175M+ ethically sourced IPs built for the highest reliability.
High-speed, cost-effective proxies built for any scraping workload.
Premium static residential proxies from trusted ASNs for most difficult targets.
Dedicated IPs from premium ASNs for demanding scraping.

AI-powered proxy solution for optimized web scraping performance.

20M+ IP addresses from real mobile devices for precise targeting.

Free Chrome proxy manager extension that works with any proxy provider.

Free Android proxy manager app that works with any proxy provider.

Free community-driven tools to improve your web scraping projects.
Web Scraper API
All-in-one web data collection platform for every stage of web scraping.
Fast Search API
Ultra-fast organic search results scraper tailored for AI workflows.
Headless Browser
Advanced browser automation solution for AI agents and scraping.
AI Studio
A suite of AI-powered tools for various scraping projects.

Documentation
All features, parameters, and integration details, backed by code samples in every coding language.
Tutorials, samples, and guides.
Latest fixes and features.





How to Use a Proxy With Scrapy in Python
This tutorial will guide you through the Scrapy installation process using Python, explaining how to set up Oxylabs proxies through the proxy as a request and proxy middleware methods. It’ll demonstrate how to use rotating proxies and integrate our proprietary Web Unblocker tool – let's dive in!


What is Scrapy?
Scrapy is a scalable open-source web crawling framework for fast data extraction from websites, featuring extensive community support, code reusability, and adequately maintained documentation. It provides a simple yet extensive collection of built-in functionalities that make scraping websites easier.
Scrapy is a portable framework – developed in Python for easy extensibility – and has built-in support for XPath or CSS selectors to parse the retrieved contents. Additionally, Scrapy uses asynchronous calls to scrape multiple web pages simultaneously.
How to set up a Scrapy project?
This section briefly explains how to set up a Scrapy project and build a basic scraper. Let's start with the installation.
Installing Scrapy and creating your first project
Start by opening your Python command terminal and execute the following pip command:
pip install scrapyThe next step is to create a Scrapy project. Let’s say that you want to create a new project named scrapyproject. To do that, you need to run the following command:
scrapy startproject scrapyprojectIt’s as simple as that – you’ve now created your first Scrapy project.
Generating spiders in a Scrapy project
The scrapy startproject scrapyproject creates a new folder, which means that before you begin generating spiders, you need to enter the scrapyproject folder.
After you’ve done that, you can start generating a spider, otherwise known as a crawler. While generating a spider, you need to specify its name and the target URL, as demonstrated below:
scrapy genspider <spider_name> <url_domain>Let’s say that the target URL for scraping is https://sandbox.oxylabs.io/products. A Scrapy spider named games can be generated by executing the following command:
scrapy genspider games sandbox.oxylabs.ioThis command will generate basic codes for the games spider in the Scrapy project (scrapyproject in this case). Let’s take a look at the outcome of the previous commands executed until now:
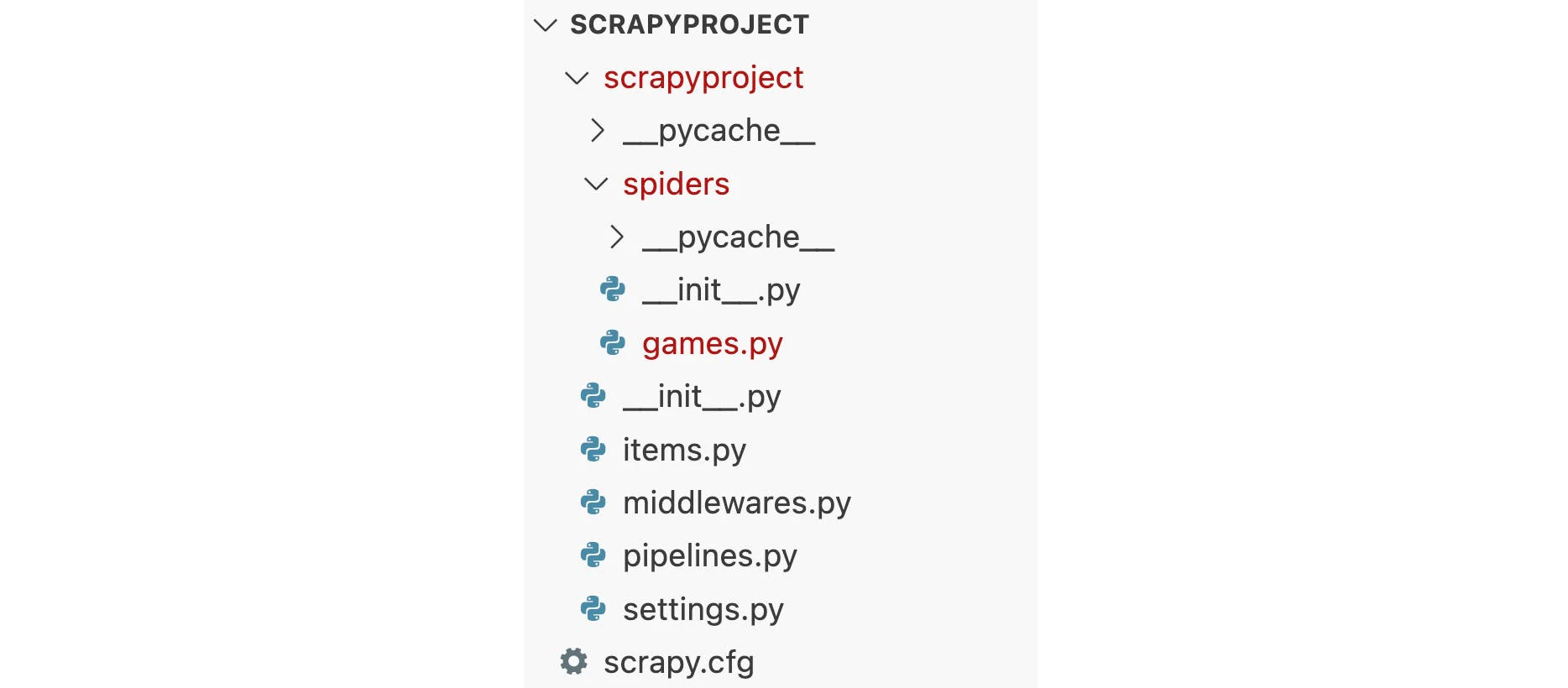
Scrapy project with games spider
NOTE: A Scrapy project can have multiple spiders. In this case, you only have a single spider whose basic code is written in games.py.
How to modify a spider to scrape desired data?
If you want to scrape titles and prices of all the games at the scraping target (video games to scrape), you need to modify the games.py files to make the spider scrape what you want.
Let’s open the existing games.py file and overwrite the contents with the following code:
import scrapy
class GamesSpider(scrapy.Spider):
name = "games"
def start_requests(self):
start_urls = ["https://sandbox.oxylabs.io/products"]
for url in start_urls:
yield scrapy.Request(url=url, callback=self.parse)
def parse(self, response):
for game in response.css(".product-card"):
yield {
"title": game.css(".title ::text").get(),
"price": game.css(".price-wrapper ::text").get(),
}The response method above first retrieves the raw contents from the target URL and then passes the response to the parse method. The parse method receives raw contents in the response variable and yields/returns the parsed data after applying the relevant parsing.
