175M+ ethically sourced IPs built for the highest reliability.
High-speed, cost-effective proxies built for any scraping workload.
Premium static residential proxies from trusted ASNs for most difficult targets.
Dedicated IPs from premium ASNs for demanding scraping.

AI-powered proxy solution for optimized web scraping performance.

20M+ IP addresses from real mobile devices for precise targeting.

Free Chrome proxy manager extension that works with any proxy provider.

Free Android proxy manager app that works with any proxy provider.

Free community-driven tools to improve your web scraping projects.
Web Scraper API
All-in-one web data collection platform for every stage of web scraping.
Fast Search API
Ultra-fast organic search results scraper tailored for AI workflows.
Headless Browser
Advanced browser automation solution for AI agents and scraping.
AI Studio
A suite of AI-powered tools for various scraping projects.

Documentation
All features, parameters, and integration details, backed by code samples in every coding language.
Tutorials, samples, and guides.
Latest fixes and features.






![]() AI Summary:
AI Summary:
From data extraction to model training, this tutorial shows how web scraping supports machine learning pipelines in practice. You’ll learn how to gather structured stock data and transform it into inputs for a neural network model.
While web scraping as we know it today has existed for well over a decade now, its relevance has never been more profound. The ability to make it useful and value-generating is currently applicable to almost all slices of business and beyond.
Here are some of the factors that provide evidence for web scraping’s ever-increasing necessity in businesses:
Scheduling and automation
Quick, low maintenance results
Cost-effectiveness
Enablement of competitive advantages such as data based market analysis
Data gathering to better understand the needs of your customers
And many more.
The main question is how will the already successful data scraping techniques be affected by machine learning?
What is machine learning?
First, let’s take a more in-depth look at the primary features of machine learning (ML). As an essential component of data science and a branch/byproduct of AI, it aims to imitate the way humans learn. It does so by gathering data and using algorithms, which are then used for gradual self-improvement in terms of predictions and their accuracy.
Such features are rather convenient since they allow for a more hands-off approach, i.e., instead of hand-coding various software routines or instructions, this will enable you to achieve a specific given task primarily through a machine with little interference from a developer.
The next question is how the benefits of ML translate to real-life scenarios? To answer this, let’s look at some use cases.
Customer service: chatbots are starting to replace human agents, with FAQs often being answered without a human reply. The Virtual Agents of Slack and Facebook are prime examples of this.
Web Unblocker: an AI-powered proxy solution, allows for block-free data gathering. This proxy solution contains ML-driven proxy management as well as ML-powered response recognition both of which ensure an effortless data collection process.
Computer Vision: the AI, and as such, ML technology, allows for the extraction of meaningful information taken solely from visual data, upon which recognition tasks can be achieved. A prime example of this use is ML integration within self-driving cars.
Stock trading: enables automated trading that optimizes stock portfolios by potentially making millions of automated trades per day.
The importance of web scraping in machine learning
Having discussed the features of Machine Learning, let’s take a look at how they all translate within web scraping.
Primarily, web scraping in ML is centered around the core problem of gathering quality data.
While the internal information gathered on day-to-day business can provide valuable insights, such data is insufficient. Therefore, gathering from external sources is essential, although a more complex task. Inaccuracy/poor data quality becomes a severe concern when scraping, and a final clean-up step must always be included within any scraping project, though this will be discussed in greater detail later on in this guide.
Using machine learning for web scraping
The following example collects historical stock prices using web scraping. Data points, such as daily opening, daily highest, daily lowest, daily closing, will be collected as well.
Thankfully, numerous websites provide such data, and it’s usually, conveniently, presented in a table. Typically, you’ll see the HTML code that renders these tables, such as the following image.
You can find all codes used in this guide on our GitHub.
