175M+ ethically sourced IPs built for the highest reliability.
High-speed, cost-effective proxies built for any scraping workload.
Premium static residential proxies from trusted ASNs for most difficult targets.
Dedicated IPs from premium ASNs for demanding scraping.

AI-powered proxy solution for optimized web scraping performance.

20M+ IP addresses from real mobile devices for precise targeting.

Free Chrome proxy manager extension that works with any proxy provider.

Free Android proxy manager app that works with any proxy provider.

Free community-driven tools to improve your web scraping projects.
Web Scraper API
All-in-one web data collection platform for every stage of web scraping.
Fast Search API
Ultra-fast organic search results scraper tailored for AI workflows.
Headless Browser
Advanced browser automation solution for AI agents and scraping.
AI Studio
A suite of AI-powered tools for various scraping projects.

Documentation
All features, parameters, and integration details, backed by code samples in every coding language.
Tutorials, samples, and guides.
Latest fixes and features.






![]() AI Summary:
AI Summary:
This guide shows how to scrape IMDb data using Python and Oxylabs' Web Scraper API. It covers extracting movie metadata (titles, ratings, years) from the Top 250 list and scraping user reviews, using the API's Custom Parser with XPath and CSS selectors. The results can be exported to JSON or CSV. It also briefly covers building a custom scraper with proxies as an alternative approach.
Want to check where you’ve seen that actor before? Or perhaps want to rate a movie you really enjoyed watching? We all know the first place you’ll look. Or at least the first place Google will take you.
This blog post provides insights into IMDb and its relevance for web scraping and offers a guide on efficient movie data extraction using Oxylabs Web Scraper API.
Get a free trial
Claim a free trial to test our Web Scraper API for your use case.
Up to 2K results
No credit card required
Why scrape IMDb
As one of the best-known entertainment data repositories, IMDb (Internet Movie Database) contains tons of data on movies, TV shows, and video games. Not only is there a lot of data, but it's also extremely varied. For example, you can explore movie descriptions, cast, ratings, trivia, related movies, awards, and more. In addition to that, you'll find user-generated IMDb data, such as reviews.
This wealth of information can be applied for a number of purposes, ranging from market research and movie recommender systems to strategic marketing initiatives. Furthermore, user reviews present a goldmine for sentiment analysis, which can deepen insights into movie audiences.
What data can be extracted from IMDb?
IMDb contains a wealth of data points for web scraping. Here are the main types of IMDb data points you can collect:
Movie/TV show/ video game metadata: titles, release dates, runtimes, genres, content ratings, and plot summaries
Cast and crew information: actors, directors, writers, and their roles
Ratings and reviews
Images: posters, production stills, and promotional materials
Box office data and budget information
Production companies and distributors
Filming locations
Technical specifications (aspect ratio, sound mix)
Awards and nominations
Trivia, goofs, and quotes
Related content recommendations
Episode guides for TV series
1. Setting up for scraping IMDb
As you’ll be writing a Python script, make sure you have Python 3.8 or newer installed on your machine. This guide is written for Python 3.8+, so having a compatible version is crucial.
Creating a virtual environment
A virtual environment is an isolated space where you can install libraries and dependencies without affecting your global Python setup. It's good practice to create one for each project. Here's how to set it up on different operating systems:
python -m venv imdb_env #Windows
python3 -m venv imdb_env #Mac and LinuxReplace imdb_env with the name you'd like to give to your virtual environment.
Activating the virtual environment
Once the virtual environment is created, you'll need to activate it:
.\imdb_env\Scripts\Activate #Windows
source imdb_env/bin/activate #Mac and LinuxYou should see the name of your virtual environment in the terminal, indicating that it's active.
Installing required libraries
We'll use the requests library for this project to make HTTP requests. Install it by running the following command:
$ pip install requests pandasAnd there you have it! Your project environment is ready for IMDb data scraping. In the following sections, we'll delve deeper into the IMDb structure.
2. Overview of Web Scraper API
Oxylabs' Web Scraper API allows you to extract IMDb data from many complex websites easily. The following is a basic example that shows how Scraper API works.
