175M+ ethically sourced IPs built for the highest reliability.
High-speed, cost-effective proxies built for any scraping workload.
Premium static residential proxies from trusted ASNs for most difficult targets.
Dedicated IPs from premium ASNs for demanding scraping.

AI-powered proxy solution for optimized web scraping performance.

20M+ IP addresses from real mobile devices for precise targeting.

Free Chrome proxy manager extension that works with any proxy provider.

Free Android proxy manager app that works with any proxy provider.

Free community-driven tools to improve your web scraping projects.
Web Scraper API
All-in-one web data collection platform for every stage of web scraping.
Fast Search API
Ultra-fast organic search results scraper tailored for AI workflows.
Headless Browser
Advanced browser automation solution for AI agents and scraping.
AI Studio
A suite of AI-powered tools for various scraping projects.

Documentation
All features, parameters, and integration details, backed by code samples in every coding language.
Tutorials, samples, and guides.
Latest fixes and features.





Web Scraping With Cheerio and Node.js: Step-by-Step Guide


Maryia Stsiopkina
Last updated on
2024-07-23
5 min read
![]() AI Summary:
AI Summary:
This guide demonstrates how to build a web scraper using Node.js, Cheerio, and Axios. It covers making HTTP requests, parsing HTML, extracting data, handling pagination, saving results to CSV/JSON, and implementing caching for performance.
Web scraping is a powerful tool for efficiently gathering data from the internet, useful for academic research, market analysis, content aggregation, and more. This guide will show you how to set up a web scraping project using Cheerio and Axios in Node.js.
Cheerio, an HTML parsing library, and Axios, a versatile HTTP client, work together to simplify web scraping. Web scraping libraries like Cheerio’s jQuery-like API make DOM manipulation intuitive, while Axios handles HTTP requests efficiently with features like automatic JSON transformation and promise-based asynchronous operations.
In this tutorial, you'll learn how to make HTTP requests with Axios, parse and manipulate HTML data with the Cheerio library, and save the extracted data in formats such as CSV or JSON. We’ll also discuss optimizing the scraper’s performance with Cheerio cache implementation.
You’ll learn:
Understanding of Cheerio web scraping
Setting up a Node.js project for web scraping
Making HTTP requests with Axios
Extracting and manipulating the HTML format with Cheerio
Saving scraped data to CSV and JSON formats
Implementing caching with Cheerio
What is Cheerio?
