175M+ ethically sourced IPs built for the highest reliability.
High-speed, cost-effective proxies built for any scraping workload.
Premium static residential proxies from trusted ASNs for most difficult targets.
Dedicated IPs from premium ASNs for demanding scraping.

AI-powered proxy solution for optimized web scraping performance.

20M+ IP addresses from real mobile devices for precise targeting.

Free Chrome proxy manager extension that works with any proxy provider.

Free Android proxy manager app that works with any proxy provider.

Free community-driven tools to improve your web scraping projects.
Web Scraper API
All-in-one web data collection platform for every stage of web scraping.
Fast Search API
Ultra-fast organic search results scraper tailored for AI workflows.
Headless Browser
Advanced browser automation solution for AI agents and scraping.
AI Studio
A suite of AI-powered tools for various scraping projects.

Documentation
All features, parameters, and integration details, backed by code samples in every coding language.
Tutorials, samples, and guides.
Latest fixes and features.






![]() AI Summary:
AI Summary:
This tutorial outlines the challenges of scraping Google search results, such as CAPTCHAs and IP interruptions. It then demonstrates two Python-based methods for overcoming these issues: using a specialized SERP API to obtain structured data or employing Playwright with residential proxies for direct scraping.
With Google being the largest search engine, naturally, it holds immeasurable amounts of useful information. However, if you need to scrape Google search pages automatically, you may run into some difficulties. Using a reliable free proxy list or any other proxy option can help you ensure consistent public data access. In today's article, we'll explore what exactly those difficulties are, how to overcome them, and successfully scrape Google search results.
For your convenience, we also prepared this tutorial in a video format:

