175M+ ethically sourced IPs built for the highest reliability.
High-speed, cost-effective proxies built for any scraping workload.
Premium static residential proxies from trusted ASNs for most difficult targets.
Dedicated IPs from premium ASNs for demanding scraping.

AI-powered proxy solution for optimized web scraping performance.

20M+ IP addresses from real mobile devices for precise targeting.

Free Chrome proxy manager extension that works with any proxy provider.

Free Android proxy manager app that works with any proxy provider.

Free community-driven tools to improve your web scraping projects.
Web Scraper API
All-in-one web data collection platform for every stage of web scraping.
Fast Search API
Ultra-fast organic search results scraper tailored for AI workflows.
Headless Browser
Advanced browser automation solution for AI agents and scraping.
AI Studio
A suite of AI-powered tools for various scraping projects.

Documentation
All features, parameters, and integration details, backed by code samples in every coding language.
Tutorials, samples, and guides.
Latest fixes and features.






![]() AI Summary:
AI Summary:
Scrapy Cloud takes the operational load off Scrapy users by handling deployment, scheduling, and monitoring in one platform. See how it supports large-scale scraping workflows and where its limitations may lead you to alternatives.
Scrapy, being an open-source web-crawling framework, is particularly famous for its versatility, robustness, and extensibility. However, managing, deploying, and monitoring Scrapy projects can be tricky, especially for large scraping tasks. That's where Scrapy Cloud comes in – it helps simplify the process. Backed by Scrapinghub, Scrapy Cloud has become an essential tool for over 2,000 companies globally, helping them orchestrate their scraping jobs.
In this article, we'll explain what Scrapy Cloud is, how it works, and how to set it up. Plus, we'll provide tips for improving spider performance and offer some alternative options to Scrapy Cloud. Let’s dive in!
What is Scrapy Cloud?
Scrapy Cloud is a scraping and data extraction platform developed by Zyte (previously ScrapingHub). This cloud-based platform helps set up, administer, and oversee large-scale scraping projects using Scrapy. With Scrapy Cloud, users can enhance their scraping tasks' scalability, efficiency, and ease of use.
How does Scrapy Cloud work?
By abstracting away the infrastructure setup and management difficulties, Scrapy Cloud enables users to concentrate on creating and running their Scrapy spiders. Here is an overview of its different use cases:
Project setup: To begin using Scrapy Cloud, you must create a project and locally set up your Scrapy Spider. The project typically consists of settings, spider code, and required dependencies.
Deployment: When your project is finalized, you can deploy the available command-line tools or the web-based user interface to Scrapy Cloud. Scrapy Cloud will set up the infrastructure and resources required to run your spiders.
Spider execution: Scrapy Cloud can run your spiders after deployment. Spider runs can be initiated manually or set to take place at predefined intervals. The use of Scrapy Cloud allows for efficient parallel scraping by dividing the task among a number of servers.
Job monitoring and logging: The easy-to-use dashboard provided by Scrapy Cloud will let you keep track of the status and progress of your spider runs in real time. You can access complete logs, review statistics, and keep track of any scraping-related errors or issues.
Data export and storage: You can store your scraped data securely using Scrapy Cloud's built-in storage. Additionally, you may set up customized data export pipelines to export scraped data to databases or other formats like CSV and JSON.
Scaling and optimization: By adding more concurrent spiders or expanding the number of servers, Scrapy Cloud makes it simple to scale your scraping applications. With the help of Scrapy Cloud's middleware and plugins, you can effectively manage intricate scraping tasks and improve the efficiency of your spiders.
Proxies and Scrapy Cloud
While Scrapy Cloud is a viable scraping solution, it’s the most effective when paired with proxies, such as Residential Proxies or Datacenter Proxies. Proxies route requests through different IP addresses and locations, improving connection reliability and success rates for your web scraping operations.
Setting up and running Scrapy Cloud
Are you developing scrapers using Scrapy and wish to avoid the hassle of setting up servers and scheduling jobs? Scrapy Cloud API is an excellent option for hosting your spiders. To use Scrapy Cloud, simply place your spiders on the platform and schedule their running. Scrapy Cloud will monitor their tasks and save the scraped data for you.
To set up and run Scrapy Cloud, you need to follow the following steps:
Create a free account on Zyte.
2. Log in to the site and create a new project from the dashboard screen.

3. Provide a Project name in the next window and click “Start.”

4. Once your project is created, you will be prompted with two options to upload and deploy your project:
a. Use the command-line utility
b. Use GitHub
We are using the command-line tool for this tutorial.

