175M+ ethically sourced IPs built for the highest reliability.
High-speed, cost-effective proxies built for any scraping workload.
Premium static residential proxies from trusted ASNs for most difficult targets.
Dedicated IPs from premium ASNs for demanding scraping.

AI-powered proxy solution for optimized web scraping performance.

20M+ IP addresses from real mobile devices for precise targeting.

Free Chrome proxy manager extension that works with any proxy provider.

Free Android proxy manager app that works with any proxy provider.

Free community-driven tools to improve your web scraping projects.
Web Scraper API
All-in-one web data collection platform for every stage of web scraping.
Fast Search API
Ultra-fast organic search results scraper tailored for AI workflows.
Headless Browser
Advanced browser automation solution for AI agents and scraping.
AI Studio
A suite of AI-powered tools for various scraping projects.

Documentation
All features, parameters, and integration details, backed by code samples in every coding language.
Tutorials, samples, and guides.
Latest fixes and features.





How to Get a Web Element from HTML Source With Selenium


Augustas Pelakauskas
Last updated on
2025-03-20
3 min read
![]() AI Summary:
AI Summary:
A Python tutorial on pulling a web element's HTML with Selenium. Starts by explaining what HTML source and web elements are, then walks through setup: installing Selenium and a WebDriver, adding authenticated proxies via Selenium Wire, and locating elements by ID, CSS, XPath, or tag name. Shows how `get_attribute('outerHTML')` and innerHTML differ, with full code examples in both Python and Java.
HTML source code is the blueprint of every website, and web elements are its building blocks. Python is arguably the most convenient programming language for extracting web data (web scraping) embedded within HTML code.
To enhance basic Python web scraping further, various frameworks, such as Playwright, Puppeteer, and Selenium, are often used to handle some of the more complex web browsing tasks, including JavaScript rendering.
Let’s overview the basics of getting web elements from HTML sources using Selenium web scraping with Python.
What is HTML source and web element?
HTML source
HTML source is the raw HTML code that makes up a web page. Web browsers interpret HTML code to display websites' content, structure, and formatting.
The HTML source includes:
HTML tags like <div>, <p>, <a>.
Text content that appears on the page.
Attributes within tags that provide additional information.
References to external resources like CSS files, JavaScript files, and images.
Metadata about the document in the <head> section.
You can view the HTML source of any web page by right-clicking on it and selecting View page source in your browser. Web developers work directly with HTML source code to create and modify websites.