Cheerio is a fast and flexible JavaScript library built on htmlparser2. It provides a jQuery-like API for manipulating DOM elements on the web server side, making it an excellent choice for web scraping tasks. Cheerio offers robust APIs for extracting data and parsing HTML efficiently. Cheerio web scraping is widely used for various tasks due to its simplicity and efficiency – you can see for yourself how it compares to other JavaScript libraries.
Primary use cases
Cheerio is primarily used for:
Traversing and parsing HTML documents
Extracting specific elements from content
Manipulating DOM elements on the server side
What is Axios
Axios is a promise-based HTTP client for Node.js and the browser. It simplifies making HTTP requests with JavaScript, allowing you to fetch web pages using XMLHttpRequest. Axios supports all modern browsers, including Chrome and Edge, and offers additional features for response handling and request processing.
Primary Use Cases:
Axios is primarily used for:
Making GET requests
Handling responses and errors
Intercepting requests and responses
Automatic JSON transformations
Pre-requisites
Before we get started, it's important to recognize the ethical and legal considerations involved in web scraping. Adhering to a website's web scraping policies ensures that your practices are respectful and compliant.
For this tutorial, we’ll target Oxylabs sandbox, a website specifically built for testing web scrapers. Before starting, we assume the following prerequisites:
Basic knowledge of Node.js and JavaScript.
Node.js (v14+) and npm installed on your system. You can check using the following commands:
node -v
npm -v An IDE or text editor, such as VS Code or Atom, installed on your system.
Familiarity with basic commands of the Command Line Interface (CLI).
Step-by-step tutorial
Now, let’s dive straight into the step-by-step demo tutorial.
Step 1. Setting up the environment
Create a new Node.js project
Open your terminal window and create a new project directory. Then, move to that directory and initialize a new Node.js project using the following commands:
mkdir web-scraper-cheerio
cd web-scraper-cheerio
npm init -yThis will create a new project in your project directory, and all the necessary Node.js modules will be added to the directory.
Install required packages
After creating the new project, install all the required packages using the following command:
npm install cheerio axioscheerio: Parses the HTML content and provides a jQuery-like API for traversing and manipulating the DOM.
axios: Used to make HTTP requests to fetch HTML content.
Step 2. Code in action
After all the configuration settings are complete, you can start writing your code by creating a .js file in your project directory, such as `index.js`.
In this section, we will go through the code step by step. But first, have a look at the illustration image, outlining all the coding steps.
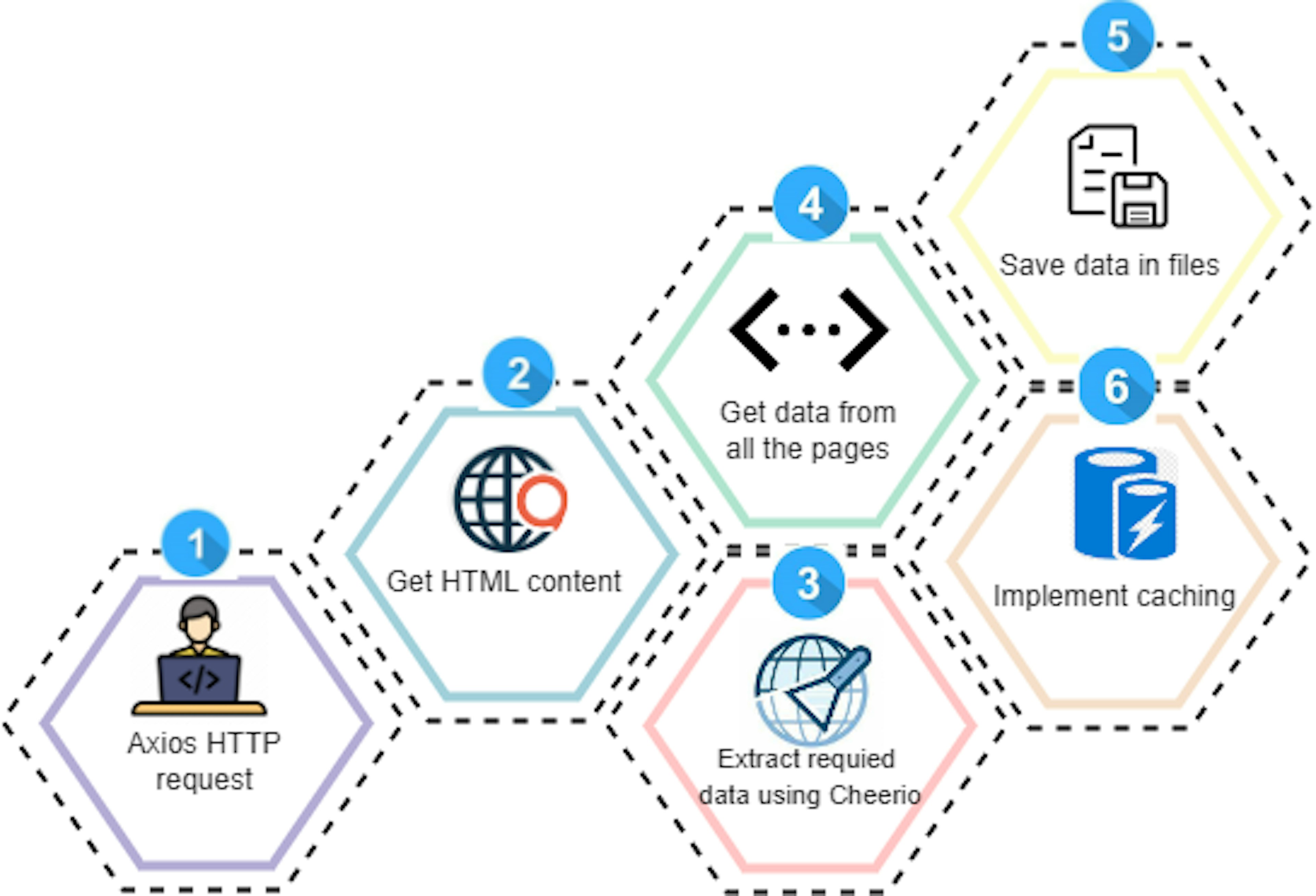
