175M+ ethically sourced IPs built for the highest reliability.
High-speed, cost-effective proxies built for any scraping workload.
Premium static residential proxies from trusted ASNs for most difficult targets.
Dedicated IPs from premium ASNs for demanding scraping.

AI-powered proxy solution for optimized web scraping performance.

20M+ IP addresses from real mobile devices for precise targeting.

Free Chrome proxy manager extension that works with any proxy provider.

Free Android proxy manager app that works with any proxy provider.

Free community-driven tools to improve your web scraping projects.
Web Scraper API
All-in-one web data collection platform for every stage of web scraping.
Fast Search API
Ultra-fast organic search results scraper tailored for AI workflows.
Headless Browser
Advanced browser automation solution for AI agents and scraping.
AI Studio
A suite of AI-powered tools for various scraping projects.

Documentation
All features, parameters, and integration details, backed by code samples in every coding language.
Tutorials, samples, and guides.
Latest fixes and features.







![]() AI Summary:
AI Summary:
This tutorial shows how to scrape Zillow real estate data using Python and third-party scraping APIs. The guide covers sending requests to extract search results, individual listings, and agent information, then parsing the JSON responses and saving the collected data to a CSV file.
Zillow is one of the largest real estate websites in the United States, with 200+ million visits per month. With a number this big, it’s no surprise that this website contains immense amounts of valuable information for real estate professionals. But to take advantage of this data, you’ll require a reliable web scraping solution. In today’s article, you’ll see an in-depth demonstration of how to use the Zillow data API, part of Web Scraper API, to gather real estate listings data.
For your convenience, we have a full Zillow scraping tutorial in video format:

What Zillow data points can be scraped?
With Oxylabs’ Zillow Scraper API, you can easily extract data from any public Zillow page, including but not limited to:
| 📍 Full addresses | 💰 Prices |
| ️🏠 Property details | 🖼️ Pictures |
| 🛏️ Beds and ️🛁 Bathrooms | 📏 Square footage |
| 👤 Listed by | 📝 Descriptions |
| ⏳ Time on Zillow | 👀 Views and Saves |
| 📈 Estimated market value | 💵 Price and Public Tax history |
How to scrape Zillow search results using Zillow Scraper API
To scrape Zillow data, let’s use Python to interact with the Zillow Scraper API; however, you can choose a different programming language if you like.
Get a free trial
Claim a free trial to test Zillow Scraper API.
up to 2K results
No credit card required
1. Install Python and required libraries
Begin by installing the latest version of Python. Once that’s done, you’ll need to install the following packages using Python's package manager pip:
pip install requests bs4The command above will install the requests and bs4 libraries. These modules will help to interact with the API and parse the extracted HTML files. You can also use the built-in Custom Parser feature for this quest, instead of Beautiful Soup.
2. Send a POST request to the Zillow Scraper API with the source and URL parameters
Before you start writing the code, let’s discuss the parameters of the API. Oxylabs’ Zillow API requires only two parameters – source and url; the rest are optional. Let’s take a look at what they do:
source – to scrape Zillow data, this parameter needs to be set to universal;
url – a valid link to any Zillow page;
user_agent_type – sets the device type and browser;
geo_location – allows acquiring data from a specific location;
locale – sets the `Accept-Language` header based on this parameter;
render - enables JavaScript rendering;
browser_instructions – performs specific browsing actions when executing JavaScript.
By following this section, you’ll build a Zillow web scraping tool to retrieve the properties in JSON format from Zillow search results and then extract data from each Zillow property. First, let’s import the necessary dependencies:
import requests, json, csvNext, insert a search query and copy the URL. For this example, let’s search for properties on sale, which gives us this URL: https://www.zillow.com/los-angeles-ca/. Before continuing, open the Developer Tools, head to the Network tab, filter for Fetch/XHR resources, and find a resource called async-create-search-page-state:
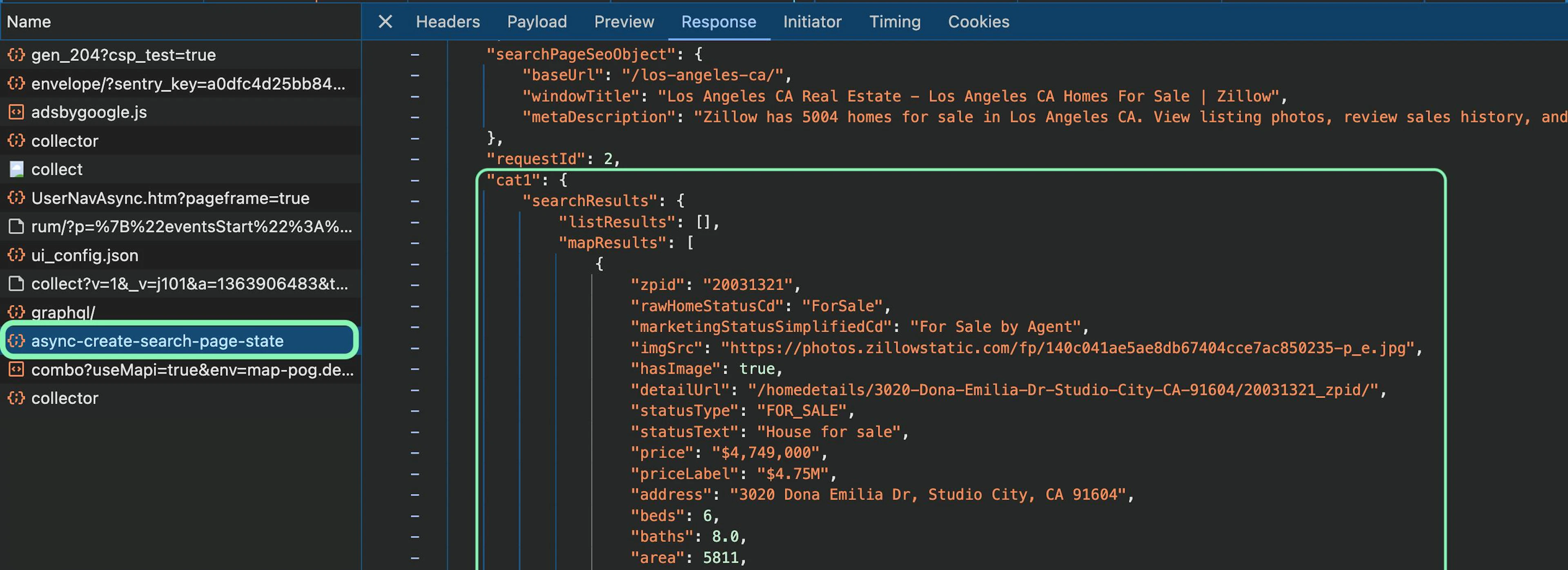
In the Response tab of this resource, you can find JSON data that contains a total of 500 Zillow listings. You can use the API to get the data from this JSON resource, simplifying the scraping and parsing process in Python. As such, there's no need to scrape individual search pages through pagination or scrape the Zillow map interface. Head to the Headers tab and copy the URL: https://www.zillow.com/async-create-search-page-state.
Using this URL, you can create a payload:
url = 'https://www.zillow.com/los-angeles-ca/'
payload = {
'source': 'universal',
'url': url,
'user_agent_type': 'desktop',
'render': 'html',
'browser_instructions': [
{
'type': 'fetch_resource',
'filter': 'https://www.zillow.com/async-create-search-page-state'
}
]
}Within the browser_instructions parameter, you can see the command that fetches the target resource. Next, let’s use the requests module to make a POST request to the API and store the result in the response variable:
response = requests.post(
'https://realtime.oxylabs.io/v1/queries',
auth=('USERNAME', 'PASSWORD'),
json=payload,
)Notice a tuple with username and password – make sure to replace these with your own Oxylabs credentials. The payload is also sent as json.
Next, let’s print the response code to validate that the connection was successful:
print(response.json())
print(response.status_code)Here, you should get a 200 status code; if you don’t, make sure your internet connection is working and you’ve entered the correct URL and credentials.
3. Parse the JSON response
The next step is to parse the retrieved Zillow JSON response containing all listing information. First, you need to grab the Zillow content from the entire JSON output of the API:
data = json.loads(response.json()['results'][0].get('content'))Then, create an empty list to store all parsed Zillow listings and then extract the data points you want from each listing:
listings = []
for listing in data['cat1']['searchResults']['mapResults']:
listing = {
'URL': 'https://www.zillow.com' + listing.get('detailUrl'),
'Address': listing.get('address'),
'Price': listing.get('price'),
'Status': listing.get('statusText'),
'Beds': listing.get('beds'),
'Baths': listing.get('baths'),
'Area (sqft)': listing.get('area'),
'Image': listing.get('imgSrc'),
'ZPID': listing.get('zpid')
}
listings.append(listing)Here, we’re simply looping over the search results list and parsing each result to extract Zillow data like the listing URL, address, price, and other details from the property page.
4. Save results to a CSV file
You can easily print the results to your terminal:
print(listings)Alternatively, you can utilize Python's CSV module to save all scraped Zillow property data to a CSV file that can be opened in Excel. Add the following lines to your Python file:
# Save the parsed listings to a CSV file.
with open('zillow_listings.csv', 'w') as f:
fieldnames = listings[0].keys()
writer = csv.DictWriter(f, fieldnames=fieldnames)
writer.writeheader()
for item in listings:
writer.writerow(item)Complete code example
import requests, json, csv
url = 'https://www.zillow.com/los-angeles-ca/'
payload = {
'source': 'universal',
'url': url,
'user_agent_type': 'desktop',
'render': 'html',
'browser_instructions': [
{
'type': 'fetch_resource',
'filter': 'https://www.zillow.com/async-create-search-page-state'
}
]
}
response = requests.post(
'https://realtime.oxylabs.io/v1/queries',
auth=('USERNAME', 'PASSWORD'),
json=payload,
)
data = json.loads(response.json()['results'][0].get('content'))
listings = []
for listing in data['cat1']['searchResults']['mapResults']:
listing = {
'URL': 'https://www.zillow.com' + listing.get('detailUrl'),
'Address': listing.get('address'),
'Price': listing.get('price'),
'Status': listing.get('statusText'),
'Beds': listing.get('beds'),
'Baths': listing.get('baths'),
'Area (sqft)': listing.get('area'),
'Image': listing.get('imgSrc'),
'ZPID': listing.get('zpid')
}
listings.append(listing)
with open('zillow_listings.csv', 'w') as f:
fieldnames = listings[0].keys()
writer = csv.DictWriter(f, fieldnames=fieldnames)
writer.writeheader()
for item in listings:
writer.writerow(item)How to scrape individual Zillow listings with Beautiful Soup
Now, let’s see how you can extract individual listing data from Zillow listing pages using the Beautiful Soup library. For our example, let’s use the link below, but feel free to replace it with your own: https://www.zillow.com/homedetails/3020-Dona-Emilia-Dr-Studio-City-CA-91604/20031321_zpid/. Start by importing the requests and Beautiful Soup libraries:
