175M+ ethically sourced IPs built for the highest reliability.
High-speed, cost-effective proxies built for any scraping workload.
Premium static residential proxies from trusted ASNs for most difficult targets.
Dedicated IPs from premium ASNs for demanding scraping.

AI-powered proxy solution for optimized web scraping performance.

20M+ IP addresses from real mobile devices for precise targeting.

Free Chrome proxy manager extension that works with any proxy provider.

Free Android proxy manager app that works with any proxy provider.

Free community-driven tools to improve your web scraping projects.
Web Scraper API
All-in-one web data collection platform for every stage of web scraping.
Fast Search API
Ultra-fast organic search results scraper tailored for AI workflows.
Headless Browser
Advanced browser automation solution for AI agents and scraping.
AI Studio
A suite of AI-powered tools for various scraping projects.

Documentation
All features, parameters, and integration details, backed by code samples in every coding language.
Tutorials, samples, and guides.
Latest fixes and features.






![]() AI Summary:
AI Summary:
This article shows how to automate Python web scraping scripts using Windows Task Scheduler. It walks through script preparation, batch file creation, and Task Scheduler configuration to run scripts periodically and reliably, even when not logged in or the computer is sleeping. It also covers common troubleshooting tips and notes Cron as the equivalent alternative for macOS and Linux.
To be of recurrent use, a Python web scraping script would have to be automated to run repeatedly and periodically. There are some ways to do this in Python directly, although a more accessible alternative is available. MS Windows has a built-in tool, Windows Task Scheduler, for running applications automatically.
In this article, you’ll learn how to set up Windows Task Scheduler (Task Scheduler) to schedule a Python script automatically and periodically.
You can also check a video tutorial, where we cover the web scraping automation topic and provide even more options on how to do it:

If you’re using macOS or Linux, you can use cron instead of Windows Task Scheduler. For more details, see how to automate web scraping with Python and cron.
Guide to running a Windows Task Scheduler Python Script
Before configuring the Task Scheduler, follow these guidelines to prepare your web scraping script and avoid the most common errors.
Preparing a Python script
Here are the three tips to follow when preparing a Python script.
Use a virtual environment to ensure that the correct Python version and all the required libraries are available when you run your Python web scraper.
Use the absolute file paths to ensure that the script doesn’t break due to missing files.
Use loggers to redirect output to a file.
After importing the logging module, you can configure logging with only one line of code:
import logging
logging.basicConfig(filename="output.log",level=logging.DEBUG)After this, you can write to the log file as follows:
logging.info("informational message here")You can read more about logging here.
Python script example
First, install the required libraries:
python -m pip install requests beautifulsoup4 lxmlIn this article, the following Python web scraping script will be used:
### price.py
from bs4 import BeautifulSoup
import requests
response = requests.get('https://sandbox.oxylabs.io/products/1')
response.encoding = 'utf-8'
soup = BeautifulSoup(response.text, 'lxml')
price = soup.select_one('div.price').text
with open('data.csv','a') as f:
f.write(price + '\n')Every time you run this script, it’ll append the latest product price in a new line to the CSV file.
How to create a batch file to run the Python script
Even though running a Python script without creating a .bat (batch) file is possible, doing so is highly recommended. A batch file will give you better control over running the scraper.
Here is what a typical batch file would look like:
cmd /k "cd /d C:\scraper & venv\Scripts\python.exe price.py"Note that there are two parts of this command – the first is the command cmd, and the second contains multiple commands.
Here is a quick explanation of the command:
cmd /k – creates a new command-line environment, executes the commands, and then terminates them.
cd /d c:\scraper – changes the current directory and drive to the folder where you have placed the Python executable.
venv\Scripts\python.exe price.py – runs the Python web scraper.
Now, as you have cd in the directory, you can use the relative file paths. If you were to skip this step, specify the full path of the Python executable and the Python script file.
How to set up Windows Task Scheduler to run a Python script
Once the batch file is ready, locate the Task Scheduler through Windows Search.

Locating Windows Task Scheduler
From the right panel of the Task Scheduler, select Create Task.

Create Task (not Basic Task)
Note that you shouldn’t select Create Basic Task due to limited options.
The Create Task window contains various settings across the General, Triggers, Actions, Conditions, and Settings tabs.

Functionality overview
The General tab has two settings to check. The first one is the name of the task that you’re creating. Choose a name that helps you remember its purpose.
Run whether user is logged on or not is an essential setting. Select it if you want your web scraper to run even when you are not logged on. Note that if you select this option, you’ll be asked for your password towards the end of the task creation process.
Next, open the Triggers tab. In this tab, click the New button. You’ll see the New Trigger window.

