175M+ ethically sourced IPs built for the highest reliability.
High-speed, cost-effective proxies built for any scraping workload.
Premium static residential proxies from trusted ASNs for most difficult targets.
Dedicated IPs from premium ASNs for demanding scraping.

AI-powered proxy solution for optimized web scraping performance.

20M+ IP addresses from real mobile devices for precise targeting.

Free Chrome proxy manager extension that works with any proxy provider.

Free Android proxy manager app that works with any proxy provider.

Free community-driven tools to improve your web scraping projects.
Web Scraper API
All-in-one web data collection platform for every stage of web scraping.
Fast Search API
Ultra-fast organic search results scraper tailored for AI workflows.
Headless Browser
Advanced browser automation solution for AI agents and scraping.
AI Studio
A suite of AI-powered tools for various scraping projects.

Documentation
All features, parameters, and integration details, backed by code samples in every coding language.
Tutorials, samples, and guides.
Latest fixes and features.





Proxy Integration With WebHarvy
To make more sense of layers upon layers of publicly available digital data, you can scan and collect it with automated tools, such as WebHarvy web scraper, for further storage and analysis.
Follow the tutorial below to learn how to integrate Oxylabs Residential Proxies and start scraping with WebHarvy.


What is WebHarvy?
WebHarvy is a web scraping tool that extracts text, HTML, and images from web pages. The tool handles logins, form submissions, navigation, pagination, scheduled scraping, and supports proxies.
How to integrate Oxylabs Proxies with WebHarvy?
The tool offers easy-to-use third-party proxy support. Either a single proxy or a list of proxy servers could be used for public web data collection. Make sure to avoid using free/open proxy services, as the probability of being shut off in the middle of an operation is high.
Download and install the WebHarvy app via webharvy.com.
Once set up, navigate to Settings.
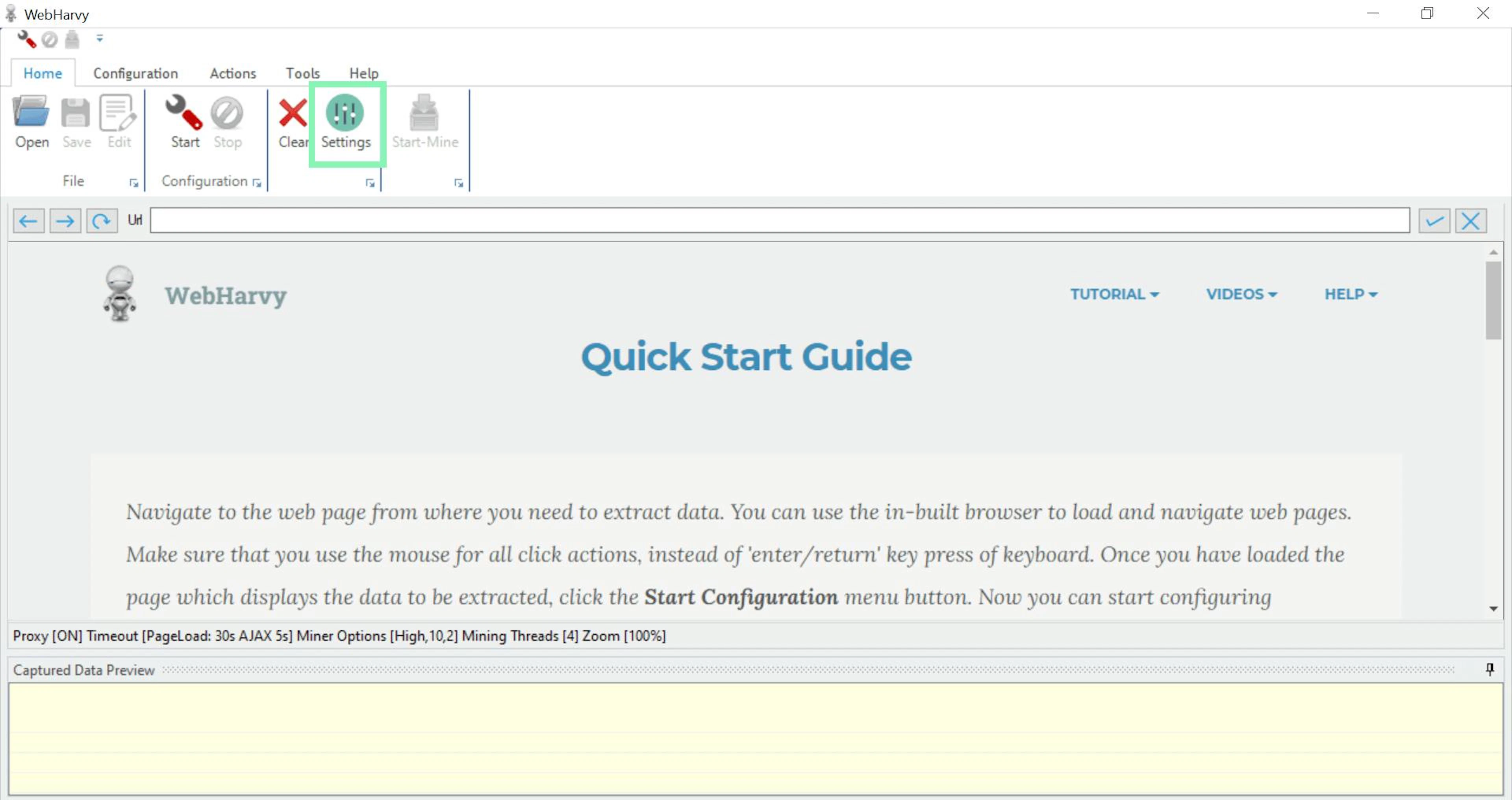
Navigating to settings
3. Click on Proxy Settings. Select to mark Enable network connection via Proxy Server and choose HTTP, HTTPS, or SOCKS5 as your Type.
