175M+ ethically sourced IPs built for the highest reliability.
High-speed, cost-effective proxies built for any scraping workload.
Premium static residential proxies from trusted ASNs for most difficult targets.
Dedicated IPs from premium ASNs for demanding scraping.

AI-powered proxy solution for optimized web scraping performance.

20M+ IP addresses from real mobile devices for precise targeting.

Free Chrome proxy manager extension that works with any proxy provider.

Free Android proxy manager app that works with any proxy provider.

Free community-driven tools to improve your web scraping projects.
Web Scraper API
All-in-one web data collection platform for every stage of web scraping.
Fast Search API
Ultra-fast organic search results scraper tailored for AI workflows.
Headless Browser
Advanced browser automation solution for AI agents and scraping.
AI Studio
A suite of AI-powered tools for various scraping projects.

Documentation
All features, parameters, and integration details, backed by code samples in every coding language.
Tutorials, samples, and guides.
Latest fixes and features.





What is ELT, and How Does It Differ From ETL?

Vytenis Kaubrė
Last updated on
2023-03-23
6 min read
![]() AI Summary:
AI Summary:
ELT (Extract, Load, Transform) is a data integration process that loads raw data directly into a target system before transformation. This differs from ETL by performing transformation within the target system, enabling faster data ingestion and greater flexibility for large, diverse datasets.
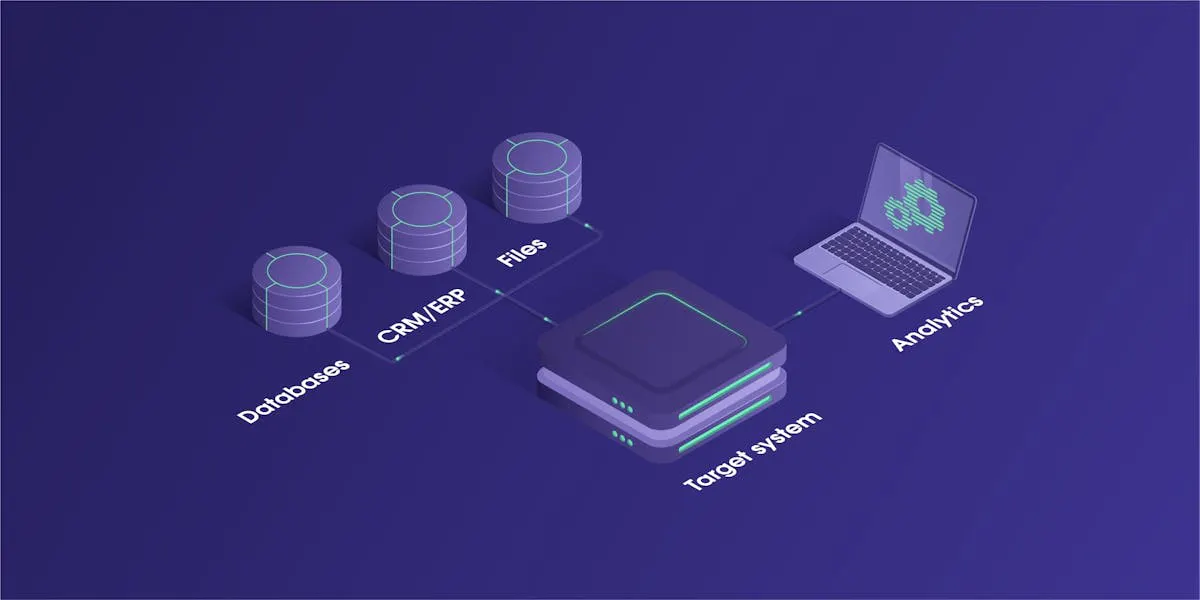
ELT, which stands for Extract, Load, and Transform, is a data integration process that moves raw data from a source system to a target system, such as a data warehouse or a data lake. Then, the unprocessed data is transformed directly inside the target source for further use.
In this article, we’ll take a deeper look at ELT by explaining how it works and why you should consider using it. We’ll compare ETL vs. ELT and the difficulties of moving from one to another. Additionally, we’ll highlight some of the more popular ELT tools and what to look for when choosing one.
How ELT works
It involves three data pipeline processes: Extract, Load, and Transform.
Extract
During this stage, structured or unstructured data is extracted from one or more source systems according to predefined rules. The source API or data extraction tools are usually employed for this process, as the source systems can be databases, text files, web pages, emails, CRM and ERP systems, and other data sources. When the source system is accessible on the web, a web scraper can be used, such as the Web Scraper API.
Load
The extracted data is then loaded straight to the destination system, like a data warehouse or a data lake. This process is usually automated and done in batches.
Transform
During this stage, the data that was taken from the source system is cleaned up and transformed it into a format suitable for the target system. This is generally achieved by altering the data according to the rules that dictate the appropriate form for storage and further data analysis. Transformation usually includes, but isn’t limited to:
Data clean up: adding new information, filtering, validating, updating, modifying text strings, converting data types, and removing the data.
Data aggregation: calculation, translation, and summarizing of data that’s based on the business analytical needs. For instance, this can involve adding up values or converting currencies.
Formatting: this includes any type of re-formatting, such as converting unstructured data into a tabular format.
ETL vs. ELT: the differences
The most significant difference between the two is when and where the transformation stage happens. ETL stands for Extract, Transform, and Load; thus, the transformation of raw data happens before it’s loaded into a data warehouse. As mentioned previously, ELT first loads the data, and the transformation happens in the target source.
The difference in the order of stages makes ETL a slower process compared to ELT, as it transforms data on a separate server. ELT is capable of faster data ingestion by skipping the secondary server and transforming data directly within the target destination.
As ELT stores raw data in the target storage, the data can be retransformed as many times as needed, which is a much more flexible and efficient approach to Business Intelligence (BI). Business goals and strategies change, and thus ELT accommodates fast access to data that can be queried as needed to fit new changes.