Trigger defines when the scraper runs
For example, you want the web scraper to run every hour. To do so, select Daily in Settings. In the Advanced settings, choose Repeat task every and set 1 hour.
For error handling, select Stop task if it runs longer than and choose a value.
Ensure that Enabled is selected and click OK to save the trigger.
Next, open the Actions tab and click New. You’ll see the New Action window.

Actions define what has to be done
In this window, maintain the action Start a program and specify the full path of the batch script.
As defined previously, the batch file contains only one line:
cmd /k "cd /d C:\scraper & venv\Scripts\python.exe price.py"Important: If you have spaces in your path, surround the entire path with double quotes.
Alternatively, you can still run a Python script directly if you aren’t using a batch file.
In the Program/script field, specify the complete path of the python.exe file. In the Add arguments textbox, indicate the complete path of the Python script. Once again, make sure that if you have spaces in any of these paths, surround them with double quotes.
Lastly, if you’re using relative paths anywhere in the code, it would be a good idea to set the Start in textbox to the folder where you have the Python script. You can skip the Conditions tab and jump directly to the tab. The suggested settings are highlighted below.
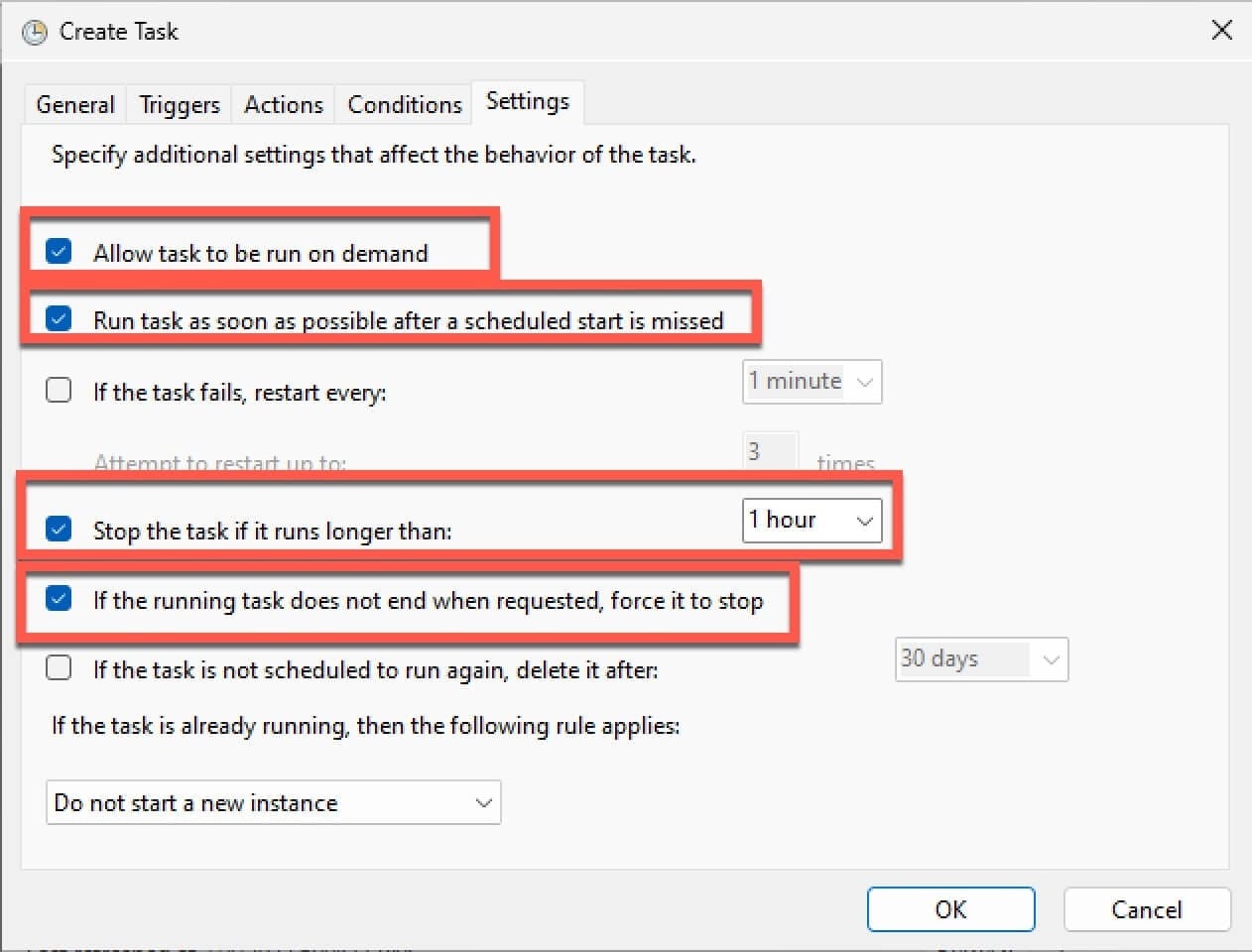
Suggested settings
All the settings are self-explanatory and optional. You can choose to select the defaults and click OK.
Once you click OK, you’ll be asked for Windows credentials. Enter your username and password and click OK to save the task. The web scraper will be executed during the next scheduled run.
Common reasons why Windows Task Scheduler Python script isn't running
The most common setback is when the Task Scheduler can’t find the python.exe file. To fix this, find the complete path of the Python executable file. Open the Command Prompt and run the following command:
where pythonThe output of this command will be one or more lines. Each line contains the full path of the Python executable:
C:\scraper>where python
C:\Program Files\Python310\python.exe
C:\Users\codeRECODE\AppData\Local\Microsoft\WindowsApps\python.exeTake a note of the Python executable that you want to use. Unless you’re using virtual environments, you must specify the complete path of the python.exe file.
Another common reason for failure is when the script path is incorrect. When working with the Task Scheduler, always use absolute paths.
Lastly, surround the path with double quotes, especially when you have spaces in the path or file names.
Other web scraping automation alternatives
Windows Task Scheduler is a tool exclusive to Windows. If you use macOS or Linux, the Cron tool is the most prominent alternative.
Cron doesn’t have a user interface, but it’s capable of doing almost everything that the Task Scheduler can do. All you have to do is run crontab -e from the terminal and enter the details. The process is covered in detail in another blog post.