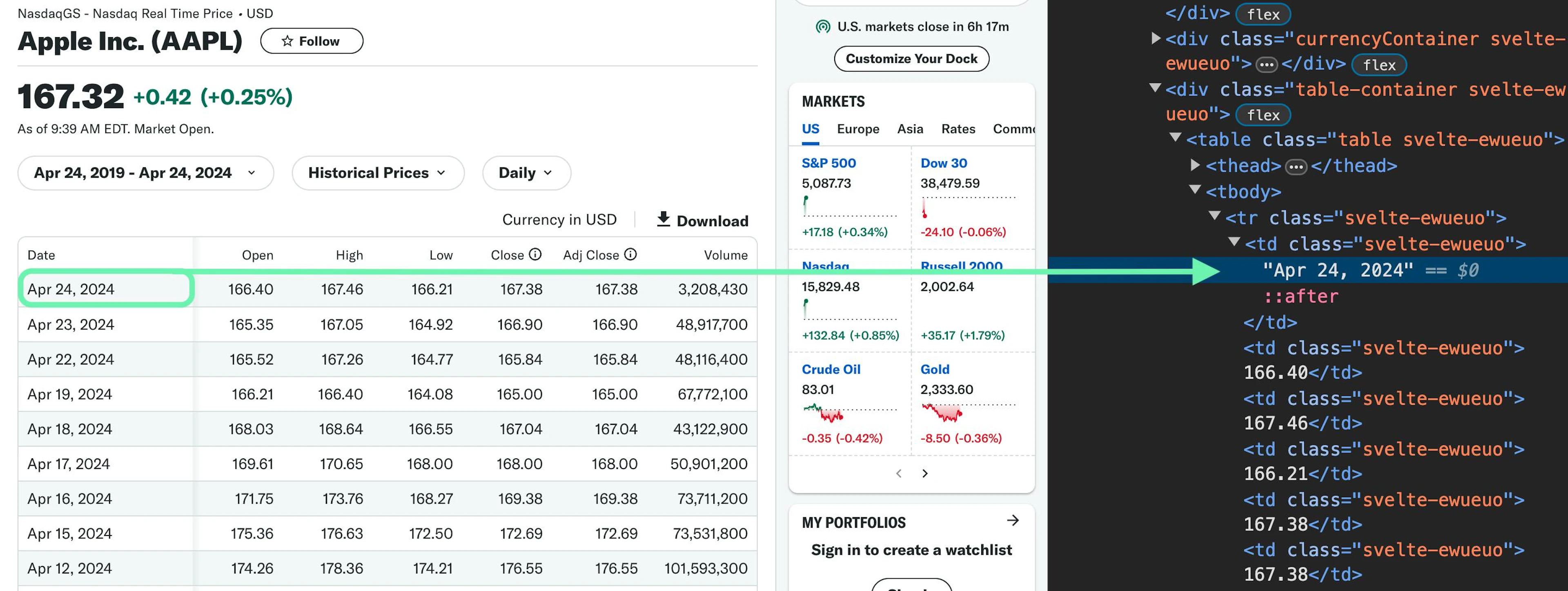
Typical stock data along with HTML markup
With that in mind, let’s get started with the first step of web scraping.
Project requirements
In this blog, we’ll be working with Python 3.9. However, this code will work with Python 3.7 and 3.8 as well.
There are two sets of requirements for this project. Firstly, libraries for web scraping and secondly, libraries for machine learning.
For web scraping, we’ll need Requests-HTML and BeautifulSoup4. Install these from the terminal as follows:
$ python3 -m pip install requests_html beautifulsoup4In regards to machine learning, we’ll be using multiple libraries instead. Primarily, Pandas and Numpy are going to be our choice on how to handle our data. For visualization, Matplotlib will be our choice. For preprocessing data, we’ll need help from the SciKit Learn library. Finally, we’ll use Tensorflow for creating a neural network machine learning model. Install all these libraries from the terminal as follows:
$ python3 -m pip install pandas numpy matplotlib seaborn tensorflow scikit-learn kerasExtracting the data
If we’re looking at machine learning projects, Jupyter Notebook is a great choice as it’s easier to run and rerun a few lines of code. Moreover, the plots are in the same Notebook.
Begin with importing required libraries as follows:
from requests_html import HTMLSession
import pandas as pdFor web scraping, we only need Requests-HTML. The primary reason is that Requests-HTML is a powerful library that can handle all our web scraping tasks, such as extracting the HTML code from websites and parsing this code into Python objects. Further benefits come from the library’s ability to function as an HTML parser, meaning collecting data and labeling can be performed using the same library.
