175M+ ethically sourced IPs built for the highest reliability.
High-speed, cost-effective proxies built for any scraping workload.
Premium static residential proxies from trusted ASNs for most difficult targets.
Dedicated IPs from premium ASNs for demanding scraping.

AI-powered proxy solution for optimized web scraping performance.

20M+ IP addresses from real mobile devices for precise targeting.

Free Chrome proxy manager extension that works with any proxy provider.

Free Android proxy manager app that works with any proxy provider.

Free community-driven tools to improve your web scraping projects.
Web Scraper API
All-in-one web data collection platform for every stage of web scraping.
Fast Search API
Ultra-fast organic search results scraper tailored for AI workflows.
Headless Browser
Advanced browser automation solution for AI agents and scraping.
AI Studio
A suite of AI-powered tools for various scraping projects.

Documentation
All features, parameters, and integration details, backed by code samples in every coding language.
Tutorials, samples, and guides.
Latest fixes and features.





Optimizing Dynamic Pricing for E-commerce


Adomas Sulcas
Last updated on
2020-04-21
5 min read
![]() AI Summary:
AI Summary:
Dynamic pricing relies on real-time data acquisition to monitor market fluctuations or competitor behavior. This article presents the four-step data collection process, the role of residential proxies if a site uses anti-bot systems, and how to manage the scraping pipeline for scalability. It also compares in-house scrapers with dedicated tools like Web Scraper API and AI Studio AI-Scraper for structured JSON data collection.
Pricing intelligence is the process of acquiring and processing data in order to optimize pricing strategies and drive growth in profits. It is quickly becoming a critical part of any consumer-facing business as dynamic pricing is an increasingly important process in most sectors. While dynamic pricing is just one way to implement strategies developed using pricing intelligence, it is the most common one.
Free PDF
Guide to Dynamic Pricing and Data Acquisition for E-Commerce Businesses

Dynamic pricing requires companies to track many external and internal factors related to the valuation of a product or service. Internal factors include:
Stock
Production costs
Shipping costs
Meanwhile, external aspects are harder to track as they might vary due to time (seasonal weather changes, holidays, etc.), consumer behavior (such as trends and brand loyalty), competition and many other factors. Yet, most of all, efficient dynamic pricing requires an accurate and effective process of data crawling and parsing.

Dynamic pricing in a few simple steps
Acquiring accurate data can be challenging due to the constantly changing nature of consumer information. Data extraction can be divided into several different processes that allow for the continuous scanning and scraping of the Internet. These processes are:
Building a scraping path
Creating data extraction scripts
Proxy management
Data storage
Data parsing
Each of these steps brings their own challenges, although, implementing a pricing data extraction process isn’t difficult in itself. Issues often arise whenever websites start to employ measures against data scraping.
Implementing the pricing data extraction process
In order to apply dynamic pricing, accurate and real-time data is required. Implementing a pricing data extraction process is one of the few ways to continuously acquire such data as only fresh information can be used for dynamic pricing strategies.
Data Acquisition

Data acquisition is an umbrella term for a 4-step process:
Developing data extraction scripts and implementing them
Using (headless) browsers and their automation
Data parsing
Data storage

Developing data acquisition tools is a critical part of dynamic pricing strategies
Building a pricing data acquisition tool is generally not too difficult for teams with dedicated and experienced developers. Nowadays at least several languages have easily accessible libraries that make building data extraction scripts and parsing acquired information significantly easier. Additionally, open source tools (e.g. Beautiful Soup) can serve as good starting grounds for some projects.
On the other hand, maintaining a constant flow of pricing data is challenging. Most website owners aren’t too keen to give large swaths of data to anyone with a Python script. As such, most data extraction targets (especially ones that are critical to pricing intelligence) have built algorithms to detect bot-like activity.
Handling bot traffic managing algorithms relies on two key factors – understanding how websites detect bot activity and consistently rotating IP addresses through proxies.
Avoiding flagged IPs

