175M+ ethically sourced IPs built for the highest reliability.
High-speed, cost-effective proxies built for any scraping workload.
Premium static residential proxies from trusted ASNs for most difficult targets.
Dedicated IPs from premium ASNs for demanding scraping.

AI-powered proxy solution for optimized web scraping performance.

20M+ IP addresses from real mobile devices for precise targeting.

Free Chrome proxy manager extension that works with any proxy provider.

Free Android proxy manager app that works with any proxy provider.

Free community-driven tools to improve your web scraping projects.
Web Scraper API
All-in-one web data collection platform for every stage of web scraping.
Fast Search API
Ultra-fast organic search results scraper tailored for AI workflows.
Headless Browser
Advanced browser automation solution for AI agents and scraping.
AI Studio
A suite of AI-powered tools for various scraping projects.

Documentation
All features, parameters, and integration details, backed by code samples in every coding language.
Tutorials, samples, and guides.
Latest fixes and features.






![]() AI Summary:
AI Summary:
Concurrency allows multiple tasks to appear to run simultaneously by rapidly switching execution on a single CPU core, pausing and resuming threads. Parallelism, however, involves tasks genuinely executing at the same time across multiple CPU cores or processors. Both approaches significantly improve performance by enabling faster processing of multiple operations, such as web scraping.
At first, it may seem that concurrency and parallelism may be referring to the same concepts. However, these terms are actually different.
This article explains the differences between concurrency vs parallelism. We also use a practical example to explore the concepts even more and show how using concurrency and parallelism can help speed up the web scraping process.
For your convenience, you can also watch this tutorial on concurrent vs parallel processing in a video format or keep reading a blog post.