Next, we use Pandas for loading the data in a DataFrame for further processing.
In the next cell, create a session and get the response from your target URL.
url = 'https://finance.yahoo.com/quote/AAPL/history?p=AAPL&guccounter=1&period1=1556113078&period2=1713965616'
session = HTMLSession()
r = session.get(url)After this, use XPath to select the desired data. It’ll be easier if each row is represented as a dictionary where the key is the column name. All these dictionaries can then be added to a list.
rows = r.html.xpath('//table/tbody/tr')
symbol = 'AAPL'
data = []
for row in rows:
if len(row.xpath('.//td')) < 7:
continue
data.append({
'Symbol':symbol,
'Date':row.xpath('.//td[1]/text()')[0],
'Open':row.xpath('.//td[2]/text()')[0],
'High':row.xpath('.//td[3]/text()')[0],
'Low':row.xpath('.//td[4]/text()')[0],
'Close':row.xpath('.//td[5]/text()')[0],
'Adj Close':row.xpath('.//td[6]/text()')[0],
'Volume':row.xpath('.//td[7]/text()')[0]
})
df = pd.DataFrame(data)The results of web scraping are being stored in the variable data. To understand why such actions are taken, we must consider that these variables are a list of dictionaries that can be easily converted to a data frame. Furthermore, completing the steps mentioned above will also help to complete the vital step of data labeling.
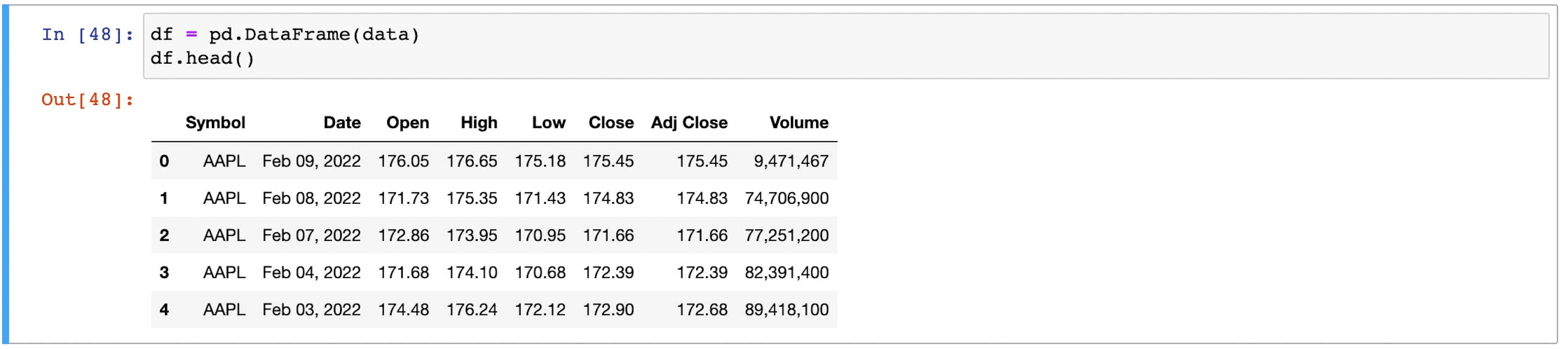
Scraped data loaded in a data frame
The provided example’s data frame is not yet ready for the machine learning step. It still needs additional cleaning.
Cleaning the data
Now that the data has been collected using web scraping, we need to clean it up. The primary reason for this action is uncertainty whether the data frame is acceptable; therefore, it’s recommended to verify everything by running df.info().
