175M+ ethically sourced IPs built for the highest reliability.
High-speed, cost-effective proxies built for any scraping workload.
Premium static residential proxies from trusted ASNs for most difficult targets.
Dedicated IPs from premium ASNs for demanding scraping.

AI-powered proxy solution for optimized web scraping performance.

20M+ IP addresses from real mobile devices for precise targeting.

Free Chrome proxy manager extension that works with any proxy provider.

Free Android proxy manager app that works with any proxy provider.

Free community-driven tools to improve your web scraping projects.
Web Scraper API
All-in-one web data collection platform for every stage of web scraping.
Fast Search API
Ultra-fast organic search results scraper tailored for AI workflows.
Headless Browser
Advanced browser automation solution for AI agents and scraping.
AI Studio
A suite of AI-powered tools for various scraping projects.

Documentation
All features, parameters, and integration details, backed by code samples in every coding language.
Tutorials, samples, and guides.
Latest fixes and features.





How to Scrape Web Data With CrewAI & Oxylabs Scraper API
CrewAI is an open-source Python framework for creating AI agents that can work together on complex workflows. Add Web Scraper API to the mix, and these agents can now navigate web pages, perform complex web scraping tasks, and intelligently scale your data collection and analysis efforts.
This guide will walk you through building a CrewAI scraping agent that searches Google results—no blocks, no hassle, just focused and reliable web scraping.