What is a Google SERP?
Upon any discussion of web scraping Google search results, you'll likely run into the “SERP” abbreviation. SERP stands for Search Engine Results Page; it's the page you get after entering a query into the search bar. Back in the day, Google would return a list of links for your query. Today, it looks completely different – to make your search experience quick and convenient, SERPs contain various features and elements. There are quite a few of them, so let's just take a look at the most important ones.
1. Featured snippets
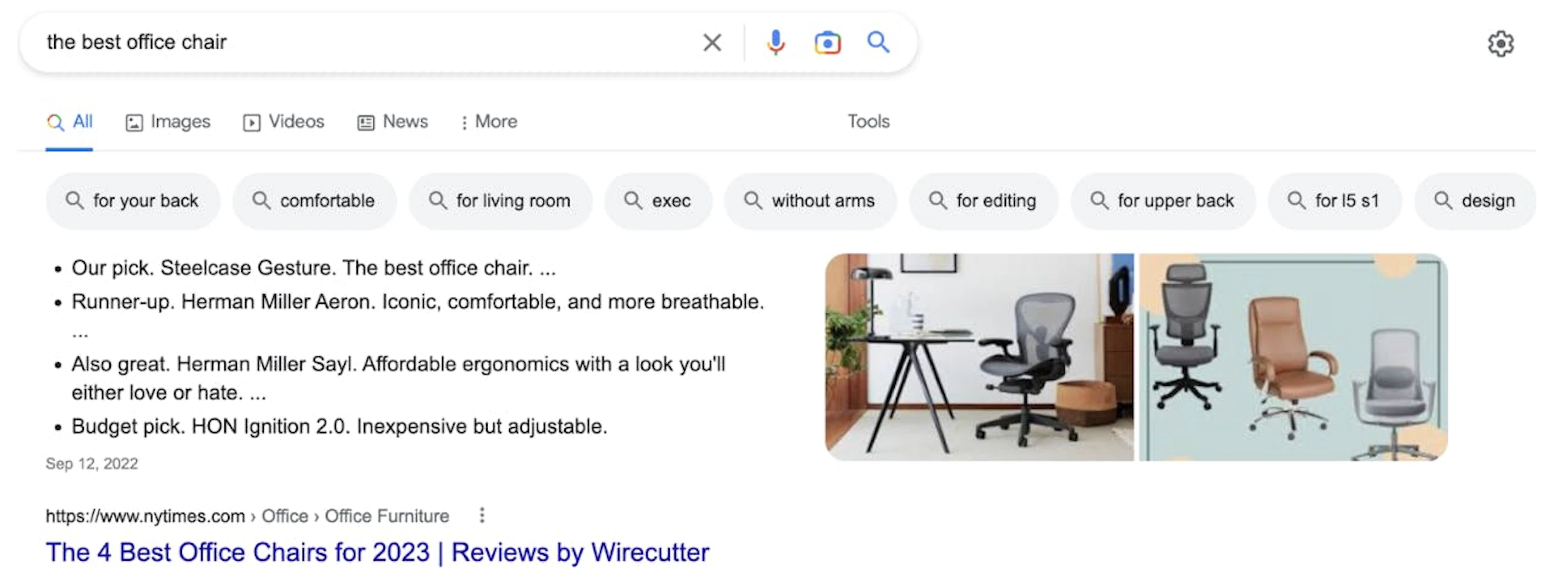
2. Paid ads
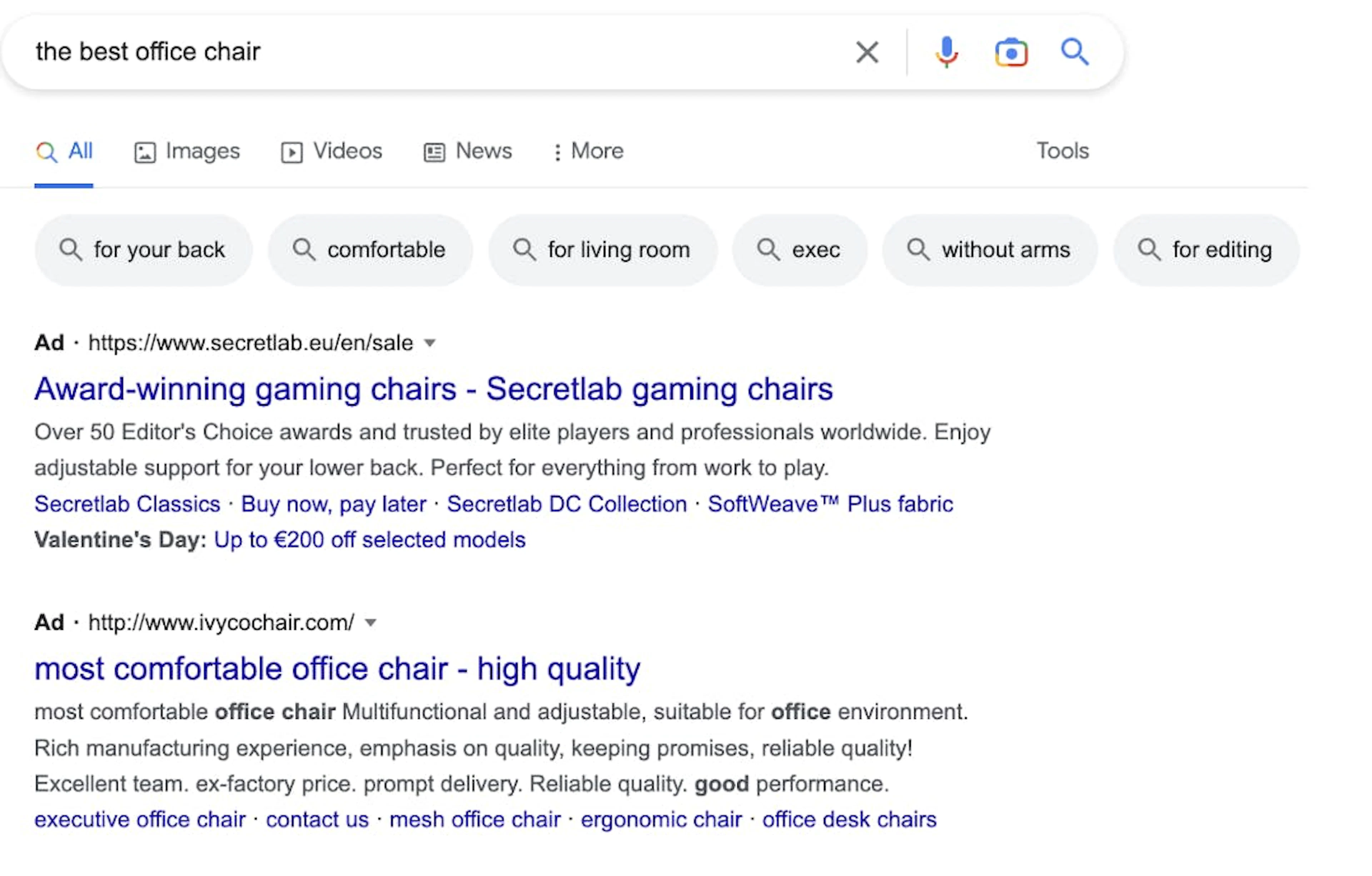
3. Video carousel
Image source: fiveblocks.com
4. People also ask
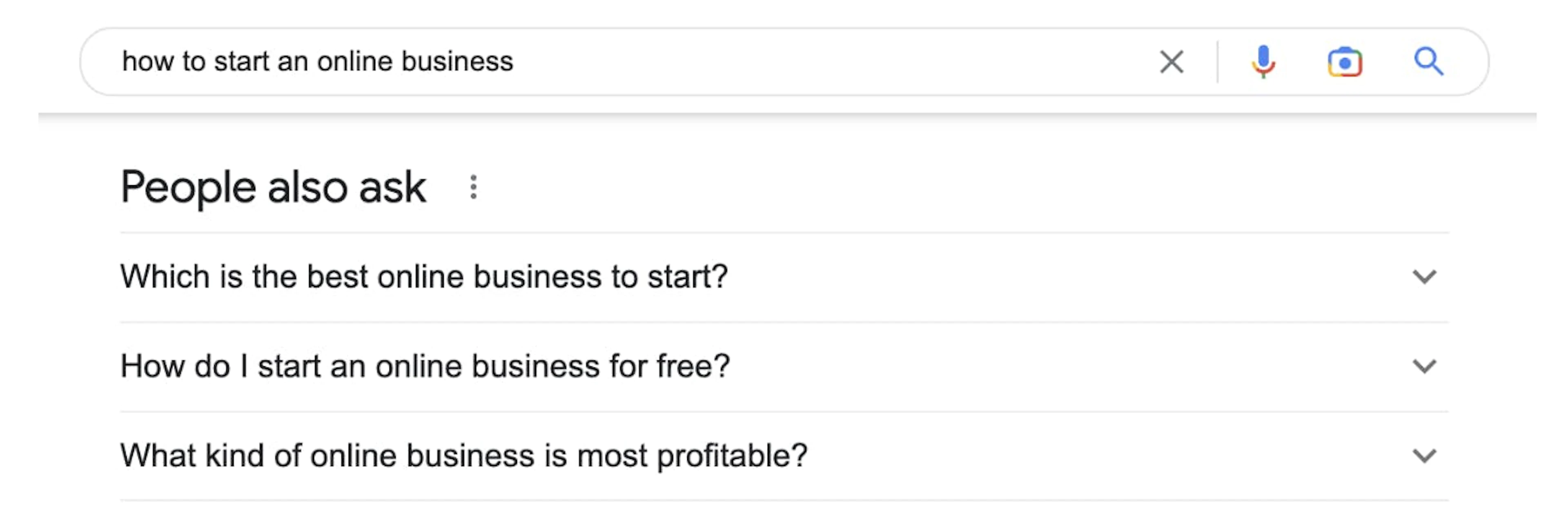
5. Local pack