import requests
from bs4 import BeautifulSoupNext, add your Zillow listing URL, create the API payload parameters, and send a request using the requests library:
url = 'https://www.zillow.com/homedetails/3020-Dona-Emilia-Dr-Studio-City-CA-91604/20031321_zpid/'
payload = {
'source': 'universal',
'url': url,
'user_agent_type': 'desktop',
}
response = requests.post(
'https://realtime.oxylabs.io/v1/queries',
auth=('USERNAME', 'PASSWORD'),
json=payload,
)You’ll also have to inspect the desired elements to find the specific HTML tags and attributes. You can do it with a web browser and parse the listing page with Beautiful Soup, using that information accordingly. The following code will print Zillow listing data in the terminal:
content = response.json()['results'][0].get('content', '')
soup = BeautifulSoup(content, 'html.parser')
price = soup.select_one('[data-testid="price"]').text
address = soup.select_one('div[class*="Address"] h1').text
number_of_bed = soup.select('div[data-testid*="bed"] span:first-child')[0].text
size = soup.select('div[data-testid*="bed"] span:first-child')[1].text
status = soup.select_one('[data-testid="home-status"], [data-testid*="status"] span:last-child').text
property_data = {
'link': url,
'price': price,
'address': address,
'number of bed': number_of_bed,
'size (sqft)': size,
'status': status,
}
print(property_data)How to scrape Zillow real estate agent data
You can also extract real estate data from agent web pages using the same API. For this, you’ll only need to slightly modify the search result scraper you’ve built earlier.
For this example, let’s use a URL that opens a list of real estate agents in the Decatur, GA area:
https://www.zillow.com/professionals/real-estate-agent-reviews/decatur-ga/.
When you open the Developer Tools > Network tab, search for Fetch/XHR resources, and navigate to the second page in your browser, you can see a resource that starts with search/?profileType=2:
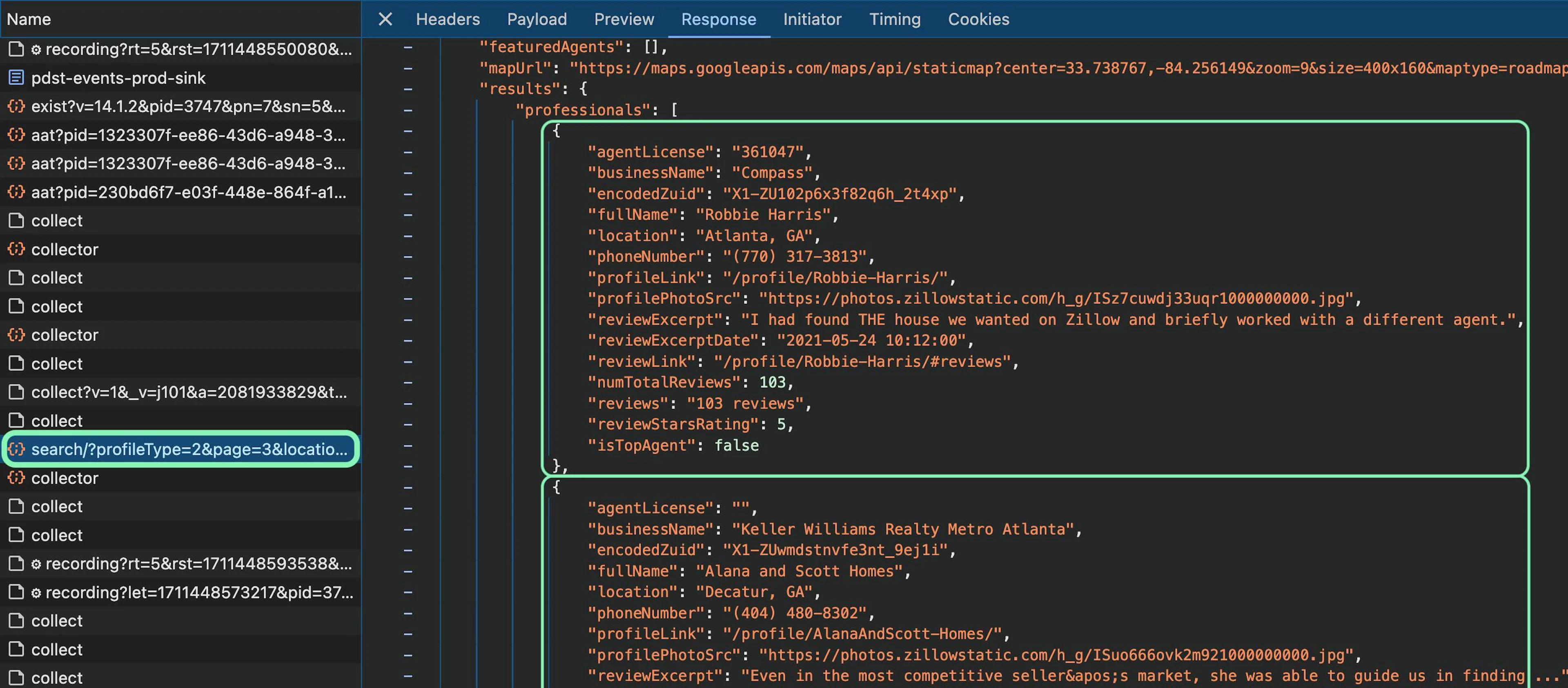
This resource contains the agent data in JSON format; hence, you can access the first page of the agents list with this URL: https://www.zillow.com/professionals/api/v2/search/?profileType=2&page=1&locationText=Decatur%20GA. The second page can be accessed by switching the page parameter to page=2. With all this in mind, you can form the URL dynamically and send a request to each agent page URL:
import requests, json, csv
number_of_pages = 5
urls = [f'https://www.zillow.com/professionals/api/v2/search/?profileType=2&page={page_num}&locationText=Decatur%20GA' for page_num in range(1, number_of_pages + 1)]
payload = {
'source': 'universal',
'url': None,
'user_agent_type': 'desktop'
}
data = []
for url in urls:
payload['url'] = url
response = requests.post(
'https://realtime.oxylabs.io/v1/queries',
auth=('USERNAME', 'PASSWORD'),
json=payload,
)
data.append(response.json()['results'][0]['content'])
agents = []
for page_data in data:
valid_json = json.loads(page_data)
professionals = valid_json['results']['professionals']
for agent in professionals:
agent = {
'Business name': agent.get('businessName'),
'Agent Name': agent.get('fullName'),
'Location': agent.get('location'),
'Phone number': agent.get('phoneNumber'),
'Profile link': 'https://www.zillow.com' + agent.get('profileLink'),
'Reviews': agent.get('numTotalReviews'),