What is concurrency?
To understand the difference between parallelism and concurrency, let’s begin with a definition of concurrent tasks. According to the Oxford Dictionary, concurrency means two or more things happening at the same time. However, this definition isn’t very helpful because parallel execution would also mean something similar. Let’s take a closer look at multitasking definition first.
A Central Processing Unit (CPU, or simply a processor) can work on only one task at a time. If multiple tasks are given to it, e.g., playing a song and writing code, it simply switches between these tasks. This switching is so fast and seamless that, for a user, it feels like multitasking.
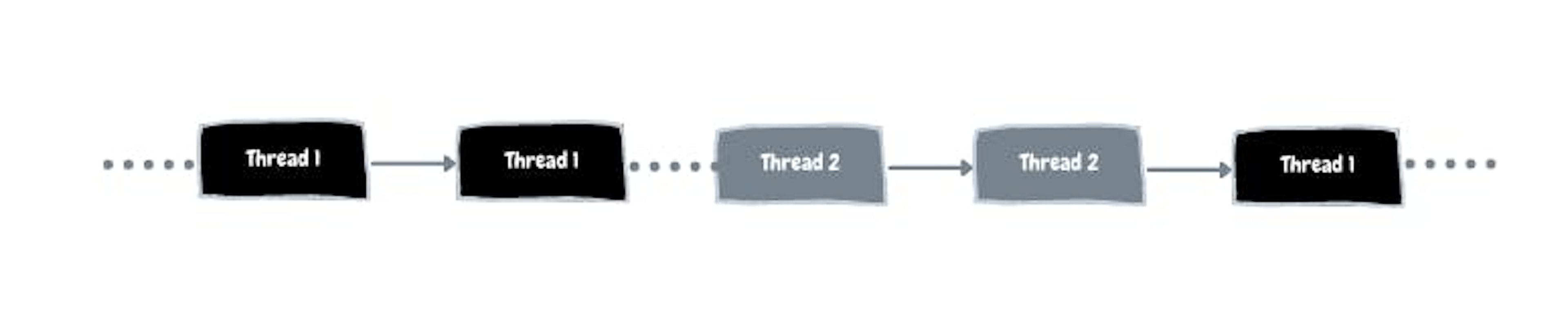
Concurrency is pausing and resuming threads
This capability of modern CPUs to pause and resume tasks so fast gives an illusion as if more than one task is running in parallel. However, this is not parallel. This is concurrent.
Concurrency can be broadly understood as multi-threading. There are usually many ways of creating concurrent applications, and threading is just one of them. Sometimes, other terms like asynchronous tasks are also used. The difference lies in the implementation and details. However, from a broader point of view, they both mean a set of instructions that can be paused and resumed.
There is a programming paradigm called Concurrent Computing. This involves writing code so that it seems like more than one process is being performed simultaneously, while they never actually execute at the same time. This is known as concurrent programming.
What is a thread?
In broad terms, a thread is the smallest set of tasks that can be handled and managed by the operating system without any dependencies on each other. The actual implementation differs in various operating systems. The way of programmatically creating threads also differs in various programming languages.
Python provides a powerful threading module for creating and managing threads.
Practical example
To understand how concurrency works, let’s solve a practical problem. The issue is to process over 200 pages as fast as possible. Here are the details:
Step 1. Go to the Wikipedia page with a list of countries by population and get the links of all the 233 countries listed on this page.
Step 2. Go to all these 233 pages and save the HTML locally.
Let’s create a function to get all the links. At first, we won’t involve concurrency or parallelism here.
import requests
from bs4 import BeautifulSoup
from urllib.parse import urljoin
def get_links():
countries_list = 'https://en.wikipedia.org/wiki/List_of_countries_by_population_(United_Nations)'
all_links = []
response = requests.get(countries_list)
soup = BeautifulSoup(response.text, "lxml")
countries_el = soup.select('td .flagicon+ a')
for link_el in countries_el:
link = link_el.get("href")
link = urljoin(countries_list, link)
all_links.append(link)