For demonstration, this tutorial uses the public Scrapy demo booksbot project. You can clone this repository using the following command:
git clone https://github.com/scrapy/booksbot.git
cd booksbot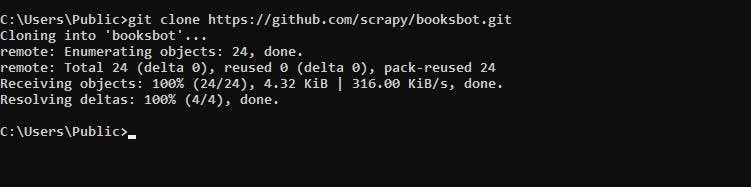
5. Now, install the shub command-line tool to deploy your spiders to Scrapy Cloud using the following command:
pip install shub6. Next, you must link the shub client to your Scrapy Cloud project. For this purpose, you can use the following command:
shub login
API key: YOUR_API_KEYNote: You can get your API key from the “Code and Deploys” section of the Zyte dashboard.

7. Then, you can deploy your Scrapy project using the following command line:
shub deploy PROJECT_ID
8. When your Scrapy project is deployed, your dashboard shows a message showing the status of deployment like this:

9. When successfully deployed, you can create spiders from the spiders' window in the dashboard:

10. You can create the spider in the next window by clicking the Run button.

11. This will prompt you to enter some options if needed. Otherwise, you can go with the default values provided. Click on the Run button to start the spider.

When you return to your dashboard, you can see your spider in any sections like queued, running, or completed.
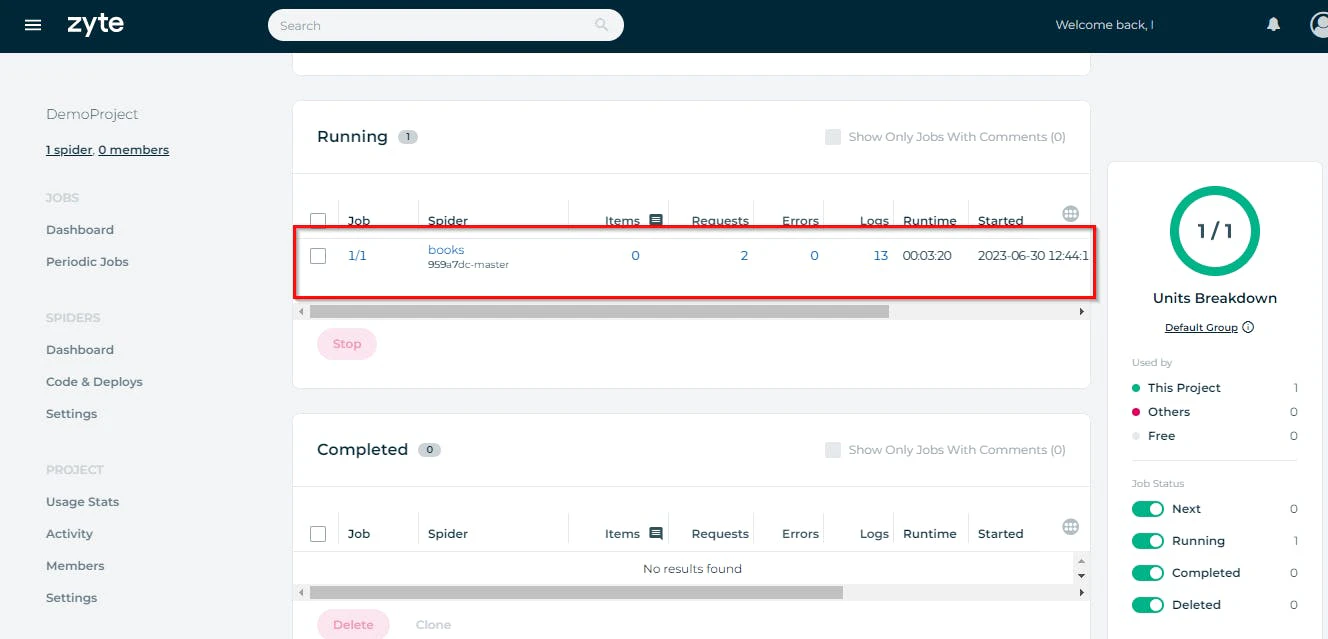

When the spider has completed its job, it will show how many items it has scraped in the items column. You can see the scraped data by clicking on this item’s value.

This shows all the items (books, in our case). You can download this data in multiple formats like CSV, JSON, or XML.
If you want to dive deeper into the technical details, check this Scrapy web scraping Python guide or Scrapy Splash tutorial.
Scheduling jobs on Scrapy Cloud
You can schedule your spider to automatically run in some interval of time. For this, you can go to your dashboard's “Periodic Jobs” section and click “Add Periodic Job.”