In this case, the parse method uses the CSS selectors to select the title and price text from every game on the target page, which are enclosed in the div element with the product-card class, as depicted in the following snippet:
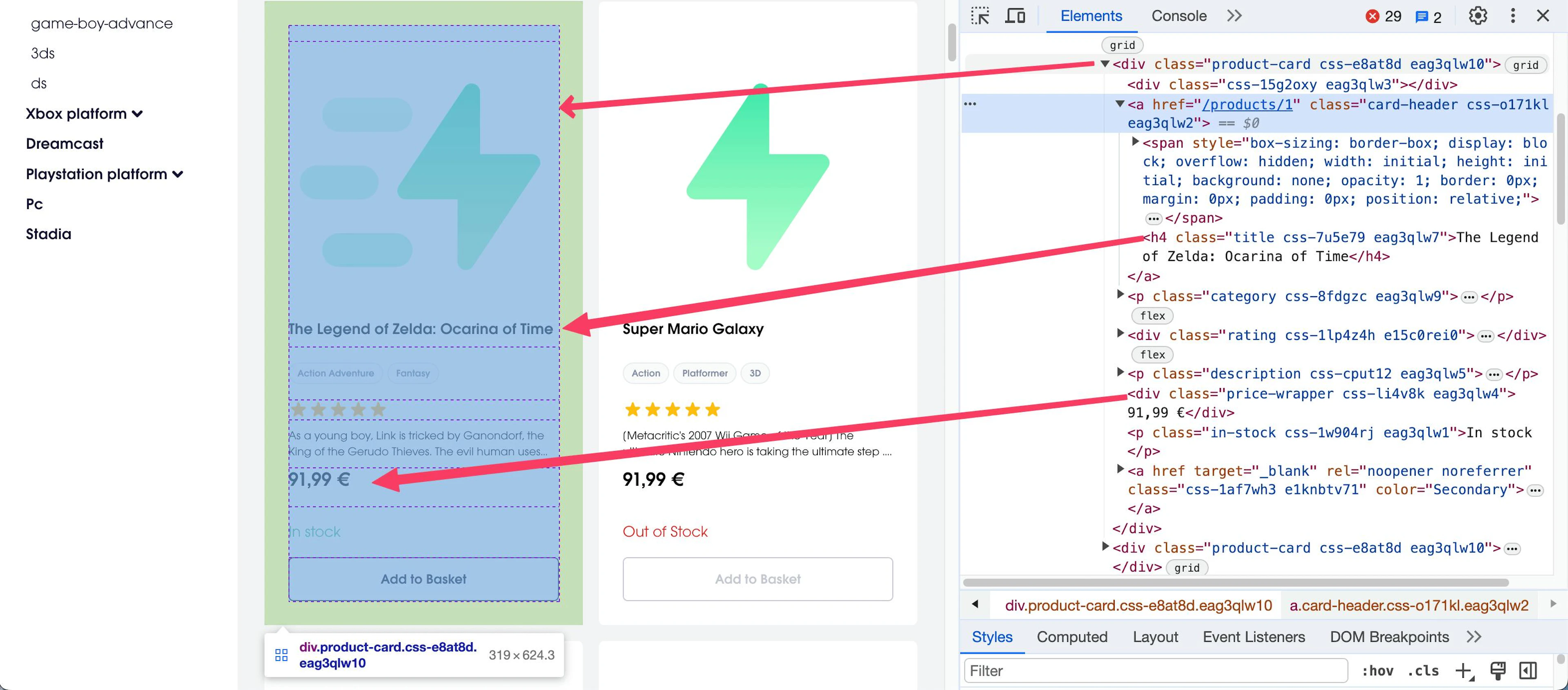
Game information in the target page
Executing a scrapy spider
Once you’re done with personalizing a spider, you can use the following command to run the spider:
scrapy crawl gamesThe command above will execute the games spider and display output in the output console. However, if you prefer saving the results to a file, run the spider with this command:
scrapy crawl -o FileName.csv gamesThe contents of the saved CSV file, created after executing the games spider, are:
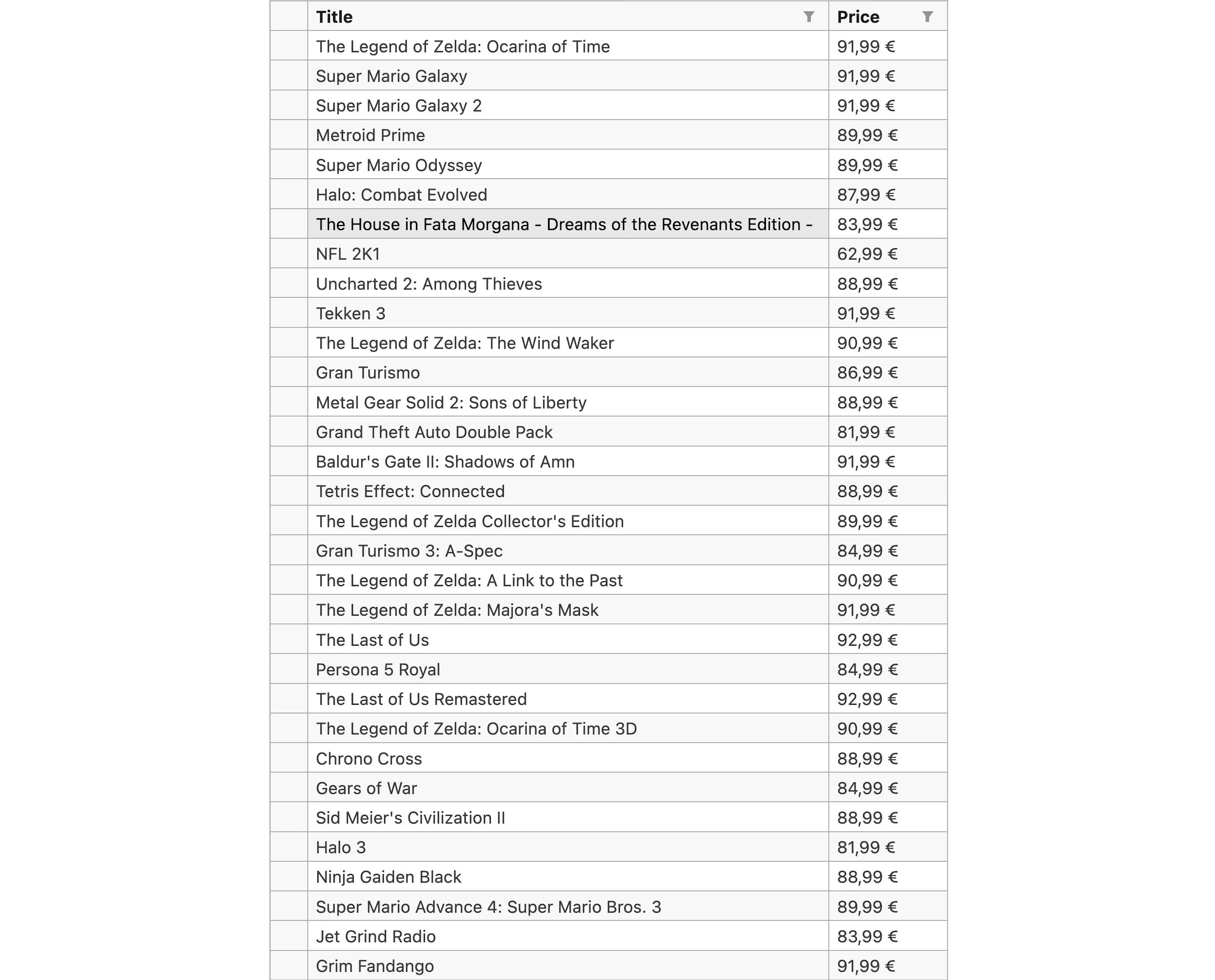
Contents of the CSV file
Setting up proxies with Scrapy
One of the advantages of using a proxy with web scraping is that it allows you to hide your actual IP address from being visible to the site's server. Using proxies protects your privacy and prevents you from being banned from the target sites when you’re using an automated tool rather than manually copying and pasting data from the site.
Scrapy proxy integration with a spider (or a scraper) can be done by passing the proxy as a request parameter. Alternatively, you can create custom middleware. Let’s see how you can use these two methods to integrate Oxylabs’ Datacenter, Mobile, and Residential Proxies.
Method 1: Proxy as a request parameter
As the name suggests, the request parameters method involves passing proxy credentials as a separate parameter to the scrapy.Request method. You can use the meta parameter to pass the ProxyUrl and the user credentials to the Request method. Following is the generic format of a proxy endpoint:
Protocol://username:password@ProxyUrl:PortThe Protocol, user credentials, ProxyUrl, and port number will differ according to the type of proxy you’ve purchased. For example, the following table provides a list of Oxylabs proxy endpoints as per the type of proxies.