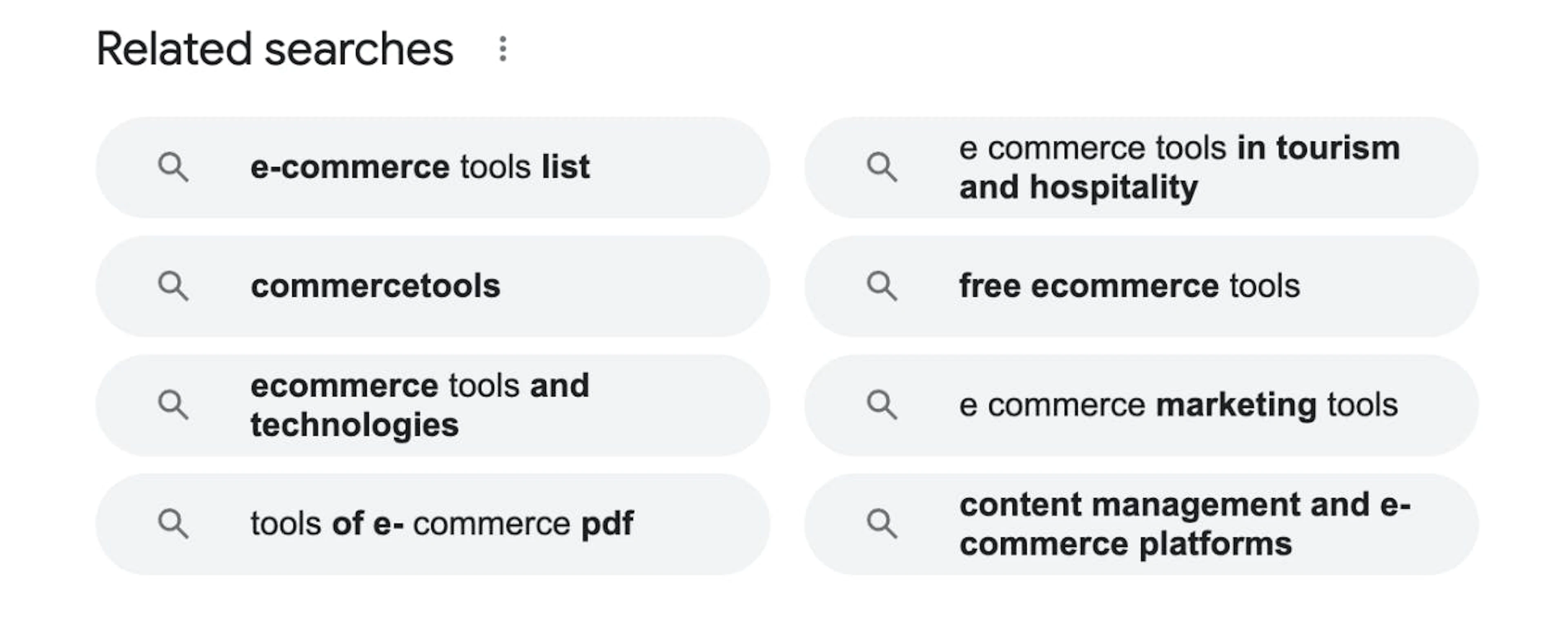
6. Related searches
Is it legal to scrape Google results?
The legality of scraping Google search data is largely discussed in the scraping field. As a matter of fact, scraping publicly available data on the internet – including Google SERP data – is legal. However, it may vary from one situation to another, so it's best to seek legal advice about your specific case.
Google search scraping: the difficulties
As said at the beginning of this article, web scraping Google search results data isn't easy. Google has implemented several techniques to prevent malicious bots from harvesting its data. Here's where the issues begin –since the difference between a malicious bot and a non-malicious one is obscure, the friendly one can get flagged, too. In other words, even if your Google search scraper isn't a threat and it gathers public data from a few pages a day, it may still get interrupted.
Let’s take a closer look at the difficulties of scraping public Google search results.
1. CAPTCHAs
Prompting CAPTCHAs is the way Google differentiates real users from bots. The tests are difficult for bots to do, but humans can complete them relatively easily. If the visitor cannot complete CAPTCHA after a few tries, it often results in IP interruption. Luckily, advanced and fast-adapting web scraping tools, such as our SERP Scraper API (part of the all-in-one Web Scraper API data collection solution), are highly effective at managing the entire extraction pipeline, including CAPTCHAs and stable access.
2. IP interruption
Whenever you do something online, your IP is visible to websites you visit. When you’re scraping Google SERP data (or data from any other website), your IP is also visible, allowing the website to stop you even when scraping isn't malicious.
3. Disorganized data
The whole point of data collection from Google is to analyze it and gain insights. For instance, with data from Google, you can build a solid search engine optimization strategy.
However, to analyze search results data, it has to be well-organized and easy to read. That said, your data-gathering tool should be able to return it in a structured format – JSON or CSV, for example.
Let's run a basic scraping request using Playwright to showcase the difficulties in action. First, install Playwright using pip install playwright and then execute the following code:
import asyncio
from playwright.async_api import async_playwright
query = 'hotels in New York City'
num = 50
url = f'https://www.google.com/search?q={query.replace(" ", "+")}&num={num}'
async def main():
async with async_playwright() as pw:
browser = await pw.chromium.launch(headless=True)
context = await browser.new_context()
page = await context.new_page()
await page.goto(url)
data = await page.content()
with open('google_page.html', 'w') as file:
file.write(data)
if __name__ == '__main__':
asyncio.run(main())If you open the saved HTML file in your browser, in most cases, you may see a CAPTCHA test rather than Google search results:
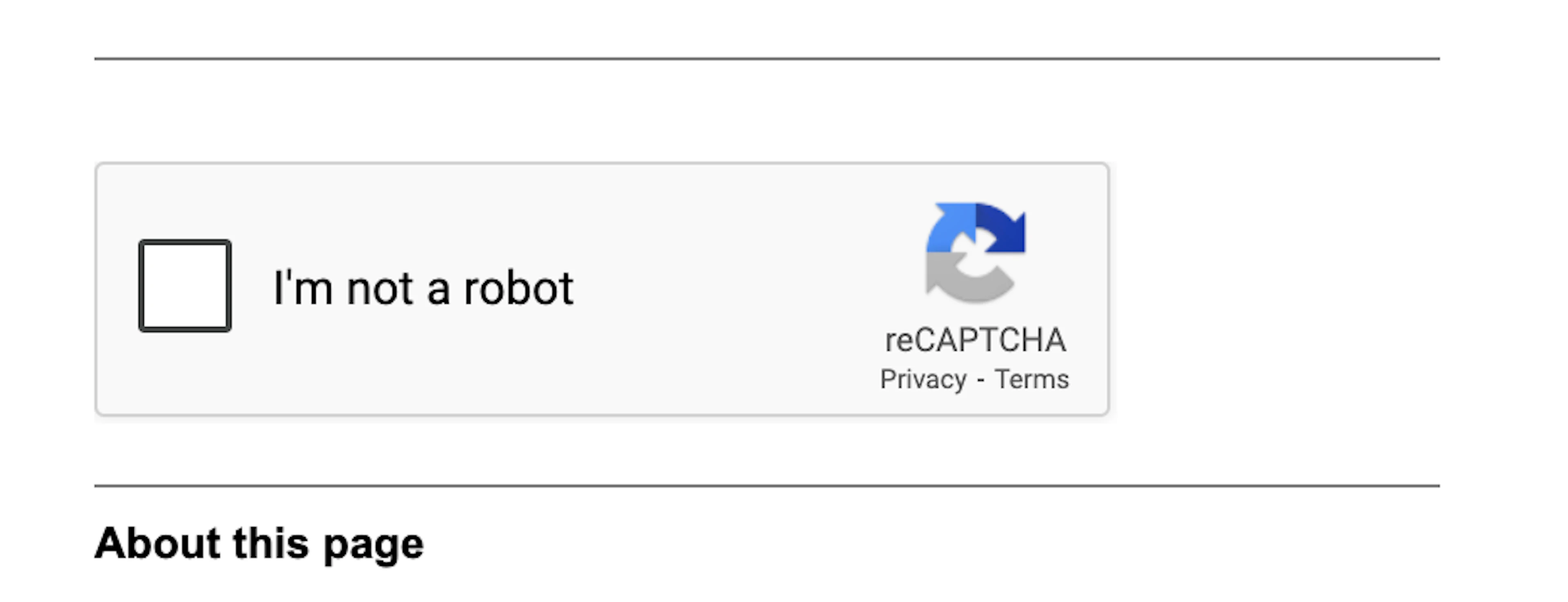
With these challenges in mind, you'll require an advanced Google scraping tool that can overcome them all. Oxylabs' Google Search API is constructed to overcome technical challenges and ensure reliable access to publicly-available web data. It smoothly delivers public Google search results without users having to take care of scraper maintenance.
In fact, it takes just a few steps to scrape Google search results with our SERP API– let’s take a closer look at that very process.
Scraping public Google search results with Python using our API
1. Install required Python libraries
To follow this guide on scraping Google search results, you’ll need the following:
Credentials for Oxylabs' SERP API
Python
Requests library
First, sign up for Oxylabs' Google Search Results API and save your username and password. Throughout this guide, you’ll see the username and password entities – these are the places where you’ll need to insert your own credentials.
Then, download and install Python 3.8 or above from the python.org website.
Finally, install the Request library, which is a popular third-party Python library for making HTTP requests. The Request library has a simple and intuitive interface for sending HTTP requests to web servers and receiving responses.
To install this library, use the following command:
$python3 -m pip install requests If you’re using Windows, choose Python instead of Python3. The rest of the command remains the same:
d:\amazon>python -m pip install requests2. Set up a payload and send a POST request
Create a new file and enter the following code:
import requests
from pprint import pprint
payload = {
'source': 'google',
'url': 'https://www.google.com/search?hl=en&q=newton' # search for newton
}
response = requests.request(
'POST',
'https://realtime.oxylabs.io/v1/queries',
auth=('USERNAME', 'PASSWORD'),
json=payload,
)
pprint(response.json())Here’s what the result should look like:
{
"results": [
{
"content": "<!doctype html><html>...</html>",
"created_at": "YYYY-DD-MM HH:MM:SS",
"updated_at": "YYYY-DD-MM HH:MM:SS",
"page": 1,
"url": "https://www.google.com/search?hl=en&q=newton",
"job_id": "1234567890123456789",
"status_code": 200
}
]
}Notice how the url in the payload dictionary is a Google search page. In this example, the keyword is newton.
As you can see, the query is executed and the page result in HTML is returned in the content key of the response.
Customizing query parameters
Let's review the payload dictionary from the above example for scraping Google search data.
payload = {
'source': 'google',
'url': 'https://www.google.com/search?hl=en&q=newton'
}The dictionary keys are parameters used to inform Google Scraper API about required customization.
The first parameter is the source, which is really important because it sets the scraper we’re going to use.
The default value is Google – when you use it, you can set the url as any Google search page, and all the other parameters will be extracted from the URL.
Although in this guide we’ll be using the google_search parameter, there are many others – google_ads, google_hotels, google_images, google_suggest, and more. To see the full parameter list, head to our documentation.
Keep in mind that if you set the source as google_search, you cannot use the url parameter. Luckily, you can use several different parameters for acquiring public Google SERP data without having to create multiple URLs. Let’s find out more about these parameters, shall we?
Basic scraper parameters
We’ll build the payload by adding the parameters one by one. First, begin with setting the source as google_search.
payload = {
'source': 'google_search',
}Now, let’s add query – a crucial parameter that determines what search results you’ll be retrieving. In our example, we’ll use newton as our search query. At this stage, the payload dictionary looks like this:
payload = {
'source': 'google_search',
'query': 'newton',
}That said, google_search and query are the two essential parameters for scraping public Google search data. If you want the API to return Google search results at this stage, you can use payload. Now, let’s move to the next parameter.
Location query parameters
To get results from a specific country, use the geo_location parameter. For example, to see results from Germany, set 'geo_location':'Germany'. See the documentation for the geo_location parameter to learn more about the correct values.
Also, here’s what changing the locale parameter looks like:
payload = {
'source':'google_search',
'query':'newton',
'geo_location': 'Germany',
'locale' : 'en-us'
}To learn more about the potential values of the locale parameter, check the documentation, as well.
If you send the above payload, you’ll receive search results in American English from google.de, just like anyone physically located in Germany would.
Controlling the number of results
By default, you’ll see the first ten results from the first page. If you want to customize this, you can use these parameters: start_page, pages, and limit.
The start_page parameter determines which page of search results to return. The pages parameter specifies the number of pages. Finally, the limit parameter sets the number of results on each page.
For example, the following set of parameters fetch results from pages 11 and 12 of the search engine results, with 20 results on each page:
payload = {
'start_page': 11,
'pages': 2,
'limit': 20,
... # other parameters
}Apart from the search parameters we’ve covered so far, there are a few more you can use to fine-tune your results – see our documentation on collecting public Google Search data.
Python code for scraping Google search data