Import the required modules
To start with, you need to import all the required modules in your JavaScript code like this:
const axios = require('axios');
const cheerio = require('cheerio');
const fs = require('fs');
const path = require('path');The file system (fs) module provides essential file manipulation functionalities, whereas the path module ensures consistent handling of file paths across different operating systems.
Fetch HTML content using Axios
To scrape data from a website, you need to send an HTTP request to the web page and retrieve its HTML content. Axios in Node.js handles this efficiently, making it easy to send GET requests and obtain HTML content.
The fetchHTML() function uses the Axios library to make an HTTP GET request and fetch the information from our target website.
async function fetchHTML(url) {
try {
const { data } = await axios.get(url);
console.log(`Fetched from network: ${url}`);
return data;
}
catch (error) {
console.error('Error fetching the HTML:', error);
throw error;
}
}In this function, the get() method is used to fetch the HTML of the target URL. The returned HTML is then saved and returned to the calling point. The function is made asynchronous to enhance efficiency and speed.
In JavaScript, asynchronous programming is essential for handling time-consuming processes such as network requests or file I/O. Using await with async functions allows for writing cleaner and more manageable asynchronous code flows.
Extract data using Cheerio
After fetching the HTML content, Cheerio can be used to extract the desired information. It provides a jQuery-like API that simplifies web data extraction and manipulation.
Before we start the extraction, let’s look at the HTML of our sample target page:
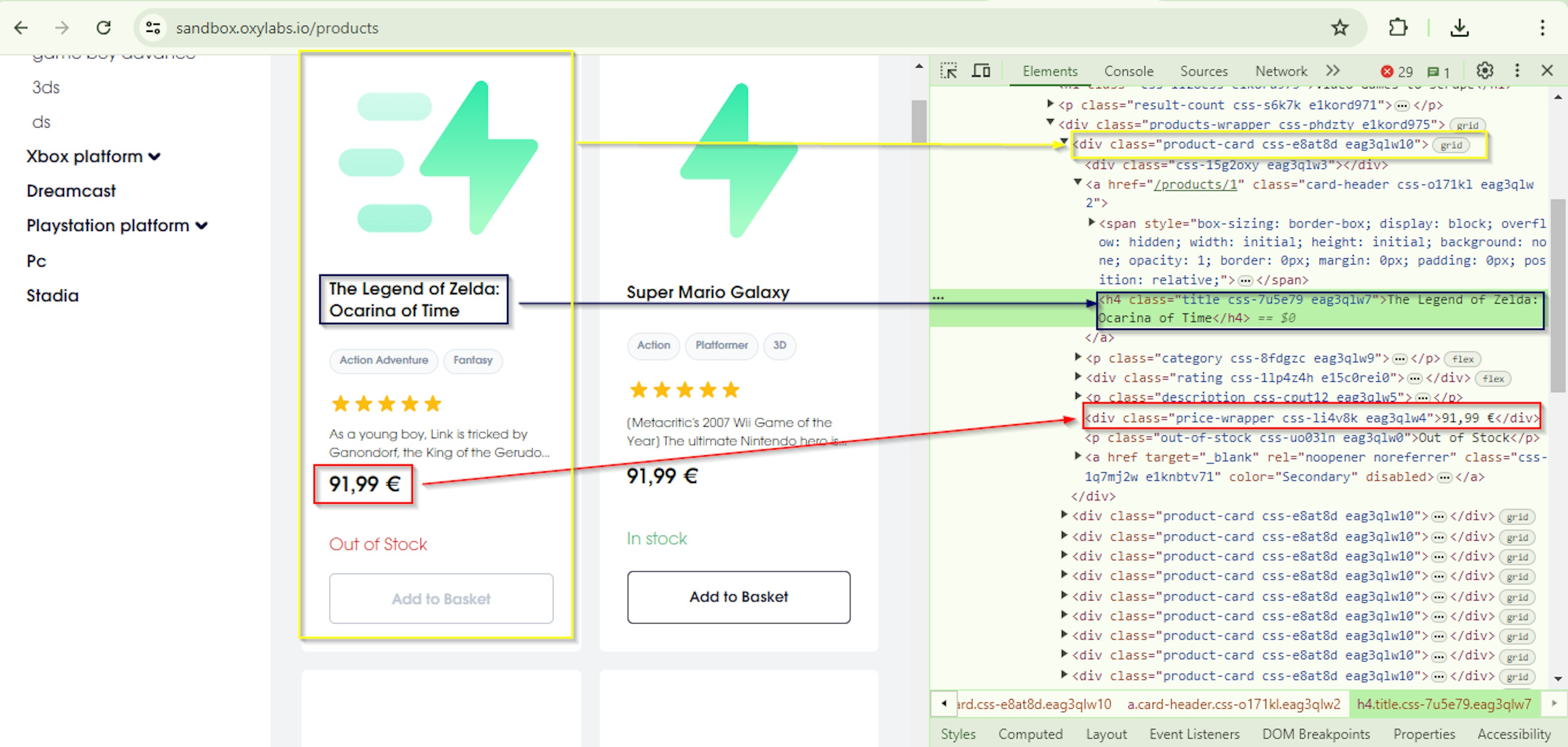
We need to scrape data for the book titles and their prices; please note the selectors of the container elements for the titles and prices. The following extractProducts() function extracts the titles and their prices for all the products in the fetched HTML content:
function extractProducts(html) {
const $ = cheerio.load(html);
const products = [];
$('.product_card').each((index, element) => {
const name = $(element).find('.title').text().trim();
const price = $(element).find('.price-wrapper').text().trim();
products.push({ name, price });
});
return products;
}This function loads the HTML content using Cheerio load() function and then parses the data using the relevant CSS selectors. Lastly, it pushes each title and price to the products collection and returns to the caller.
Save the data to CSV and JSON file
You can save the extracted data in JSON and CSV format, which will help analyze the scraped data later.
// File paths for storing data
const jsonFilePath = path.join(__dirname, 'products.json');
