






Maintenance-free API for Google scraping
Get Web Scraper API that automatically adapts to Google's changes and enjoy hassle-free public data scraping.
7-day free trial, then $0.5/1K results
CAPTCHA management
Save time and development costs
175M+ ethically sourced IPs built for the highest reliability.
High-speed, cost-effective proxies built for any scraping workload.
Premium static residential proxies from trusted ASNs for most difficult targets.
Dedicated IPs from premium ASNs for demanding scraping.

AI-powered proxy solution for optimized web scraping performance.

20M+ IP addresses from real mobile devices for precise targeting.

Free Chrome proxy manager extension that works with any proxy provider.

Free Android proxy manager app that works with any proxy provider.

Free community-driven tools to improve your web scraping projects.
All-in-one web data collection platform for every stage of web scraping.
Ultra-fast organic search results scraper tailored for AI workflows.
Advanced browser automation solution for AI agents and scraping.
A suite of AI-powered tools for various scraping projects.
All features, parameters, and integration details, backed by code samples in every coding language.
Tutorials, samples, and guides.
Latest fixes and features.
![]() AI Summary:
AI Summary:
Google now requires JavaScript for its search results to enhance security and prevent automated abuse. This change specifically targets non-JavaScript-based bots and scrapers, meaning users must enable JavaScript and businesses using traditional scraping methods will need to adapt.
On January 17, 2025, Google announced that users have to enable JavaScript to use Google Search. This JavaScript requirement for Google Search is part of an update intended to protect search results from malicious actors and improve the overall user experience. This change may signal a broader trend among search engines to enhance security.
