175M+ ethically sourced IPs built for the highest reliability.
High-speed, cost-effective proxies built for any scraping workload.
Premium static residential proxies from trusted ASNs for most difficult targets.
Dedicated IPs from premium ASNs for demanding scraping.

AI-powered proxy solution for optimized web scraping performance.

20M+ IP addresses from real mobile devices for precise targeting.

Free Chrome proxy manager extension that works with any proxy provider.

Free Android proxy manager app that works with any proxy provider.

Free community-driven tools to improve your web scraping projects.
Web Scraper API
All-in-one web data collection platform for every stage of web scraping.
Fast Search API
Ultra-fast organic search results scraper tailored for AI workflows.
Headless Browser
Advanced browser automation solution for AI agents and scraping.
AI Studio
A suite of AI-powered tools for various scraping projects.

Documentation
All features, parameters, and integration details, backed by code samples in every coding language.
Tutorials, samples, and guides.
Latest fixes and features.






![]() AI Summary:
AI Summary:
This post explains how to automate Python web scraping scripts on Unix-like operating systems using the cron utility. It details preparing Python scripts with best practices and configuring crontab entries for scheduled, recurring execution.
In most cases, the first step to building an automated web scraper comes from writing up a Python web scraper script. The second is the automation itself, which can be done in many different ways, yet one of them stands out as the most straightforward. macOS, Linux, and other Unix-like operating systems have a built-in tool - cron - which is specifically suited for continuously repeated tasks.
Therefore, this article will primarily teach how to schedule tasks using cron. For the automation example, a web scraper written using Python was chosen.
You can also check a video tutorial, where we cover the web scraping automation topic and provide even more options on how to do it:

Note that before you start configuring cron, there are certain preparatory guidelines we’d recommend you follow, as this will ensure you’ll have fewer chances of errors.
Preparing the Python script
The first tip is to use a virtual environment. It will ensure that the correct Python version is available as well as all required libraries are there just for your Python web scraper and not everyone on your system.
The next good practice is to use the absolute file paths. Doing so ensures that the script does not break because of missing files in case you change your working directory.
Lastly, using logging is highly recommended as it allows you to have a log file you can refer to and troubleshoot if something breaks.
You can configure logging with just a single line of code after importing the logging module:
import logging
logging.basicConfig(filename="scraper.log",level=logging.DEBUG)After this, you can write in the log file as follows:
logging.info("informational message here")For more information on logging, see the official documentation.
Example Python script
First, install the required libraries:
python -m pip install requests beautifulsoup4 lxmlSince the article’s focus is on providing a realistic example, the following script is made to resemble real-life automated scraping:
from bs4 import BeautifulSoup
import requests
url = 'https://books.toscrape.com/catalogue/a-light-in-the-attic_1000/index.html'
response = requests.get(url)
response.encoding = 'utf-8'
soup = BeautifulSoup(response.text, 'lxml')
price = soup.select_one('#content_inner .price_color').text
with open('data.csv', 'a') as f:
f.write(price + '\n')Every time you run this script, it will append the latest price in a new line to the CSV.
What is cron, and how does it work
The cron utility is a program that checks if any tasks are scheduled and runs those tasks if the schedule matches.
An essential part of cron is crontab, which is short for cron table, a utility to create files that the cron utility reads, a.k.a crontab files.
In this article, we will directly work with such files. If you want to learn how to write cron jobs in Python directly, see the library python-crontab.
When using python-crontab, it is possible to configure cron directly. In this case, you can also use Python to remove crontab jobs. In our example, however, we will focus on working with crontab.
Crontab Syntax
The first step of building an automated web scraping task is understanding how crontab utility works.
To view a list of currently configured crontab tasks, use the -l switch as follows:
crontab -lTo edit the crontab file, use the -e switch:
crontab -eThis command will open the default editor, which in most cases is vi. You can change the editor to something more straightforward, such as nano, by running the following command:
export EDITOR=nanoNote that other editors, such as Visual Studio Code, won’t work because of how it handles files at the system level. It is safest to stick with vi or nano.
The crontab entry use this pattern:
<schedule> <command to run>Each line contains the schedule and the task to be run.
How to edit the crontab file
To edit the crontab file, open the terminal and enter the following command:
crontab -eThis command will open the default editor for crontab. On some Linux distros, you may be asked which program you want to open to edit this file.
In the editor, enter the task and frequency in each line.
The following image shows the virtualenv python as the binary:
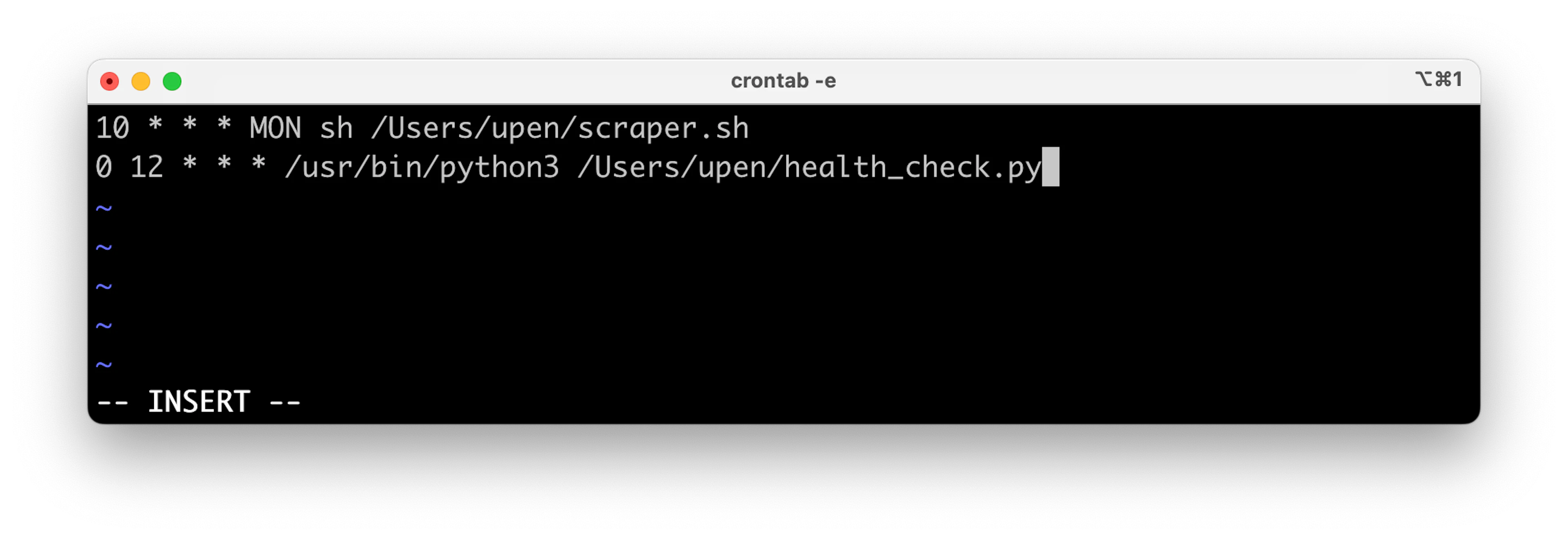
Crontab_e
How to run cron job frequently
Each entry in crontab begins with cron job frequency. The frequency or schedule contains five parts:
Minute
Hour (in 24-hour format)
Day of the month
Month
Day of the week
The possible values are * (any value) or a number.
For example, if you want to run a task every hour, the schedule will be as follows:
0 * * * *Notably, the cron process runs every minute and matches the current system time with this entry. In our case, it will only match when the system time is minute 0. All other fields have *, meaning these will fit for any value.
Since this task will run at 4:00, 5:00, 6:00, etc. -- effectively, the schedule will create a job run every hour.
Here are a few more examples.
To run a task at 10 am on the 1st of every month, use the following:
0 10 1 * *To run a task at 2 pm (14:00) every Monday, type:
0 14 * * 1Many sites, such as crontab.guru can help you build and validate a schedule.
How to remove python crontab job
To remove all crontab jobs, open the terminal and use this command:
crontab -rIf you want to remove a specific crontab job, you can edit the crontab file as follows:
crontab -eOnce in edit mode, you can delete the line for that job and save this file. The crontab will be configured with the updated contents, effectively deleting the cron job.
How to schedule Python script in crontab