# scraper_api_demo.py
import requests
USERNAME = "username"
PASSWORD = "password"
payload = {
"source": "universal",
"url": "https://www.imdb.com"
}
response = requests.post(
url="https://realtime.oxylabs.io/v1/queries",
json=payload,
auth=(USERNAME,PASSWORD),
)
print(response.json())After importing requests, you need to replace the credentials with your own, which you can get by registering for a Web Scraper API subscription or getting a free trial. The payload is where you inform the API what and how you want to scrape.
Save this code in a file scraper_api_demo.py and run it. You’ll see that the entire HTML of the page will be printed, along with some additional information from Scraper API.
In the following section, let's examine various parameters we can send in the payload.
Scraper API parameters
The most critical parameter is source. For IMDb, set the source as universal, which is general-purpose and can handle most domains.
The parameter url is self-explanatory, a direct link to the IMDb URLs you want to scrape. In the code discussed in the previous section, there are only two parameters. As a result, you get the entire HTML of the page.
Instead, what you need is parsed data. This is where the parameter parse comes into the picture. When you send parse as True, you must also send one more parameter — parsing_instructions. Combined, these two allow you to get parsed data in a structure you prefer.
The following allows you to get a JSON of the page title:
"title": {
"_fns": [
{
"_fn": "xpath_one",
"_args": ["//title/text()"]
}
]
}
},If you send this as parsing_instructions, the output would be the following JSON:
{'title': 'IMDb Top 250 Movies'}The key _fns indicates a list of functions, which can contain one or more functions indicated by the _fn key, along with the arguments.