In today's article, we'll give a quick overview of what this change means for businesses and individual users. We'll also explain why this change does not negatively affect our users. Finally, we'll briefly showcase how to send requests to Google Search JavaScript-enabled environments with a headless browser and JavaScript if you use your own custom tools.
As primary reasons for the update, Google cited security enhancements, spam prevention, and an improved user experience. This requirement ensures web pages interactive elements function properly, and making web pages interactive helps prevent automated abuse. More specifically, this change is aimed at blocking bots, scrapers, and SEO tools that rely on non-JavaScript-based methods to extract search result data.
What does this update mean for individual users and businesses? Individuals will have to enable JavaScript, otherwise, some Google Search features may become unavailable. To make sure you have JavaScript enabled on your browser, refer to this page and screenshot:
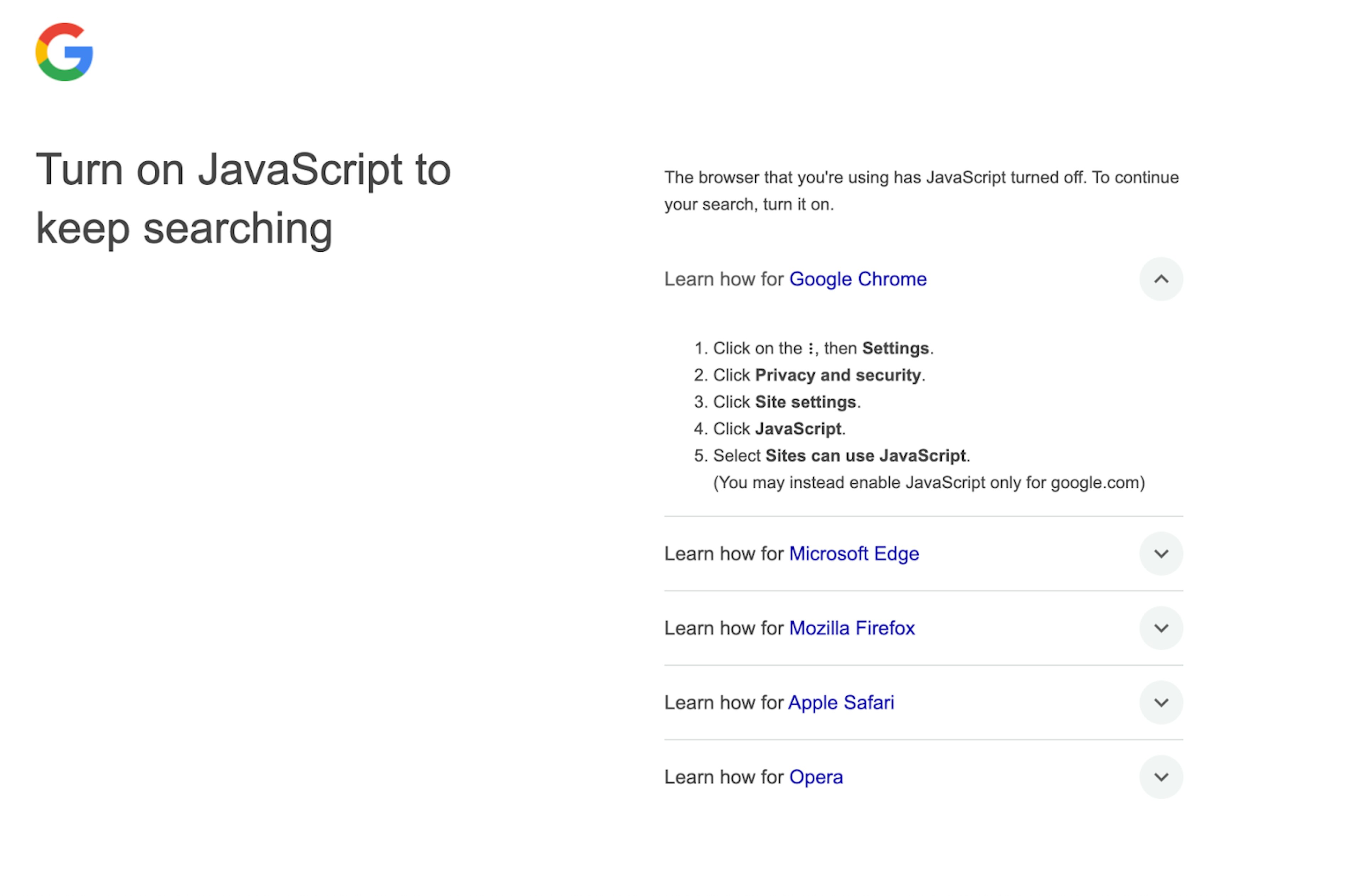
Meanwhile, businesses that regularly use Google Search for market research and tools that analyze search results for ranking data face significant challenges, as traditional scraping methods without JavaScript support may no longer work. While other search engines haven't announced similar requirements yet, some SEO tools have already reported disruptions, making it necessary for companies to adapt their approaches to continue monitoring search results effectively.
With this update targeting automated activities, a natural question arises: does it impact Oxylabs' scraping solutions? We can assure that our web scraping solutions (Web Scraper API, for instance) remain unaffected. Our clients can expect the same performance, reliability, and scraping volumes they usually rely on. While this update may cause concern, the Oxylabs infrastructure team is prepared to meet any challenges and keep customer web scraping operations running smooth.
