175M+ ethically sourced IPs built for the highest reliability.
High-speed, cost-effective proxies built for any scraping workload.
Premium static residential proxies from trusted ASNs for most difficult targets.
Dedicated IPs from premium ASNs for demanding scraping.

AI-powered proxy solution for optimized web scraping performance.

20M+ IP addresses from real mobile devices for precise targeting.

Free Chrome proxy manager extension that works with any proxy provider.

Free Android proxy manager app that works with any proxy provider.

Free community-driven tools to improve your web scraping projects.
Web Scraper API
All-in-one web data collection platform for every stage of web scraping.
Fast Search API
Ultra-fast organic search results scraper tailored for AI workflows.
Headless Browser
Advanced browser automation solution for AI agents and scraping.
AI Studio
A suite of AI-powered tools for various scraping projects.

Documentation
All features, parameters, and integration details, backed by code samples in every coding language.
Tutorials, samples, and guides.
Latest fixes and features.





Web Scraping with Crawlee: Step-By-Step Tutorial


Yelyzaveta Hayrapetyan
Last updated on
2025-10-01
6 min read
![]() AI Summary:
AI Summary:
Crawlee is a Node.js package for web scraping and browser automation, providing a unified interface for HTTP and headless browser crawling. It supports features like proxy management, session handling, and pluggable storage to efficiently extract data from websites. The package simplifies setup with a CLI and offers customizable lifecycles for complex scraping tasks.
Web scraping and browser automation have emerged as essential tools for businesses looking to stay competitive in the digital market. This easy web crawling tutorial covers everything you need to get started with Crawlee – a tool for web scraping and browser automation.
Crawlee web scraping tutorial
This section discusses the installation steps of Crawlee web scraping library and explains how it works. Additionally, it contains a working example of scraping a website using Crawlee. If you're new to scraped data extraction and JavaScript web crawling, we highly recommend starting with the basics by following this detailed JavaScript & Node.js web scraping tutorial.
Installation
To use Crawlee web crawler with JavaScript on your system, you must install Node.JS version 16.0 or above. Along with it, NPM should also be installed.
The Crawlee CLI is the quickest and most efficient way to build new projects with Crawlee. The following command will create a new Crawlee NodeJS project inside the “my-crawler” directory:
npx crawlee create my-crawlerThe npx CLI tool runs the crawlee package locally without installing it globally on your machine. Running the above command will show you a prompt message to choose a template, as shown in the following snippet:
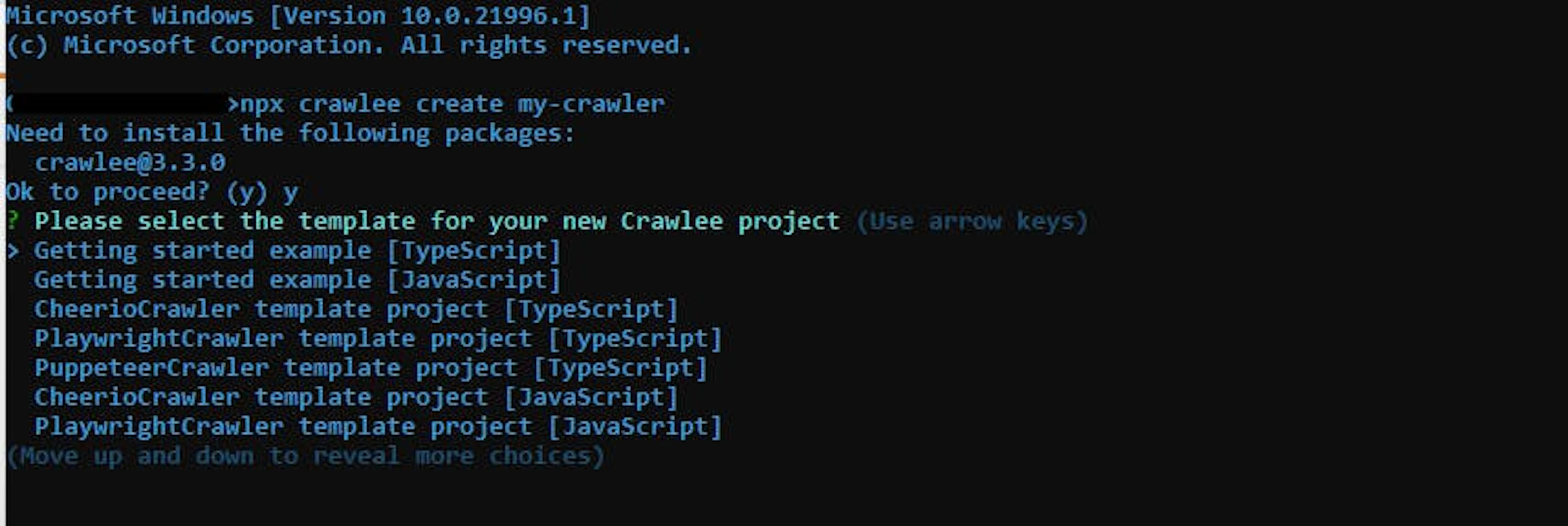
Since we are doing Node.JS development, we can select Getting Started Example (Javascript). This option will install all required dependencies and create a new directory named my-crawler in your current working directory. It will also add a package.json to this folder. Additionally, it will include example source code that you may use immediately. The image below shows the completed installation message:
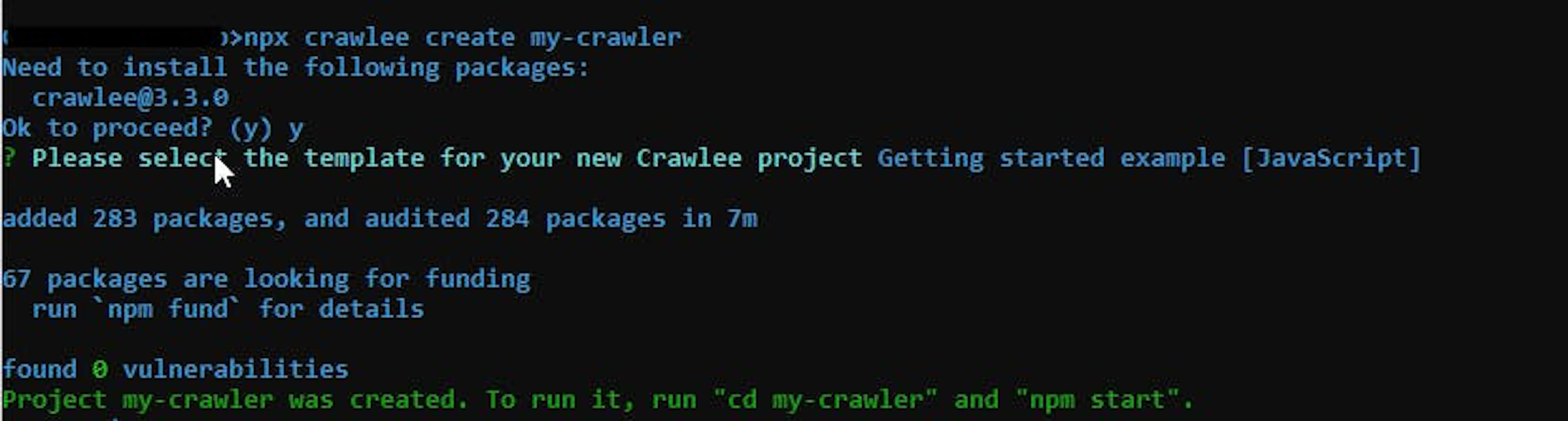
Remember, the Crawlee project was created inside the my-crawler folder. You first need to change your current directory to this folder.
cd my-crawlerNext, run the following command to start the Crawlee project:
npm startThe start command will start the default crawler of the project. This crawler crawls the Crawlee website and outputs the titles of all the links on the website.
Congratulations! You have successfully installed Crawlee and run one of the crawlers with it.
Crawlee working
Crawlee has three types of crawlers: CheerioCrawler, PuppeteerCrawler, and PlaywrightCrawler. They all share some basic characteristics.
Every crawler is designed to visit a webpage, carry out specific tasks, save the results, navigate to the next page, and repeat this cycle until the job is finished. Each crawler must therefore respond to two queries: Where should I go? What should I do there?
The crawler can start working when these queries are resolved since most other settings are pre-configured for the crawlers.
Crawlee web scraping example
Our target for this web scraping demonstration is books.toscrape.com. We will be scraping the titles of the books listed on the website.
Open the main.js file from the src folder of your project and overwrite the following code in it:
import { PlaywrightCrawler } from 'crawlee';
const crawler = new PlaywrightCrawler({
requestHandler: async ({ page }) => {
// Waiting for book titles to load
await page.waitForSelector('h3');
// Execute a function in the browser that targets
// the book title elements and allows their manipulation
const bookTitles = await page.$$eval('h3', (els) => {
// Extract text content from the titles list
return els.map((el) => el.textContent);
});
bookTitles.forEach((text, i) => {
console.log(`Book_${i + 1}: ${text}\n`);
});
},
});
await crawler.run(['https://books.toscrape.com/']);This code is the best example of how to crawl a website using JavaScript through Crawlee's PlaywrightCrawler class.
The code first imports the PlaywrightCrawler class from the crawlee package. Then it creates a new crawler of the PlaywrightCrawler type.
Instantiating the PlaywrightCrawler class requires an options object which includes a requestHandler function. The requestHandler function is an asynchronous function executed for every page visited by the crawler.
The requestHandler function first waits for the page's <h3> elements, representing the book titles, to be rendered using the page. waitForSelector() call. The page.$$eval() method is executed in the browser's context, extracting the text content from all of the <h3> elements on the page. You can read more on the best practices of using these functions on our Javascript wait for an element to exist page. Lastly, the crawler code logs the book titles to the console.
The last line of code initiates the crawling operation using the crawler.run() method.
The following command runs the project:
npm startHere is what the code output when once you run the crawlee project:
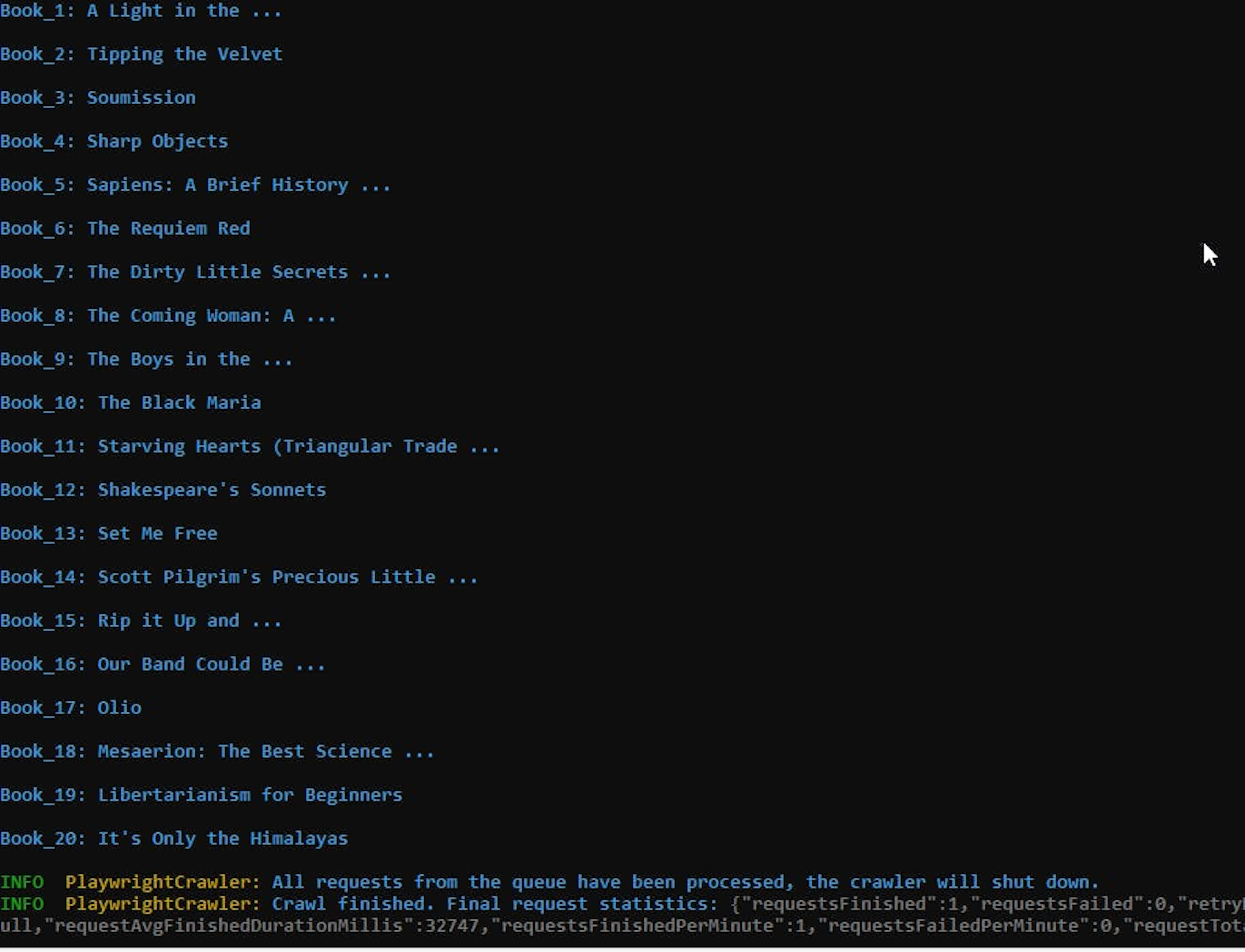
Using headless browsers with Crawlee
Crawlee supports headless control over the browsers like Chromium, Firefox, and WebKit. You can combine headless browsers with Crawlee's PuppeteerCrawler and PlaywrightCrawler classes to perform true browser crawling, making the process of crawling JavaScript generated pages and extracting valuable data much simpler.
You just need to set up a few variables, such as the browser type, start options, and context options, to use headless browsers with Crawlee.
Here is a simple code example to launch a Firefox headless instance and scrape the titles of the books using the JavaScript site crawler (as we did in the earlier section):
import { PlaywrightCrawler } from 'crawlee';
import { firefox } from 'playwright';
const crawler = new PlaywrightCrawler({
launchContext: {
// Set the Firefox browser to be used by the crawler.
launcher: firefox,
},
requestHandler: async ({ page }) => {
// Wait for the actor cards to render.
await page.waitForSelector('h3');
// Execute a function in the browser which targets
// the actor card elements and allows their manipulation.
const bookTitles = await page.$$eval('h3', (els) => {
// Extract text content from the actor cards
return els.map((el) => el.textContent);
});
bookTitles.forEach((text, i) => {
console.log(`Book_${i + 1}: ${text}\n`);
});
},
});
await crawler.run(['https://books.toscrape.com/']);Crawlee offers rich features for HTTP and real browser crawling. These features include:
HTTP crawling:
Automation configuration of browser-like headers
Replication of browser TLS fingerprints
Integrated fast HTML parsers
Zero config HTTP2 support, even for proxies
Scraping JSON APIs
Real browser crawling
JavaScript rendering and screenshots
Headless and headful support
Zero-config generation of human-like fingerprints
Automatic browser management
Use Playwright and Puppeteer with the same interface
Chrome, Firefox, Webkit and many others
How to manage proxies with Crawlee
Crawlee includes built-in support for managing proxy servers. It lets you quickly choose between a list of proxies to avoid IP-based restrictions or website blocking.
You can construct a new instance of a crawler and give in a ProxyConfiguration object with the list of proxies. You can optionally specify the rotation technique. For example, you can set your proxy to rotate every request or after a specified number of requests, both for residential proxies and datacenter ones.
Moreover, you can also use a third-party solution such as Oxylabs' Web Unblocker to ensure that your Crawlee web scraping is not blocked or restricted.
Integrating proxies with Crawlee
To integrate the proxy endpoints with Crawlee, you can use the ProxyConfiguration class. You can create an instance of this class using the constructor and provide the necessary options. You can visit the ProxyConfigurationOptions class page to learn about proxy configuration options.
The following code demonstrates setting a proxy list Crawlee. You can get a list of residential proxy endpoints by registering an account at Oxylabs' Web Unblocker page.