Now, let’s put together everything we’ve learned so far – here’s what the final script with the shoes keyword looks like:
import requests
from pprint import pprint
payload = {
'source': 'google_search',
'query': 'shoes',
'geo_location': 'Germany',
'locale': 'en-us',
'parse': True,
'start_page': 1,
'pages': 5,
'limit': 10,
}
# Get response.
response = requests.request(
'POST',
'https://realtime.oxylabs.io/v1/queries',
auth=('USERNAME', 'PASSWORD'),
json=payload,
)
if response.status_code != 200:
print("Error - ", response.json())
exit(-1)
pprint(response.json())3. Export scraped data to a CSV
One of the best Google Scraper API features is the ability to parse an HTML page into JSON. For that, you don't need to use BeautifulSoup or any other library – just send the parse parameter as True.
Here is a sample payload:
payload = {
'source': 'google_search',
'query': 'adidas',
'parse': True,
}When sent to the Google Scraper API, this payload will return the results in JSON. To see a detailed JSON data structure, see our documentation.
The key highlights:
The results are in the dedicated results list. Here, each page gets a new entry.
Each result contains the content in a dictionary key named content.
The actual results are in the results key.
Note that there’s a job_id in the results.
The easiest way to save the data is by using the Pandas library, since it can normalize JSON quite effectively.
import pandas as pd
...
data = response.json()
df = pd.json_normalize(data['results'])
df.to_csv('export.csv', index=False)Alternatively, you can also take note of the job_id and send a GET request to the following URL, along with your credentials.
http://data.oxylabs.io/v1/queries/{job_id}/results/normalized?format=csvIn case you need multiple data formats, you can utilize the multi-format output feature to get all result types in a single API response. For example, the following will fetch parsed data, a screenshot of the page, and the raw HTML document:
https://data.oxylabs.io/v1/queries/{job_id}/results?type=parsed,png,rawFor production workloads, consider saving results to Cloud Storage (S3, GCS, etc.) in combination with the Result Aggregator feature. You'll be able to merge scraped data into larger aggregate files, streamlining storage management and data pipeline integration.
Handling errors and exceptions
When scraping Google, you can run into several challenges: network issues, invalid query parameters, or API quota limitations.
To handle these, you can use try-except blocks in your code. For example, if an error occurs when sending the API request, you can catch the exception and print an error message:
try:
response = requests.request(
'POST',
'https://realtime.oxylabs.io/v1/queries',
auth=('USERNAME', 'PASSWORD'),
json=payload,
)
except requests.exceptions.RequestException as e:
print("Error:", e)If you send an invalid parameter, Google Scraper API will return the 400 response code.
To catch these errors, check the status code:
if response.status_code != 200:
print("Error - ", response.json())Web Scraping Google search results with proxies
If you’d like to try scraping public Google search results without an API, you can use a headless browser like Playwright and Oxylabs’ Residential Proxies. Below is a simple code example you can use for your future project:
1. Prerequisites
Install required Python libraries:
pip install playwrightThen, set up your Oxylabs proxy credentials, which you can easily get by signing up and selecting a suitable plan through our self-service dashboard. Note that you'll have to contact our support team to enable proxy access to Google domains.
2. Making the request
Let’s now use the Playwright library and Oxylabs’ proxies to scrape the top 50 Google search results for "hotels in New York City":
import asyncio
from playwright.async_api import async_playwright
# Replace these with your Oxylabs proxy credentials.
USERNAME = 'PROXY_USERNAME'
PASSWORD = 'PROXY_PASSWORD'
# Define the search query and the number of total results.
query = 'hotels in New York City'
num = 50
url = f'https://www.google.com/search?q={query.replace(" ", "+")}&num={num}'
async def main():
async with async_playwright() as pw:
# Enable headless mode and proxies.
browser = await pw.chromium.launch(
headless=True,
proxy={
'server': 'https://pr.oxylabs.io:7777',
'username': f'customer-{USERNAME}',
'password': PASSWORD
}
)
# Create an isolated context and a new page.
context = await browser.new_context(ignore_https_errors=True)