HTML source for oxylabs.io
Web element
A web element is any HTML tag or part of a web page you can interact with – anything you find on a web page is a web element.
Some common web elements include:
Clickable buttons
Fillable Text fields
Links that navigate to other pages
Images that display visual content
Dropdown menus
Navigation bars
Headers and footers
Sliders and carousels
Windows and popups
Web elements are defined using HTML code (for structure), styled with CSS (for appearance), and can be manipulated with JavaScript (for behavior). Identifying and working with these HTML elements is essential for creating interactive and functional websites in web development and testing.
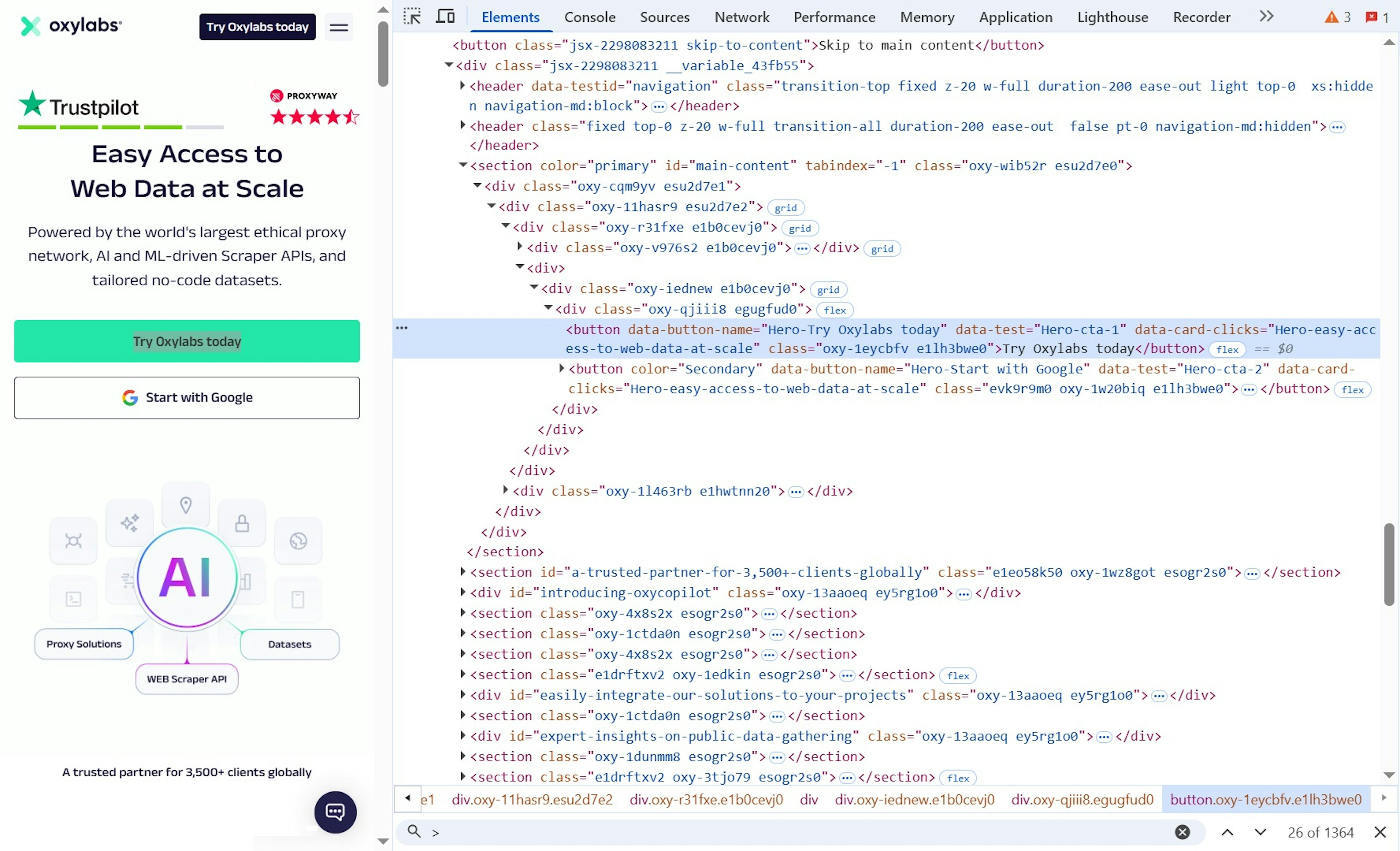
An HTML web element for a button
Tutorial on how to retrieve a web element from an HTML source using Python
Prerequisites
Python 3.6 or higher
Selenium package
Selenium Wire package for proxies
Selenium WebDriver for your preferred browser
1. Installation
Install Selenium:
pip install selenium selenium-wireDownload the appropriate Selenium WebDriver for your browser:
Chrome: ChromeDriver
Firefox: GeckoDriver
Edge: EdgeDriver
Let’s use ChromeDriver.
2. Proxy integration
Let's integrate proxies with Selenium to conceal your actual IP address and manage CAPTCHA. Proxies enable you to spread HTTP requests across multiple proxy IPs, enhancing web scraping efficiency. They also allow you to access content that is restricted to specific regions.
As a rule, the best proxy providers are always paid services. Luckily, they tend to offer free proxies for testing purposes.
While Selenium enables proxies through the --proxy-server= parameter, it doesn't allow proxy authentication. For this reason, use Selenium Wire, an unofficial third-party package that extends Selenium's Python bindings and enables you to use authenticated proxies.
Let’s set up a Selenium WebDriver to use a proxy server and add Oxylabs Residential Proxies.
3. Web element retrieval
To find an element using Selenium and Python, use the get_attribute('outerHTML') or get_attribute('innerHTML') method.
The difference between outerHTML and innerHTML:
outerHTML includes the element itself and all its content
innerHTML includes only the content inside the element
Remember that the choice between outerHTML and innerHTML depends on your specific needs – whether you need the complete element with its tags or just the content within.
Similarly, various locators offer flexibility in targeting elements on a page:
ID
CSS selector
XPath
tag name
You can use different locators to find an element:
# Find by CSS selector
element = driver.find_element(By.CSS_SELECTOR, ".my-class")
# Find by XPath
element = driver.find_element(By.XPATH, "//div[@class='my-class']")
# Find by tag name
element = driver.find_element(By.TAG_NAME, "div")Here's how to do it:
from seleniumwire import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.service import Service
# Proxy details
USER = "PROXY_USERNAME"
PASS = "PROXY_PASSWORD"
SERVER = "pr.oxylabs.io:7777"
# Create a driver with the proxy dict
driver = webdriver.Chrome(
seleniumwire_options={
"proxy": {
"http": f"http://customer-{USER}:{PASS}@{SERVER}",
"https": f"https://customer-{USER}:{PASS}@{SERVER}",
}
}
)
# Send a web request to a specific URL
driver.get("https://example.com")
# Find the element ID you want to get the HTML from
element = driver.find_element(By.ID, "my-element-id") # or use other locators
# Get the outer HTML (including the element itself)
outer_html = element.get_attribute('outerHTML')
print("Outer HTML:", outer_html)
# Get the inner HTML (only the content inside the element)
inner_html = element.get_attribute('innerHTML')
print("Inner HTML:", inner_html)
# Close the driver
driver.quit()NOTE: Using hardcoded credentials in the script is generally not recommended for security reasons.