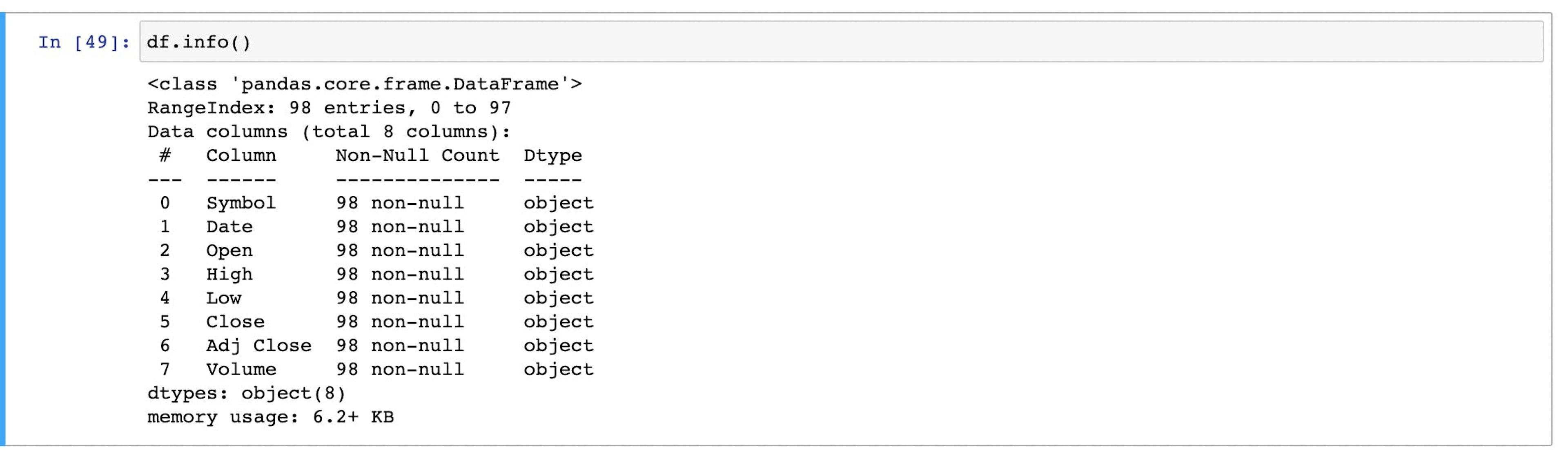
Data frame has everything stored as strings
As evident from the above screen-print, all the columns have data type as object. For machine learning algorithms, these should be numbers.
Dates can be handled using Pandas.to_datetime. It’ll take a series and convert the values to datetime. This can then be used as follows:
df['Date'] = pd.to_datetime(df['Date'])The issue we ran into now is that the other columns were not automatically converted to numbers because of comma separators.
Thankfully, there are multiple ways to handle this. The easiest one is to remove the comma by calling str.replace() function. The astype function can also be called in the same line which will then return a float.
str_cols = ['High', 'Low', 'Close', 'Adj Close', 'Volume']
df[str_cols]=df[str_cols].replace(',', '', regex=True).astype(float)Finally, if there are any None or NaN values, these can be deleted by calling the dropna().
df.dropna(inplace=True)As the last step, set the Date column as the index and preview the data frame.
df = df.set_index('Date')
df.head()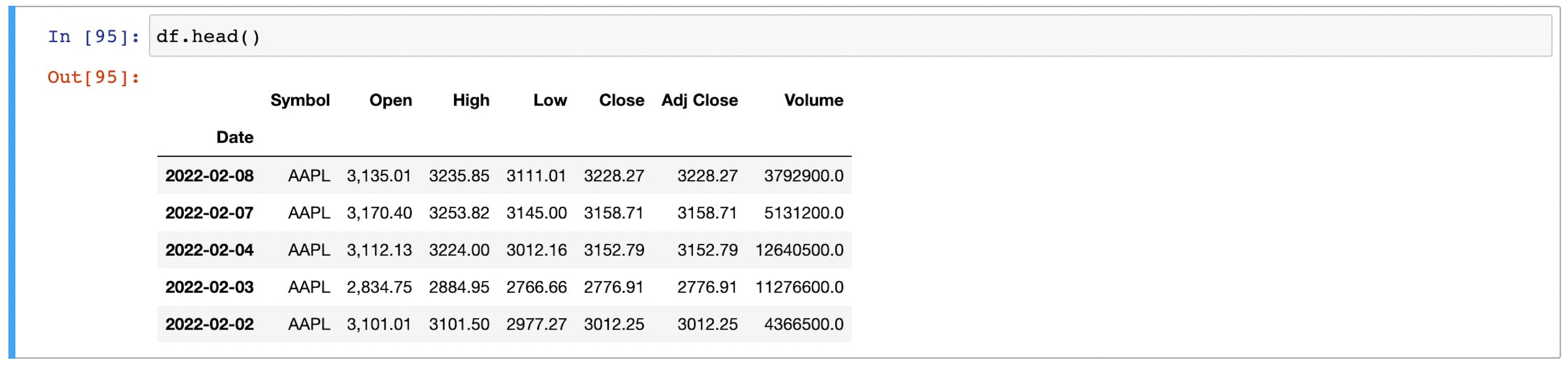
The clean DataFrame is now ready to be processed.