page = await context.new_page()
# Send the request through a proxy.
await page.goto(
url,
wait_until='domcontentloaded',
timeout=60000
)
# Extract titles and links from each search result.
results = await page.query_selector_all('.tF2Cxc')
data = []
for result in results:
title_el = await result.query_selector('.DKV0Md')
title = await title_el.inner_text() if title_el else None
link_el = await result.query_selector('.yuRUbf a')
link = await link_el.get_attribute('href') if link_el else None
data.append({'title': title, 'link': link})
# Print the results.
for idx, d in enumerate(data, 1):
print(f'{idx}. {d["title"]}\n{d["link"]}\n')
await browser.close()
if __name__ == '__main__':
asyncio.run(main())This script will print the titles and links of the top 50 search results for the query.
3. Saving results to a file
If you'd like to save the scraped results to a file for further analysis or sharing, you can extend the script as follows:
import csv
# Save the results to a CSV file.
with open('google_results.csv', 'w', newline='') as file:
writer = csv.writer(file)
writer.writerow(['Title', 'Link']) # Header row.
for item in data:
writer.writerow([item['title'], item['link']])
print(f"Results saved.")If you'd like to try out Oxylabs' proxies before committing to a full subscription, we have free proxy servers available for use. Simply log in to the dashboard, select Datacenter Proxies, and you'll acquire 5 US IPs.
Scraping methods’ comparison
Google Search results scraper can be approached in various ways, each with its own set of advantages and challenges. However, it's important to mention that there's no right or wrong way to approach scraping Google search results. Everything depends on your or your business' needs and development resources.
| Method | Pros | Cons |
|---|---|---|
| Without proxies | Direct requests without additional configurations, no extra costs associated with proxies. | High risk of IP mismanagement, CAPTCHAs, limited scalability. |
| With proxies | Enhanced anonymity, access to geo-restricted content. | Additional costs, complexity in managing and rotating proxies, legal considerations. |
| Using an API | Simplified data extraction, built-in handling of IP bans and CAPTCHAs, scalable solutions. | Additional costs, dependency on third-party service reliability, potential limitations on specific data needs. |
| Other tools (e.g. Scrapy) | Full control over the scraping process, flexibility for customization, no recurring costs if self-managed. | Steep learning curve, manual handling of anti-scraping mechanisms, ongoing maintenance to adapt to website changes |
Conclusion
We hope this extensive guide on how to scrape Google search results with Python helps you get the data you need to get your operations going. If you're scraping at scale, using a proxy server can significantly improve your success rate. In case you run into any questions or uncertainties, don’t hesitate to reach out to our support team via email or live chat – our professional team will be happy to consult you about any matter related to scraping Google SERPs. If you're looking to enhance your scraping efforts, you can also buy a proxy server or use residential proxies to ensure a smoother experience.
Want to learn how to scrape data from Google’s services? See our Jobs, Scholar, Images, Trends, News, Flights, and AI Mode web scraping guides.
If you want to dive deeper into scraping techniques, we encourage you to learn more about the process and check out our article on how to scrape dynamic websites.
In case you're interested in scraping Google News articles hassle-free, check out Oxylabs' Google News API. Also, check out our blog post on how to find all website pages to learn more about Google Search capabilities.
Frequently asked questions
Is scraping Google allowed?
Google search results are considered publicly available data, so scraping them is allowed. However, there are some types of data you cannot scrape (i.e., personal information, copyrighted content) so it’s best if you consult a legal professional beforehand.
How to crawl google search results?
Can I scrape Google Events results?
Can I scrape Google Local results?
Can I scrape the "About this result" sections?
Can I scrape Google Video results?
What are the main ways to scrape Google search pages?
About the author