return all_linksThis function gets the response from the link and uses BeautifulSoup to extract all the links. Links that we retrieve are relative links. They are converted to absolute links using urljoin.
Now let’s write a function that doesn’t use any threading, but sequentially downloads the HTML from all those 233 links.
First, let’s create a function to fetch and save a link.
def fetch(link):
response = requests.get(link)
with open(link.split("/")[-1]+".html", "wb") as f:
f.write(response.content)This function is simply getting the response of the parameter link and saving it as an HTML file.
Finally, let’s call this function in a loop:
import time
if __name__ == '__main__':
links = get_links()
print(f"Total pages: {len(links)}")
start_time = time.time()
# This for loop will be optimized
for link in links:
fetch(link)
duration = time.time() - start_time
print(f"Downloaded {len(links)} links in {duration} seconds")With our computer, this took 137.37 seconds. Our objective is to bring this time down.
Using concurrency to speed up processes
Although we can create threads manually, we’ll have to start them manually and call the join method on each thread so that the main program waits for all these threads to complete.
The better approach is to use the ThreadPoolExecutor class. This class is part of the concurrent.futures module. The benefit of using this class is that it allows us an easy interface for creating and executing threads. Let’s see how it can be used.
First, we need to import ThreadPoolExecutor:
from concurrent.futures import ThreadPoolExecutorNow, the for loop written above can be changed to the following
with ThreadPoolExecutor(max_workers=16) as executor:
executor.map(fetch, links)Here, the executor applies the function fetch to every item of links and yields the results. The maximum number of threads is controlled by max_workers argument.
The final result is astonishing! All these 233 links were downloaded in 11.23 seconds. It’s a better result than the synchronous version which took around 138 seconds.
It’s important to find the sweet spot for the max_worker. On our computer, if the max_worker parameter is changed to 32, the time comes down to 4.6 seconds. Increasing this number further doesn’t improve things much. This sweet spot will differ for every processor for the same code.
Note: the print() function isn’t thread-safe. The reason is that print works with a reference to the standard output. The standard output is shared globally. We’ll use print() with a new line character explicitly and an empty end parameter.
What is parallelism?
In the previous section, we looked at a single processor. However, most processors have more than one core. In some cases, a machine can have more than one processor.
One example is parallel computing. This is a type of computation in which multiple processors carry out many processes at the same time. To achieve this parallel processing, specialized programming is needed. This is known as parallel programming, where the code is written to utilize multiple CPU Cores. In this case, more than one process is actually executed in parallel. The following image should help understand parallelism and how it helps in executing multiple tasks.