In this example, the function is xpath_one, which takes an XPath and returns the first matching element. On the other hand, the function xpath returns all matching elements.
The functions css_one and css are similar but use CSS selectors instead of XPath. For a complete list of available functions, see the Scraper API documentation.
The following code prints the title of the IMDb page:
# imdb_title.py
import requests
USERNAME = "username"
PASSWORD = "password"
payload = {
"source": "universal",
"url": "https://www.imdb.com",
"parse": True,
"parsing_instructions": {
"title": {
"_fns": [
{
"_fn": "xpath_one",
"_args": [
"//title/text()"
]
}
]
}
},
}
response = requests.post(
url="https://realtime.oxylabs.io/v1/queries",
json=payload,
auth=(USERNAME,PASSWORD),
)
print(response.json()['results'][0]['content'])Run this file to get the title of the IMDb page. In the next section, you’ll scrape movie data from a list.
3. Scraping movie info from a list
Before scraping a page, we need to examine the page structure. Open the IMDb top 250 listing in Chrome, right-click the movie list, and select Inspect.
Move around your mouse until you can precisely select one movie list item and related data.
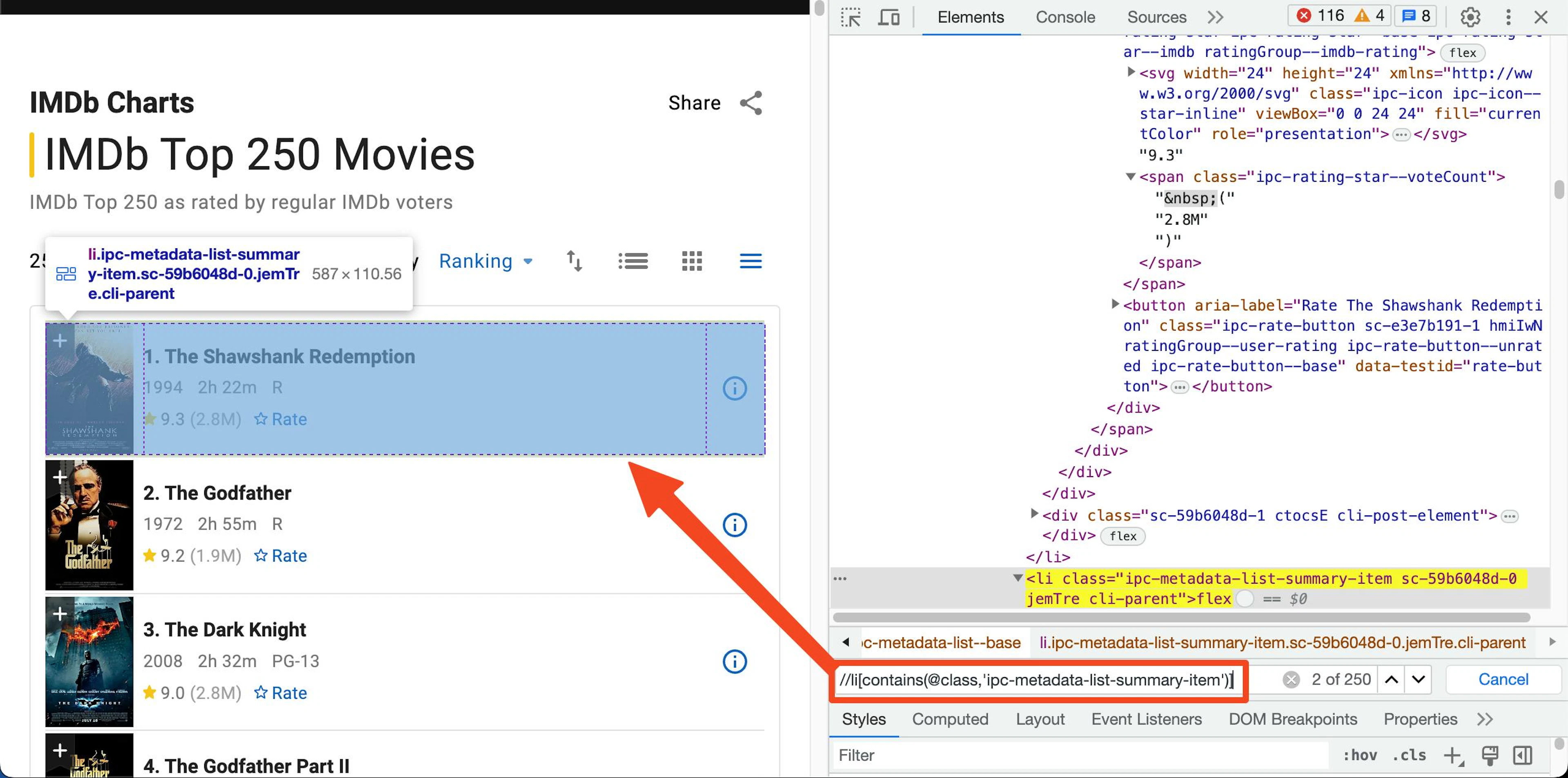
Inspecting an element
You can use the following XPath to select one movie detail:
//li[contains(@class,'ipc-metadata-list-summary-item')]
Also, you can iterate over these 250 items and get movie titles, year, and ratings using the same selector. Let’s see how to do it.
First, create the placeholder for movies as follows:
"movies": {
"_fns": [
{
"_fn": "xpath",
"_args": [
"//li[contains(@class,'ipc-metadata-list-summary-item')]"
]
}
],Note the use of the function xpath. It means that it will return all matching elements.
Next, we can use reserved property _items to indicate that we want to iterate over a list, further processing each list item separately.