Dynamic pricing strategies require continuous access to data sources
There are two ways to consistently scrape the web for pricing intelligence – using residential proxies or using a web scraping solution such as E-commerce Scraper API (part of Web Scraper API).
Residential proxies allow web scrapers to acquire IP addresses of physical devices which makes data access significantly easier. These proxies need to be consistently changed in order to not play into algorithms looking for bots. Exact details on IP change frequency, work volume etc will depend on the scraping target.
Efficient web scraping requires not only a large pool of residential proxies in the world but also a large degree of customization:
Backconnect entries
City and country-level targeting
Session control
Sticky ports.
Managing proxies without a dedicated developer team is a daunting task, therefore many Oxylabs clients choose to outsource their data acquisition pipeline. After all, it is often significantly more time and cost efficient. Our data collection tool is created for those looking to focus mainly on data analysis and developing dynamic pricing strategies.
Out-of-the-box solutions like Web Scraper API bring many benefits to those looking for a reliable way to extract data. Proxy management, data extraction script development and other resource-intensive tasks are done on the side of the provider, allowing companies to focus making use of the data.
Additionally, tools like Web Scraper API can extract data from challenging targets without the requiring increased resource allocation. Scraping large e-commerce websites or some search engines can require additional development time as these targets often create sophisticated bot traffic control algorithms. In-house solutions would have to create solutions through trial and error which means inevitable slowdowns, ineffective IP addresses and an unreliable flow of pricing data.
Tools like Web Scraper API make data acquisition easy because:
High data acquisition success rate
Implementing Web Scraper API into any project is easy
Highly scalable and customizable
Receive fully parsed data (in JSON format)
Accurate geo-location based pricing data
Updates are managed on our side
Oxylabs’ Web Scraper API strength lies in its ability to be tailored to almost any business case. The API can easily scrape the largest e-commerce and search engine targets without any hiccups. It can be easily implemented in place of proxies (through Proxy Endpoint) if a scraping solution has already been built.
Web Scraper API in detail
Our Web Scraper API is an out-of-the-box solution for businesses looking to cut through the development process and move straight to data analysis. It is well suited for scraping and acquiring data from search engines and large e-commerce websites.
There are two ways to receive parsed data from our Web Scraper API tool – Callback or Realtime. Callback allows for both single and batch queries to be sent. Larger queries might take some time and their job status can be checked by sending a GET request. For some tasks (if a callback url is provided) we will send you a message automatically once the task has been completed.
On the other hand, the Realtime option is exactly what it says on the tin – we send you the data on an open connection (timeouts are 100 seconds). Ensure that timeout times align as sending data over might take some time.
By default, all Web Scraper API’s results are stored in our databases which means extra queries. This setting can easily be changed by providing your own cloud storage.
Web Scraper API is an exceptional tool for pricing intelligence as it covers the entire data acquisition and parsing pipeline with 24/7 system monitoring. Resources can be heavily geared towards providing dynamic pricing solutions to clients.