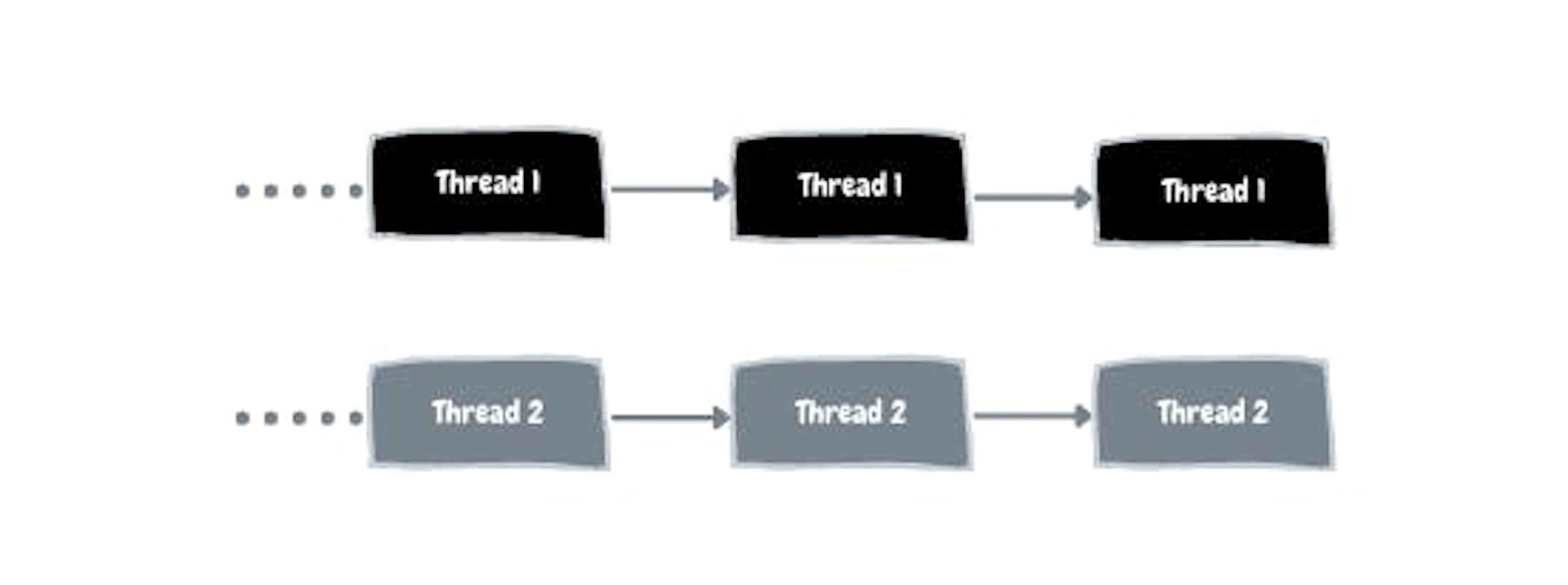
Parallelism is multiple threads running in multiple CPUs
Using parallelism to speed up processes
Let’s go back to the previously mentioned practical issue of downloading the HTML from all those 233 links.
In Python, parallelism can be achieved by using multitasking. It allows us for a simultaneous execution (download several links at the same time) by using several processors.
To write an effective code that can be run on any machine, you would need to know the number of processors available on that machine. Python provides a very useful method, cpu_count(), to get the count of the processor on a machine. This is very helpful to find the exact number of tasks that can be processed in parallel. Note that in the case of a multi-core CPU, each core works as a different CPU.
Let’s start with importing the required module:
from multiprocessing import Pool, cpu_countNow we can replace the for loop in the synchronous code with this code:
with Pool(cpu_count()) as p:
p.map(fetch, links)This will create a multiprocessing pool that is equal to the count of the CPU. It means that the limit of multiple tasks being carried out would be determined when the code is actually running.
This fetches all 233 links in 18.10 seconds. It’s also noticeably faster than the synchronous version which took around 138 seconds.
Difference between concurrency and parallelism
Here’s a list of parallelism vs concurrency differences:
Concurrency is when multiple tasks can run in overlapping periods. It’s an illusion of multiple tasks running in parallel because of a very fast switching by the CPU. Two tasks can’t run at the same time in a single-core CPU. Parallelism is when tasks actually run in parallel in multiple CPUs.
Concurrency is about managing multiple different tasks at the same time, while a parallel program is running multiple instruction sequences at the same time.
In Python, concurrency is achieved by using threading, while parallelism is achieved by using multitasking.
Concurrency needs only one separate CPU Core, while to achieve parallelism it needs more than one.
Concurrent programs are about interruptions, and parallelism is about isolation.
Combination of concurrent and parallel programming
This is often known as Parallel Concurrent execution. The following image can help to understand the combination of parallelism and concurrency.
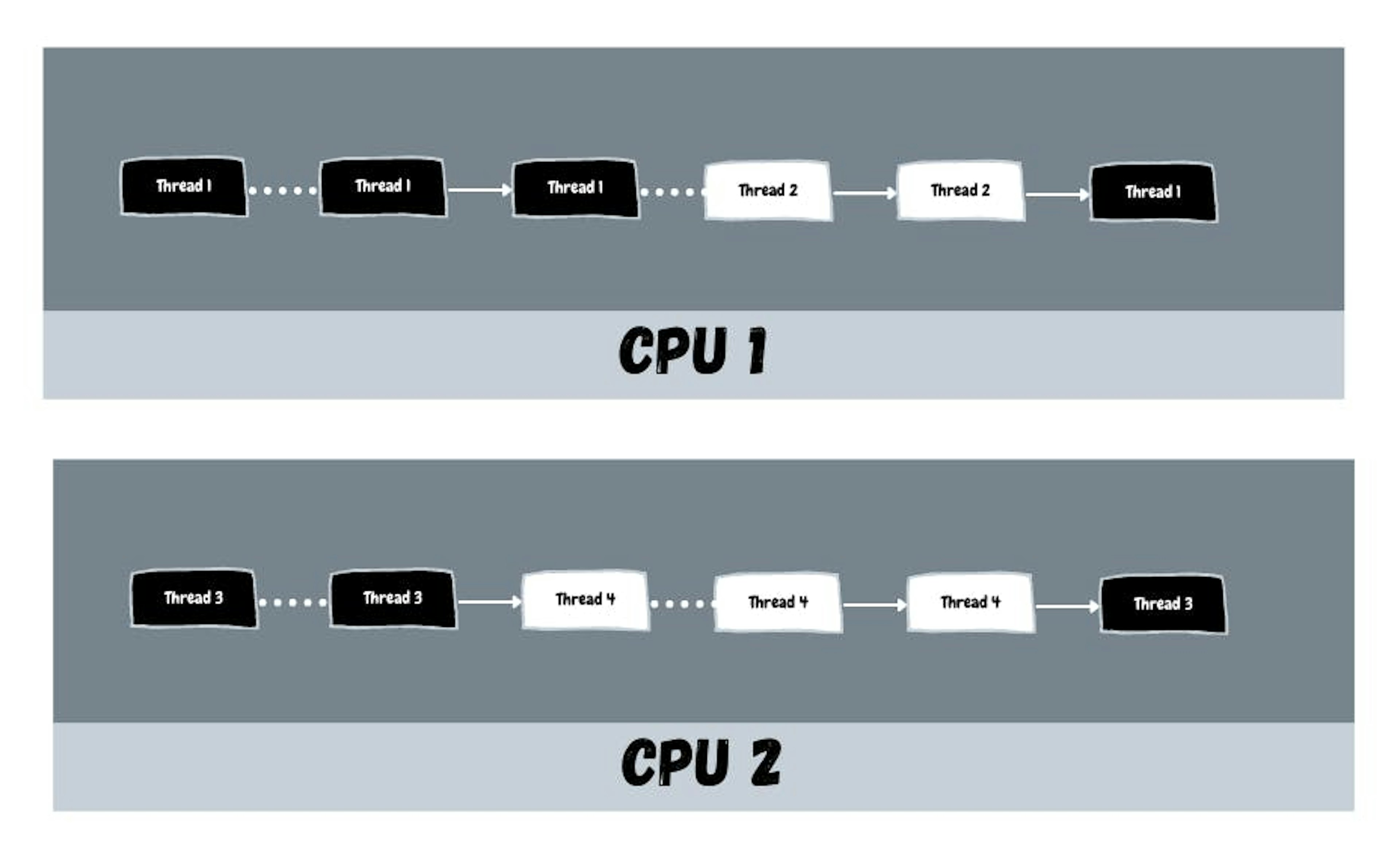
An example of concurrent and parallel execution
As it’s evident, if multiple CPUs are running separate threads, the process is parallel and concurrent at the same time.
Suitable solution for web scraping
It can be assumed that both parallel and concurrent programming make the web scraping process much faster. However, this should be taken with a pinch of salt. Every project is unique, and the complexity of every project is different.