First, decide what command you want to run. If you are not using a virtual environment, you can run your web scraping script as follows:
python3 /Users/upen/shopping/scraper.pyIn some cases, you will have specific dependencies. If you're following recommended practices, it’s likely you've created a virtual environment.
Do note that it's often unnecessary to use source venv/bin/activate to release your venvo python with all its dependencies. For example, .venv/bin/python3 script.py already uses python3 from virtualenv.
A further recommendation would be to create a shell script and write the above lines in that script to make it more manageable. If you do that, the command to run your scraper would be:
sh /Users/upen/shopping/run_scraper.shThe second step is to create a schedule. Let’s take an example of where the script must be run hourly. The cron schedule will be as follows:
0 * * * *After finalizing these two pieces of information, open the terminal and enter the command:
crontab -eNext, enter the following line, assuming you are using a shell script.
0 * * * * sh /Users/upen/shopping/run_scraper.shUpon saving the file, you may receive a prompt by your operating system, which will state your system settings are being modified.
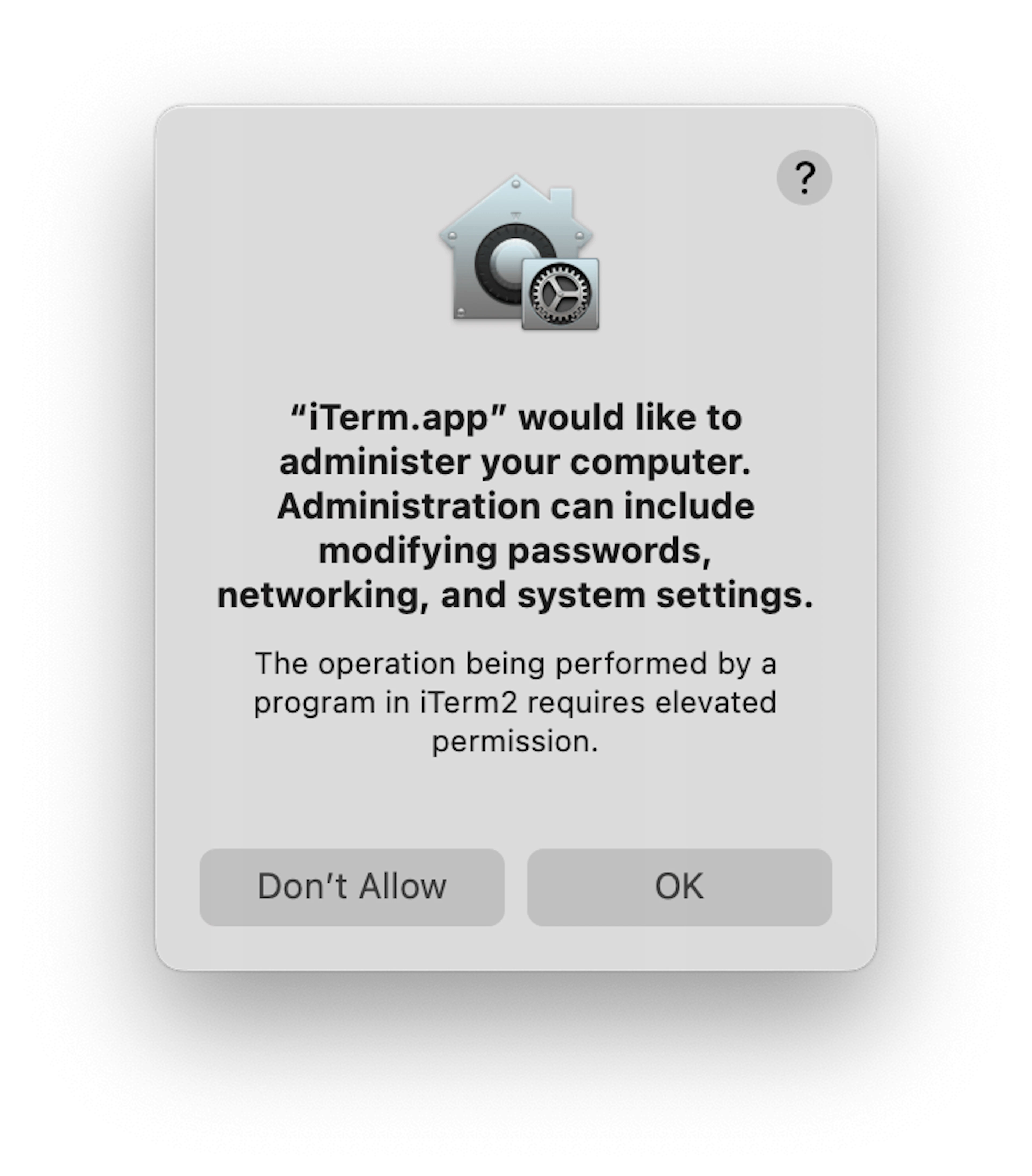
Permissions
Accept it to create the cron job.
Installing_cron
Common reasons why crontab Python script isn't running
On macOS, the most common reason is cron’s lack of permission. To specify them, open System Preferences and click on Security & Privacy. In the Privacy tab, select Full Disk Access on the left and add the path of the cron executable. If you aren’t sure about the location of the cron executable, run the following command from the terminal:
which cronAnother common problem is that the system used Python 2 instead of 3 and vice versa. Remember that macOS and many other Linux distros ship with both Python 2 and Python 3. To fix this, find the complete path of the python executable file. Open the command prompt and run the following:
where python3Take note of the python executable that you want to use. Unless you are using virtual environments, you must specify the complete path of the Python file.
Another common reason for failure is an incorrect path script. As a thumb rule, when working with cron, always use absolute paths.
Cron job vs SystemD vs Windows Task Scheduler vs AutoScraper
Cron is a tool specific to Unix-like operating systems such as macOS and Linux. Tools similar to it are Systemd (read as system-d) and Anacron. However, these are Linux-specific and aren't available on Windows.
For Windows, you can use the dedicated Windows Task Scheduler tool.
AutoScraper, on the other hand, is an open-source Python library that can work with most scenarios. You should note that the library isn’t meant to be an alternative to cron. It can automate the web scraping part, but you still have to write the Python script and use cron or one of the alternatives to run it automatically.
Scraper API Scheduler
Automating web scraping tasks is even easier with Oxylabs Scraper APIs. They come with a free feature called Scheduler, with which you can schedule multiple scraping and parsing jobs at any frequency. What’s great about it is that you can configure it to deliver the results straight to your preferred cloud storage and notify you once the delivery is done.
There are three simple steps to automating your tasks with Scheduler:
Submit a cron expression that tells us the frequency rate;
Specify the job parameters that we should execute;
Tell us when the schedule should be stopped.
You can find in-depth information on using Scheduler by visiting our documentation.
Conclusion
After having covered the crucial aspects of cron, crontab, and cron jobs, we hope you’ve gained a greater understanding of how web scraping automation is possible through above mentioned specific practices. As always, before automating web scraping projects, do make sure you conduct adequate research to determine which software and languages are the most relevant for your projects, as both Cron and Python have a variety of benefits and limitations when compared to the alternatives, such as Crawlee web scraping using JavaScript.
Fortunately, you can find advanced web scraping solutions for various cases, such as the Web Scraper API. With it, you get access to proxies, sophisticated scraping features, and a Scheduler to automate scraping and parsing jobs, so be sure to take a look.
People also ask
What is a crontab in Linux?
The crontab (short for cron-Table) is the file that lists the programs or scripts that will be executed by the cron tool. These files cannot be edited directly and should be adjusted using the command line tool crontab.
What is a cron job in Python?
What is the difference between cron and crontab?
Forget about complex web scraping processes
Choose Oxylabs' advanced web intelligence collection solutions to gather real-time public data hassle-free.
About the author