Here, we can highlight another major nuance of both methods – ETL is best with small amounts of data, whereas ELT can process large amounts of data.
Additionally, the ELT process is more often used to store information in a data lake instead of a data warehouse, as a data lake is specifically designed to hold structured and unstructured information. On the other hand, ETL requires storage for structured data, as the data is transformed before it’s loaded into a data warehouse.
Interestingly, ELT also reduces the workload of data engineers, as they can focus on the loading stage and forget about the transformation stage. The latter is left for analysts or analytics engineers, which is beneficial as they know the business cases from top to bottom compared to data engineers. Meaning they can perform the data transformation process with utmost precision according to the business needs and data analysis requirements.
When it comes to privacy, one key advantage that ETL has over its counterpart is that it’s ideal when certain information needs to be changed or removed entirely before being loaded. For instance, ETL would be a preferable choice when dealing with sensitive information such as personal identifying data or data protected by the government.
Let’s summarize the comparisons side-by-side:
| ETL | ELT | |
|---|---|---|
| Process | Data is transformed in a separate staging server and then loaded to a destination system. | Data is first loaded into a destination system and then transformed within the same system. |
| Scale | Used to process small data sets with complex transformation conditions. | Used to process large data sets with speed and efficiency. |
| Speed | The process takes more time as it has three independent stages. | The process is faster as it loads un-transformed data directly to the target. |
| Flexibility | ETL requires planning prior to the loading stage to ensure all needed data is loaded. Any changes to the transformation rules require retransformation and reloading. | As raw data is loaded before transformation, it can be retransformed in any way whenever needed. It doesn’t require a loading stage when the transformation rules change. |
| Data granularity | Low-level granularity. | High-level granularity. |
| Storage support | Supports data warehouses but not data lakes. Used for relational and structured data. | Supports data warehouses and data lakes. Used for structured, semi-structured, and unstructured data. |
| Hardware | ETL tools commonly require specific hardware for the transformation stage. | ELT tools usually don’t need specific hardware. |
| Privacy | Sensitive data can be removed before it’s loaded. | Requires additional privacy protection as all available data is loaded to the target. |
| Programming skills required | The extract and load stages often require writing custom scripts. | The extract and load stages generally require little to no code. |
| Costs | ETL cost is on the higher end, as it needs separate servers and additional hardware. | ELT requires fewer resources to manage the process; thus, the cost is usually lower. |
Benefits of ELT
Using the ELT method for your data integration can bring about particular advantages:
Faster process and data availability
With ELT, the time of data being in transit is significantly reduced. ELT loads raw data to the destination source, meaning real-time data is available in the target source as soon as it’s there.Flexibility
ELT enables endless data retransformation according to the business needs as unprocessed data is accessible in the target source. Additionally, it saves time as it doesn’t require a loading stage to retransform the data, compared to ETL.Merge data from multiple sources
Various data sets from different source systems can be combined, regardless of whether the data is structured, semi-structured or unstructured, related or unrelated.Scalability
It’s much more scalable as ELT relies on the target source for computation and storage. Usually, these target systems are cloud-based, which enables rapid scalability unseen in ETL.Lower expenses
ELT doesn’t require a separate server and additional hardware to perform data transformation as it does it using the resources of the destination system.
When to use ELT?
In short, you should use ELT whenever it’s possible. But let’s underline a few notable cases when you should definitely use ELT over ETL:
When instant access to data is needed
If real-time data is the principal factor leading your business decisions, then use ELT. An example would be a stock exchange company that requires real-time stock data to make immediate economic decisions.When the data is high-volume