const csvFilePath = path.join(__dirname, 'products.csv');
function saveToJSON(data) {
fs.writeFileSync(jsonFilePath, JSON.stringify(data, null, 2));
console.log(`Data saved to products.json`);
}
// Function to save data to CSV file
function saveToCSV(data) {
const csvHeader = 'Name,Price\n';
const csvRows = data.map(product => `${product.name.replace(/,/g, '')},${product.price}`).join('\n');
fs.writeFileSync(csvFilePath, csvHeader + csvRows);
console.log(`Data saved to products.csv`);
}
}Implementing Cache in Cheerio
The caching mechanism with Cheerio can significantly enhance the performance and efficiency of web scraping operations by storing and reusing previously retrieved HTML content.
Implementing a Cheerio cache reduces server load and bandwidth usage by minimizing redundant HTTP requests to the same target server. By caching fetched HTML pages, we can avoid repeated network requests, speed up the scraping process, and reduce completion time. This approach ensures a more streamlined and optimized scraping workflow, reducing latency and improving overall throughput.
The fetchHTML function utilizes a cache to store and retrieve HTML content. If the URL is already in the Cache, it returns the cached HTML instead of making a new request. This approach helps in reducing redundant network requests and improves efficiency.
// Cache to store fetched pages
const cache = {};
// Function to fetch HTML with caching
async function fetchHTML(url) {
if (cache[url]) {
console.log(`Fetching from cache: ${url}`);
return cache[url];
}
try {
const { data } = await axios.get(url);
cache[url] = data;
console.log(`Fetched from network: ${url}`);
return data;
} catch (error) {
console.error('Error fetching the HTML:', error);
throw error;
}
}Handling pagination
Since the target website has multiple web pages, the scrapeProducts function recursively scrapes product information from these pages.
// Function to scrape products from multiple pages
async function scrapeProducts(url, allProducts = []) {
try {
const html = await fetchHTML(url);
const products = extractProducts(html);
allProducts = allProducts.concat(products);
// Save data to CSV and JSON files
saveToJSON(allProducts);
saveToCSV(allProducts);
// Check if there is a next page
const $ = cheerio.load(html);
const nextPage = $('.next > a').attr('href');
if (nextPage.indexOf("#") == -1) {
const nextUrl = new URL(nextPage, url).href;
await scrapeProducts(nextUrl, allProducts);
}
} catch (error) {
console.error('Failed to scrape the website:', error);
}
}The scrapePoducts() function leverages the fetchHTML() and extractProducts() functions to scrape the base target. It saves the data in JSON and CSV formats and goes on to check if there are any more pages to scrape. A simple check is looking for the next button on the page. If there is one (which means there are more pages to scrape), it recursively calls itself and scrapes for the next page. This process continues until all the pages are scraped successfully.