Danielius Radavicius
Former Copywriter
Danielius Radavičius was a Copywriter at Oxylabs. Having grown up in films, music, and books and having a keen interest in the defense industry, he decided to move his career toward tech-related subjects and quickly became interested in all things technology. In his free time, you'll probably find Danielius watching films, listening to music, and planning world domination.
All information on Oxylabs Blog is provided on an "as is" basis and for informational purposes only. We make no representation and disclaim all liability with respect to your use of any information contained on Oxylabs Blog or any third-party websites that may be linked therein. Before engaging in scraping activities of any kind you should consult your legal advisors and carefully read the particular website's terms of service or receive a scraping license.
Related articles

Web Scraping with Crawlee: Step-By-Step Tutorial

Yelyzaveta Hayrapetyan
2025-10-01
![Automated Web Scraper With Python AutoScraper [Guide]](https://oxylabs.io/oxylabs-web/ZpBhlx5LeNNTxEcW_eba26704-d9e7-4562-aaf4-0375a6bb9693_Python-Web-Scraping-1200x600.png?auto=format%2Ccompress&rect=0%2C0%2C1200%2C600&w=3840&h=600&q=75)


Automated Web Scraper With Python & Windows Task Scheduler

Augustas Pelakauskas
2022-08-04

Get the latest news from data gathering world
Scale up your business with Oxylabs®
Proxies
Advanced proxy solutions
Data Collection
Datasets
Resources
Innovation hub
Forget about complex web scraping processes
Choose Oxylabs' advanced web intelligence collection solutions to gather real-time public data hassle-free.