175M+ ethically sourced IPs built for the highest reliability.
High-speed, cost-effective proxies built for any scraping workload.
Premium static residential proxies from trusted ASNs for most difficult targets.
Dedicated IPs from premium ASNs for demanding scraping.

AI-powered proxy solution for optimized web scraping performance.

20M+ IP addresses from real mobile devices for precise targeting.

Free Chrome proxy manager extension that works with any proxy provider.

Free Android proxy manager app that works with any proxy provider.

Free community-driven tools to improve your web scraping projects.
Web Scraper API
All-in-one web data collection platform for every stage of web scraping.
Fast Search API
Ultra-fast organic search results scraper tailored for AI workflows.
Headless Browser
Advanced browser automation solution for AI agents and scraping.
AI Studio
A suite of AI-powered tools for various scraping projects.

Documentation
All features, parameters, and integration details, backed by code samples in every coding language.
Tutorials, samples, and guides.
Latest fixes and features.






![]() AI Summary:
AI Summary:
This step-by-step guide shows how to extract job data from Indeed using Oxylabs' Web Scraper API and Python. It covers structured data extraction with XPath and CSS selectors, iterating through job listings, and exporting results to JSON and CSV. The guide also includes an alternative approach using Oxylabs' residential proxies for those who prefer building their own scraper without an API.
In an era where data drives decisions, accessing up-to-date job market information is crucial. Indeed.com, a leading job portal, offers extensive insights into job openings, popular roles, and company hiring trends. However, manually collecting this job data can be tedious and time-consuming. This is where web scraping, supported by the use of various proxies comes in as a game-changer, and Oxylabs' Web Scraper API makes this task seamless, efficient, and reliable.
Why scrape Indeed job postings?
Scraping Indeed.com allows businesses, analysts, and job seekers to stay ahead in the competitive job market. From tracking the most popular jobs to understanding industry demands, the insights gained from job postings and job details on Indeed are invaluable. Automated data collection through scraping not only saves time but also provides a more comprehensive view of the job landscape. Job scraping is a technique widely used by HR professionals.
The tool: Oxylabs’ Web Scraper API
Oxylabs' Web Scraper API is designed to handle complex web scraping tasks with ease. It bypasses anti-bot measures, ensuring you get the job data you need without interruption. Whether you're looking to scrape job titles, company names, or detailed job descriptions, Oxylabs simplifies the process.
This step-by-step tutorial will explain how to extract job data from Indeed.com, focusing on extracting key job details like job titles, descriptions, and company names.
Try for free
Get a free trial to test our Web Scraper API.
Up to 2K results
No credit card required
Project setup
You can find the following code on our GitHub.
Prerequisites
Before diving into the code to scrape indeed, ensure you have Python 3.8 or newer installed on your machine. This guide is written for Python 3.8+, so having a compatible version is crucial.
Creating a virtual environment
A virtual environment is an isolated space where you can install libraries and dependencies without affecting your global Python setup. It's a good practice to create one for each project. Here's how to set it up on different operating systems:
python -m venv indeed_env #Windows
python3 -m venv indeed_env #Mac and LinuxReplace indeed_env with the name you'd like to give to your virtual environment.
Activating the virtual environment
Once the virtual environment is created, you'll need to activate it:
.\indeed_env\Scripts\Activate #Windows
source indeed_env/bin/activate #Mac and LinuxYou should see the name of your virtual environment in the terminal, indicating that it's active.
Installing required libraries