Dovydas Vėsa
Technical Content Researcher
Dovydas Vėsa is a Technical Content Researcher at Oxylabs. He creates in-depth technical content and tutorials for web scraping and data collection solutions, drawing from a background in journalism, cybersecurity, and a lifelong passion for tech, gaming, and all kinds of creative projects.
All information on Oxylabs Blog is provided on an "as is" basis and for informational purposes only. We make no representation and disclaim all liability with respect to your use of any information contained on Oxylabs Blog or any third-party websites that may be linked therein. Before engaging in scraping activities of any kind you should consult your legal advisors and carefully read the particular website's terms of service or receive a scraping license.
Related articles

Cheerio vs. Puppeteer: Which Should You Use for Web Scraping?

Shinthiya Nowsain Promi
2026-06-23



List Crawling in Python: Tools, Tips, and Techniques

Danielė Virinaitė
2026-06-17
Try Google Search Scraper API
Choose Oxylabs' Google Search Scraper API to unlock real-time search data hassle-free.
Try Free Proxies
Discover the benefits of using Oxylabs' high-quality services with free proxies.

Get the latest news from data gathering world
Scale up your business with Oxylabs®
Proxies
Advanced proxy solutions
Data Collection
Datasets
Resources
Innovation hub
Try Google Search Scraper API
Choose Oxylabs' Google Search Scraper API to unlock real-time search data hassle-free.
Try Free Proxies
Discover the benefits of using Oxylabs' high-quality services with free proxies.