import { PlaywrightCrawler, ProxyConfiguration } from 'crawlee';
const proxyConfiguration = new ProxyConfiguration(
{
proxyUrls: [
'http://username:password@unblock.oxylabs.io:60000',
'https://username:password@unblock.oxylabs.io:60000',
],
},);
proxyConfiguration.isManInTheMiddle = true;
const crawler = new PlaywrightCrawler({
proxyConfiguration,
requestHandler: async ({page}) => {
// Waiting for book titles to load
await page.waitForSelector('h3');
// Execute a function in the browser that targets
// the book title elements and allows their manipulation
const bookTitles = await page.$$eval('h3', (els) => {
// Extract text content from the titles list
return els.map((el) => el.textContent);
});
bookTitles.forEach((text, i) => {
console.log(`Book_${i + 1}: ${text}\n`);
});
},
navigationTimeoutSecs: 120,
});
await crawler.run(['https://books.toscrape.com/']); The above code snippet creates a new instance of the ProxyConfiguration class by passing a list of Oxylabs’ Web Unblocker proxy endpoints. Then it sets the isManInTheMiddle property to true. This property indicates that the proxy server will be used as a Man-in-the-Middle (MITM) proxy.
After that, it uses this ProxyConfiguration object (i.e., stored in the proxyList) to initialize a Playwright crawler instance. The proxyList contains a list of the Oxylabs’ Web Unblocker proxies.
Make sure to replace the username and password with your account credentials.
The rest of the crawler code remains the same as we wrote in the previous example.
What is Crawlee?
Crawlee is a Node.JS package that offers a straightforward and adaptable interface for web scraping and browser automation. Users can retrieve web pages, apply CSS selectors to extract data from them, and navigate the DOM tree to follow links and scrape several sites.
Crawlee is a versatile tool that provides a uniform interface for web crawling via HTTP and headless browser approaches. It has an integrated persistent queue for handling URLs to crawl in either breadth-first or depth-first order.
Users can also benefit from integrated proxy rotation and session management, pluggable storage solutions for files and tabular data, and other features. Moreover, Crawlee offers hook-based customized lifecycles, programmable routing, error handling, and retries.
For speedy project setup, a CLI is accessible, and Dockerfiles are included to streamline deployment. Crawlee is a robust and effective tool for web scraping and crawling written in TypeScript using generics.
The benefits of using Crawlee for web scraping and browser automation
The following are some of the most common pros of using Crawlee web scraping framework for browser automation and web scraping:
Single interface: Crawlee offers a single interface for headless browser crawling as well as HTTP crawling, making it simple to switch between the two based on your needs.
Customizable lifecycles: Crawlee allows developers to alter their crawlers' lifecycles using hooks. These hooks can be used to carry out operations before or after specific events, such as before a request is made or after data is collected.
