"customized": false,
"images": [
"https://i.etsystatic.com/41402376/c/1969/1567/75/243/il/3afc9a/4653235704/il_75x75.4653235704_1g03.jpg",
"https://i.etsystatic.com/41402376/r/il/39f8e3/4701471373/il_75x75.4701471373_q610.jpg",
"https://i.etsystatic.com/41402376/r/il/112b77/4653235192/il_75x75.4653235192_a6vx.jpg"
],
"parse_status_code": 12005,
"price": 618.84,
"product_id": "1423148329",
"seller": {
"best_seller": false,
"reviews_count": 0,
"star_seller": false,
"title": "RoyalSicily",
"url": "https://www.etsy.com/shop/RoyalSicily?ref=simple-shop-header-name&listing_id=1423148329"
},
"shipping": {
"from": "Italy"
},
"stock_status": "Only 1 available",
"title": "Sicilian ceramic lamp Sunflowers 65 cm",
"url": "https://www.etsy.com/listing/1423148329/sicilian-ceramic-lamp-sunflowers-65-cm"
},
"created_at": "2023-02-24 16:17:18",
"job_id": "7034919195095648257",
"page": 1,
"parser_type": "etsy_product",
"status_code": 200,
"updated_at": "2023-02-24 16:17:22",
"url": "https://www.etsy.com/listing/1423148329"
}
]
}Step 4: Save the data to CSV
The data extracted and displayed above can be saved into a CSV file using the csv module in Python. Add the following code to your Python file:
# The data is saved in the dictionary
dictionary = response.json()["results"][0]['content']
# The data in the dictionary is then stored in the csv file, "etsy_data.csv"
with open('etsy_data.csv', 'w', newline='') as f:
writer = csv.DictWriter(f, fieldnames=dictionary.keys())
writer.writeheader()
writer.writerow(dictionary)The JSON response is stored in the dictionary first, and then, using the csv library, we create a file named etsy_data.csv. You can import the CSV to an Excel file for further analysis. And that’s it! You can now tweak or filter the data per your project's requirements.
When running this at scale in production, you typically want to save results to Cloud Storage (S3, GCS, etc.). When dealing with thousands of small files of scraped data, it can create storage inefficiencies and higher costs. The Result Aggregator feature can help you handle this by merging files into larger aggregates, cutting storage and transfer expenses while streamlining your data pipeline.
Scraping Etsy with Oxylabs’ Residential Proxies
If you prefer a more manual approach instead of using dedicated web scrapers, you can scrape Etsy data using the requests library in Python along with Oxylabs' Residential Proxies.
Step 1: Install the required libraries
Before you start, ensure you have the necessary libraries installed:
pip install requests beautifulsoup4Step 2: Set up the proxy connection
For reliable access while scraping Etsy data, use Oxylabs' Residential Proxies. Here's an example of how to make a request through the proxy to scrape a specific Etsy search page:
import requests
from bs4 import BeautifulSoup
import csv
# Configure proxy settings
proxy = {
"http": "http://your_username:your_password@pr.oxylabs.io:7777",
"https": "http://your_username:your_password@pr.oxylabs.io:7777"
}
# Set up standard browser headers
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36"
}
# Target URL for scraping
url = "https://www.etsy.com/de-en/search?q=throw+blanket&anchor_listing_id=721378704&ref=hub_stashgrid_module-3&mosv=ssos&moci=1337201102321&mosi=1337201672571&is_merch_library=true&max=75"
# Send the request through the proxy
response = requests.get(url, headers=headers, proxies=proxy)Step 3: Handle the response data
Once you receive the response, you can parse the HTML using BeautifulSoup to extract specific elements like product titles and prices:
# Check if the request was successful
if response.status_code == 200:
# Parse the HTML content
soup = BeautifulSoup(response.text, "html.parser")
# Find all product information containers
products = soup.find_all("div", class_="v2-listing-card__info")
# Extract data from each product
product_data = []
for product in products:
title = product.find("h3").text.strip() if product.find("h3") else "N/A"
price = product.find("span", class_="currency-value").text.strip() if product.find("span", class_="currency-value") else "N/A"
# Print data for verification
print(f"Title: {title}\nPrice: {price}\n")
# Store data for saving to CSV
product_data.append({"Title": title, "Price": price})
else:
print(f"Failed to scrape: {response.status_code}")Step 4: Save data for further analysis
If you wish to save the extracted data, you can store it in a CSV file using Python's csv module:
# Only proceed if we have product data to save
if response.status_code == 200 and product_data:
with open("etsy_search_results.csv", "w", newline="", encoding="utf-8") as file:
# Define CSV writer
fieldnames = ["Title", "Price"]
writer = csv.DictWriter(file, fieldnames=fieldnames)
# Write header and data rows
writer.writeheader()
writer.writerows(product_data)
print("Data saved to etsy_search_results.csv")Things to keep in mind
When you scrape Etsy listings, remember that Etsy has anti-scraping measures, so rotating Etsy proxies and varying headers can help maintain reliable access.
If CAPTCHA pages appear frequently, consider using headless browsers like Selenium.
Scrape responsibly and respect the site's terms of service.
Using Oxylabs' Residential Proxies ensures your requests come from real residential IPs, improving the chances of successful data retrieval with reliable access.
Which scraping method to choose?
If you’re unsure whether to scrape with proxies, without them, or using a dedicated scraper, here’s a comparison table to help you decide.
Scraping methods compared
| Approach | Key Features | Advantages | Limitations | Best For |
|---|---|---|---|---|
| No Proxies | • Basic HTTP requests • Single IP address • Simple request handling |
• Easy to implement • No additional costs • Minimal setup • Small-scale scraping |
• High risk of blocks • Limited request volume • No geo-targeting • Poor scalability |
• Small projects • Non-restricted content • Testing and development |
| With proxies | • Rotating IP addresses • Geo-location targeting • Session management |
• High success rates • Scalability • Reliable access • Geographic flexibility |
• Proxy management • More costs • Complex setup • Needs monitoring |
• Large-scale operations • Competitor monitoring • Global data collection |
| Scraper APIs | • Pre-built infrastructure • JavaScript rendering • Parsing • CAPTCHA handling |
• Ready-to-use solution • Maintenance-free • Technical support |
• Higher costs • Limited customization • API-specific limitations • Dependency on provider |
• Complex websites • JavaScript-heavy sites • Resource-constrained teams |
Wrapping up
Web scraping Etsy product data isn’t easy as it requires a lot of effort to go around the website’s anti-scraping system. You may need to use proxies, rotate different user agents, and pass more complex headers in order to get the data you need on a large scale.
A dedicated marketplace scraper, like Etsy Scraper API, can take away the hardships of web scraping and allow users to scrape the web without a hitch.
Residential Proxies are essential for reliable web scraping. For standard, real-user traffic, you can buy proxy solutions, most notably residential and datacenter IPs, or choose a free proxy list.
If you want to dive deeper into scraping techniques, we encourage you to learn more about the process and check out our article on how to scrape dynamic websites.
If you have any questions or need assistance, don't hesitate to get in touch with us via email or live chat.
About the author