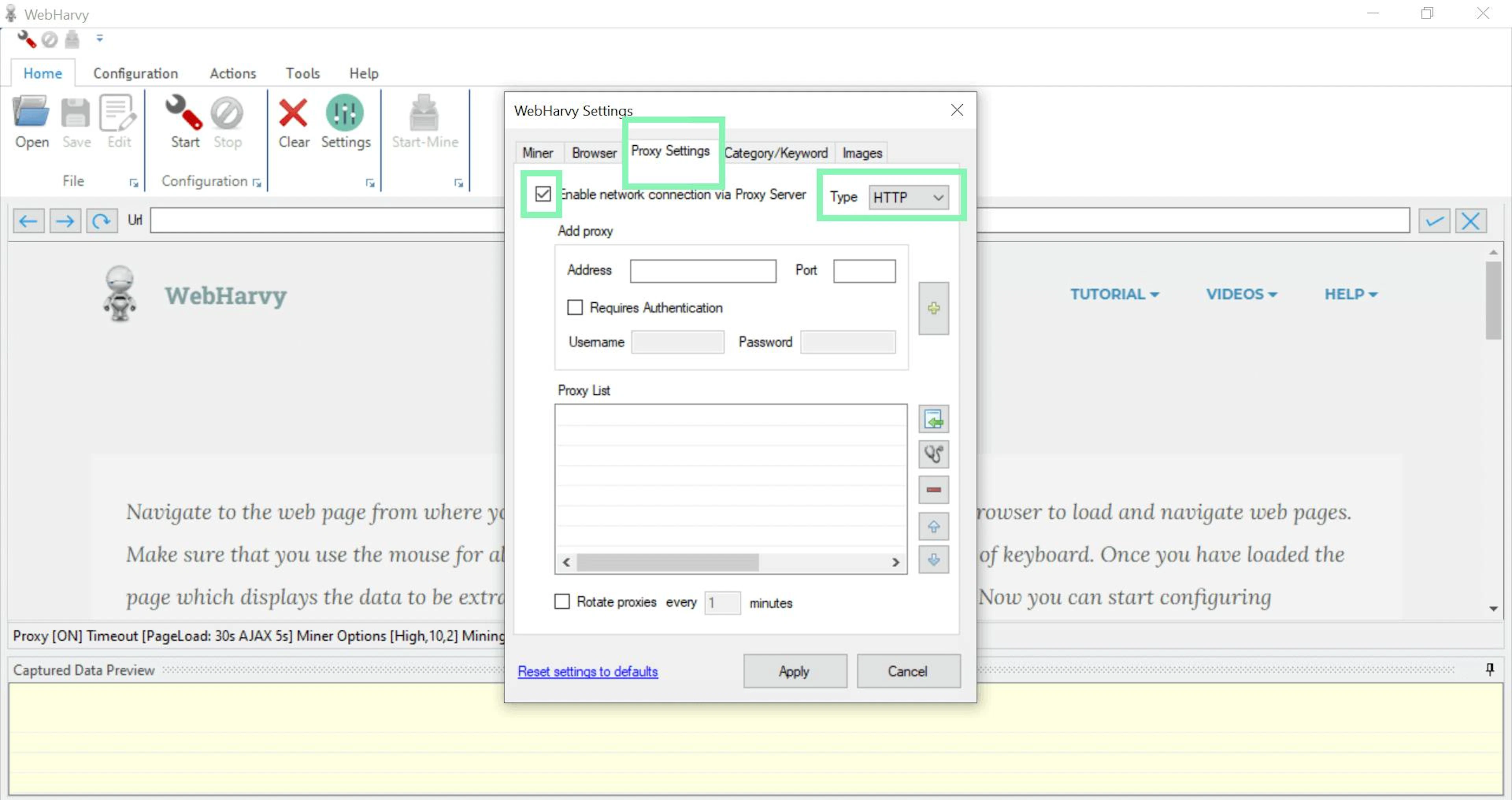
Adjusting settings
To configure Oxylabs proxies, add the following details.
Residential Proxies
Type: HTTP, HTTPS, or SOCKS5
Host: pr.oxylabs.io
Port: 7777
You can also use country-specific entries. For example, if you fill in us-pr.oxylabs.io under Address and 10000 under Port, you’ll acquire a US exit node. For a complete list of country-specific entry nodes or if you need a sticky session, please refer to our documentation.
Enterprise Dedicated Datacenter Proxies
Specify the following if you purchased Dedicated Datacenter Proxies via sales.