Examples of industries can include transportation companies that use telematics devices or transaction processing businesses that process enormous volumes of data.When the data is structured and unstructured
Combining both data types is impossible in ETL, but the ELT process enables that. This closely relates to the point mentioned above, as companies that process massive amounts of data usually deal with structured and unstructured data simultaneously.When projects involve machine learning
Machine learning projects require raw data, so it’s vital to use a process, like ELT, that makes unprocessed data available to machines.
Challenges of moving from ETL to ELT
Changing your data integration process to ELT may impose certain obstacles, which can include:
The difference in code and logic
The major challenge is the difference in code and structure between the two. This decision might require a complete design change or possibly even new infrastructure to accommodate ELT.Additional security safeguards are required
With ETL, you process the data prior to loading it; thus, any data privacy concerns are handled during transformation. Using ELT requires additional security safeguards to protect sensitive data in the destination storage.
ELT tools
When choosing ELT tools, the most significant criterion you should consider is the ability to read and get the data from multiple sources that your business uses. If your company uses different applications and APIs, the ideal ELT solution should be able to integrate with these sources.
Next, easy-to-use ELT solutions are best as they simplify the already complicated process. Such tools should offer a convenient user interface, opening up the possibility of training non-technical employees.
Another measure you should consider when choosing an ELT tool is its scalability and security. The perfect solution should be able to easily handle the scalability of big data, and it should implement top-tier security mechanisms.
Although, the choice doesn’t have to be either ETL or ELT. It’s possible to use both data integration methods if that’s what your business needs.
Some of the market leaders that offer ELT tools include:
Informatica (Cloud Data Integration)
Oracle (Oracle Data Transforms)
IBM (IBM DataStage)
Microsoft (Azure Data Factory)
SAP (SAP Data Integrator)
Airbyte
Matillion
Fivetran
Palantir Foundry
Wrapping up
The ELT data integration process is essential to any business that deals with the shortcomings of ETL. With ELT, crucial data can be accessed instantly to make decisive business decisions. It enables the processing of huge volumes of structured and unstructured data that can be scaled to suit business needs. However, both data integration methods can be used simultaneously, this way taking care of certain disadvantages that both methods impose.
As always, if you have any questions or need immediate assistance, don't hesitate to get in touch with us via 24/7 live chat or email.
Forget about complex web scraping processes
Choose Oxylabs' advanced web intelligence collection solutions to gather real-time public data hassle-free.
About the author
Vytenis Kaubrė
Technical Content Researcher
Vytenis Kaubrė was a Technical Content Researcher at Oxylabs. Creative writing and a growing interest in technology fueled his work, where he researched and crafted technical content while honing his skills in Python. Off duty, he could often be found working on personal projects, learning about cybersecurity, or relaxing with a book.
All information on Oxylabs Blog is provided on an "as is" basis and for informational purposes only. We make no representation and disclaim all liability with respect to your use of any information contained on Oxylabs Blog or any third-party websites that may be linked therein. Before engaging in scraping activities of any kind you should consult your legal advisors and carefully read the particular website's terms of service or receive a scraping license.
Related articles

Top 7 Web Price Scraping Software and Tools for 2026

Shinthiya Nowsain Promi
2026-06-11

What Is Data Grounding in AI? A Complete Guide
Shinthiya Nowsain Promi
2026-05-22



Get the latest news from data gathering world
Scale up your business with Oxylabs®
Proxies
Advanced proxy solutions
Data Collection
Datasets
Resources
Innovation hub
Forget about complex web scraping processes
Choose Oxylabs' advanced web intelligence collection solutions to gather real-time public data hassle-free.