175M+ ethically sourced IPs built for the highest reliability.
High-speed, cost-effective proxies built for any scraping workload.
Premium static residential proxies from trusted ASNs for most difficult targets.
Dedicated IPs from premium ASNs for demanding scraping.

AI-powered proxy solution for optimized web scraping performance.

20M+ IP addresses from real mobile devices for precise targeting.

Free Chrome proxy manager extension that works with any proxy provider.

Free Android proxy manager app that works with any proxy provider.

Free community-driven tools to improve your web scraping projects.
Web Scraper API
All-in-one web data collection platform for every stage of web scraping.
Fast Search API
Ultra-fast organic search results scraper tailored for AI workflows.
Headless Browser
Advanced browser automation solution for AI agents and scraping.
AI Studio
A suite of AI-powered tools for various scraping projects.

Documentation
All features, parameters, and integration details, backed by code samples in every coding language.
Tutorials, samples, and guides.
Latest fixes and features.






In this tutorial, you’ll learn how to fetch Yellow Pages using Python. Yellow pages typically contain valuable business details such as their address, ratings, services offered, business email, phone numbers, etc. In today's data-driven world, acquiring such information from diverse sources, often with the help of a free proxy server or any other proxy solution, is crucial for every business. It provides insights for market analysis, competitor profiling, lead generation, and more. So, let’s get started.