Vytenis Kaubrė
Technical Content Researcher
Vytenis Kaubrė was a Technical Content Researcher at Oxylabs. Creative writing and a growing interest in technology fueled his work, where he researched and crafted technical content while honing his skills in Python. Off duty, he could often be found working on personal projects, learning about cybersecurity, or relaxing with a book.
All information on Oxylabs Blog is provided on an "as is" basis and for informational purposes only. We make no representation and disclaim all liability with respect to your use of any information contained on Oxylabs Blog or any third-party websites that may be linked therein. Before engaging in scraping activities of any kind you should consult your legal advisors and carefully read the particular website's terms of service or receive a scraping license.
Frequently asked questions
Does Etsy allow scraping?
Etsy, like most websites, employs anti-scraping measures to prevent bot activity on its platform. These include tracking user actions and implementing CAPTCHAs. While Etsy doesn't explicitly allow scraping, public data can be collected using appropriate tools and techniques that respect their systems and terms of service.
How to scrape Etsy products?
How to bulk download Etsy listings?
Is it legal to scrape data?
Related articles






Get premium Oxylabs proxies
Enjoy reliable access with 177M+ premium paid proxies located in 195 countries.
Try free proxies
Claim your free proxies for lifetime by registering on the Oxylabs dashboard.

Get the latest news from data gathering world
Scale up your business with Oxylabs®
Proxies
Advanced proxy solutions
Data Collection
Datasets
Resources
Innovation hub
Get premium Oxylabs proxies
Enjoy reliable access with 177M+ premium paid proxies located in 195 countries.
Try free proxies
Claim your free proxies for lifetime by registering on the Oxylabs dashboard.