We'll use the requests library for this project to make HTTP requests. Install it by running the following command:
pip install requests pandasAnd there you have it! Your project environment is ready for Indeed data scraping using Oxylabs' Indeed Scraper API. In the following sections, look into the Indeed structure.
Overview of Web Scraper API
Oxylabs' Web Scraper API allows you to extract data from many complex websites easily.
The following is a simple example that shows how Scraper API works.
# scraper_api_demo.py
import requests
payload = {
"source": "universal",
"url": "https://www.indeed.com"
}
response = requests.post(
url="https://realtime.oxylabs.io/v1/queries",
json=payload,
auth=("username", "password"),
)
print(response.json())As you can see, the payload is where you would inform the API what and how you want to scrape.
Save this code in a file scraper_api_demo.py and run it. You will see that the entire HTML of the page will be printed, along with some additional information from Scraper API.
In the following section, let's examine various parameters we can send in the payload.
Scraper API parameters
The most critical parameter is source. For IMDb, set the source as universal, a general-purpose source that can handle all domains.
The parameter url is self-explanatory, a direct link to the page you want to scrape.
The example code in the earlier section has only these two parameters. The result is, however, the entire HTML of the page.
Instead, what we need is parsed data. This is where the parameter parse comes into the picture. When you send parse as True, you must also send one more parameter —parsing_instructions. Combined, these two parameters allow you to get parsed data in any structure you like.
The following allows you to parse the page title and retrieve results in JSON:
"title": {
"_fns": [
{
"_fn": "xpath_one",
"_args": ["//title/text()"]
}
]
}
},The key _fns indicates a list of functions, which can contain one or more functions indicated by the "_fn" key, along with the arguments.
In this example, the function is xpath_one, which takes an XPath and returns one matching element. On the other hand, the function xpath returns all matching elements.
On similar lines are css_one and css functions that use CSS selectors instead of XPath.
For a complete list of available functions, see the Scraper API documentation.
The following code prints the title of the Indeed page:
# indeed_title.py
import requests
payload = {
"source": "universal",
"url": "https://www.indeed.com",
"render": "html",
"parse": True,
"parsing_instructions": {
"title": {
"_fns": [
{
"_fn": "xpath_one",
"_args": ["//title/text()"]
}
]
}
}
}
response = requests.post(
url="https://realtime.oxylabs.io/v1/queries",
json=payload,
auth=("username", "password")
)
print(response.json()["results"][0]["content"])Run this file to get the title of Indeed.
In the next section, we will scrape jobs from a list.
Scraping Indeed job postings
Before scraping a page, we need to examine the page structure.
Open the Job search results in Chrome, right-click the job listing, and select Inspect.
Move around your mouse until you can precisely select one job list item and related data.
You can use the following CSS selector to select one job listing:
.job_seen_beaconWe can iterate over each matching item and get the specific job data points such as job title, company name, location, salary range, date posted, and job description.
First, create the placeholder for job listing as follows:
payload = {
"source": "universal",
"url": "https://www.indeed.com/jobs?q=work+from+home&l=San+Francisco%2C+CA",
"render": "html",
"parse": True,
"parsing_instructions": {
"job_listings": {
"_fns": [
{
"_fn": "css",
"_args": [".job_seen_beacon"]
}
],Note the use of the function css. It means that it will return all matching elements.
Next, we can use reserved property _items to indicate that we want to iterate over a list, further processing each list item separately.
It will allow us to use concatenating to the path already defined as follows:
"job_listings": {
"_fns": [