Claim your free trial
Request a free trial to test our Web Scraper API.
Up to 2K results
No credit card required
Project setup
First, you’ll need to install Python. Please visit the official website and download the latest release from here.
1. Install dependencies
Now that you’ve installed Python, you can use the pip command to install the necessary libraries and their dependencies using the below command.
pip install requests bs4The above command will install two libraries: requests & Beautiful Soup.
2. Import libraries
Once installed, you can import those libraries by typing the following code in your favorite code editor.
from bs4 import BeautifulSoup
import requests3. Get Scraper API credentials
To improve Yellow Pages access reliability, you can use Oxylabs’ Web Scraper API. It’s a powerful AI-driven tool that can handle proxy rotation and management. It also has various useful features, such as browser parameter configuration and JavaScript rendering.
Once you sign up and create an Oxylabs account, you’ll get the sub-account credentials. Take note of the username and password, you’ll use them in the next step.
4. Fetch the Yellow Page using the API
Next, you’ll fetch a Yellow page using the Web Scraper API. You’ll have to send a POST request to the Scraper API with a payload and credential.
url = "https://www.yellowpages.ca/bus/Ontario/North-York/The-Burger-Cellar/6835043.html"
payload = {
'source': 'universal',
'render': 'html',
'url': url,
}
credential = ('USERNAME', 'PASSWORD')
response = requests.post(
'https://realtime.oxylabs.io/v1/queries',
auth=credential,
json=payload,
)
print(response.status_code)To scrape Yellow Pages, the source must be set to universal. The render parameter tells the API to execute JavaScript while rendering the HTML content. Don’t forget to replace USERNAME and PASSWORD with your credentials; otherwise, you’ll get authentication errors from the API. If everything works as expected, you’ll get a status_code of 200 when you run the code.
5. Parse the Yellow Pages content
Now, from the response object, you can extract the HTML content of the web page. Scraper API returns a JSON response that contains the HTML content, so you can take advantage of the json() method.
content = response.json()["results"][0]["content"]
soup = BeautifulSoup(content, "html.parser")The soup object will have the parsed HTML content from which you can extract the Yellow Page data using CSS Selectors.
Extract business info
The easiest way to find the CSS Selectors of the element is to use the Developer tool of a web browser. In this tutorial, we’re using Google Chrome web browser, but Firefox and other web browsers also have similar tools available. All you need to do is open the target URL in your browser, right-click on the page, and select inspect. Alternatively, you can press the keyboard shortcut CTRL + SHIFT + I.
6. Extract business name
Now, if you inspect the source code and locate the name element, you’ll notice the business name is wrapped in a span tag.