1. Prepare the environment
Prerequisites:
Python ≥3.10
uv package manager
API key for your chosen LLM
Oxylabs Web Scraper API credentials (free trial available)
Installation steps:
Install uv by following the documentation
Install and verify CrewAI:
uv tool install crewai
uv tool list2. Create your CrewAI project
In this guide, we’ll create a simple agentic flow that scrapes Google search results for a given term and generates a concise report in Markdown format. Open your terminal and execute this line:
crewai create crew search_crewIt will prompt you to configure a project. This guide uses the following setup:
Select OpenAI as your AI provider
Choose gpt-4o-mini as your model
Enter your OPENAI API key
Your project should be structured like shown below, where the most important files you’ll need to edit are highlighted in green:
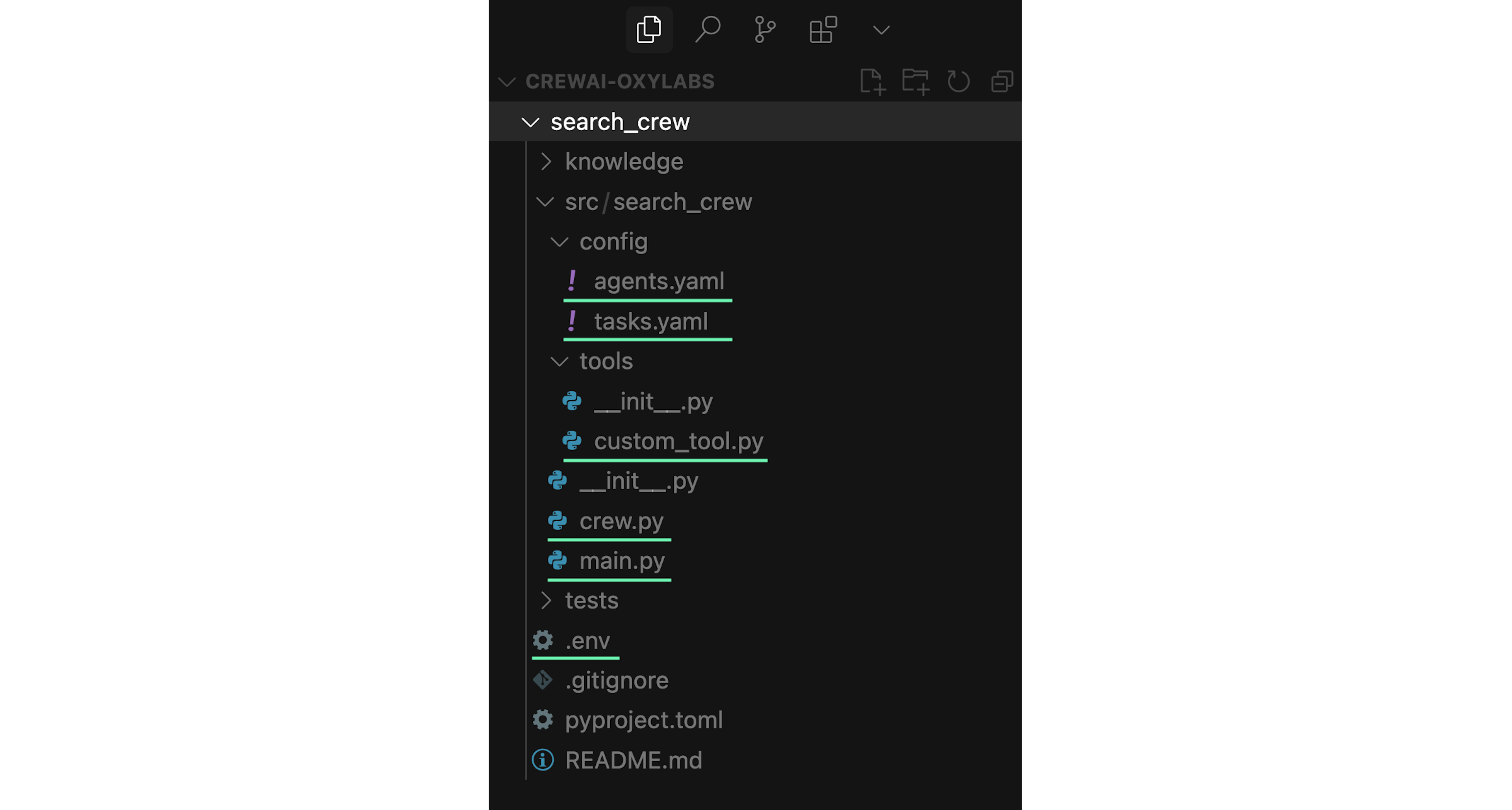
Store Web Scraper API credentials to .env
Visit the Oxylabs dashboard to claim a free trial and create your API user.
Add your API credentials to the local .env file:
API_USERNAME=YOUR_USERNAME_HERE
API_PASSWORD=YOUR_PASSWORD_HERE3. Create a custom search tool
Note: Oxylabs Web Scraper API is directly integrated into CrewAI. Check out the documentation to learn more. The following code example is useful if you want to make direct API calls instead of using the crewai_tools module.
Open the custom_tool.py file and implement Oxylabs Web Scraper API by following these key steps:
Define your input schema: Create a Pydantic model to validate the API parameters.
Build OxylabsSearch class: Extend the BaseTool class with your API implementation.
Handle credentials: Access environment variables to securely manage your API authentication.
Implement the request logic: Construct the API payload for making HTTP requests.
Process the results: Get results and implement appropriate error handling.
# src/search_crew/tools/custom_tool.py
import os
import json
from typing import Type
import requests
from pydantic import BaseModel, Field, PrivateAttr
from crewai.tools import BaseTool
class OxylabsSearchInput(BaseModel):
query: str
geo_location: str
pages: int
class OxylabsSearch(BaseTool):
_username: str = PrivateAttr()
_password: str = PrivateAttr()
name: str = 'Oxylabs Web Search'
description: str = (
'Searches the web using Oxylabs Web Scraper API to find content for '
'user-defined queries. This tool returns the latest information from '
'Google search results.'
)
args_schema: Type[BaseModel] = OxylabsSearchInput
def __init__(self, **kwargs):
super().__init__(**kwargs)
self._username = os.environ.get('API_USERNAME')
self._password = os.environ.get('API_PASSWORD')
if not self._username or not self._password:
raise ValueError('Oxylabs credentials not provided.')
def _run(self, query: str, geo_location: str, pages: int) -> str:
payload = {
'source': 'google_search',
'query': query,
'geo_location': geo_location,
'pages': pages,
'parse': True
}
try:
response = requests.post(
'https://realtime.oxylabs.io/v1/queries',
auth=(self._username, self._password),
json=payload
)
response.raise_for_status()
search_results = []
for result in response.json()['results']:
search_results.append(result['content'])
return json.dumps(search_results, indent=2)
except requests.exceptions.RequestException as e:
return f'Error making request to Oxylabs API: {str(e)}'
except (KeyError, json.JSONDecodeError) as e:
return f'Error processing API response: {str(e)}'The 'parse': True parameter automatically extracts search results data from an entire webpage. You can also use batch processing, enabling your agents to scrape data for multiple queries at the same time. The API also handles dynamic content using its JavaScript rendering feature.