Some other Linux-specific tools available on Linux distributions are systemd (read as system-d) and Anacron.
Conclusion
Thanks to software found in every PC running Windows, the in-Python task scheduler may be an unnecessary burden. Automating Python web scraping scripts with Windows Task Scheduler is a quick and easy-to-use solution for running tasks at predefined intervals, even while the computer is sleeping.
Exclusive to Windows, the Task Scheduler has an analogue automation solution on macOS and Linux called Cron.
If you're looking for an easy way to scrape websites, check out our daily proxies for scraping and Scraper API solutions that's specifically built to get the data you need with ease. Don’t forget to take a look at other solutions for Python web scraping, such as how to make it faster and for specific use cases - how to build a price tracker or how to automate competitor analysis.
People also ask
How to schedule a Python script via the Cron job on Windows?
Windows has a better and easier-to-use tool - Windows Task Scheduler. Windows Task Scheduler is an alternative to Cron, available on Unix and Unix-like operating systems such as macOS and Linux. Windows Task Scheduler has, in fact, more features than Cron.
Does Windows Task Scheduler work when the computer is sleeping?
Forget about complex web scraping processes
Choose Oxylabs' advanced web intelligence collection solutions to gather real-time public data hassle-free.
About the author

Augustas Pelakauskas
Former Senior Technical Copywriter
Augustas Pelakauskas was a Senior Technical Copywriter at Oxylabs. Coming from an artistic background, he is deeply invested in various creative ventures - the most recent being writing. After testing his abilities in freelance journalism, he transitioned to tech content creation. When at ease, he enjoys the sunny outdoors and active recreation. As it turns out, his bicycle is his fourth-best friend.
All information on Oxylabs Blog is provided on an "as is" basis and for informational purposes only. We make no representation and disclaim all liability with respect to your use of any information contained on Oxylabs Blog or any third-party websites that may be linked therein. Before engaging in scraping activities of any kind you should consult your legal advisors and carefully read the particular website's terms of service or receive a scraping license.
Related articles

Cheerio vs. Puppeteer: Which Should You Use for Web Scraping?

Shinthiya Nowsain Promi
2026-06-23



Build Python Headless Browser Automation from Scratch
Shinthiya Nowsain Promi
2026-06-11

Get the latest news from data gathering world
Scale up your business with Oxylabs®
Proxies
Advanced proxy solutions
Data Collection
Datasets
Resources
Innovation hub
Forget about complex web scraping processes
Choose Oxylabs' advanced web intelligence collection solutions to gather real-time public data hassle-free.