{
"_fn": "css",
"_args": [".job_seen_beacon"]
}
],
"_items": {
"job_title": {
"_fns": [
{
"_fn": "xpath_one",
"_args": [".//h2[contains(@class,'jobTitle')]/a/span/text()"]
}
]
},
"company_name": {
"_fns": [
{
"_fn": "xpath_one",
"_args": [".//span[@data-testid='company-name']/text()"]
}
]
},Similarly, we can add other selectors. After adding other details, here are the job_search_payload.json file contents:
{
"source": "universal",
"url": "https://www.indeed.com/jobs?q=work+from+home&l=San+Francisco%2C+CA",
"render": "html",
"parse": True,
"parsing_instructions": {
"job_listings": {
"_fns": [
{
"_fn": "css",
"_args": [".job_seen_beacon"]
}
],
"_items": {
"job_title": {
"_fns": [
{
"_fn": "xpath_one",
"_args": [".//h2[contains(@class,'jobTitle')]/a/span/text()"]
}
]
},
"company_name": {
"_fns": [
{
"_fn": "xpath_one",
"_args": [".//span[@data-testid='company-name']/text()"]
}
]
},
"location": {
"_fns": [
{
"_fn": "xpath_one",
"_args": [".//div[@data-testid='text-location']//text()"]
}
]
},
"salary_range": {
"_fns": [
{
"_fn": "xpath_one",
"_args": [".//div[contains(@class, 'salary-snippet-container') or contains(@class, 'estimated-salary')]//text()"]
}
]
},
"date_posted": {
"_fns": [
{
"_fn": "xpath_one",
"_args": [".//span[@class='date']/text()"]
}
]
},
"job_description": {
"_fns": [
{
"_fn": "xpath_one",
"_args": ["normalize-space(.//div[@class='job-snippet'])"]
}
]
}
}
}
}
}A good way to organize your code is to save the payload as a separator JSON file. It will allow you to keep your Python file as short as follows:
# parse_jobs.py
import requests
import json
payload = {}
with open("job_search_payload.json") as f:
payload = json.load(f)
response = requests.post(
url="https://realtime.oxylabs.io/v1/queries",
json=payload,
auth=("username", "password"),
)
print(response.status_code)
with open("result.json", "w") as f:
json.dump(response.json(), f, indent=4)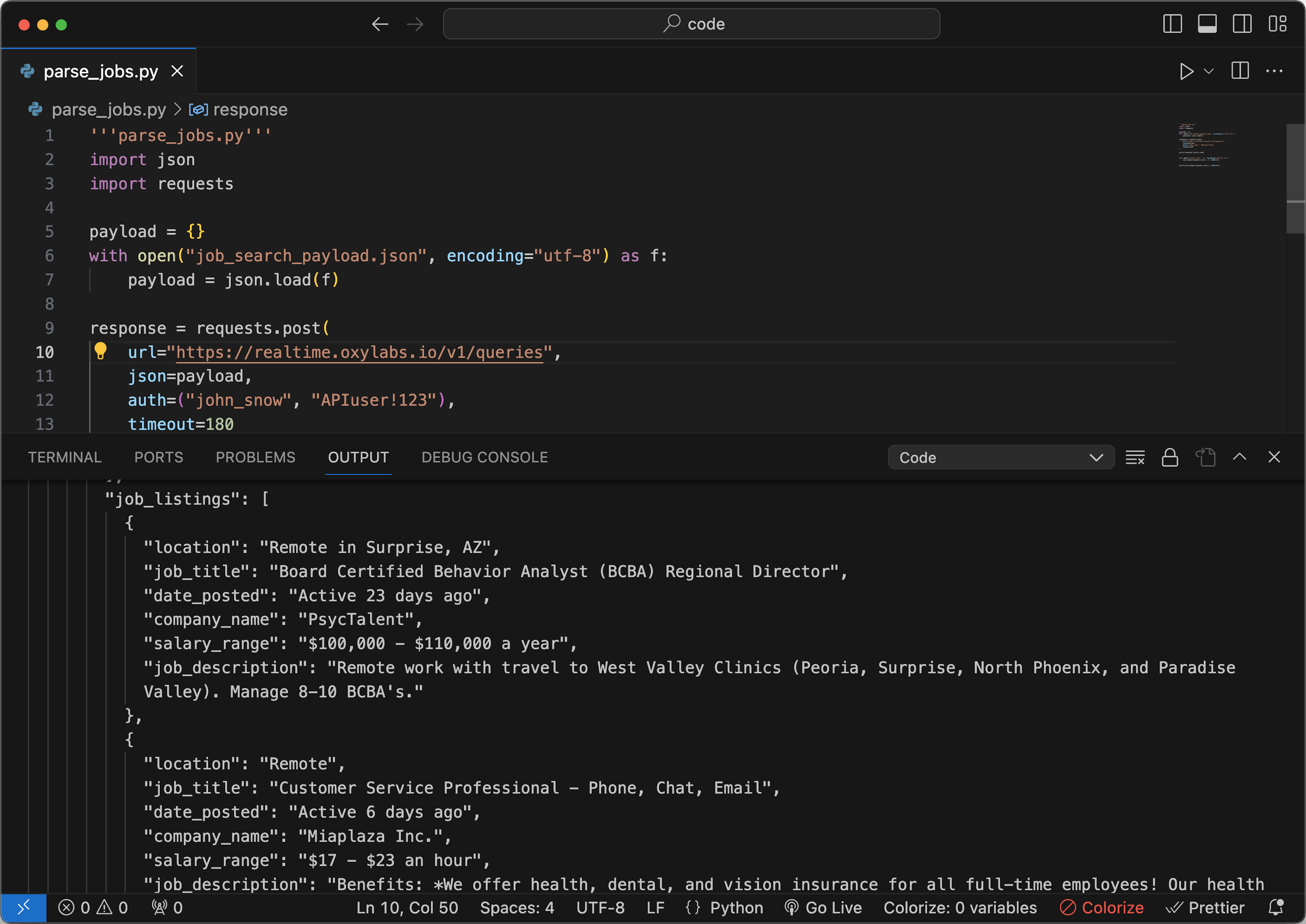
Exporting to JSON and CSV
The output of Scraper API is a JSON. You can save the extracted job listing as JSON directly.
You can use a library such as Pandas to save the job data as CSV.
Remember that the parsed data is stored in the content inside results.
As we created the job listings in the key job_listings, we can use the following snippet to save the extracted indeed data:
# parse_jobs.py
import pandas as pd
# save the indeed data as a json file and then save to CSV
df = pd.DataFrame(response.json()["results"][0]["content"]["job_listings"])
df.to_csv("job_search_results.csv", index=False)Indeed scraping with proxies
If you’d like to try building an Indeed job scraper without an API, you can use Python's requests library and Oxylabs’ Residential Proxies. Below is a simple code example you can use for your future project:
1. Prerequisites
Install required Python libraries:
pip install requests beautifulsoup4Then, set up your Oxylabs proxy credentials that you can easily get by signing up and selecting a suitable plan through our self-service dashboard.
2. Making the the request
Let’s now use Python requests library and Oxylabs’ proxies to scrape Indeed job postings for "data scientist" roles in "New York".
import requests
from bs4 import BeautifulSoup
# Replace these with your Oxylabs proxy credentials
USERNAME = 'PROXY_USERNAME' # Replace with your Oxylabs username
PASSWORD = 'PROXY_PASSWORD' # Replace with your Oxylabs password
# Set up the proxies
proxies = {
'http': f'http://{USERNAME}:{PASSWORD}@pr.oxylabs.io:7777',
'https': f'https://{USERNAME}:{PASSWORD}@pr.oxylabs.io:7777'
}
# Define the search query for Indeed.com
query = 'data scientist'
location = 'New York'
indeed_url = f'https://www.indeed.com/jobs?q={query.replace(" ", "+")}&l={location.replace(" ", "+")}'
# Set headers to mimic a browser
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'
}
# Send the request through the proxy
try:
response = requests.get(indeed_url, headers=headers, proxies=proxies)
response.raise_for_status() # Raise HTTPError for bad responses (4xx or 5xx)
# Parse the response
soup = BeautifulSoup(response.text, 'html.parser')