Starting with concurrency first and then looking at parallelism would be a great idea. Combining concurrency and parallelism may help in some cases, but it can make code complex and introduce challenging trace bugs. Once again, you should choose the one that suits your web scraping project best.
In addition to optimizing your code, implementing proxy servers is another powerful way to scale your web scraping efforts efficiently. Proxies help to distribute requests across different IP addresses, avoiding rate limits and IP bans that can prevent your scraper from running smoothly – even when your system is fully concurrent or parallelized. Residential, rotating, or datacenter proxies can each play a role depending on your target website and business needs. Additionally, if you’re looking to test proxies before committing to a full subscription, you can always take advantage of high-quality free proxies coming from a reputable provider.
You can always forget about complex web scraping processes and choose an advanced public data collection solution – Web Scraper API. Try it for free to decide if it's a suitable option for your case.
Conclusion
In this article, we explored concurrency vs parallelism and described what is the difference between concurrency and parallelism. Concurrency can be easily understood as multiple threads or units of work that can be paused and resumed. Parallelism is simply multiple tasks running on multiple cores. Concurrency and parallelism can be achieved using Python threading and multitasking libraries, respectively. Using either concurrent vs parallel execution will improve the performance of the web scraping process significantly.
See more comparison articles, such as Go vs Python, by exploring our blog.
About the author

Iveta Liupševičė
Head of Content & Research
Iveta Liupševičė is a Head of Content & Research at Oxylabs. Growing up as a writer and a challenge seeker, she decided to welcome herself to the tech-side, and instantly became interested in this field. When she is not at work, you'll probably find her just chillin' while listening to her favorite music or playing board games with friends.
All information on Oxylabs Blog is provided on an "as is" basis and for informational purposes only. We make no representation and disclaim all liability with respect to your use of any information contained on Oxylabs Blog or any third-party websites that may be linked therein. Before engaging in scraping activities of any kind you should consult your legal advisors and carefully read the particular website's terms of service or receive a scraping license.
Related articles





Scale your web scraping with proxies
Use high-quality Oxylabs proxies to scale your web scraping efforts and prevent unwanted blocks.

Get the latest news from data gathering world
Scale up your business with Oxylabs®
Proxies
Advanced proxy solutions
Data Collection
Datasets
Resources
Innovation hub
Scale your web scraping with proxies
Use high-quality Oxylabs proxies to scale your web scraping efforts and prevent unwanted blocks.