Step 3. Compiling and running the code
The complete code, after combining all the code components discussed earlier, is as follows:
const axios = require('axios');
const cheerio = require('cheerio');
const fs = require('fs');
const path = require('path');
// File paths for storing data
const jsonFilePath = path.join(__dirname, 'products.json');
const csvFilePath = path.join(__dirname, 'products.csv');
// Cache to store fetched pages
const cache = {};
// Function to fetch HTML with caching
async function fetchHTML(url) {
if (cache[url]) {
console.log(`Fetching from cache: ${url}`);
return cache[url];
}
try {
const { data } = await axios.get(url);
cache[url] = data;
console.log(`Fetched from network: ${url}`);
return data;
} catch (error) {
console.error('Error fetching the HTML:', error);
throw error;
}
}
// Function to extract product data
function extractProducts(html) {
const $ = cheerio.load(html);
const products = [];
$('.product-card').each((index, element) => {
const name = $(element).find('.title').text().trim();
const price = $(element).find('.price-wrapper').text().trim();
products.push({ name, price });
});
return products;
}
// Function to save data to JSON file
function saveToJSON(data) {
fs.writeFileSync(jsonFilePath, JSON.stringify(data, null, 2));
console.log(`Data saved to products.json`);
}
// Function to save data to CSV file
function saveToCSV(data) {
const csvHeader = 'Name,Price\n';
const csvRows = data.map(product => `${product.name.replace(/,/g, '')},${product.price}`).join('\n');
fs.writeFileSync(csvFilePath, csvHeader + csvRows);
console.log(`Data saved to products.csv`);
}
// Function to scrape products from multiple pages
async function scrapeProducts(url, allProducts = []) {
try {
const html = await fetchHTML(url);
const products = extractProducts(html);
allProducts = allProducts.concat(products);
// Save data to CSV and JSON files
saveToJSON(allProducts);
saveToCSV(allProducts);
// Check if there is a next page
const $ = cheerio.load(html);
const nextPage = $('.next > a').attr('href');
if (nextPage.indexOf("#") == -1) {
const nextUrl = new URL(nextPage, url).href;
await scrapeProducts(nextUrl, allProducts);
}
} catch (error) {
console.error('Failed to scrape the website:', error);
}
}
(async () => {
const baseURL = 'https://sandbox.oxylabs.io/products';
await scrapeProducts(baseURL);
})();You can run the JavaScript code using the following command:
node index.js Let’s move forward and look at the output on the console as well as CSV and JSON file:
Console:
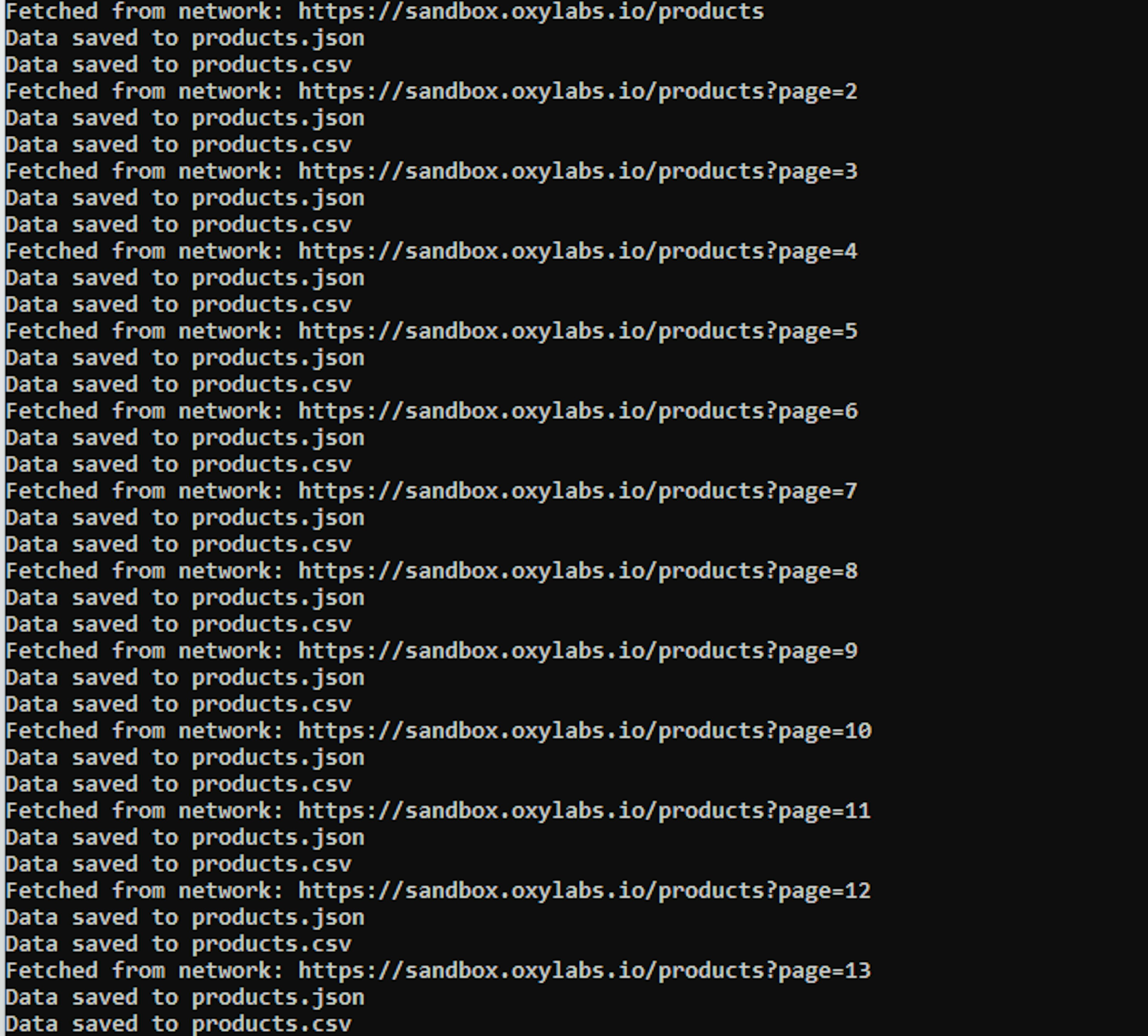
CSV:

JSON:

Conclusion
In this guide, we explored how to use Cheerio and Axios in Node.js to scrape web pages. You learned how to set up a Node.js project and install necessary packages, fetch HTML content using Axios, extract and manipulate data using Cheerio, save it in CSV or JSON formats, and implement caching to enhance Cheerio scraper performance.
By following these steps, you now have the foundational skills to build efficient web scrapers. Experiment with different websites, refine your techniques, and take on advanced challenges like handling infinite scroll and CAPTCHAs. With practice, you'll enhance your scraping capabilities and add significant value to your projects.
Forget about complex web scraping processes
Choose Oxylabs' advanced web intelligence collection solutions to gather real-time public data hassle-free.
About the author
Maryia Stsiopkina
Former Senior Content Manager
Maryia Stsiopkina was a Senior Content Manager at Oxylabs. As her passion for writing was developing, she was writing either creepy detective stories or fairy tales at different points in time. Eventually, she found herself in the tech wonderland with numerous hidden corners to explore. At leisure, she does birdwatching with binoculars (some people mistake it for stalking), makes flower jewelry, and eats pickles.
All information on Oxylabs Blog is provided on an "as is" basis and for informational purposes only. We make no representation and disclaim all liability with respect to your use of any information contained on Oxylabs Blog or any third-party websites that may be linked therein. Before engaging in scraping activities of any kind you should consult your legal advisors and carefully read the particular website's terms of service or receive a scraping license.
Related articles

Cheerio vs. Puppeteer: Which Should You Use for Web Scraping?

Shinthiya Nowsain Promi
2026-06-23



List Crawling in Python: Tools, Tips, and Techniques

Danielė Virinaitė
2026-06-17

Get the latest news from data gathering world
Scale up your business with Oxylabs®
Proxies
Advanced proxy solutions
Data Collection
Datasets
Resources
Innovation hub
Forget about complex web scraping processes
Choose Oxylabs' advanced web intelligence collection solutions to gather real-time public data hassle-free.