Type: HTTP or SOCKS5
Host: a specific IP address (e.g., 1.2.3.4)
Port: 60000
For Enterprise Dedicated Datacenter Proxies, you’ll have to choose an IP address from the acquired list. Visit our documentation for more details.
Self-Service Dedicated Datacenter Proxies
Specify the following if you purchased Dedicated Datacenter Proxies via the dashboard.
Type: HTTP, HTTPS, or SOCKS5
Host: ddc.oxylabs.io
Port: 8001
For Self-Service Dedicated Datacenter Proxies, the port indicates the sequential number of an IP address from the acquired list. Check our documentation for more details.
Datacenter Proxies
Type: HTTP, HTTPS, or SOCKS5
Host: dc.oxylabs.io
Port: 8001
For the Pay-per-IP subscription, the port is the sequential number assigned to an IP address from the given list. Thus, port 8001 uses the first IP address from your list. For more details, see our documentation.
For the Pay-per-traffic subscription, port 8001 picks a random IP address but stays consistent during a session. You can also specify geo-location, for example, the US, within the user authentication string: user-USERNAME-country-US:PASSWORD. See our documentation for more details.
ISP Proxies
Type: HTTP, HTTPS, or SOCKS5
Host: isp.oxylabs.io
Port: 8001
4. Click to mark Requires authentication to enter your Oxylabs proxy user’s Username and Password. Click on the + button to add your newly input proxy to the list. Lastly, press Apply to finish your WebHarvy proxy servers integration.
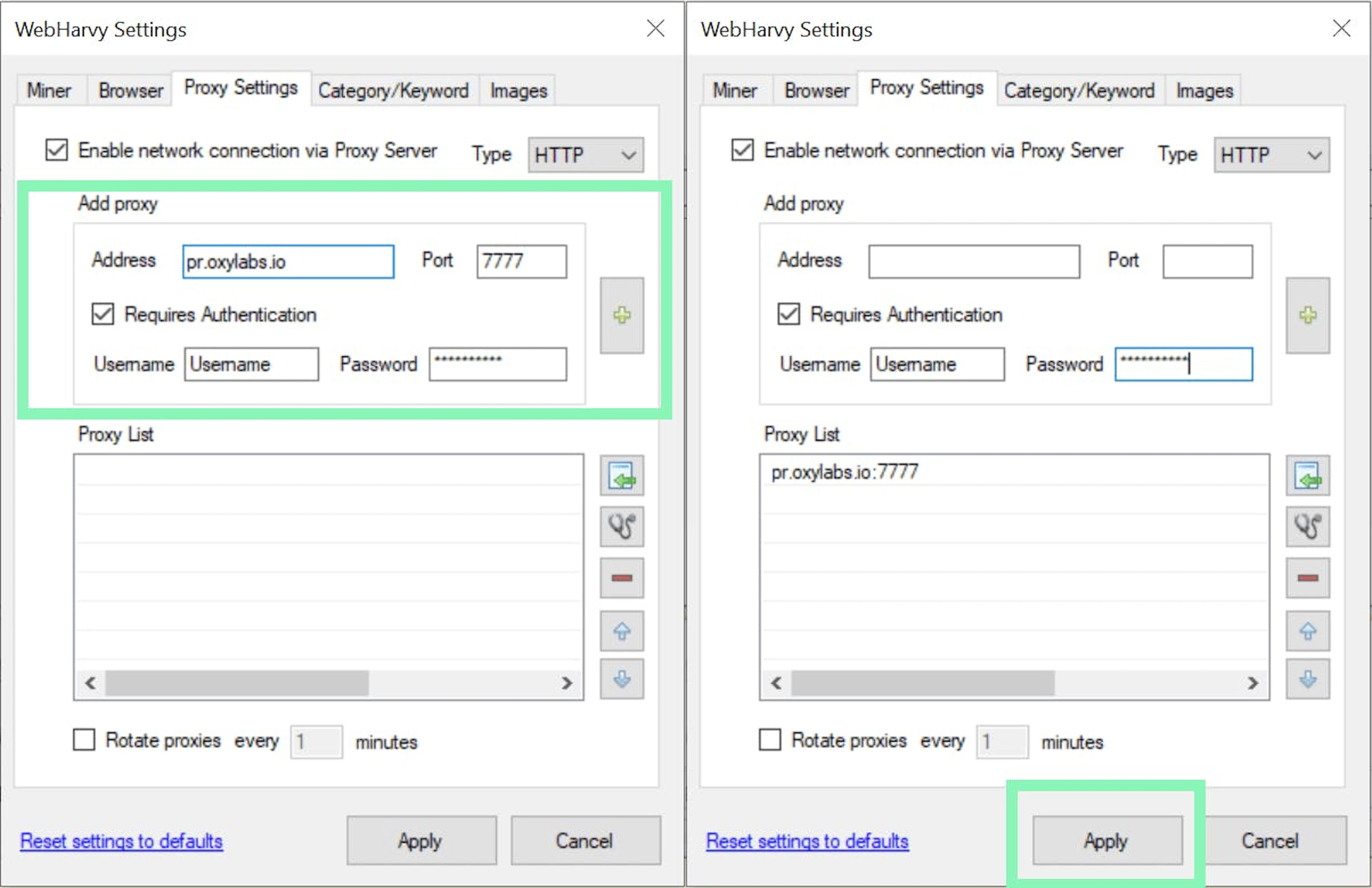
Configuring proxies
And that’s all. With proxies, WebHarvy can scrape data anonymously without being blocked.