4. Define agents
Inside the agents.yaml file, configure your specialized agents:
Researcher: Scrapes Google results and picks relevant content.
Analyst: Crafts a detailed and easy to read report.
researcher:
role: >
Senior Researcher
goal: >
Scrape Google search results with strategic search parameters and extract
high-value, factual information.
backstory: >
You can craft the perfect search query and other parameters to get the most
relevant results. You pick the most relevant and accurate information from
reliable sources.
analyst:
role: >
Analytics Expert
goal: >
Transform raw data points into cohesive, actionable intelligence through
concise structuring
backstory: >
You see patterns where others see only scattered facts. Your reports reveal
connections between facts and their implications. You excel at converting
information overload into strategic clarity.5. Define tasks
Next, create specific tasks for each agent that outline their responsibilities within the workflow. As noted in CrewAI’s documentation, this tasks.yaml file is the most important part for accurate results.
Here, the search_task instructs the researcher agent on how to use Web Scraper API with concrete usage examples, enabling it to craft API parameters on the go. The report_task simply defines what we’re expecting from the final report file.
search_task:
description: >
Use OxylabsSearch according to the user's {query}. Craft API parameters as
follows:
- 'query': craft a concise and accurate Google search term.
- 'geo_location': 'United States' by default or a relevant country name.
- 'pages': 2 by default or 1–5, depending on search complexity.
Filter the scraped Google search results by finding highly valuable
information.
expected_output: >
A structured JSON object containing neatly organized comprehensive data.
Don't rephrase, rewrite, or summarize the content.
Provide accurate scraped information and URLs.
agent: researcher
output_file: output/search_data.json
report_task:
description: >
Create a concise, actionable intelligence report that's easy to read.
Answer the user's {query} with concrete data. Identify valuable patterns and
trends in the data, including related searches. Don't make up any information.
expected_output: >
A scannable report focusing on the most informative and relevant
information. Choose the structure and format that best fits the data and the user's query. Prioritize clarity and brevity throughout,
structurize in a visual way. The entire report should be readable in under 2 minutes.
agent: analyst
context: [search_task]
output_file: output/report.md6. Configure your crew
Connect all the components together in the crew.py file to form a functional crew. Note how the OxylabsSearch tool is imported and used in the researcher agent function.
# src/search_crew/crew.py
from crewai import Agent, Crew, Process, Task
from crewai.project import CrewBase, agent, crew, task
from .tools.custom_tool import OxylabsSearch
@CrewBase
class WebIntelligenceCrew:
@agent
def researcher(self) -> Agent:
return Agent(
config=self.agents_config['researcher'],
tools=[OxylabsSearch()],
verbose=True
)
@agent
def analyst(self) -> Agent:
return Agent(
config=self.agents_config['analyst'],
verbose=True
)
@task
def search_task(self) -> Task:
return Task(
config=self.tasks_config['search_task'],
output_file='output/search_data.json'
)
@task
def report_task(self) -> Task:
return Task(
config=self.tasks_config['report_task'],
output_file='output/report.md'
)
@crew
def crew(self) -> Crew:
return Crew(
agents=self.agents,