The data frame is now clean and ready to be sent to the machine learning model.
Visualizing the data
Before we begin the section on machine learning, let’s have a quick look at the closing price trend.
First, import the packages and set the plot styles:
import matplotlib.pyplot as plt
import seaborn as sns
sns.set_style('darkgrid')
plt.style.use('ggplot')Next, enter the following lines to plot the Adj Close, which is the adjusted closing price:
plt.figure(figsize=(15, 6))
df['Adj Close'].plot()
plt.ylabel('Adj Close')
plt.xlabel(None)
plt.title('Closing Price of AAPL')
plt.show()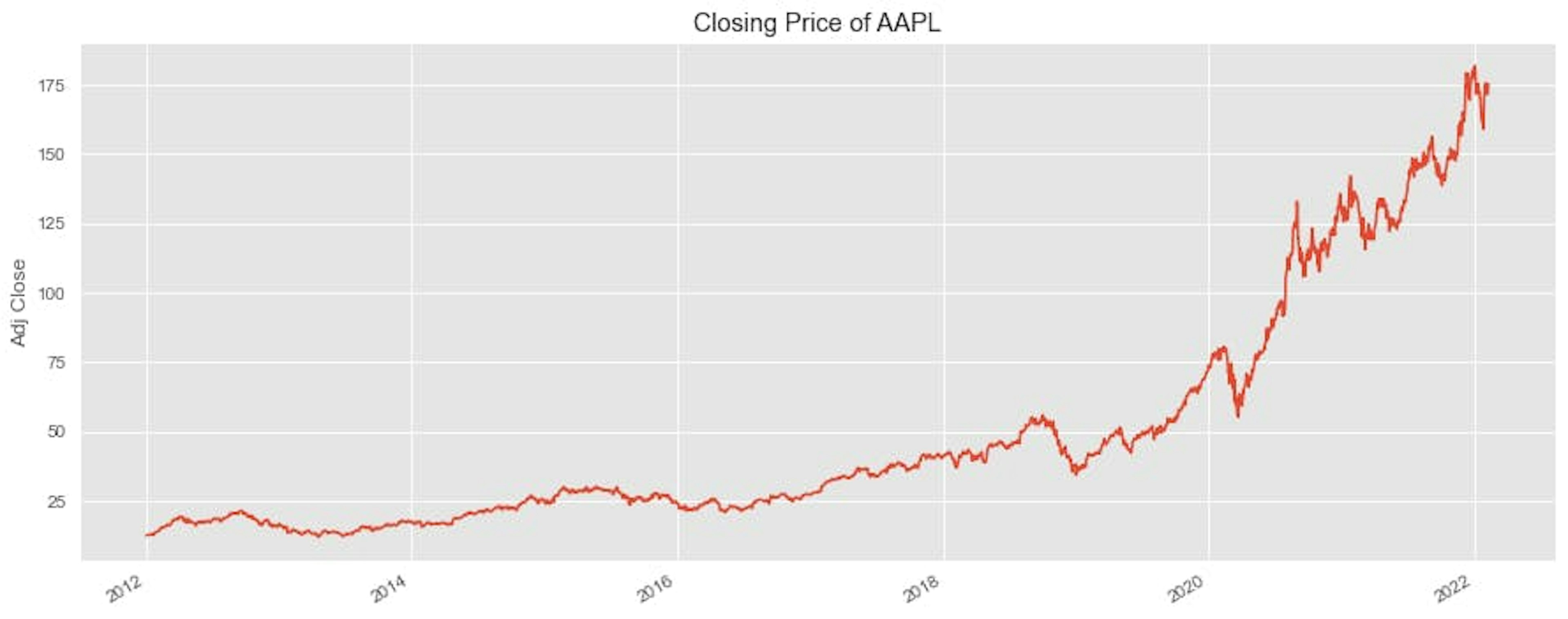
Plotting the adjusted closing price of AAPL
Preparing data for machine learning
The first step to machine learning is the selection of features and values we want to predict.