It will allow us to use concatenating to the path already defined as follows:
import json
payload = {
"source": "universal",
"url": "https://www.imdb.com/chart/top/?ref_=nv_mv_250",
"parse": True,
"parsing_instructions": {
"movies": {
"_fns": [
{
"_fn": "xpath",
"_args": [
"//li[contains(@class,'ipc-metadata-list-summary-item')]"
]
}
],
"_items": {
"movie_name": {
"_fns": [
{
"_fn": "xpath_one",
"_args": [
".//h3/text()"
]
}
]
},
"year":{
"_fns": [
{
"_fn": "xpath_one",
"_args": [
".//*[contains(@class,'cli-title-metadata-item')]/text()"
]
}
]
},
"rating": {
"_fns": [
{
"_fn": "xpath_one",
"_args": [
".//*[contains(@aria-label,'IMDb rating')]/text()"
]
}
]
}
}
}
}
}
with open("top_250_payload.json", 'w') as f:
json.dump(payload, f, indent=4)Note the use of ./ in the XPath of movie_name and year. A good way to organize your code is to save the payload as a separator JSON file. It will allow you to keep your Python file short:
# parse_top_250.py
import requests
import json
USERNAME = "username"
PASSWORD = "password"
payload = {}
with open("top_250_payload.json") as f:
payload = json.load(f)
response = requests.post(
url="https://realtime.oxylabs.io/v1/queries",
json=payload,
auth=(USERNAME, PASSWORD),
)
print(response.status_code)
with open("result.json", "w") as f:
json.dump(response.json(),f, indent=4)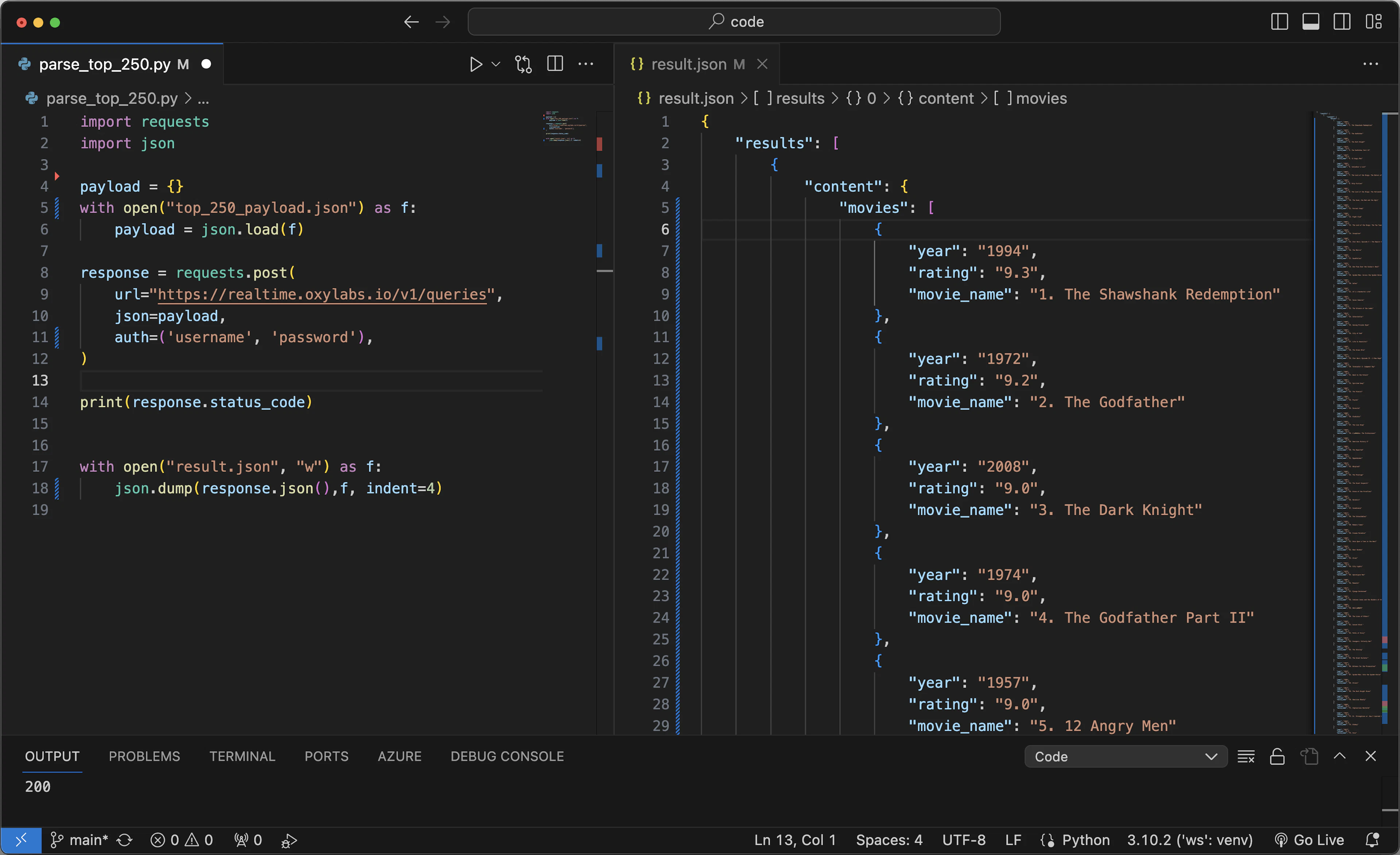
Code and output
That’s how it’s done! In the next section, let’s explore how to scrape IMDb movie reviews.
