175M+ ethically sourced IPs built for the highest reliability.
High-speed, cost-effective proxies built for any scraping workload.
Premium static residential proxies from trusted ASNs for most difficult targets.
Dedicated IPs from premium ASNs for demanding scraping.

AI-powered proxy solution for optimized web scraping performance.

20M+ IP addresses from real mobile devices for precise targeting.

Free Chrome proxy manager extension that works with any proxy provider.

Free Android proxy manager app that works with any proxy provider.

Free community-driven tools to improve your web scraping projects.
Web Scraper API
All-in-one web data collection platform for every stage of web scraping.
Fast Search API
Ultra-fast organic search results scraper tailored for AI workflows.
Headless Browser
Advanced browser automation solution for AI agents and scraping.
AI Studio
A suite of AI-powered tools for various scraping projects.

Documentation
All features, parameters, and integration details, backed by code samples in every coding language.
Tutorials, samples, and guides.
Latest fixes and features.







![]() AI Summary:
AI Summary:
Dynamic websites, which generate content using JavaScript and often feature infinite scroll, require specialized tools for scraping beyond basic requests and Beautiful Soup. This tutorial outlines three primary methods: using Selenium or Playwright for browser automation to render JavaScript, or employing a dedicated Scraper API for simplified handling of dynamic content and anti-bot measures.
For websites built with static HTML and CSS, simple tools like Python's request library and Beautiful Soup can often do the job when web scraping. However, scraping dynamic content gets tricky when dealing with advanced websites built on dynamic JavaScript frameworks like React, Angular, and Vue. These frameworks streamline web development by providing pre-built components and architecture, but they also make dynamic websites difficult to scrape.
In this blog post, we'll overview the differences between dynamic and static websites and give a step-by-step guide on dynamic web scraping, particularly those featuring infinite scroll.
What is a dynamic website, and how is it different from a static one?
A dynamic website is a site where HTML pages are not fixed but generated in real-time based on user actions, database queries, or other factors. Unlike static websites, which serve the same pre-built HTML file to every visitor, dynamic sites load content on the fly, meaning different users can see different versions of the same page depending on their behavior, preferences, or search inputs.
This difference comes down to how each type handles a request. With a static page, the server simply delivers a fixed file, fast, straightforward, and identical for everyone. With a dynamic web page, the server performs intermediate processing first, querying a database, applying logic, and personalizing content, before sending the final result to the browser. This makes dynamic sites more complex to serve, but far richer in interactivity and personalization.
E-commerce product pages, social media feeds, and account dashboards are all common examples – the underlying URL may be the same, but the content shifts based on who's viewing it and when.
Challenge of web scraping dynamic content
Scraping dynamic content presents unique challenges that simple tools like Python's Requests library and Beautiful Soup aren't built to handle. Some of them can be:
JavaScript rendering: basic HTTP requests won't capture HTML generated in real-time by frameworks like React, Angular, and Vue
Pop-up windows and overlays: interstitial elements can block content access and interrupt the scraping flow
Drop-down menus and live search suggestions: interactive elements that require user input to reveal their content
Real-time updates: content that changes continuously without a page reload is harder to capture accurately