In this example, the “Adjusted Close” is dependent on the “Close” part. Therefore, we’ll ignore the Close column and focus on Adj Close.
The features are usually stored in a variable named X and the values that we want to predict are stored in a variable y.
features = ['Open', 'High', 'Low', 'Volume']
y = df.filter(['Adj Close'])The next step we have to consider is feature scaling. It’s used to normalize the features, i.e., the independent variables. Within our example, we can use MinMaxScaler. This class is part of the preprocessing module of the Sci Kit Learn library.
First, we’ll create an object of this class. Then, we’ll train and transform the values using the fit_transform method as follows:
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
X = scaler.fit_transform(df[features])The next step is splitting the data we have received into two datasets, test and training.
The example we’re working with today is a time-series data, meaning data that changes over a time period requires specialized handling. The TimeSeriesSplit function from SKLearn’s model_selection module will be what we need here.
from sklearn.model_selection import TimeSeriesSplit
tscv = TimeSeriesSplit(n_splits=10)
for train_index, test_index in tscv.split(X):
X_train, X_test = X[train_index], X[test_index]
y_train, y_test = y.iloc[train_index], y.iloc[test_index]Our approach for today will be creating a neural network that uses an LSTM or a Long Short-Term Memory layer. LSTM expects a 3-dimensional input with information about the batch size, timesteps, and input dimensions. We need to reshape the features as follows:
X_train = X_train.reshape(X_train.shape[0], 1, X_train.shape[1])
X_test = X_test.reshape(X_test.shape[0], 1, X_test.shape[1])Training the model and predictions
We’re now ready to create a model. Import the Sequential model, LSTM layer, and Dense layer from Keras as follows:
from keras.models import Sequential
from keras.layers import LSTM, DenseContinue by creating an instance of the Sequential model and adding two layers. The first layer will be an LSTM with 32 units while the second will be a Dense layer.
model = Sequential()
model.add(LSTM(32, activation='relu', return_sequences=False))