4. Scraping movie reviews
Let's scrape movie reviews of Shawshank Redemption. You’ll use CSS selectors instead of XPath this time, but the basic idea remains the same. You’ll use the css function to create a reviews node and then use the _items to extract data about the review.
First, take a look at the selectors:
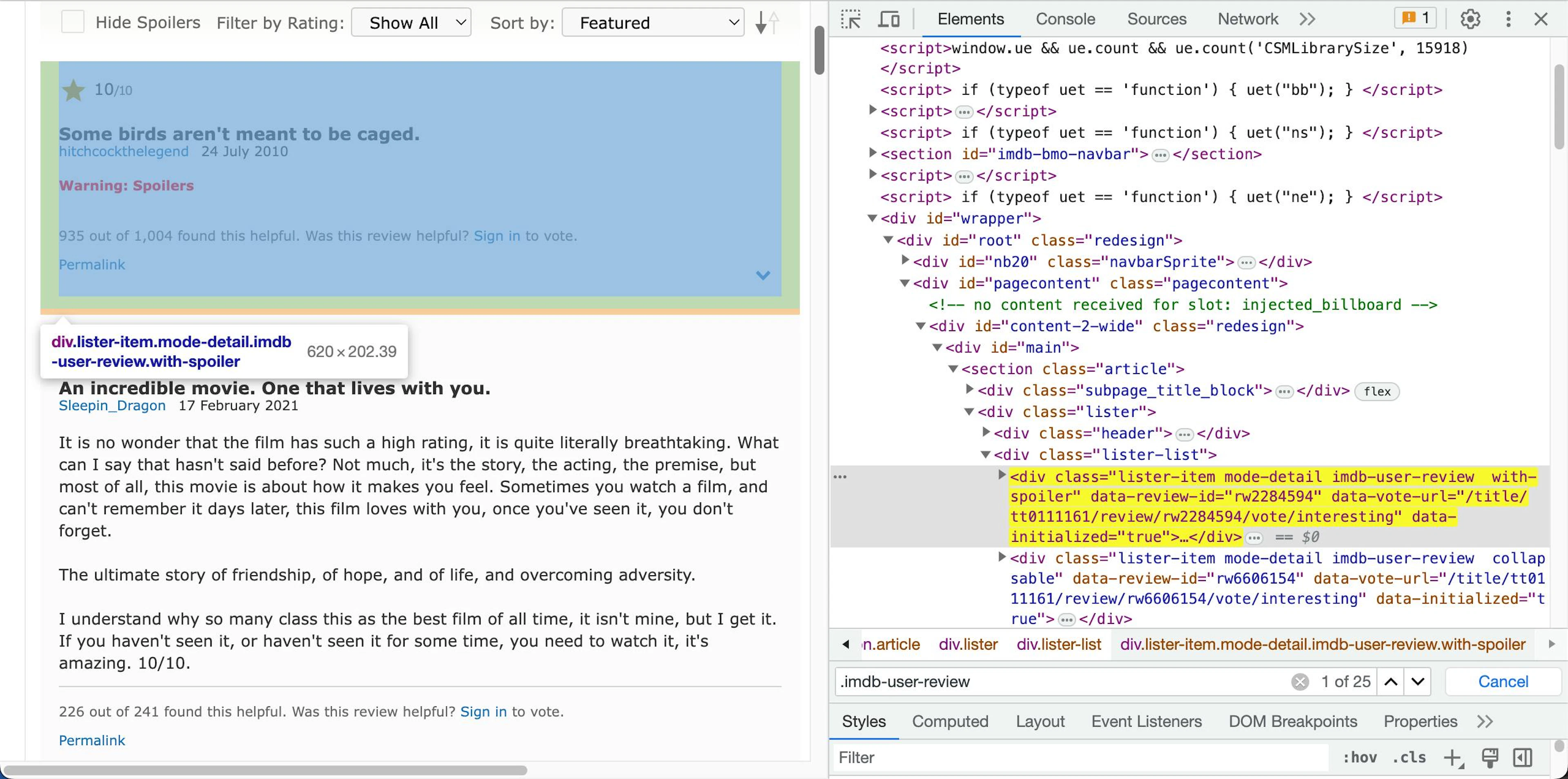
The container for each review can be selected using .imdb-user-review. After that, we can use the following selectors to get various metadata:
.title for selecting the review title
.display-name-link a for reviewer name
.review-date for the review date
.content>.show-more__control for the review body
CSS selector, unlike XPath, cannot directly match the text in an element. This is where one more function from Scraper API becomes useful — element_text.