How do you scrape with WebHarvy?
To begin, navigate to a target website. In this case, search results from https://sandbox.oxylabs.io/products.
Press Start to begin target data selection.
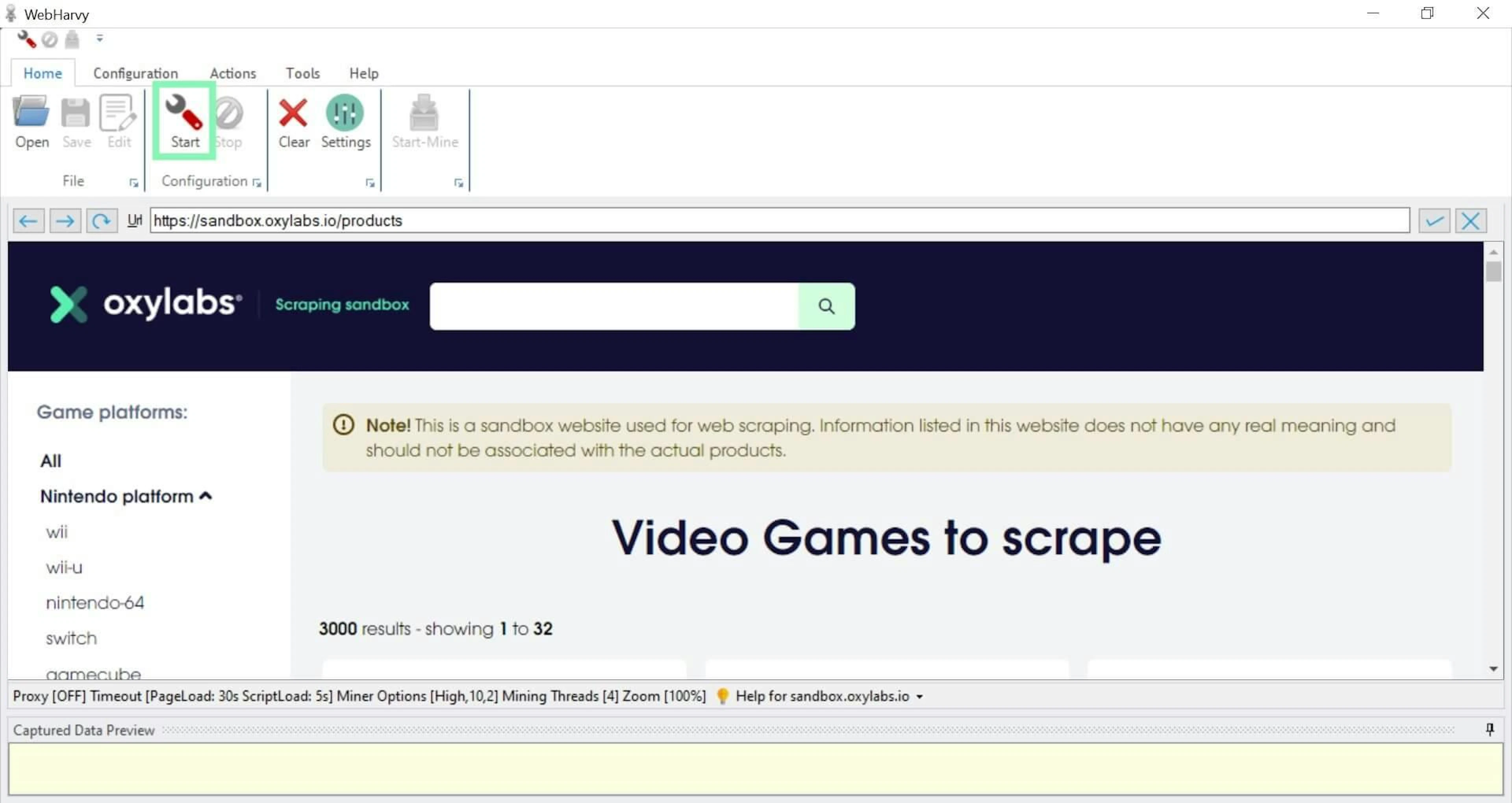
Initiating data selection
3. Select the desired attributes, for example, book titles and prices. The browser allows you to click on specific content for scraping. The cursor detects data patterns that occur on a webpage. If the data repeats, the tool scrapes it automatically without additional user input.
