175M+ ethically sourced IPs built for the highest reliability.
High-speed, cost-effective proxies built for any scraping workload.
Premium static residential proxies from trusted ASNs for most difficult targets.
Dedicated IPs from premium ASNs for demanding scraping.

AI-powered proxy solution for optimized web scraping performance.

20M+ IP addresses from real mobile devices for precise targeting.

Free Chrome proxy manager extension that works with any proxy provider.

Free Android proxy manager app that works with any proxy provider.

Free community-driven tools to improve your web scraping projects.
Web Scraper API
All-in-one web data collection platform for every stage of web scraping.
Fast Search API
Ultra-fast organic search results scraper tailored for AI workflows.
Headless Browser
Advanced browser automation solution for AI agents and scraping.
AI Studio
A suite of AI-powered tools for various scraping projects.

Documentation
All features, parameters, and integration details, backed by code samples in every coding language.
Tutorials, samples, and guides.
Latest fixes and features.





Headless Browser for AI Agents & Advanced Automation
Headless Browser scraping is built to support interaction with even the most complex websites, delivering market-leading success rates – no surprise fees, ever.
Advanced browser automation in every plan
Simple plug-and-play integration for quick setup
Scalable and cost-effective for any workload
Dynamic CAPTCHA management for reliable access

Full web automation stack in one tool

JS rendering
Extract data from dynamic, JS-heavy sites with full rendering support.

Simple integration
Works with Puppeteer, Playwright, CDP tools, and MCP for Claude & Cursor.

Proxy management
Access 175M+ premium residential proxies with country, city, and state geo-targeting.

Easy scaling
Run at scale in the cloud – no browser setup, servers, or proxy management.
Visual debugging
Get real-time visual access to the browser automation sessions.
Multi-step data extraction at scale
Headless Browser delivers a production-ready browser environment optimized for interaction with modern websites at scale.
Emulates browser behavior
Handles CAPTCHAs, including hCaptcha, reCAPTCHA, and Cloudflare Turnstile
Supports dynamic content rendering
AI-controlled browsing via MCP
Automate browsing and data extraction with AI agents like Claude, Cursor and other MCP clients via Headless Browser and MCP integration:
No browser setup needed
Works with Claude Desktop, Cursor, and other MCP clients
Built-in request management
Zero-maintenance infrastructure
Headless Browser runs on our backend – no local browser infrastructure required. Powered by Oxylabs' Residential Proxies for high concurrency, with support for both human and AI control via MCP.

Headless Browser pricing
Maintenance-free browsing infrastructure
Starter
50GB
$
6
/GB
$300
billed monthly
VAT may apply
24/7 Support
Dedicated Account Manager
Advanced
100GB
$
5.50
/GB
$550
billed monthly
VAT may apply
24/7 Support
Dedicated Account Manager
Premium
Best value300GB
$
4.70
/GB
$1,410
billed monthly
VAT may apply
24/7 Support
Dedicated Account Manager
Enterprise
400GB+
Tailored solutions for high-volume needs
Custom price
24/7 Support
Dedicated Account Manager
Fast & Secure payments powered by Stripe
Why our Headless Browser is the best choice
Plug & play integration
JavaScript rendering
AI-controlled browsing
Scalable & cost-effective
CAPTCHA management
Largest IP pool included
Connect your AI agent to Headless Browser
Skip the manual setup. The Oxylabs Agent Skills teach your AI agent to scrape through the Headless Browser. Add it once, then just describe the job. Works with Claude, Cursor, Copilot, and more.
Open the Agent Skills repository1. Add Agent Skills
Drop our SKILL.md files into your AI agent.