The element_text function extracts the text in the element. Scraper API allows us to chain as many functions as needed. It means we can chain css_one and element_text functions to select the data we need.
"reviews": {
"_fns": [
{
"_fn": "css",
"_args": [
".imdb-user-review"
]
}
],
"_items": {
"review_title": {
"_fns": [
{
"_fn": "css_one",
"_args": [
".title"
]
},
{
"_fn": "element_text"
}
]
},
}Similarly, you can extract other IMDb data points. That's how the code should look so far:
{
"source": "universal",
"url": "https://www.imdb.com/title/tt0111161/reviews?ref_=tt_urv",
"parse": true,
"parsing_instructions": {
"movie_name": {
"_fns": [
{
"_fn": "css_one",
"_args": [
".parent a"
]
},
{
"_fn": "element_text"
}
]
},
"reviews": {
"_fns": [
{
"_fn": "css",
"_args": [
".imdb-user-review"
]
}
],
"_items": {
"review_title": {
"_fns": [
{
"_fn": "css_one",
"_args": [
".title"
]
},
{
"_fn": "element_text"
}
]
},
"review-body": {
"_fns": [
{
"_fn": "css_one",
"_args": [
".content>.show-more__control"
]
},
{
"_fn": "element_text"
}
]
},
"rating": {
"_fns": [
{
"_fn": "css_one",
"_args": [
".rating-other-user-rating"
]
},
{
"_fn": "element_text"
}
]
},
"name": {
"_fns": [
{
"_fn": "css_one",
"_args": [
".display-name-link a"
]
},
{
"_fn": "element_text"
}
]
},
"review_date": {
"_fns": [
{
"_fn": "css_one",
"_args": [
".review-date"
]
},
{
"_fn": "element_text"
}
]
}
}
}
}
}Once your payload file is ready, you can use the same Python code file shown in the previous section, point to this payload, and run the code to get the results.