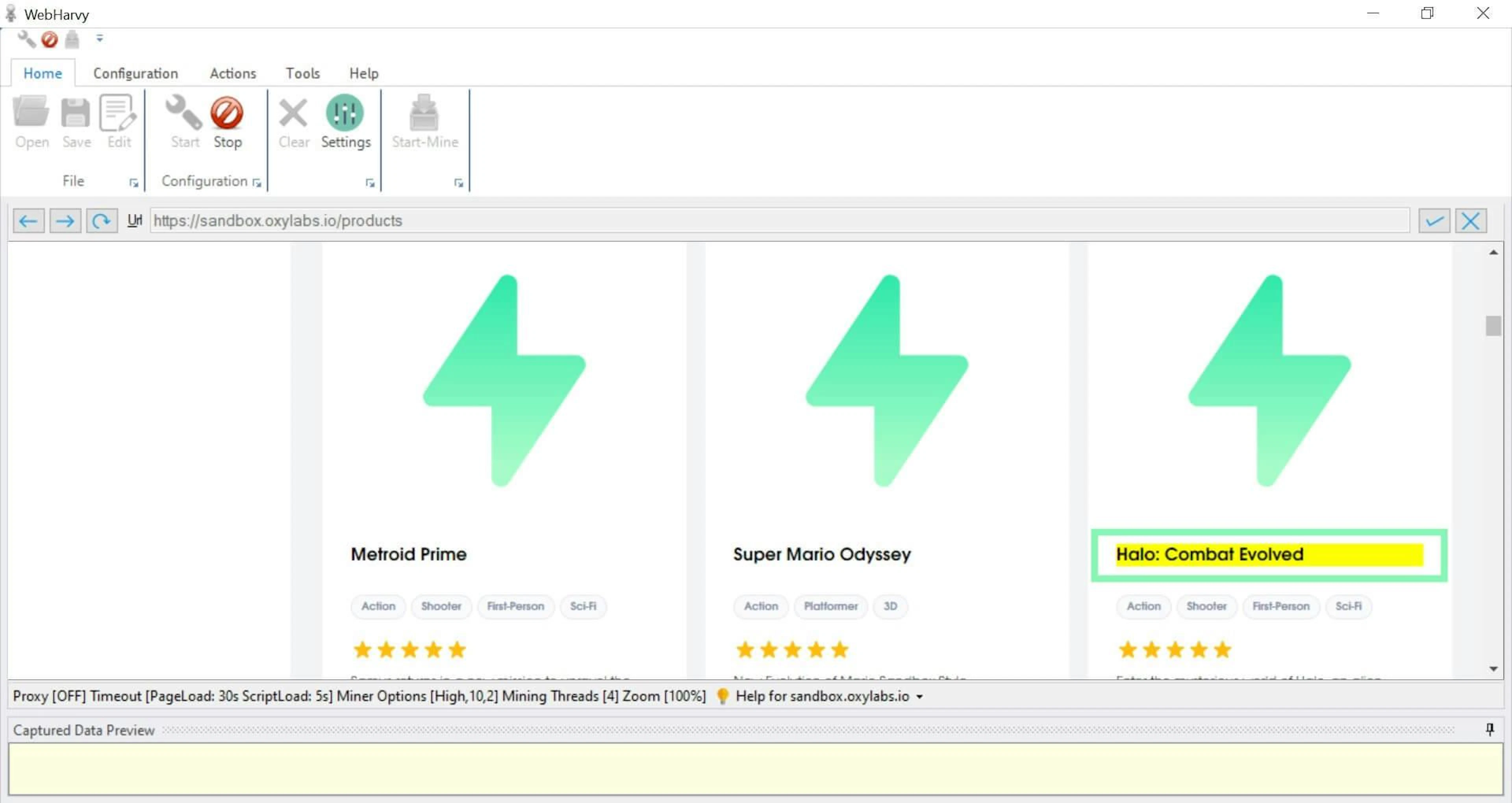
Selecting chunks of content
4. Choose Capture Text and name your items accordingly.
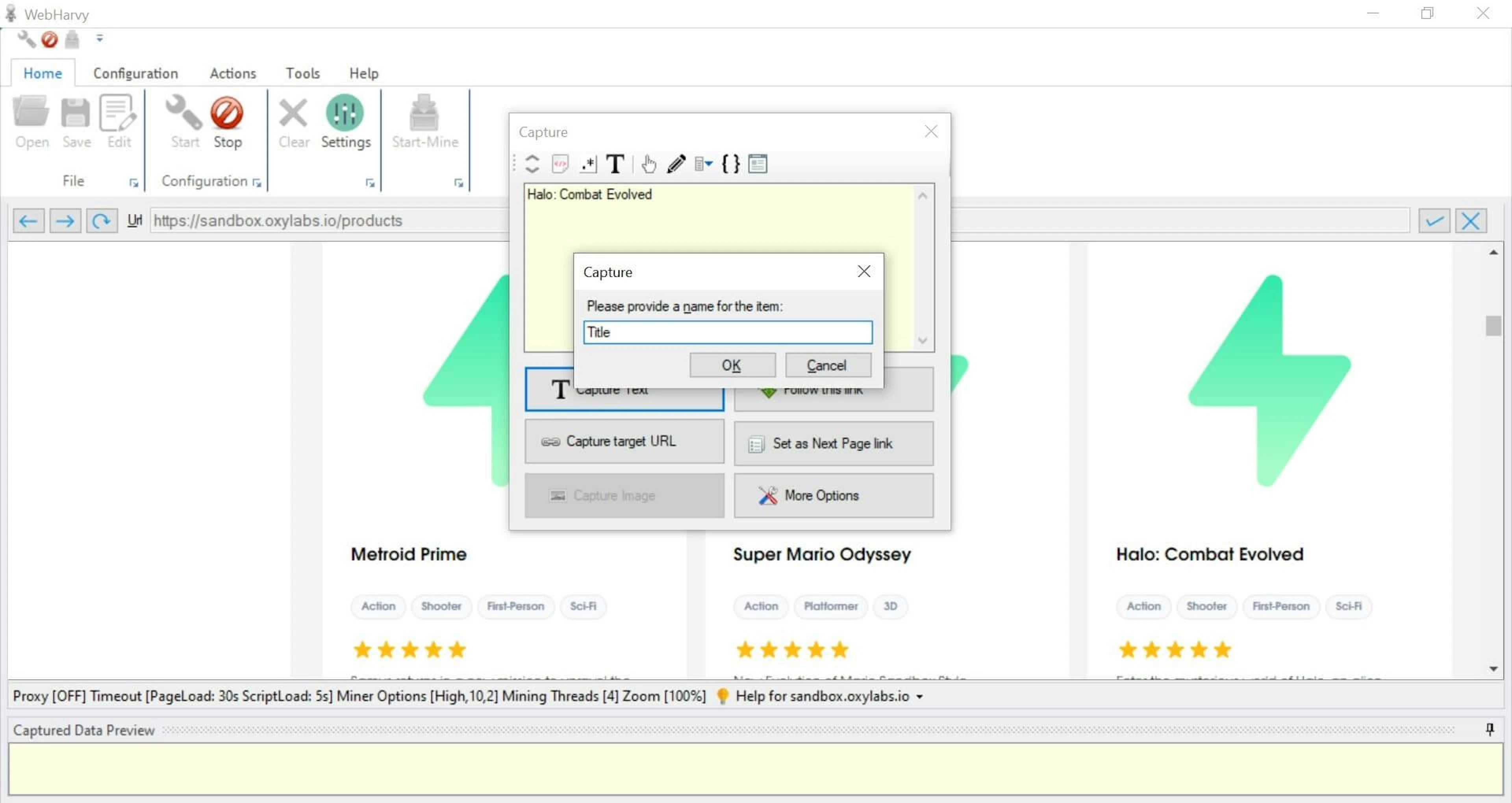
Capturing target data
5. After selecting data to be scraped, press Stop to finish the configuration.