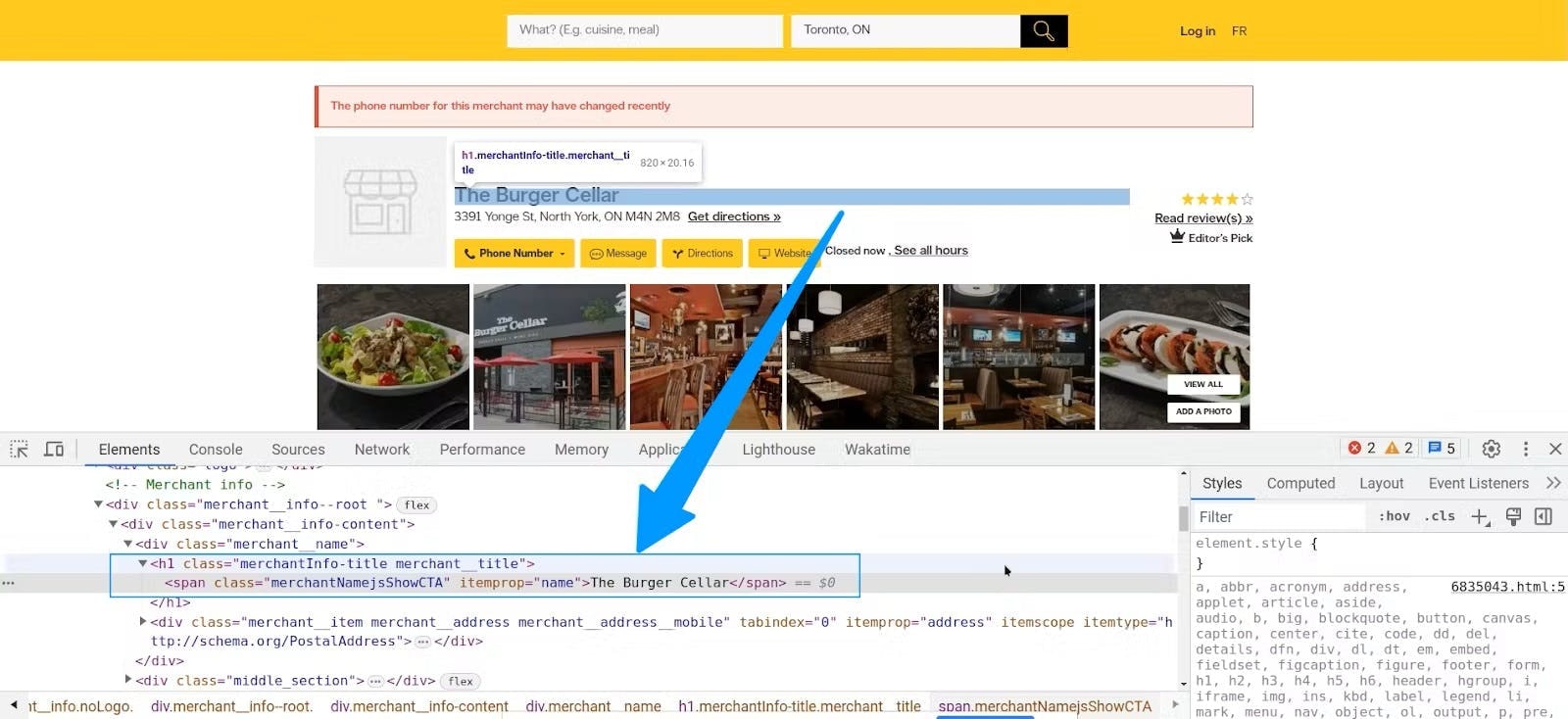
As you can see, this <span> element has an attribute itemprop set to name. You can use this attribute to locate the element using the find() method as below.
name = soup.find('span', {'itemprop': 'name'}).get_text(strip=True)
print(name)7. Scrape business address
Next, let’s inspect the address element by finding the <div> element that wraps the address. Inside this <div> element, you’ll find several <span> tags.
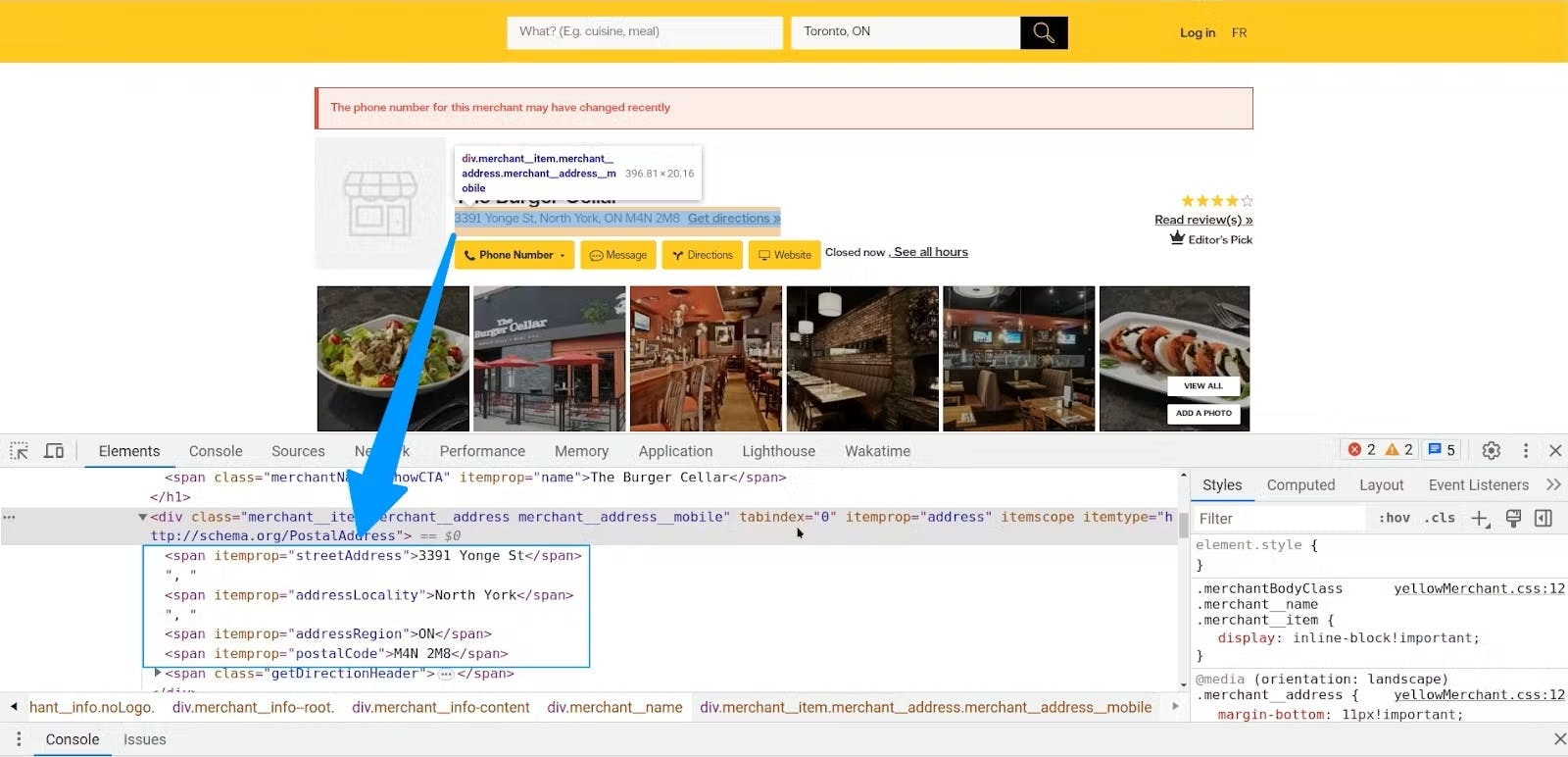
Since the address is split into chunks of <span> elements, you can use a for loop to extract the text of each of these <span> elements. And then, use the join() method to reconstruct the address string as below.
itemprops = ["streetAddress", "addressLocality", "addressRegion", "postalCode"]
address_text = []
for itemprop in itemprops:
address_text.append(soup.find('span', {'itemprop': itemprop}).get_text(strip=True))
address = ', '.join(text for text in address_text if text)
print(address)8. Scrape phone information
Similarly, you can find the phone element, which is also a span tag with itemprop set to telephone.
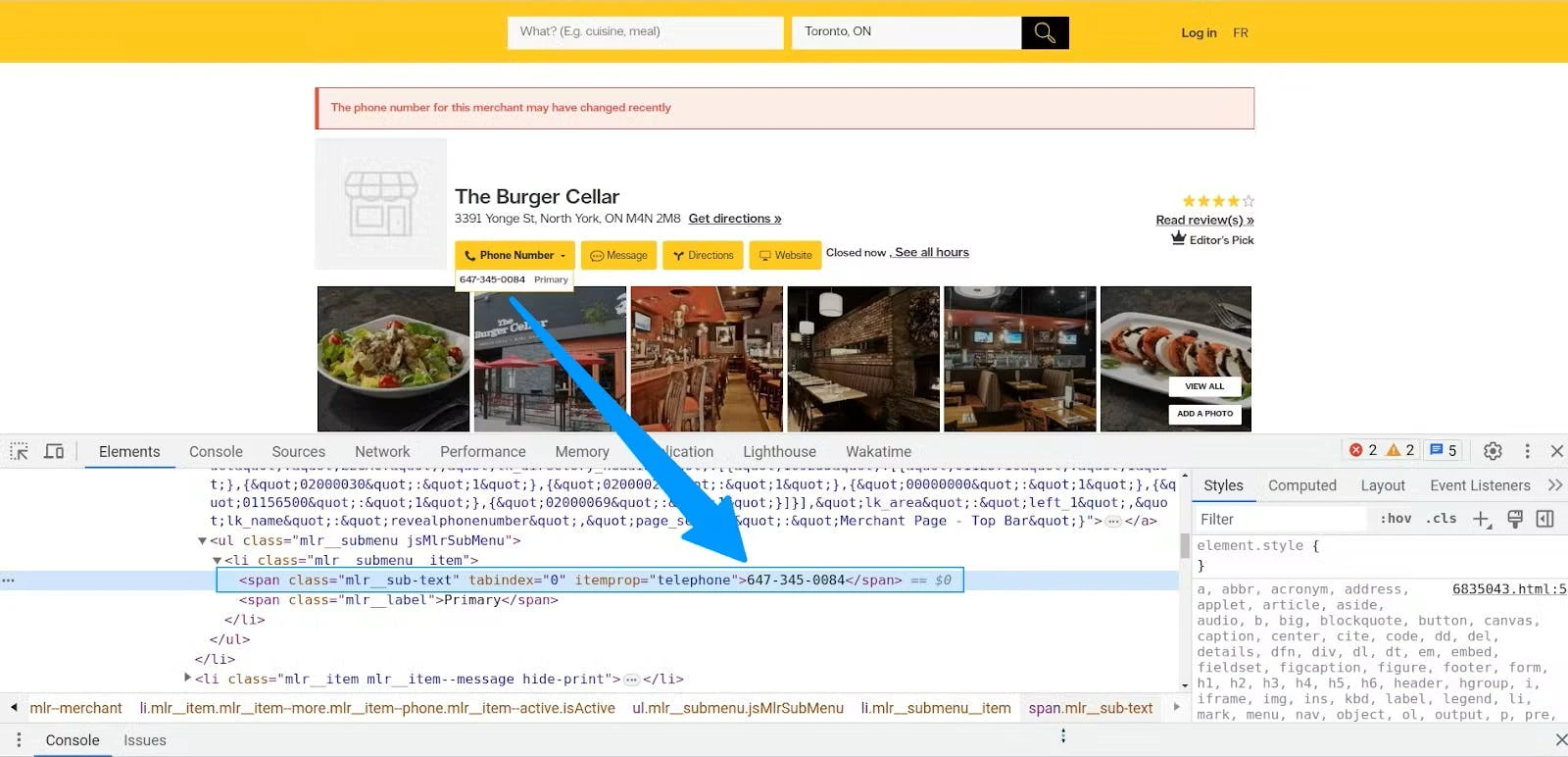
The code to extract phone numbers is similar to the code for extracting business names.
phone = soup.find('span', {'itemprop': 'telephone'}).get_text(strip=True)
print(phone)9. Retrieve ratings
Last but not least, inspect the ratings element. Notice that all the stars are wrapped in a <span> element.
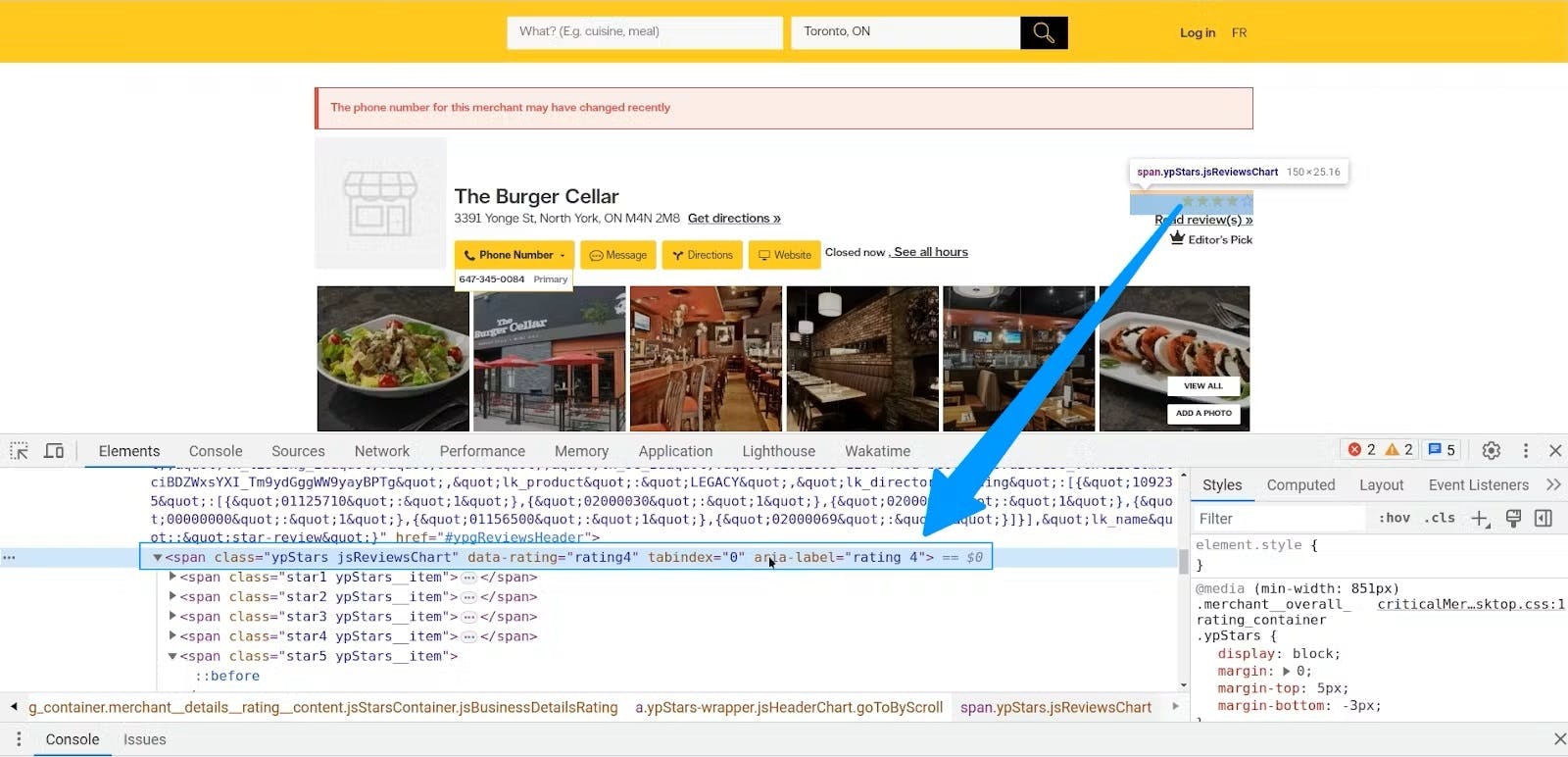
This span element doesn’t have the attribute itemprop, so you can use the class jsReviewsChart as CSS Selector instead.
ratings = soup.find('span', {'class': 'jsReviewsChart'})['aria-label']
print(ratings)And that’s it! You’ve successfully extracted this business's names, phone numbers, ratings, and addresses. If you want to extract other elements, you can inspect those elements to find the appropriate CSS selectors and modify the source code accordingly.
Conclusion
In conclusion, you’ve learned how to extract information from the Yellow Pages with Python using Oxylabs’ Yellow Pages Scraper API. The API made the whole process smooth and hassle-free with automated request and proxy management, as well as JavaScript rendering, so that you can focus on the necessary business data instead of dealing with scraping hurdles. If you're looking to scale your operations, you can buy proxy solutions to further enhance your scraping capabilities. You can also use this API and these techniques to optimize access to other complex websites and extract data.
Frequently asked questions
Can you scrape Yellow Pages?
Yes, absolutely. It’s possible to scrape data from Yellow Pages and collect business information. The Yellow Pages website is a directory of business contact details. You're not breaking any laws by scraping Yellow Pages data as it’s considered publicly available information. However, our legal team strongly recommends consulting a legal professional before being involved in any scraping activity.
How do I extract data from Yellow Pages to Excel?
How do you scrape Yellow Pages in Python?
About the author