| Proxy type | Protocol | ProxyUrl | Port | Credentials |
|---|---|---|---|---|
| Residential and Mobile Proxies | HTTP, HTTPS, SOCKS5 |
pr.oxylabs.io | 7777 |
Proxy user’s username and password |
| Datacenter Proxies | HTTP, HTTPS, SOCKS5 |
dc.oxylabs.io | 8001 |
Proxy user's username and password |
| Enterprise Dedicated Datacenter Proxies | HTTP, SOCKS5 |
a specific IP address | 60000 |
Proxy user's username and password |
| Self-Service Dedicated Datacenter Proxies | HTTP, HTTPS, SOCKS5 |
ddc.oxylabs.io | 8001 |
Proxy user's username and password |
| ISP Proxies | HTTP, HTTPS, SOCKS5 |
isp.oxylabs.io | 8001 |
Proxy user's username and password |
NOTE: For additional Oxylabs’ proxy customization options – such as country-specific entry points – refer to Datacenter per traffic, Datacenter per IP, Enterprise Dedicated Datacenter, Self-Service Dedicated Datacenter, Mobile, and Residential Proxies documentations, respectively.
The following code demonstrates an example of integrating a Residential Proxy IP with the games spider using the proxy as a parameter to the request method.
import scrapy
class GamesSpider(scrapy.Spider):
name = "games"
def start_requests(self):
start_urls = ["https://sandbox.oxylabs.io/products"]
for url in start_urls:
yield scrapy.Request(
url=url,
callback=self.parse,
meta={"proxy": "http://username:password@pr.oxylabs.io:7777"},
)
def parse(self, response):
for game in response.css(".product-card"):
yield {
"title": game.css(".title ::text").get(),
"price": game.css(".price-wrapper ::text").get(),
}Method 2: Creating custom Scrapy proxy middleware
Scrapy proxy middleware is an intermediary layer to route requests through a proxy server. Once a middleware is defined and registered, every spider in the project has to pass through this middleware.
Using Scrapy proxy middleware is particularly handy when you have multiple spiders. It makes it easy to add, remove, and modify proxy endpoints for the spiders without requiring any changes to the spiders’ actual code.
To use a proxy middleware in Scrapy, you must add it to the list of middleware in your settings.py file. Before registering a middleware, let’s create one first.
Open the middlewares.py file and write the following custom proxy middleware code in it:
class GamesProxyMiddleware:
@classmethod
def from_crawler(cls, crawler):
return cls(crawler.settings)
def __init__(self, settings):
self.username = settings.get('PROXY_USER')
self.password = settings.get('PROXY_PASSWORD')
self.url = settings.get('PROXY_URL')
self.port = settings.get('PROXY_PORT')
def process_request(self, request, spider):
host = f'http://{self.username}:{self.password}@{self.url}:{self.port}'
request.meta['proxy'] = hostGamesProxyMiddleware expects all the required information for a proxy endpoint and adds it to the metaparameter of the request.
The next step is to register this middleware in settings.py so that it can serve as an intermediary for each crawl/scrape request. Open the settings.py file and update it as:
PROXY_USER = 'username'
PROXY_PASSWORD = 'password'
PROXY_URL = 'pr.oxylabs.io'
PROXY_PORT = '7777'
DOWNLOADER_MIDDLEWARES = {
'scrapyproject.middlewares.GamesProxyMiddleware': 100,
'scrapy.downloadermiddlewares.httpproxy.HttpProxyMiddleware': 110,
}The GamesProxyMiddleware is added to the DOWNLOADER_MIDDLEWARES list in settings.py with a sequence number equal to 100. The middleware is applied to the spiders in ascending order of the sequence numbers.
Another thing to note here is that all the proxy endpoint credentials are defined in the settings.py file. Whenever you update the endpoint, you only need to change it in the settings.py file. If any change occurs in the proxy endpoint, the proxy middleware saves you from updating code for all the spiders.
Once the code for the middleware is complete and all the proxy parameter values are set, you can run the games spider using the same scrapy crawl games command.
Using rotating proxies for Scrapy
Rotating proxies means alternatively using different proxy IPs from proxy lists. Proxy rotation in Scrapy spiders can help avoid being detected and blocked by website administrators. Your scraper or spider keeps working, even if one of the proxy IPs gets blocked.
To rotate proxies in Scrapy, you must install the scrapy-rotating-proxies package. The package can be installed using the following command:
pip install scrapy-rotating-proxiesOnce the scrapy-rotating-proxies package is installed, you need to create a list of available proxies in the setting.py file. For example, the following sample proxy list can serve the purpose when used with proper user credentials and specific IPs:
ROTATING_PROXY_LIST = [
'http://username:password@pr.oxylabs.io:7777',
'http://username:password@dc.oxylabs.io:8000',
'http://username:password@Specific_IP_1:60000',
'http://username:password@Specific_IP_2:60000',
.