Nonetheless, if you have any questions, please contact our support team via live chat on our website or at support@oxylabs.io.
If you're not using Oxylabs API for scraping Google search results, we've prepared a custom Python scraping guide for you to follow.
First off, let's install the prerequisite libraries. We'll need Selenium and webdriver for the headless browser, also fake_useragent to handle CAPTCHA. To access Google Search features programmatically, we'll need to set up the right environment:
rom selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.chrome.options import Options
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.common.by import By
from fake_useragent import UserAgent
ua = UserAgent()
# Set up Chrome options
options = Options()
options.add_argument("--headless") # Run in headless mode
options.add_argument("--disable-gpu") # Sometimes needed for headless mode
options.add_argument("--window-size=1920x1080") # Set window size
options.add_argument(f"user-agent={ua.chrome}") # Set a chrome user-agent
# Initialize WebDriver
service = Service(ChromeDriverManager().install())
driver = webdriver.Chrome(service=service, options=options)
query = "python web scraping"
url = f"https://www.google.com/search?q={query.replace(' ', '+')}"
driver.get(url)Now that we have the browser set up, let's extract some Google Search result titles and print them out to the console. For that, we will need to find some CSS identifier for the titles by inspecting the google search result HTML:
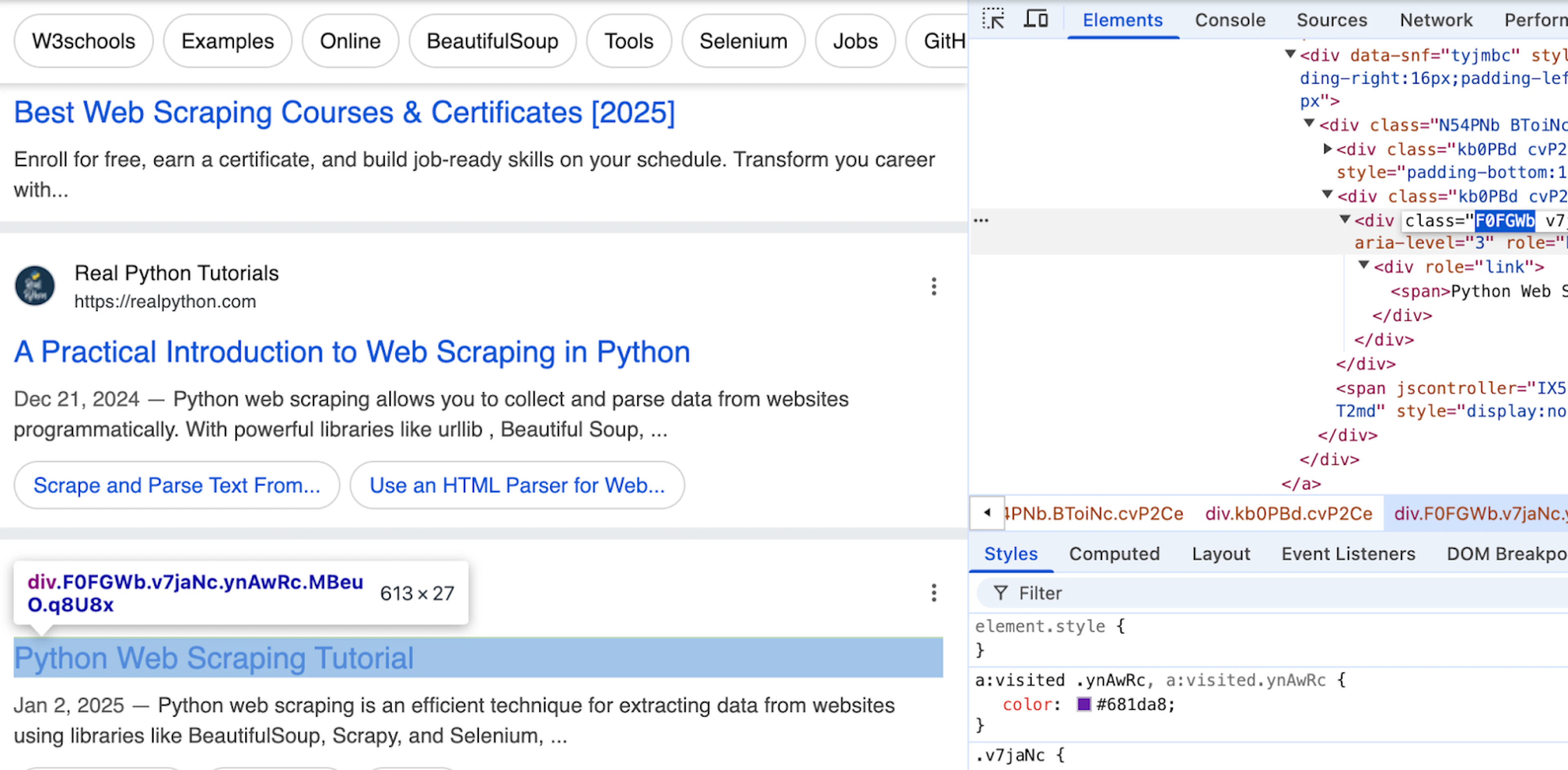
That identifier could be div.F0FGWb. Let's put it to use and locate these titles in our code using our initialized driver:
driver.get(url)