Maryia Stsiopkina
Former Senior Content Manager
Maryia Stsiopkina was a Senior Content Manager at Oxylabs. As her passion for writing was developing, she was writing either creepy detective stories or fairy tales at different points in time. Eventually, she found herself in the tech wonderland with numerous hidden corners to explore. At leisure, she does birdwatching with binoculars (some people mistake it for stalking), makes flower jewelry, and eats pickles.
All information on Oxylabs Blog is provided on an "as is" basis and for informational purposes only. We make no representation and disclaim all liability with respect to your use of any information contained on Oxylabs Blog or any third-party websites that may be linked therein. Before engaging in scraping activities of any kind you should consult your legal advisors and carefully read the particular website's terms of service or receive a scraping license.
Related articles

Cheerio vs. Puppeteer: Which Should You Use for Web Scraping?

Shinthiya Nowsain Promi
2026-06-23



List Crawling in Python: Tools, Tips, and Techniques

Danielė Virinaitė
2026-06-17
Try Yellow Pages Scraper API
Choose Oxylabs' Yellow Pages Scraper API to unlock real-time product data hassle-free.

Get the latest news from data gathering world
Scale up your business with Oxylabs®
Proxies
Advanced proxy solutions
Data Collection
Datasets
Resources
Innovation hub
Try Yellow Pages Scraper API
Choose Oxylabs' Yellow Pages Scraper API to unlock real-time product data hassle-free.