.
.
'http://username:password@Specific_IP_N:60000'
]You can also load available proxies from a file instead of writing in a list. If you want to load proxies from a file, you must set the ROTATING_PROXY_LIST_PATH variable in the setting.py to point to your desired file:
ROTATING_PROXY_LIST_PATH = '/path/to/file/proxieslist.txt'To apply the rotating proxies middleware, you must add the RotatingProxyMiddleware and BanDetectionMiddlewareto the DOWNLOADER_MIDDLEWARES list in the settings.py file, as shown in the code below:
DOWNLOADER_MIDDLEWARES = {
'rotating_proxies.middlewares.RotatingProxyMiddleware': 610,
'rotating_proxies.middlewares.BanDetectionMiddleware': 620,
}Once you’ve done that, you’re all set! Just execute your spider using the scrapy crawl command. The RotatingProxyMiddleware will take on the responsibility of rotating the proxy endpoints periodically.
Integrating Scrapy with Oxylabs Web Unblocker
Although powerful, even with proxies, Scrapy can still be limited when dealing with some advanced anti-bot systems, resulting in blocks. To successfully collect public web data without interruptions, you can use Oxylabs' Web Unblocker with a free trial.

What is Web Unblocker?
Web Unblocker is an AI-driven tool that automates and manages proxies, browser fingerprinting, automatic retries, CAPTCHA bypass, and JavaScript rendering.
Let’s incorporate Web Unblocker into the Scrapy workflow.
In essence, Web Unblocker functions as a proxy, letting you set it up just like a proxy by editing the spider. Do so by using the meta parameter in scrapy.Request that was created in the start_requests function.
class GamesSpider(scrapy.Spider):
name = "games"
def start_requests(self):
start_urls = ["https://sandbox.oxylabs.io/products"]
for url in start_urls:
yield scrapy.Request(
url=url,
callback=self.parse,
meta={"proxy": "http://USERNAME:PASSWORD@unblock.oxylabs.io:60000"})
def parse(self, response):
for game in response.css(".product-card"):
yield {
"title": game.css(".title ::text").get(),
"price": game.css(".price-wrapper ::text").get(),
}You only need to provide the proxy URL (unblock.oxylabs.io:60000) and your user credentials. You can also add configurable parameters like geolocation and session ID by passing them to the request header. You can find all the parameters in our documentation.
NOTE: Scrapy will write custom headers for you, but Web Unblocker will ignore and rewrite them to pass the blocking systems. If you wish, you can override Web Unblocker and specify headers explicitly using configurable parameters in the request header.
Conclusion
Due to its speed and reliability, Scrapy is a perfect choice when you want to extract data in vast amounts. It will do a great job of preventing IP blocks and ensuring the efficiency of your scraping operations.
In case your project requires scraping dynamically-loaded content, then check out our detailed analysis of Scrapy vs. Selenium to learn more. For more general information, you can also check out Scrapy vs. Beautiful Soup.
If you have further questions about using Oxylabs’ proxies with Scrapy or any other proxy solution, don’t hesitate to contact our team. You can also check out our integrations for more.
Please be aware that this is a third-party tool not owned or controlled by Oxylabs. Each third-party provider is responsible for its own software and services. Consequently, Oxylabs will have no liability or responsibility to you regarding those services. Please carefully review the third party's policies and practices and/or conduct due diligence before accessing or using third-party services.
Useful resources
Web Scraping with Scrapy: Python Tutorial
This technical tutorial will walk you through the key steps of web scraping with Scrapy.
How to Rotate Proxies in Python
A beginner-friendly guide for rotating proxies using Python.
Using Apache Airflow to Build a Pipeline for Scraped Data
Learn how to acquire public data with Oxylabs' E-Commerce Scraper API and build a pipeline for scraped data.

Get the latest news from data gathering world
Proxies
Advanced proxy solutions
Data Collection
Datasets
Resources
Innovation hub