results = driver.find_elements(By.CSS_SELECTOR, "div.F0FGWb") # Select result blocks
for result in results:
print(result.text)
driver.quit()Once we run the code, the results should look similar to this:
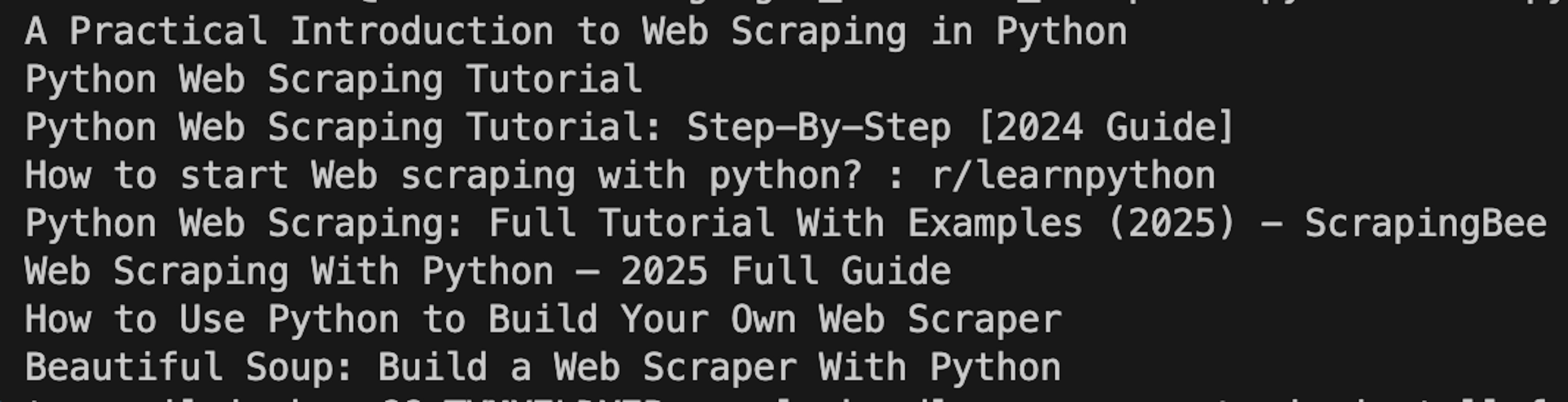
Keep in mind that with minimal effort of handling technical challenges Google has implemented, you might run into CAPTCHA. If you’re not able to navigate it, you should give our API a try.
Get Web Scraper API that automatically adapts to Google's changes and enjoy hassle-free public data scraping.
7-day free trial, then $0.5/1K results
CAPTCHA management
Save time and development costs
About the author

Dovydas Vėsa
Technical Content Researcher
Dovydas Vėsa is a Technical Content Researcher at Oxylabs. He creates in-depth technical content and tutorials for web scraping and data collection solutions, drawing from a background in journalism, cybersecurity, and a lifelong passion for tech, gaming, and all kinds of creative projects.
All information on Oxylabs Blog is provided on an "as is" basis and for informational purposes only. We make no representation and disclaim all liability with respect to your use of any information contained on Oxylabs Blog or any third-party websites that may be linked therein. Before engaging in scraping activities of any kind you should consult your legal advisors and carefully read the particular website's terms of service or receive a scraping license.


Vytautas Kirjazovas
2026-07-09


Narmin Mammadova
2026-06-19
Web Scraper API free trial
Quickly and smoothly adapt to Google's changes without interrupting your scraping operations.

Get the latest news from data gathering world
Scale up your business with Oxylabs®
Proxies
Advanced proxy solutions
Data Collection
Datasets
Resources
Innovation hub
Web Scraper API free trial
Quickly and smoothly adapt to Google's changes without interrupting your scraping operations.