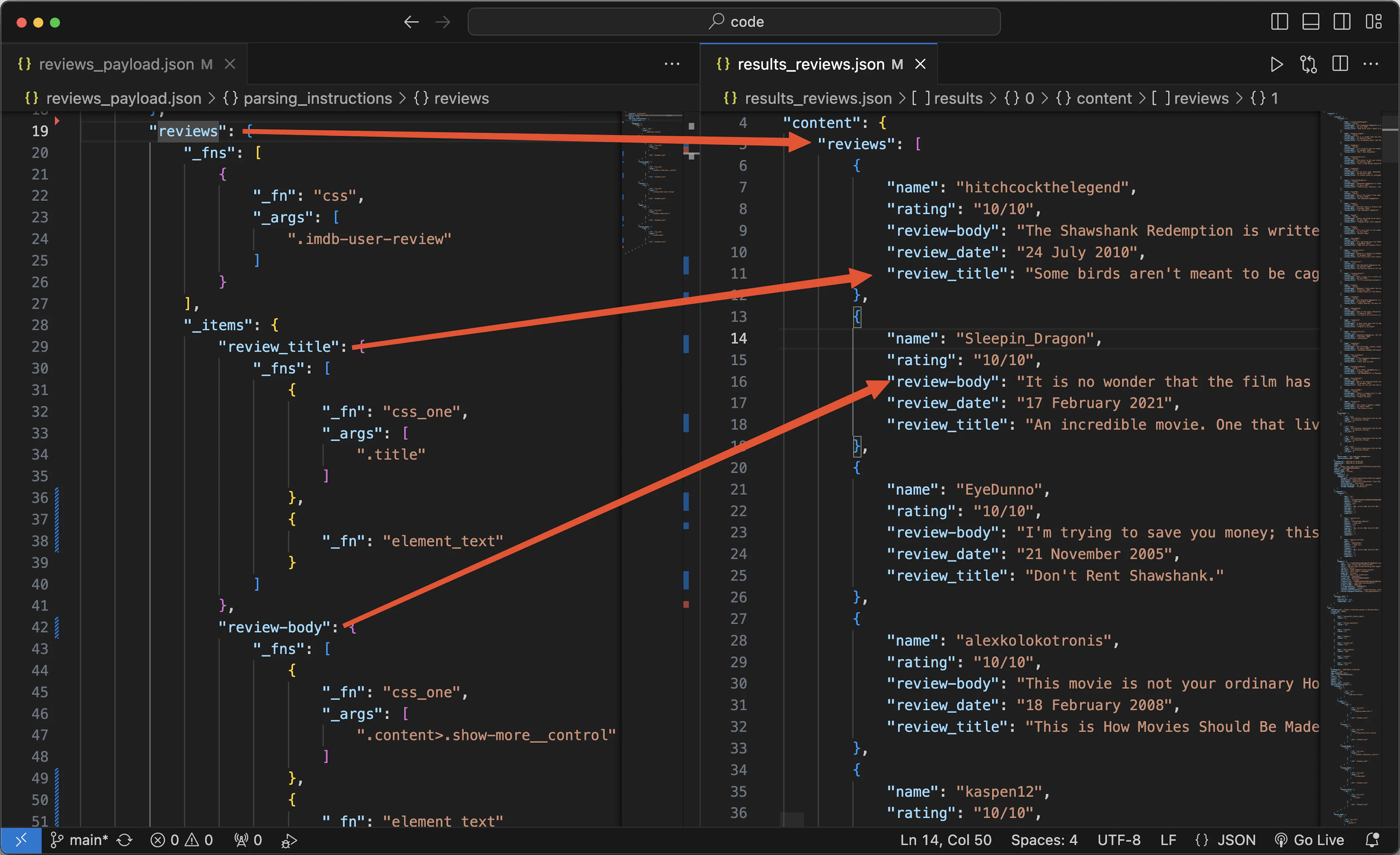
Comparing payload and results
5. Exporting to JSON and CSV
The output of Scraper API is JSON, and you can save the extracted data as JSON directly. If you want a CSV file, you can use a library such as Pandas. Remember that the parsed data is stored in the content inside results.
As we created the review in the key review, we can use the following snippet to save the extracted data:
# parse_reviews.py
import json
import pandas as pd
# save results into a variable data
data = response.json()
# save the data as a json file
with open("results_reviews.json", "w") as f:
json.dump(data, f, indent=4)
# save the reviews in a CSV file
df = pd.DataFrame(data['results'][0]['content']['reviews'])
df.to_csv('reviews.csv', index=False)Web scraping IMDb data with Python using proxies
Of course, you can scrape IMDb data using Python web scraping with your favorite IDE, no API required. However, to extract data from multiple pages at scale, using proxies is almost obligatory.
Proxies help you maintain uninterrupted connections and stay within standard rate limits. They distribute your requests through different IP addresses, ensuring smooth performance without IP flagging.
The foundation of a web scraping script is selecting the right Python libraries. Beautiful Soup and Requests are a must, and frameworks like Selenium will be needed to deal with interactive web elements (JavaScript).
Here's a typical workflow:
Identify target data - Determine exactly which IMDb pages and data points you need.
Set up your environment - download Python, choose an IDE, and install the necessary libraries.
Get proxies - Obtain reliable proxy IPs from a proxy service.