# Extract job titles and links
results = []
for job_card in soup.find_all('div', class_='job_seen_beacon'): # Targeting each job card
title_element = job_card.find('h2', class_='jobTitle')
company_element = job_card.find('span', class_='companyName')
if title_element and company_element:
title = title_element.text.strip()
company = company_element.text.strip()
link_element = job_card.find('a', href=True) # Find the <a> tag with href
if link_element:
relative_link = link_element['href']
absolute_link = f'https://www.indeed.com{relative_link}' # Construct absolute URL
else:
absolute_link = "Link not found"
results.append({'title': title, 'company':company, 'link': absolute_link})
# Print the results
for idx, res in enumerate(results[:5], 1): # Limit to the first 5 results for brevity
print(f"{idx}. {res['title']} - {res['company']}")
print(f" {res['link']}")
except requests.exceptions.RequestException as e:
print(f"Request failed: {e}")
print(f"Response Content: {response.text if 'response' in locals() else 'No response'}")This script extracts the job title, company and link of the job posting and prints them to the console. Note that the HTML structure of Indeed can change, so the selectors might need adjustments. It is important to check the selectors often.
3. Saving results to a file
If you'd like to save the scraped results to a file for further analysis or sharing, you can extend the script as follows:
import csv
# Save the results to a CSV file
output_file = 'indeed_results.csv'
with open(output_file, 'w', newline='', encoding='utf-8') as file:
writer = csv.writer(file)
writer.writerow(['Title', 'Company', 'Link']) # Header row
for res in results:
writer.writerow([res['title'], res['company'], res['link']])
print(f"Results saved to {output_file}")Scraping methods comparison
| Approach | Key Features | Advantages | Limitations | Best For |
|---|---|---|---|---|
| No Proxies | • Basic HTTP requests • Single IP address • Simple request handling |
• Easy to implement • No additional costs • Minimal setup • Small-scale scraping |
• High risk of blocks • Limited request volume • No geo-targeting • Poor scalability |
• Small projects • Non-restricted content • Testing and development |
| With proxies | • Rotating IP addresses • Geo-location targeting • Session management |
• High success rates • Scalability • Anti-ban protection • Geographic flexibility |
• Proxy management • More costs • Complex setup • Needs monitoring |
• Large-scale operations • Competitor monitoring • Global data collection |
| Scraper APIs | • Pre-built infrastructure • JavaScript rendering • Parsing • CAPTCHA handling |
• Ready-to-use solution • Maintenance-free • Technical support |
• Higher costs • Limited customization • API-specific limitations • Dependency on provider |
• Complex websites • JavaScript-heavy sites • Resource-constrained teams |
Conclusion
Utilizing Web Scraper API to perform Indeed web scraping simplifies the task, whereas, without it, the job can be rather difficult and daunting. Notably, you can even use GUI tools such as Postman or Insomnia to scrape Indeed. You only need to send a POST request to the API with the desired payload. For even more efficient scraping, you can buy proxies to enhance your performance and maintain reliable access. Feel free to check out our general blog post on scraping job postings in 2024 as well as discover our Job Postings Datasets.
The detailed documentation on Web Scraper API is available here, and if you’d like to try our Web Scraper API, you can do so for free by registering on the dashboard.
Frequently asked questions
Is it legal to scrape Indeed job postings?
While web scraping publicly accessible data is generally legal, you must always check the website's terms of service to make sure you don’t violate any rules when collecting the needed information. For example, excessive scraping that overloads their servers or infringes on copyright is likely prohibited and will get you blocked.
Can you scrape Indeed using headless browsers such as Playwright?
Is there a public API for Indeed.com?
About the author