Proxies for web scraping
Get free proxies for small tasks or buy proxies for large-scale web data collection.
5 IPs for FREE
No credit card required
Avg. 99.82% success rate
Using other languages
Here’s the basic process of getting an HTML source using Java.
Initialize ChromeDriver
Navigate to the target page
Find an element with the ID my-element-id
Retrieve the outerHTML attribute
Retrieve the innerHTML attribute
Print both to the console
Close the WebDriver
import org.openqa.selenium.By;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.WebElement;
import org.openqa.selenium.chrome.ChromeDriver;
public class WebElementHtmlRetrieval {
public static void main(String[] args) {
// Initialize the WebDriver
WebDriver driver = new ChromeDriver();
driver.get("https://example.com");
// Find the element ID
WebElement element = driver.findElement(By.id("element-id"));
// Get the outer HTML
String outerHtml = element.getAttribute("outerHTML");
System.out.println("Outer HTML: " + outerHtml);
// Get the inner HTML
String innerHtml = element.getAttribute("innerHTML");
System.out.println("Inner HTML: " + innerHtml);
// Close the driver
driver.quit();
}
}Using different locators
// Find by CSS selector
WebElement elementByCSS = driver.findElement(By.cssSelector(".my-class"));
// Find by XPath
WebElement elementByXPath = driver.findElement(By.xpath("//div[@class='my-class']"));
// Find by tag name
WebElement elementByTag = driver.findElement(By.tagName("div"));Wrap up
Whether you're building a web scraper, developing automated tests, or analyzing web content programmatically, understanding how to extract web elements from an HTML source is a fundamental skill.
Selenium provides methods like get_attribute('outerHTML') and get_attribute('innerHTML') that give you precise control over an HTML source you retrieve.
Alternatively, check competing web data extraction frameworks. See how they compare to Selenium:
Frequently asked questions
How to use Selenium to get HTML (Selenium get HTML)?
The Selenium get HTML process typically involves instantiating a Selenium WebDriver object, navigating to the target URL, and extracting the page_source attribute containing the fully rendered HTML source structure.
How to get XPath from an HTML file?
How to get the content of an entire page using Selenium?
How to get text from a tag in Selenium?
Forget about complex web scraping processes
Choose Oxylabs' advanced web intelligence collection solutions to gather real-time public data hassle-free.
About the author
Augustas Pelakauskas
Former Senior Technical Copywriter
Augustas Pelakauskas was a Senior Technical Copywriter at Oxylabs. Coming from an artistic background, he is deeply invested in various creative ventures - the most recent being writing. After testing his abilities in freelance journalism, he transitioned to tech content creation. When at ease, he enjoys the sunny outdoors and active recreation. As it turns out, his bicycle is his fourth-best friend.
All information on Oxylabs Blog is provided on an "as is" basis and for informational purposes only. We make no representation and disclaim all liability with respect to your use of any information contained on Oxylabs Blog or any third-party websites that may be linked therein. Before engaging in scraping activities of any kind you should consult your legal advisors and carefully read the particular website's terms of service or receive a scraping license.
Related articles





Get the latest news from data gathering world
Scale up your business with Oxylabs®
Proxies
Advanced proxy solutions
Data Collection
Datasets
Resources
Innovation hub
Forget about complex web scraping processes
Choose Oxylabs' advanced web intelligence collection solutions to gather real-time public data hassle-free.