tasks=self.tasks,
process=Process.sequential,
verbose=True
)7. Create the main execution file
Kick off the crew by passing the user’s primary input for processing.
# src/search_crew/main.py
import os
from search_crew.crew import WebIntelligenceCrew
os.makedirs('output', exist_ok=True)
def run():
try:
result = WebIntelligenceCrew().crew().kickoff(
inputs={'query': input('\nSearch for: ').strip()}
)
return result
except Exception as e:
print(f'An error occurred: {str(e)}')
if __name__ == '__main__':
run()8. Run your AI agents
Follow these final steps in the terminal to execute your CrewAI application:
1. Navigate to your project directory and install dependencies:
cd search_crew
crewai install2. Execute the application:
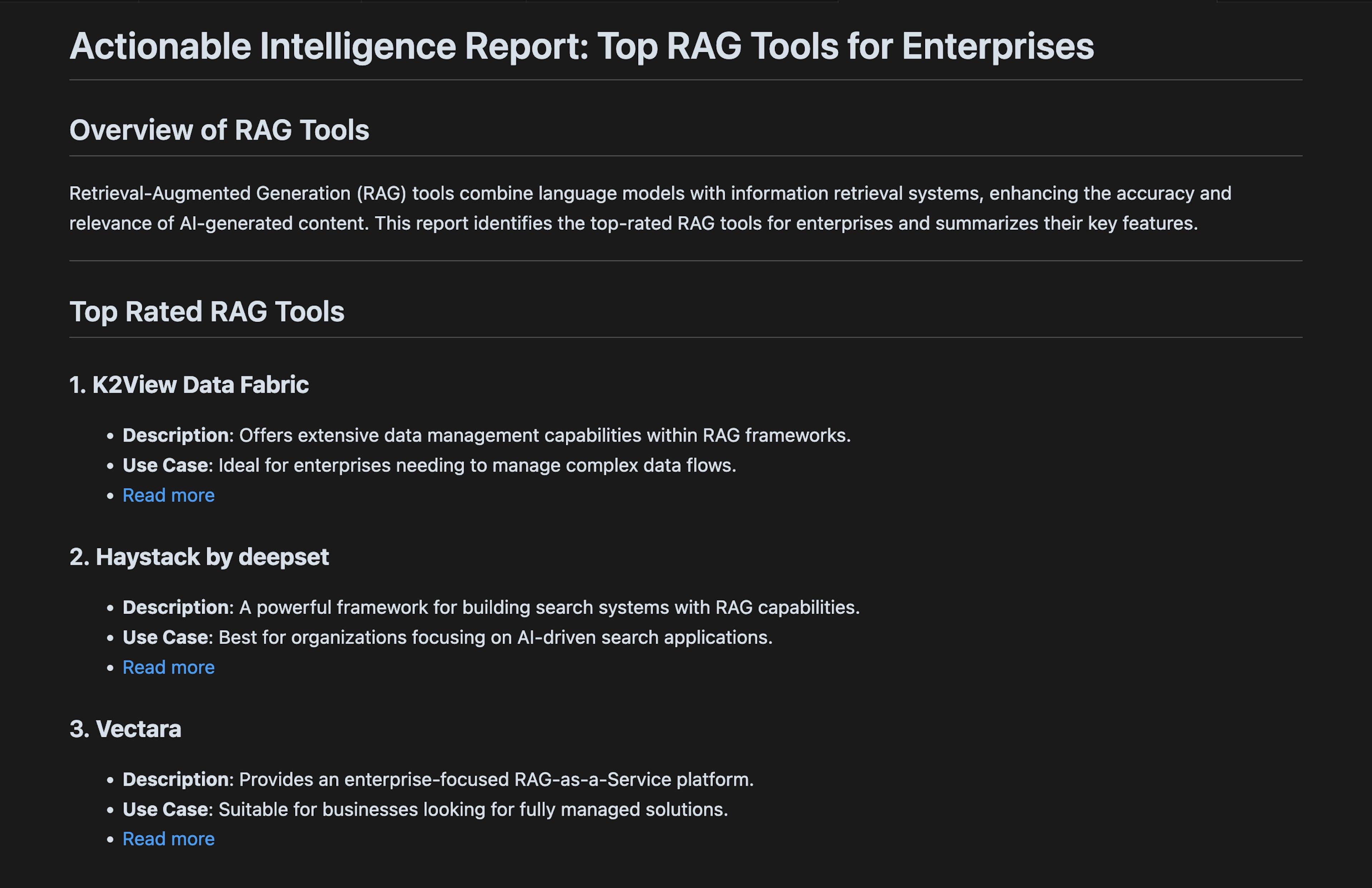
crewai runThe final report is a Markdown file as shown in this screenshot:
How it works
The researcher agent uses Oxylabs Web Scraper API to search for information based on your question. It forms an API query, selects the geo-location, and how many pages to scrape.
The researcher picks the most valuable information and saves structured JSON in the output directory.
The analyst agent processes this data and generates a concise and actionable report.
Summary
This setup provides a simple yet reliable foundation for building AI agent workflows with CrewAI and Web Scraper API. Feel free to adapt it to suit your use case, whether by tweaking parameters, adding additional steps, utilizing other API sources and features, or integrating with other tools.
If you're looking to better understand the technical side of how AI models are trained, check out our guide for AI training.
For more on available sources, additional parameters, and smart features, explore the Web Scraper API documentation. The API also comes with an AI-powered web scraping copilot to help you create scraper and parser codes for any website URL, allowing you to define specific CSS element selectors. Check out our other posts about web scraping with n8n, LangGraph integration, scraping with ChatGPT, the 8 main web data sources for LLM training, and MCP vs A2A protocol compared.
Have questions? Our team is here to help via email or live chat.
Please be aware that this is a third-party tool not owned or controlled by Oxylabs. Each third-party provider is responsible for its own software and services. Consequently, Oxylabs will have no liability or responsibility to you regarding those services. Please carefully review the third party's policies and practices and/or conduct due diligence before accessing or using third-party services.
Frequently asked questions
Can CrewAI scrape websites?
Yes, CrewAI can scrape a specified website by integrating with web scraping tools such as Oxylabs Web Scraper API. This integration allows CrewAI agents to control the API and perform web scraping tasks efficiently without blocks.
What is the difference between OpenAI and CrewAI?
Useful resources
How to Navigate AI, Legal, and Web Scraping: Asking a Professional
In this interview, we sit down with a legal professional to shed light on the ever-changing legal framework surrounding web scraping.
Acquiring High-Quality Web Data for LLM Fine-Tuning
Discover data categories, large-scale scraping strategies, and cost optimization tips for fine-tuning your AI models.
Building Web Scraping Architecture for AI Companies
The process of building a workflow that allows you to collect large-scale web data for AI training.

Get the latest news from data gathering world
Get Web Scraper API for $1.35/1K results
Proxies
Advanced proxy solutions
Data Collection
Datasets
Resources
Innovation hub