Sortable tables: data that reorders dynamically based on user interaction requires additional handling
Infinite scroll: content that only loads as the user scrolls down requires custom scraper logic to capture fully
Anti-bot protection: dynamic sites often deploy CAPTCHAs and IP blocks that interrupt automated scraping
How to scrape dynamic web pages?
We've previously discussed dynamic scraping techniques like employing Selenium, utilizing a headless browser, and making AJAX request. So, we invite you to check these resources out as well. Additionally, check out the advanced web scraping with Python guide to learn more tactics, such as emulating AJAX calls and handling infinite scroll.
However, it's important to note that each target presents unique challenges. Indeed, there can be different elements that require special attention, such as pop-up windows, drop-down menus, live search suggestions, real-time updates, sortable tables, and more.
One of the most encountered challenges is continuous or infinite scroll — a technique that allows content to be dynamically loaded as the user scrolls down a webpage. To scrape target URL from websites with infinite scroll, you need to customize your scraper, which is exactly what we'll discuss below using Google Search as an example of a dynamic target.
How to scrape dynamic web pages using Selenium
This section will go through the numbered steps to scrape dynamic sites using Selenium in Python. For our target, we will use the Google Search page with some keywords.
Step 1: Setting up the environment
First, make sure you have installed the latest version of Python on your system. You'll also need to install Selenium library using the following command:
pip install seleniumThen, download the Chrome driver and ensure that the version matches your Google Chrome version.
Step 2: Code in action
Start by creating a new Python file and import the required libraries:
import time
from selenium import webdriver
from selenium.webdriver.chrome.service import Service as ChromeService
from bs4 import BeautifulSoupThen set up Chrome Webdriver with Selenium by copying the path to your driver executable file and pasting in the following code:
# Set up the Chrome WebDriver
driver = webdriver.Chrome()Following that, navigate to the Google Search Page and provide your search keyword:
# Navigate to Google Search
search_keyword = "adidas"
driver.get("https://www.google.com/search?q=" + search_keyword)Now you can simulate a continuous scroll on Selenium. Using the script below, you’ll scroll multiple times to get more results and then scrape the results:
Define the number of times to scroll
scroll_count = 5
# Simulate continuous scrolling using JavaScript
for _ in range(scroll_count):
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
time.sleep(2) # Wait for the new results to load Finally, use BeautifulSoap to parse and extract the results:
page_source = driver.page_source
# Parse the page source with BeautifulSoup
soup = BeautifulSoup(page_source, 'html.parser')
search_results = soup.find_all('div', class_='tF2Cxc')
for result in search_results:
title = result.h3.text
link = result.a['href']
print(f"Title: {title}")
print(f"Link: {link}")
print("\n")Run the final code as specified below to see the results:
import time
from selenium import webdriver
from selenium.webdriver.chrome.service import Service as ChromeService
from bs4 import BeautifulSoup
# Set up the Chrome WebDriver
driver = webdriver.Chrome()
# Navigate to Google Search
search_keyword = "adidas"
driver.get("https://www.google.com/search?q=" + search_keyword)
# Define the number of times to scroll
scroll_count = 5
# Simulate continuous scrolling using JavaScript
for _ in range(scroll_count):
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
time.sleep(2) # Wait for the new results to load (adjust as needed)
# Get the page source after scrolling
page_source = driver.page_source