'Rating': agent.get('reviewStarsRating'),
'Total sales': agent.get('saleCountAllTime'),
'Top agent': agent.get('isTopAgent')
}
agents.append(agent)
with open('zillow_agents.csv', 'w') as f:
fieldnames = agents[0].keys()
writer = csv.DictWriter(f, fieldnames=fieldnames)
writer.writeheader()
for item in agents:
writer.writerow(item)Once you run this code, it’ll use the API to extract the list of real estate agents from the number of pages you’ve defined. Feel free to adjust the code to extract more agent details, including review excerpts, review link, or even a three year minimum/maximum sale price range.
Scaling operations with Zillow Scraper API
In this article, we’ve shown you how to extract data from Zillow, yet you can expand the code further by scraping more data points and doing it all on a large scale. There are a few options to consider if you want to scale up your public data acquisition:
Use the batch query endpoint to simultaneously submit up to 5,000 Zillow URLs for scraping;
Use the asyncio and aiohttp libraries to send requests asynchronously. This way, you’ll make your scraping operations significantly faster;
Utilize the geo_location parameter to randomize the IP address for each request. As a result, you’ll be able to spread your requests across multiple IPs and not trip any bot monitoring systems.
Benefits of real estate data scraping
Let’s answer one crucial question: is scraping property information from Zillow beneficial? Yes, in fact, it is beneficial for several reasons:
Collecting bulk data
Automated web scraping tools allow you to easily gather large amounts of data from multiple sources. This way, you don’t have to spend hours of repetitive work; also, it would nearly be impossible to collect large volumes of data manually. And, as a real estate professional, you'll definitely need large quantities of data to make informed decisions.
Accessing data from various sources
Certain trends and patterns may not be apparent from a single source of data. That said, it would be wise to scrape data from several sources, including listing sites, property portals, and individual agent or broker websites. This way, you’ll be sure to get a more comprehensive view of the real estate market.
Detect new opportunities
Scraping real estate data can also help you identify opportunities and make more informed decisions. For example, as an investor, you can use scraped data to identify real estate properties that are undervalued or overvalued in order to make more profitable investment decisions.
Similarly, you can use scraped data to identify properties that are similar to your own listings – this way, you can determine the optimal pricing and marketing strategy.
Challenges of real estate data scraping
Nothing good ever comes easy, and the process of scraping real estate websites is no exception. Let’s take a look at some of the common obstacles you may come across during the process:
Sophisticated dynamic layouts
Often, property websites use complex and dynamic web layouts. Because of that, it may be difficult for web scrapers to adapt and extract relevant information. As a result, the extracted data may be inaccurate or incomplete, requiring you to make fixes manually.
Advanced anti-scraping measures
Another common challenge is that many property websites use technologies like JavaScript, AJAX, and CAPTCHA. These technologies may prevent you from gathering the data or even result in an IP flagging, so you’ll need specific techniques to handle them.