Danielius Radavicius
Former Copywriter
Danielius Radavičius was a Copywriter at Oxylabs. Having grown up in films, music, and books and having a keen interest in the defense industry, he decided to move his career toward tech-related subjects and quickly became interested in all things technology. In his free time, you'll probably find Danielius watching films, listening to music, and planning world domination.
All information on Oxylabs Blog is provided on an "as is" basis and for informational purposes only. We make no representation and disclaim all liability with respect to your use of any information contained on Oxylabs Blog or any third-party websites that may be linked therein. Before engaging in scraping activities of any kind you should consult your legal advisors and carefully read the particular website's terms of service or receive a scraping license.
Related articles




Get premium Oxylabs proxies
Maintain reliable web access and handle CAPTCHAs with 177M+ premium paid proxies located in 195 countries.
Try free proxies
Claim your free proxies for lifetime by registering on the Oxylabs dashboard.

Get the latest news from data gathering world
Scale up your business with Oxylabs®
Proxies
Advanced proxy solutions
Data Collection
Datasets
Resources
Innovation hub
Get premium Oxylabs proxies
Maintain reliable web access and handle CAPTCHAs with 177M+ premium paid proxies located in 195 countries.
Try free proxies
Claim your free proxies for lifetime by registering on the Oxylabs dashboard.