# Parse the page source with BeautifulSoup
soup = BeautifulSoup(page_source, "html.parser")
# Extract and print search results
search_results = soup.find_all("div", class_="tF2Cxc")
for result in search_results:
title = result.h3.text
link = result.a["href"]
print(f"Title: {title}")
print(f"Link: {link}")
print("\n")
# Close the WebDriver
driver.quit()The output should look something like this:
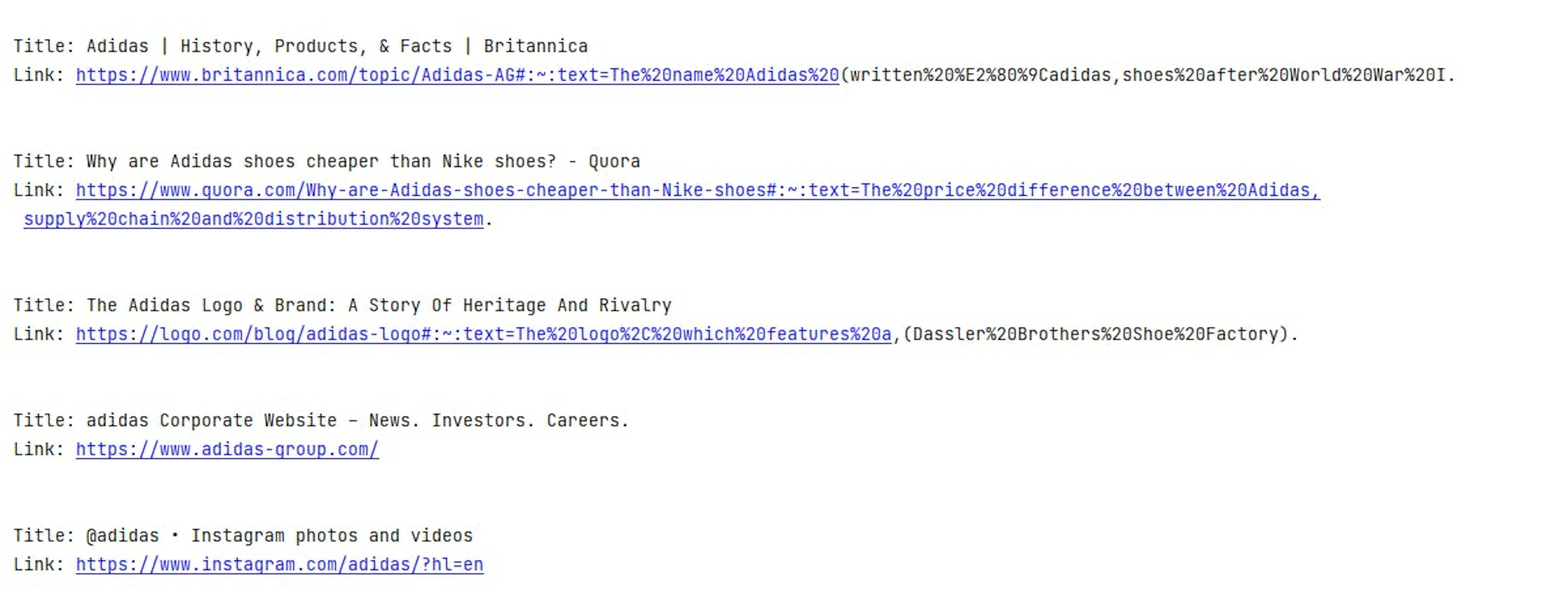
One problem with this web scraping approach is that Google might mistake you for a malicious bot, which would frequently trigger CAPTCHA. This means you'll have to integrate reliable proxies into your script and rotate them continuously.
So, if you're looking for a solution to extract data on a large scale, you might also want to consider a commercial solution that will deal with anti-bot systems for you, and we'll cover this in the subsequent section.
How to scrape dynamic web pages using Playwright
This section will go through the numbered steps to scrape dynamic sites using Playwright in Python. For our target, we will use the Oxylabs sandbox product listing page at sandbox.oxylabs.io/products.
Step 1: Setting up the environment
First, make sure you have installed the latest version of Python on your system. You'll also need to install Playwright library using the following command:
python -m pip install playwright
python -m playwright installStep 2: Code in action
Start by creating a new Python file and import the required libraries:
from playwright.sync_api import sync_playwrightTThen, launch a Chromium browser instance and open a new page:
# Launch Browser
with sync_playwright() as p:
browser = p.chromium.launch(headless=False)
page = browser.new_page()Navigate to the target product listing page and wait for the product cards to load. Since this is a dynamic site, we wait for the content to be visible before proceeding:
# Navigate to Target Page
page.goto("https://sandbox.oxylabs.io/products")
page.locator(".product-card").first.wait_for(state="visible")Now check if pagination exists on the page, and print how many pages are available:
# Check for Pagination
pagination = page.locator(".pagination")
if pagination.is_visible():
page_links = page.locator(".pagination a").all()
print(f"Found {len(page_links)} pages")If a "Next" button is found, click it and wait for the new page's products to load dynamically:
# Navigate to Next Page
next_button = page.locator("text=Next").first
if next_button.is_visible():
print("clicking 'next' button")
next_button.click()
page.locator(".product-card").first.wait_for(state="visible")Next, let’s scrape the products from the new page and close the browser:
# Scrape Products
products = page.locator(".product-card").all()
print(f"Found {len(products)} products on page 2")
# Clean Up
browser.close()Now, let’s do parsing:
# Parse Product Details
for product in products:
title = product.locator("h4").inner_text()
price = product.locator(".price-wrapper").inner_text()
print(f"Title: {title} | Price: {price}")Run the final code as specified below to see the results:
from playwright.sync_api import sync_playwright
def main():
# Launch Browser
with sync_playwright() as p:
browser = p.chromium.launch(headless=False)
page = browser.new_page()
# Navigate to Target Page
page.goto("https://sandbox.oxylabs.io/products")
page.locator(".product-card").first.wait_for(state="visible")
# Check for Pagination
pagination = page.locator(".pagination")
if pagination.is_visible():
page_links = page.locator(".pagination a").all()
print(f"Found {len(page_links)} pages")
# Navigate to Next Page
next_button = page.locator("text=Next").first
if next_button.is_visible():
print("clicking 'next' button")
next_button.click()
page.locator(".product-card").first.wait_for(state="visible")
# Scrape Products
products = page.locator(".product-card").all()
print(f"Found {len(products)} products on page 2")
# Parse Product Details
for product in products:
title = product.locator("h4").inner_text()
price = product.locator(".price-wrapper").inner_text()
print(f"Title: {title} | Price: {price}")
# Clean Up
browser.close()
if __name__ == '__main__':
main()The parsing section loops through each product card and extracts data.
The output should look something like this in the Terminal:
Found 10 pages
clicking 'next' button
Found 32 products on page 2
Title: iPhone 15 Pro | Price: $999.99
Title: Samsung Galaxy S24 | Price: $849.99If you're looking for a solution to extract data on a large scale, you might also want to consider a commercial solution that will deal with anti-bot systems for you, and we'll cover this in the subsequent section.
Scraping dynamic web pages without a browser
It's important to note that you're not restricted to Selenium when web scraping dynamic targets. In fact, there are alternative ways to do that:
1. Oxylabs Scraper API
One of the best ways to scrape dynamic content is using a specialized scraper service. For example, Oxylabs Scraper API is designed for web scraping tasks and is adapted to the most popular web scraping targets. This solution leverages Oxylabs data gathering infrastructure, meaning that you don't need to worry about IP blocks or JavaScript-rendered content, making it a valuable tool for web scraping dynamic web content.
2. Specialized no-code scrapers
There are also some no-code scrapers designed to handle dynamic content. These tools typically offer user-friendly interfaces that allow users to select and extract specific elements from dynamic pages without the need for writing code. However, these solutions can sometimes lack flexibility and are more suitable for more basic scraping projects.
Scraping targets with infinite scrolling using Scraper API
As mentioned above, you can use a commercial Scraper API to scrape dynamic content. The benefit of web scraping dynamic pages is that you won't need to worry about having your own scraping infrastructure. Specifically, you don't need to pass any additional parameters to deal with CAPTCHAs and IP blocks, as the tool does these things for you.
What's more, Oxylabs Scraper APIs are designed to deal with dynamically loaded content. For example, our Web Scraper API automatically detects infinite scroll and efficiently loads the requested organic results without extra parameters required.
Let's see how it works in action!
Step 1: Setting up the environment
Before we start scraping, make sure you have the following libraries installed:
pip install requests beautifulsoup4 pandasAlso, to use the Web Scraper API, you need to get access to the Oxylabs API by creating an account. After doing that, you will be directed to the Oxylabs API dashboard. Head to the Users tab and create a new API user. These API user credentials will be used later in the code.
Step 2: Code in action
After getting the credentials, you can start writing the code in Python. Begin by importing the required library files in your Python file:
import requests
import pandas as pdThen, create the Payload for SERP Scraper API following this structure:
# Structure payload.
payload = {
'source': 'google_search',
'domain': 'com',
'query': 'adidas',
'parse': True,
'limit': 100,
}You can then initialize the request and get the response from the API:
USERNAME = "<your_username>"
PASSWORD = "<your_password>"
response = requests.request(
'POST',
'https://realtime.oxylabs.io/v1/queries',
auth=(USERNAME, PASSWORD),
json=payload,
)
After receiving the response, you can get the content from the JSON results using pandas:
df = pd.DataFrame(columns=["Product Title", "Seller", "Price","URL"])
results = response.json()['results']
items = results[0]['content']['results']
items_list = items['pla']['items']
for it in items_list:
df = pd.concat(
[pd.DataFrame([[it['title'], it['seller'], it['price'], it['url']]], columns=df.columns), df],
ignore_index=True,)Here, we have created a dataFrame and added all the data to it. You can then convert the dataFrame and CSV and JSON files like this:
df.to_csv("google_search_results.csv", index=False)
df.to_json("google_search_results.json", orient="split", index=False)That’s it! Let’s combine all the code and execute it to see the output:
import requests
import pandas as pd
USERNAME = "<your_username>"
PASSWORD = "<your_password>"
# Structure payload.
payload = {
"source": "google_search",
"domain": "com",
"query": "adidas",
"start_page": 11,
"pages": 2,
"parse": "true",
}
# Get response.
response = requests.request(
"POST",
"https://realtime.oxylabs.io/v1/queries",
auth=(USERNAME, PASSWORD),
json=payload,
)
df = pd.DataFrame(columns=["Product Title", "Seller", "Price", "URL"])
results = response.json()["results"]
items = results[0]["content"]["results"]
items_list = items["pla"]["items"]
for it in items_list:
df = pd.concat(
[
pd.DataFrame(
[[it["title"], it["seller"], it["price"], it["url"]]],
columns=df.columns,
),
df,
],
ignore_index=True,
)
print(df)
df.to_csv("google_search_results.csv", index=False)
df.to_json("google_search_results.json", orient="split", index=False)As a result, you’ll get a CSV file which you can open in Excel:
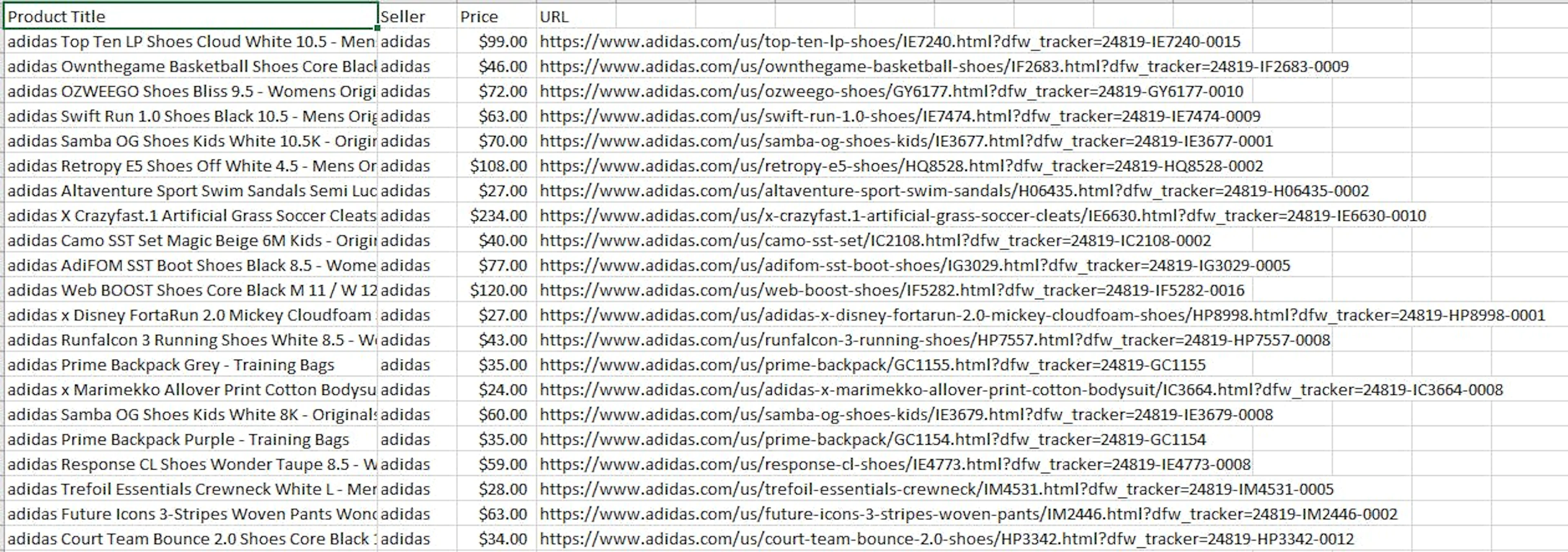
Conclusion
Scraping dynamic web pages is possible with Python, Selenium, and the Oxylabs SERP Scraper API. Your individual use case, data requirements, and preferences will determine the approach you use. While the SERP Scraper API streamlines the process of scraping search engine results, Selenium offers more control over browser automation.
We hope you found this guide on how to scrape dynamic web pages useful and if you're looking for more materials, be sure to check out our blog posts on dynamic web scraping with Playwright, PHP, or R. You might also be interested in web scraping with Python or asynchronous data gathering. Plus, check out news about Google now requiring JavaScript to scrape its data
Take a look at our tutorials on scraping different targets:
Frequently asked questions
Why BeautifulSoup and Requests are not enough to scrape dynamic websites?
Beautiful Soup and Requests are not enough to scrape dynamic websites primarily because they do not have the capability to execute JavaScript. Instead, you need to employ additional tools like headless browsers or leverage other libraries like Requests-HTML with Pyppeteer or Playwright.
Forget about complex web scraping processes
Choose Oxylabs' advanced web intelligence collection solutions to gather real-time public data hassle-free.
About the author

Enrika Pavlovskytė
Former Copywriter
Enrika Pavlovskytė was a Copywriter at Oxylabs. With a background in digital heritage research, she became increasingly fascinated with innovative technologies and started transitioning into the tech world. On her days off, you might find her camping in the wilderness and, perhaps, trying to befriend a fox! Even so, she would never pass up a chance to binge-watch old horror movies on the couch.
All information on Oxylabs Blog is provided on an "as is" basis and for informational purposes only. We make no representation and disclaim all liability with respect to your use of any information contained on Oxylabs Blog or any third-party websites that may be linked therein. Before engaging in scraping activities of any kind you should consult your legal advisors and carefully read the particular website's terms of service or receive a scraping license.
Related articles



JavaScript Web Scraping using Node.js & Puppeteer

Adelina Kiskyte
2025-11-13

15 Tips on How to Crawl a Website While Maintaining Reliable Access
Adelina Kiskyte
2024-03-15

Get the latest news from data gathering world
Scale up your business with Oxylabs®
Proxies
Advanced proxy solutions
Data Collection
Datasets
Resources
Innovation hub
Forget about complex web scraping processes
Choose Oxylabs' advanced web intelligence collection solutions to gather real-time public data hassle-free.