Questionable data quality
It’s no secret that property prices change rapidly; hence, there’s a risk of receiving outdated information that doesn’t reflect the present state of the real estate market.
Copyrighted data
All in all, the legality of web scraping is a largely debated topic. And, when it comes to extracting data from real estate sites, it’s no exception. The rule of thumb is if the data is considered publicly available, you should be able to scrape it. On the other hand, if the data is copyrighted, you should respect the rules and not scrape it. In general, it’s best if you consult a legal professional about your specific situation so you can be sure you’re not breaching any rules.
Conclusion
Due to the frequent layout changes and bot monitoring measures, scraping Zillow can be rather challenging. Luckily, Oxylabs’ Zillow data scraper is designed to deal with these obstacles so you can scrape Zillow data successfully.
If you run into any questions or uncertainties, don’t hesitate to reach out to our support team via email or live chat on our website. Our professional team will gladly consult you about any matter related to scraping public data from Zillow.
Frequently Asked Questions
Does Zillow allow scraping?
Zillow property listings and associated details are publicly accessible information. Essentially, you can extract property data and track price fluctuations, property availability, and agents from Zillow pages. Nevertheless, the Oxylabs team recommends consulting legal counsel prior to initiating any scraping activities in order to assess your specific situation and account for pertinent local and international regulations. It's essential to acquire expert advice on the appropriate course of action. For a more thorough exploration of the legal dimensions of web scraping, you can find additional information here.
How can I pull data from Zillow?
Is Zillow API free?
Can I export Zillow listings to Excel?
About the author

Vytenis Kaubrė
Technical Content Researcher
Vytenis Kaubrė was a Technical Content Researcher at Oxylabs. Creative writing and a growing interest in technology fueled his work, where he researched and crafted technical content while honing his skills in Python. Off duty, he could often be found working on personal projects, learning about cybersecurity, or relaxing with a book.
All information on Oxylabs Blog is provided on an "as is" basis and for informational purposes only. We make no representation and disclaim all liability with respect to your use of any information contained on Oxylabs Blog or any third-party websites that may be linked therein. Before engaging in scraping activities of any kind you should consult your legal advisors and carefully read the particular website's terms of service or receive a scraping license.
Related articles

Web Scraping in R: A Complete Tutorial for Data Extraction in R

Augustas Pelakauskas
2026-05-05

Guide to Using Google Sheets for Basic Web Scraping
Vytenis Kaubrė
2025-07-18


Try Zillow Scraper API
Choose Oxylabs' Zillow Scraper API to gather real estate data with no interruptions.

Get the latest news from data gathering world
Scale up your business with Oxylabs®
Proxies
Advanced proxy solutions
Data Collection
Datasets
Resources
Innovation hub
Try Zillow Scraper API
Choose Oxylabs' Zillow Scraper API to gather real estate data with no interruptions.