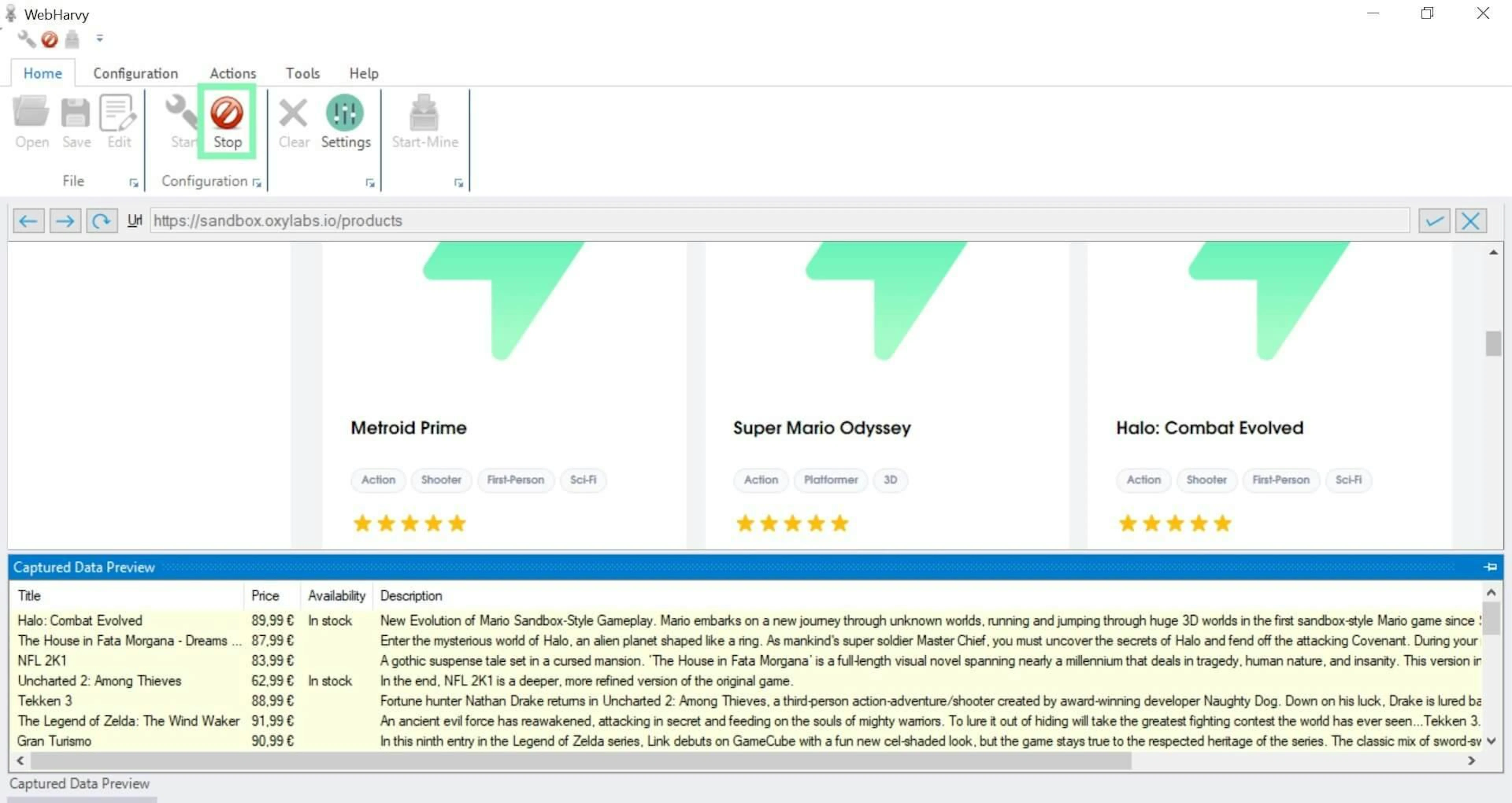
Finishing the configuration
6. Click Start-Mine and press ▶Start to extract your data.
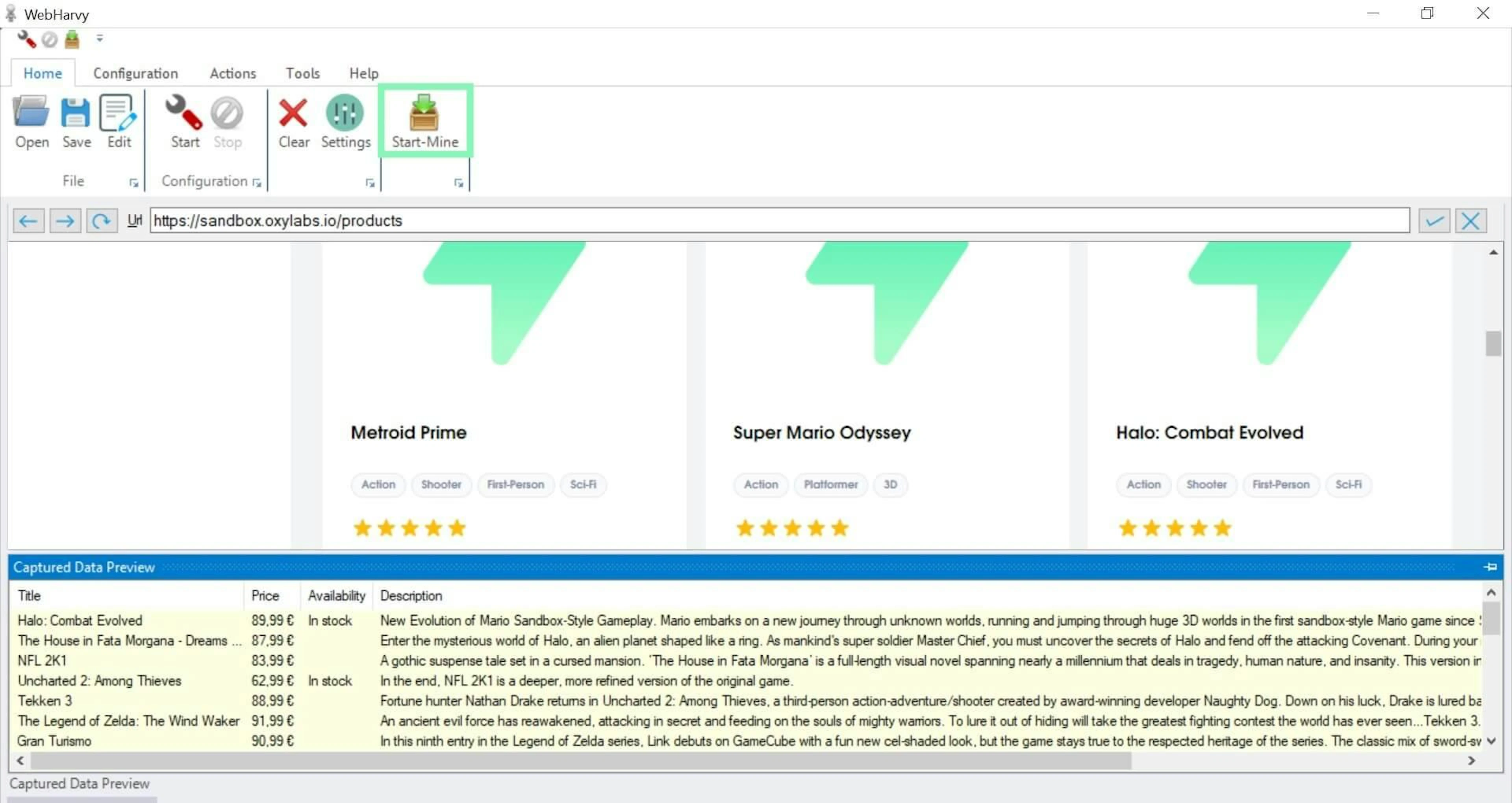
Extracting data
7. After the extraction process is over, click Export and select the export method. WebHarvy saves scraped data in Excel, XML, CSV, JSON, and TSV formats. Alternatively, a database destination could be used as well.
Exporting data
And that’s it. Here’s the final result – a spreadsheet with titles, prices, availability, and description.