Design request headers - Set up realistic user agents and other headers to mimic browser behavior.
Code the scraper - Create functions to send requests through proxies, parse HTML, and extract data.
Store the data - Save extracted data to a database or file format (CSV, JSON).
Proxies for web scraping
Get free proxies and access web scraping targets with an average 99.82% success rate.
5 IPs for FREE
No credit card is required
IMDb data scraping methods comparison
| Criteria | Manual scraping (without proxies) | Manual scraping using proxies | Scraper APIs |
| Key features | • Single, static IP address • Direct network requests • Local execution environment |
• IP rotation • Geo-targeting • Request distribution • Success-rate optimizations |
• Maintenance-free infrastructure • CAPTCHA handling • JavaScript rendering • Automatic proxy management |
| Pros | • Maximum flexibility • No additional service costs • Complete data pipeline control • Minimal latency |
• Improved success rate • Reduced IP flagging • Coordinate, city, state-level targeting • Anonymity |
• Minimal maintenance overhead • Built-in error handling • Regular updates for site layout changes • Technical support |
| Cons | • High likelihood of IP flags • Regular maintenance • Limited scaling • No geo-targeting |
• Additional proxy service costs • Manual proxy management • Additional setup • Increased request latency |
• Higher costs • Fixed customization • API-specific limitations • Dependency on provider |
| Best for | • Small-scale scraping • Unrestricted websites • Custom data extraction logic |
• Medium to large-scale scraping • Restricted websites • Global targets |
• Enterprise-level scraping • Complex websites with bot traffic management systems • Resource-constrained teams • Quick implementation |
Conclusion
Web Scraper API simplifies IMDb web scraping by handling the most common data gathering challenges, including managing your proxies. You can use any language you like, and all you need to do is send the correct payload.
If you want to scale efforts using your own scraper, you can buy proxies to ensure efficient and uninterrupted scraping, such as a paid or free proxy list of residential proxies or datacenter IPs.
You might also be interested in reading up about extracting Google News or collecting E-Commerce data.
Frequently asked questions
Does IMDb allow scraping?
While web scraping publicly available data from IMDb is considered to be legal, it highly depends on such factors as the target, local legislation, and how the data is going to be used. We highly recommend that you seek professional legal advice before starting any operations.
To learn more about the legality of web scraping, check here.
How do I scrape IMDb data?
How do I scrape a movie review on IMDb?
Does IMDb have an API?
Why should you use Oxylabs Scraper instead of IMDb API?
About the author

Enrika Pavlovskytė
Former Copywriter
Enrika Pavlovskytė was a Copywriter at Oxylabs. With a background in digital heritage research, she became increasingly fascinated with innovative technologies and started transitioning into the tech world. On her days off, you might find her camping in the wilderness and, perhaps, trying to befriend a fox! Even so, she would never pass up a chance to binge-watch old horror movies on the couch.
All information on Oxylabs Blog is provided on an "as is" basis and for informational purposes only. We make no representation and disclaim all liability with respect to your use of any information contained on Oxylabs Blog or any third-party websites that may be linked therein. Before engaging in scraping activities of any kind you should consult your legal advisors and carefully read the particular website's terms of service or receive a scraping license.
Related articles

Cheerio vs. Puppeteer: Which Should You Use for Web Scraping?

Shinthiya Nowsain Promi
2026-06-23


List Crawling in Python: Tools, Tips, and Techniques

Danielė Virinaitė
2026-06-17
Try IMDb Scraper API
Choose Oxylabs' IMDb Scraper API to gather movie data hassle-free.
Premium Oxylabs proxies
Forget about IP blocks and CAPTCHAs with 102M+ premium proxies located in 195 countries.

Get the latest news from data gathering world
Scale up your business with Oxylabs®
Proxies
Advanced proxy solutions
Data Collection
Datasets
Resources
Innovation hub
Try IMDb Scraper API
Choose Oxylabs' IMDb Scraper API to gather movie data hassle-free.
Premium Oxylabs proxies
Forget about IP blocks and CAPTCHAs with 102M+ premium proxies located in 195 countries.