This will give you a prompt to set certain options for your scheduled job. You can set these options and click the “Save” button.
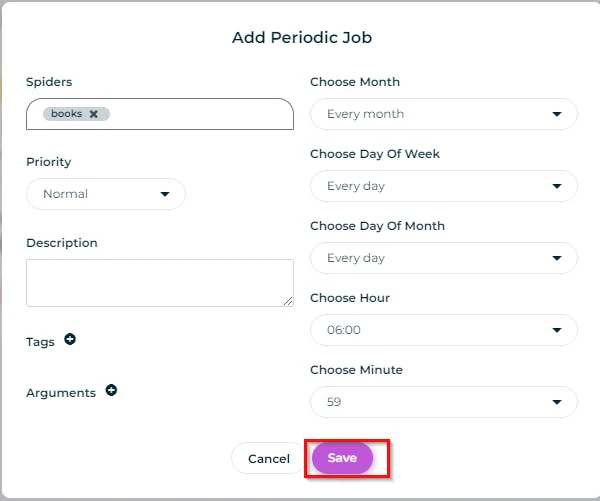
Once set, this spider will run automatically after the saved time interval. It is important to note that this feature is only available in the paid Scrapy Cloud plan.
Downsides of Scrapy Cloud
Despite its several perks, the Scrapy Cloud platform may have its own limitations and drawbacks. Consideration of these drawbacks is inevitable before making any decision to choose this platform. Let’s outline a few of these possible downsides.
Limited customization: Although Scrapy Cloud offers a user-friendly interface for managing and monitoring spiders, it may be restricted in customizing the scraping process. Because the platform is intended to be user-friendly and abstract away technical complexities, more advanced customization possibilities may be limited. This may disadvantage users needing precise control over their scraping operations.
Infrastructure dependency: To run your spiders when using Scrapy Cloud, you must rely on the servers and infrastructure of Scrapinghub. While this may be useful for scaling and managing the underlying infrastructure, it also implies that any outage or performance problems encountered by Scrapinghub may directly impact your scraping operations.
Alternatives to Scrapy Cloud
If you’re curious to explore Scrapy Cloud alternatives, Oxylabs’ Web Scraper API is definitely one of them. It can help by providing cost-effective, scalable, and reliable solutions to your web scraping problems.
With Oxylabs’ Web Scraper API, you can effortlessly scrape and extract data from even the most complex websites. Oxylabs’ Scraper API comes together with an integrated and patented proxy rotator, JavaScript rendering, and other smart AI techniques for fast and reliable data scraping and extraction.
Another alternative is to run a serverless Scrapy on AWS Lambda. It allows you to easily scale your scraping projects up and down as needed, while having cost-effectiveness in mind.
Conclusion
Scrapy Cloud offers a cloud-based solution to deploy, manage, and actively monitor Scrapy projects. However, it has its limitations. As an alternative, Oxylabs’ Web Scraper API provides an out-of-the-box scraping solution with a flexible cost model. Additionally, it is easy to use, includes CAPTCHA handling, has integrated proxies, and even features AI-based auto-scraping for e-commerce platforms.
Frequently asked questions
Is Scrapy free to use?
Yes, Scrapy is a free and open-source framework. The framework is available under the open-source BSD license. Anyone can use, alter, and distribute it for free. You can use Scrapy's features without paying any upfront licensing fees for personal or business applications.
About the author

Maryia Stsiopkina
Former Senior Content Manager
Maryia Stsiopkina was a Senior Content Manager at Oxylabs. As her passion for writing was developing, she was writing either creepy detective stories or fairy tales at different points in time. Eventually, she found herself in the tech wonderland with numerous hidden corners to explore. At leisure, she does birdwatching with binoculars (some people mistake it for stalking), makes flower jewelry, and eats pickles.
All information on Oxylabs Blog is provided on an "as is" basis and for informational purposes only. We make no representation and disclaim all liability with respect to your use of any information contained on Oxylabs Blog or any third-party websites that may be linked therein. Before engaging in scraping activities of any kind you should consult your legal advisors and carefully read the particular website's terms of service or receive a scraping license.
Related articles






Secure Residential Proxies starting at $8
Access a reliable proxy pool with over 175M Residential IPs covering 195 countries.

Get the latest news from data gathering world
Scale up your business with Oxylabs®
Proxies
Advanced proxy solutions
Data Collection
Datasets
Resources
Innovation hub
Secure Residential Proxies starting at $8
Access a reliable proxy pool with over 175M Residential IPs covering 195 countries.