Pluggable storage: Crawlee supports pluggable storage methods for both tabular data and files, making storing and managing the extracted data extra simple.
Proxy rotation and session management: Crawlee has built-in support for these features, which can be used to manage complex web interactions and maintain reliable web access.
Configurable request routing, error handling, and retries: Crawlee enables developers to control request routing, deal with errors, and retry requests as needed, making it simpler to handle edge cases and unexpected issues.
Docker-capable: Crawlee comes with Dockerfiles that let developers rapidly and easily deploy their web crawler JS to production environments.
Conclusion
Crawlee is a powerful web scraping and browser automation solution with a unified interface for HTTP and headless browser crawling. It supports pluggable storage, headless browsing, automatic scaling, integrated proxy rotation and session management, customized lifecycles, and much more. Crawlee is an effective solution for developers and data analysts who want to automate browser actions and crawl JavaScript website data effectively.
Compare Crawlee against other best web crawlers and see whether this particular software fits your project needs best. Also, since Crawlee has built-in support for managing proxies, you can test it with our free proxy server list.
For your convenience, we also have this article presented on our GitHub. Have questions about this tutorial or any other web scraping topic? Don’t hesitate to contact us at hello@oxylabs.io or via our 24/7 live chat.
Forget about complex web scraping processes
Choose Oxylabs' advanced web intelligence collection solutions to gather real-time public data hassle-free.
About the author
Yelyzaveta Hayrapetyan
Former Senior Technical Copywriter
Yelyzaveta Hayrapetyan was a Senior Technical Copywriter at Oxylabs. After working as a writer in fashion, e-commerce, and media, she decided to switch her career path and immerse in the fascinating world of tech. And believe it or not, she absolutely loves it! On weekends, you’ll probably find Yelyzaveta enjoying a cup of matcha at a cozy coffee shop, scrolling through social media, or binge-watching investigative TV series.
All information on Oxylabs Blog is provided on an "as is" basis and for informational purposes only. We make no representation and disclaim all liability with respect to your use of any information contained on Oxylabs Blog or any third-party websites that may be linked therein. Before engaging in scraping activities of any kind you should consult your legal advisors and carefully read the particular website's terms of service or receive a scraping license.
Related articles

Cheerio vs. Puppeteer: Which Should You Use for Web Scraping?

Shinthiya Nowsain Promi
2026-06-23



List Crawling in Python: Tools, Tips, and Techniques

Danielė Virinaitė
2026-06-17

Get the latest news from data gathering world
Scale up your business with Oxylabs®
Proxies
Advanced proxy solutions
Data Collection
Datasets
Resources
Innovation hub
Forget about complex web scraping processes
Choose Oxylabs' advanced web intelligence collection solutions to gather real-time public data hassle-free.