2. Describe the task
Explain what you need in plain language.

3. Start building
AI agent generates the code for you.
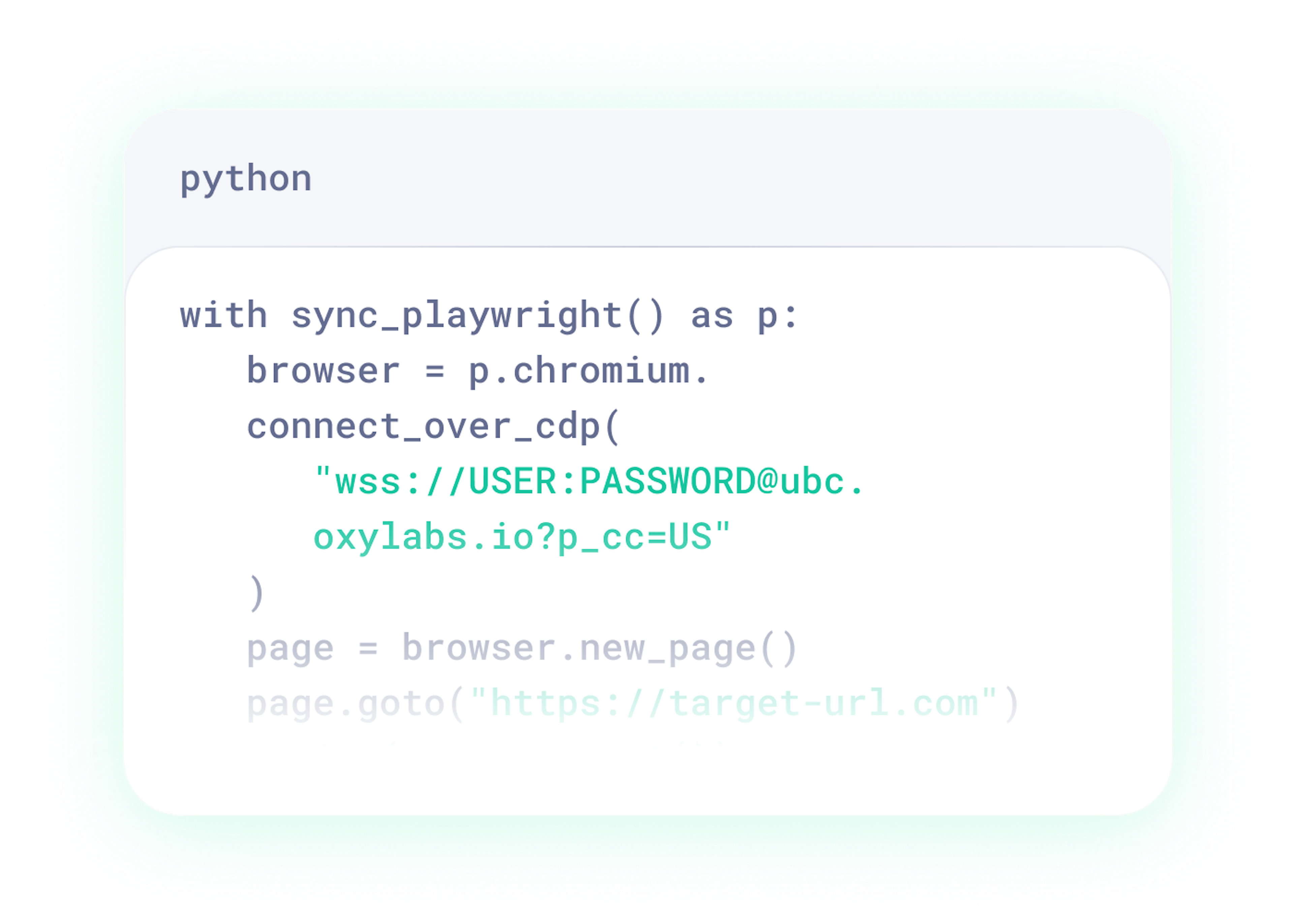
Works with your stack
Headless Browser is a scalable engine for scraping and automation – built for humans and AI agents alike.
Libraries: Playwright, Puppeteer & CDP-compatible tools
Browsers: Chromium and Firefox
AI control: support for MCP on Claude Desktop, Cursor, and other MCP clients

Usage statistics & Dashboard API
Monitor your Headless Browser operations with precise statistics directly in your Oxylabs dashboard or track usage data with your internal reporting tools automatically through our Dashboard API.
Monitor traffic usage by target
Track request counts data
Feed metrics directly into AI tools

Powered by 175M+ Residential Proxies
Frequently asked questions
What is headless browser scraping?
Headless browser web scraping is a method of extracting data from websites using a browser that runs without a visible user interface. This approach is widely used for automated web scraping and data scraping tasks that require a standard web browser environment. It can load JavaScript, interact with pages, click buttons, fill out input boxes, and emulate browser behavior, including form submissions. This makes it useful for scraping dynamic or protected websites. Headless browsers can also wait for elements to load, render images and other media, and execute JavaScript and CSS just like a normal browser.
What is Oxylabs' Headless Browser?
When should I use a headless browser?
Which libraries does Oxylabs’ Headless Browser support?
Does it work on both Chrome and Firefox?
How does Headless Browser work with AI assistants?
How do I control browser settings?
How do I get rid of browser interruptions?
How does Oxylabs' Headless Browser handle CAPTCHAs?
How is Oxylabs' Headless Browser different from other headless browsers?
How do headless browsers work?
How can I improve access reliability while scraping?
Get the latest news from data gathering world
Scale up your business with Oxylabs®
Proxies
Advanced proxy solutions
Data Collection
Datasets
Resources
Innovation hub