Oxylabs’ Web Scraper API saves costs in two ways – by reducing the price of data acquisition and by cutting down on internal spending.
Both residential proxies and Web Scraper API work great for data acquisition:
| Residential proxies | Web Scraper API |
| Flexible | Requires no infrastructure |
| More control over development | Predictable pricing |
| Can be utilized in other tasks | High data delivery success rate |
| Pay for traffic | Accurate data |
| Advanced configuration control | Pay for requests only |
| Inbuilt JavaScript rendering | |
| No extra scaling costs |
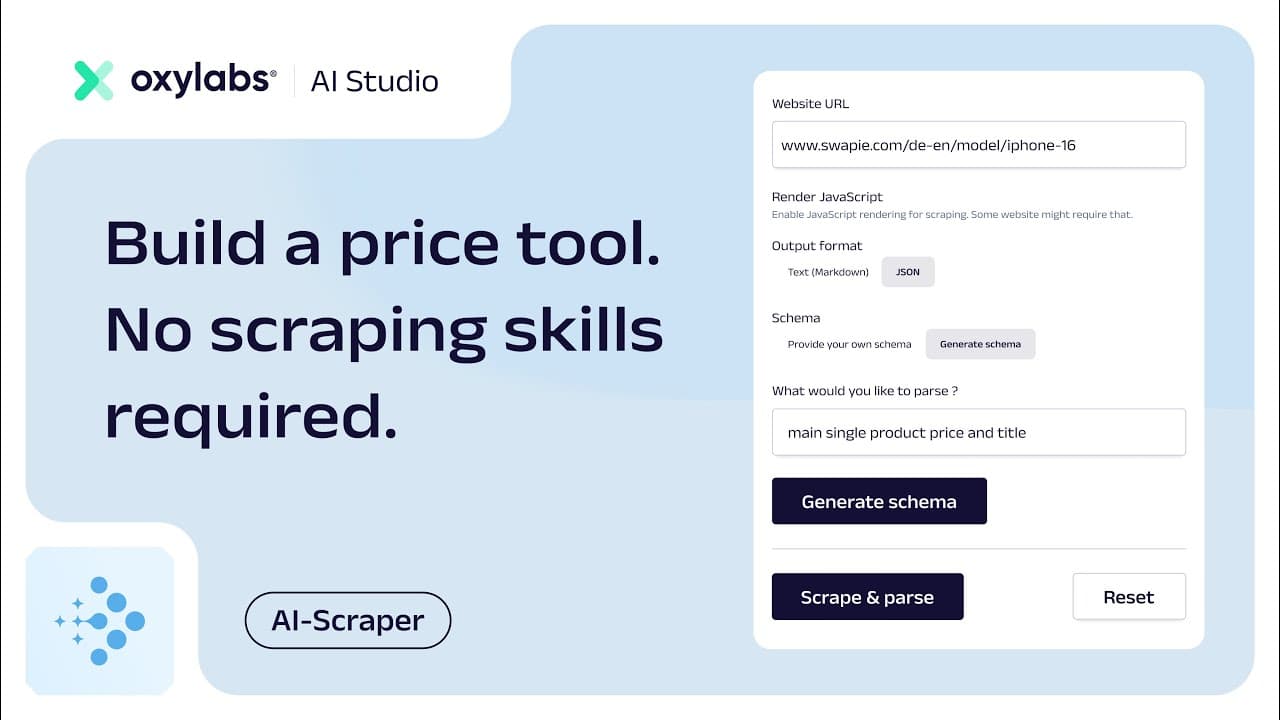
Build a price comparison tool with AI Studio's AI-Scraper
If you're looking for a fast and easy way to build a price comparison, this short demo will show you how smoothly it can be done with Oxylabs’ AI Studio. AI-Scraper takes care of both the scraping and parsing processes, so you don’t have to worry about bot traffic control systems, writing custom parsing logic for each domain or accessing even difficult sites.
In the video, you’ll learn how to build a simple iPhone 16 price comparison tool by using the app’s user interface and by implementing it with the Python SDK.
Conclusion
Both options have their own benefits and drawbacks, though, many of our clients choose to use our Web Scraper API as it allows them to cut down on data extraction costs. Web Scraper API makes pricing intelligence almost effortless due to ease-of-use, simple implementation and almost infinite scalability. If you are looking for more efficient ways to extract data from large e-commerce websites and search engines, Web Scraper API will be the game changer you need.
Ready to get started? Sign up and test out our solutions with a free 1-week trial by clicking here! Still having some doubts which option is better? Need more technical details before a decision can be made? Contact our sales department by clicking "Contact sales" at the top-left corner and filling out a form.
People also ask
What if I encounter IP blocks even despite using proxies?
If the IPs you're using can't access the site even with proxies, most probably it means that the site you're trying to reach employs an advanced system that's very effective at noticing bots. To access it successfully, you might need a smart AI-powered proxy solution like Web Unblocker.
Forget about complex web scraping processes
Choose Oxylabs' advanced web intelligence collection solutions to gather real-time public data hassle-free.
About the author
Adomas Sulcas
Former PR Team Lead
Adomas Sulcas was a PR Team Lead at Oxylabs. Having grown up in a tech-minded household, he quickly developed an interest in everything IT and Internet related. When he is not nerding out online or immersed in reading, you will find him on an adventure or coming up with wicked business ideas.
All information on Oxylabs Blog is provided on an "as is" basis and for informational purposes only. We make no representation and disclaim all liability with respect to your use of any information contained on Oxylabs Blog or any third-party websites that may be linked therein. Before engaging in scraping activities of any kind you should consult your legal advisors and carefully read the particular website's terms of service or receive a scraping license.
Related articles



List Crawling in Python: Tools, Tips, and Techniques

Danielė Virinaitė
2026-06-17

Top 7 Web Price Scraping Software and Tools for 2026

Shinthiya Nowsain Promi
2026-06-11

Get the latest news from data gathering world
Scale up your business with Oxylabs®
Proxies
Advanced proxy solutions
Data Collection
Datasets
Resources
Innovation hub
Forget about complex web scraping processes
Choose Oxylabs' advanced web intelligence collection solutions to gather real-time public data hassle-free.