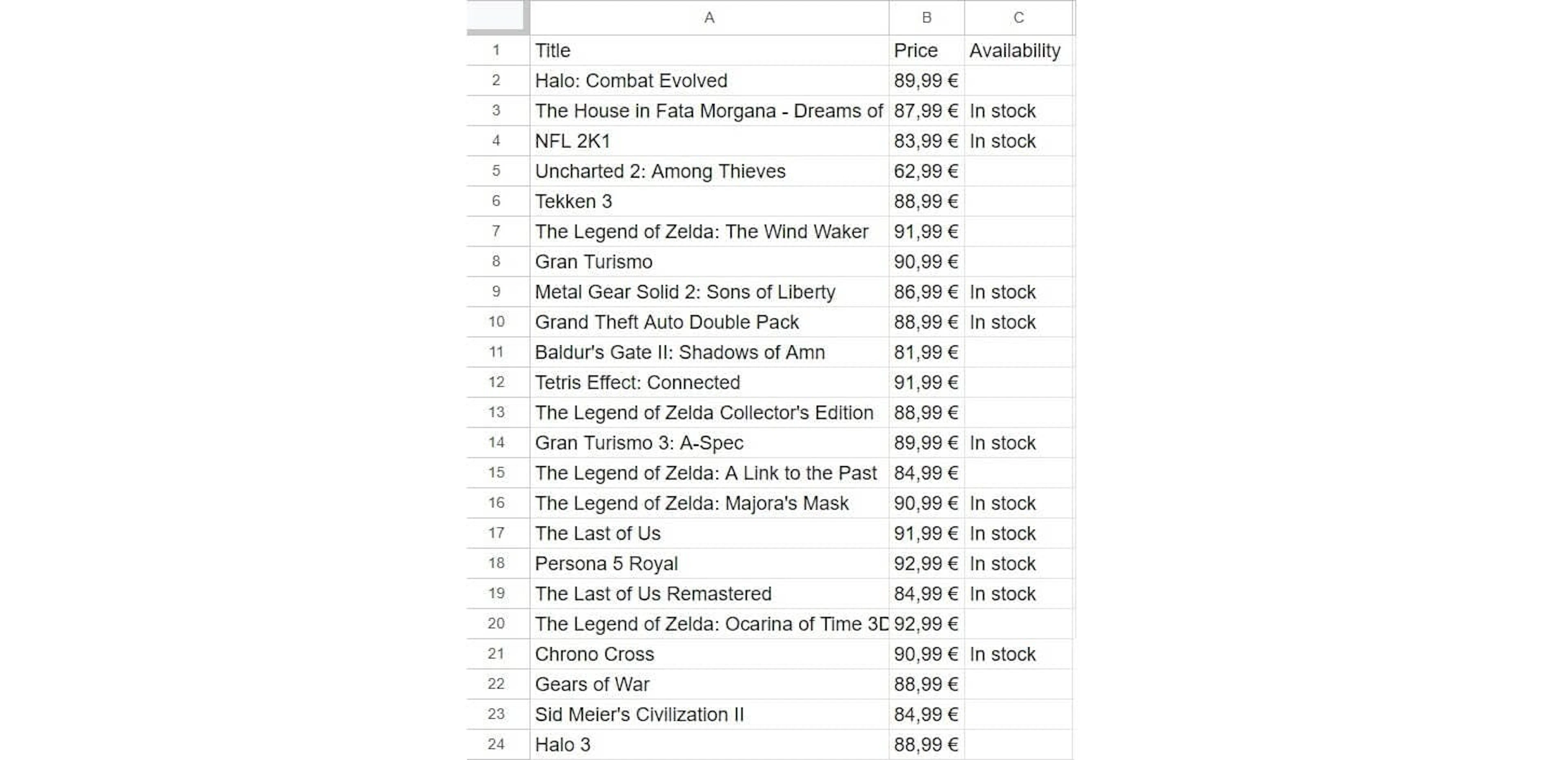
The final result
Wrapping up
Implementation of web scraping is a crucial part of up-to-date data-gathering solutions. WebHarvy is a code-free tool able to swiftly scale your daily data processing. As the tool accepts various third-party proxies, be sure to employ a reliable proxy services provider.
If you have any questions configuring our proxies or contemplating using our public web scraping solutions, don’t hesitate to get in touch with us for more information.
Please be aware that this is a third-party tool not owned or controlled by Oxylabs. Each third-party provider is responsible for its own software and services. Consequently, Oxylabs will have no liability or responsibility to you regarding those services. Please carefully review the third party's policies and practices and/or conduct due diligence before accessing or using third-party services.
Frequently asked questions
Is WebHarvy free?
As shareware, WebHarvy offers 15 days free trial.
Does WebHarvy support RegEx?
Useful resources
Most Common HTTP Headers
HTTP headers enable to transfer further details within the request or response headers. Find out 5 key HTTP headers that are crucial to use and optimize in web scraping.
Python Web Scraping Tutorial: Step-By-Step
We take you through every step of building your first web scraper. Find out how to get started in data acquisition with Python.
Web Crawler vs Web Scraper: The Differences
Data scraping has become the ultimate tool for business development with a significant influence in nearly any business area. With this article, we're covering the intricacies of data scraping in greater detail.

Get the latest news from data gathering world
Proxies
Advanced proxy solutions
Data Collection
Datasets
Resources
Innovation hub