model.add(Dense(1))
model.compile(loss='mean_squared_error', optimizer='adam')The model can be trained with the following line of code:
model.fit(X_train, y_train, epochs=100, batch_size=8)While the predictions can be made using this line of code:
y_pred= model.predict(X_test)Finally, let’s plot the actual values and predicted values with the following:
plt.figure(figsize=(15, 6))
plt.plot(y_test.values, label='Actual Value')
plt.plot(y_pred, label='Predicted Value')
plt.ylabel('Adjusted Close (Scaled)')
plt.xlabel('Time Scale')
plt.legend()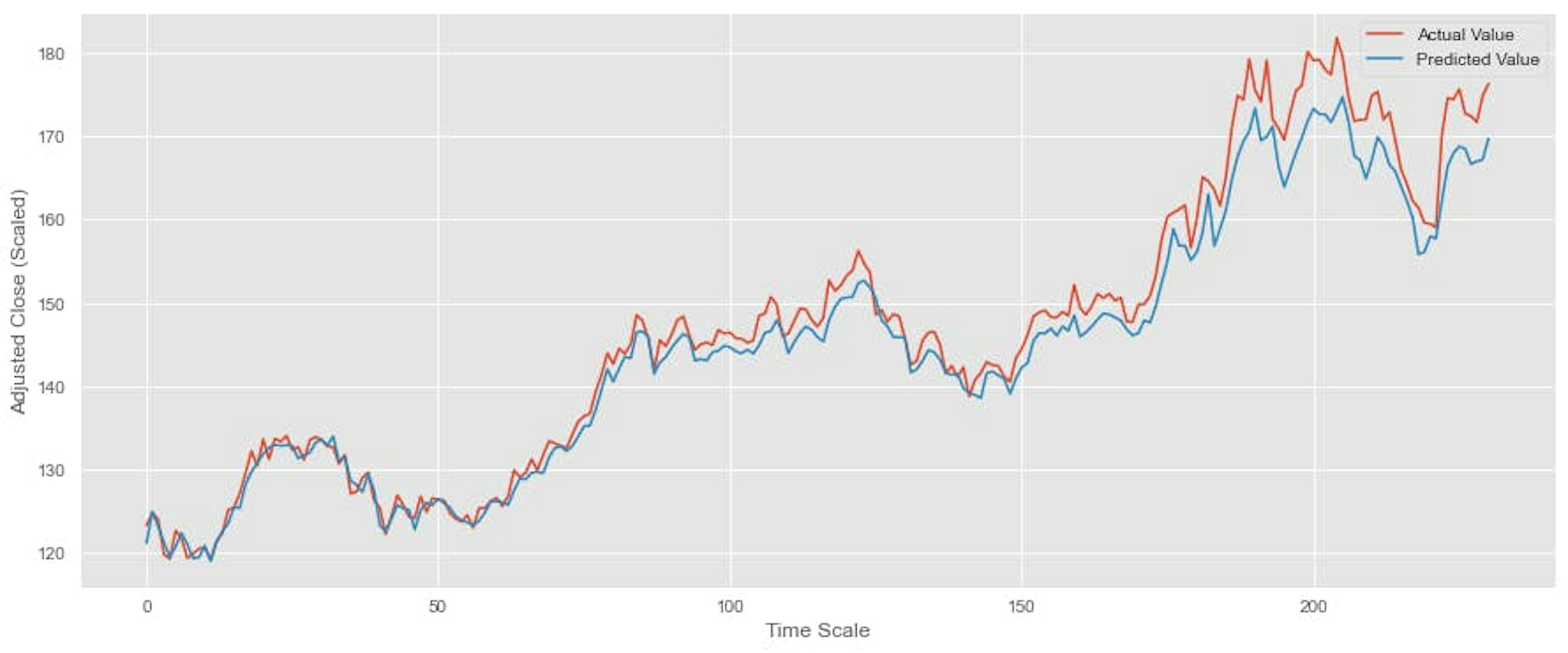
The trend and values of the predictions are very close.
The plot shows that the predictions are close to the actual values. Yet, more importantly, the trends are similarly close as well.
Full code for machine learning
from requests_html import HTMLSession
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.preprocessing import MinMaxScaler
from sklearn.model_selection import TimeSeriesSplit
from keras.models import Sequential
from keras.layers import LSTM, Dense
url = 'https://finance.yahoo.com/quote/AAPL/history?p=AAPL&guccounter=1&period1=1556113078&period2=1713965616'
session = HTMLSession()
r = session.get(url)
rows = r.html.xpath('//table/tbody/tr')
symbol = 'AAPL'
data = []
for row in rows:
if len(row.xpath('.//td')) < 7:
continue
data.append({
'Symbol':symbol,
'Date':row.xpath('.//td[1]/text()')[0],
'Open':row.xpath('.//td[2]/text()')[0],
'High':row.xpath('.//td[3]/text()')[0],
'Low':row.xpath('.//td[4]/text()')[0],
'Close':row.xpath('.//td[5]/text()')[0],
'Adj Close':row.xpath('.//td[6]/text()')[0],
'Volume':row.xpath('.//td[7]/text()')[0]
})
df = pd.DataFrame(data)
df['Date'] = pd.to_datetime(df['Date'])
str_cols = ['High', 'Low', 'Close', 'Adj Close', 'Volume']
df[str_cols]=df[str_cols].replace(',', '', regex=True).astype(float)
df.dropna(inplace=True)
df = df.set_index('Date')
df.head()
sns.set_style('darkgrid')
plt.style.use('ggplot')
plt.figure(figsize=(15, 6))
df['Adj Close'].plot()
plt.ylabel('Adj Close')
plt.xlabel(None)
plt.title('Closing Price of AAPL')
plt.show()
features = ['Open', 'High', 'Low', 'Volume']
y = df.filter(['Adj Close'])
scaler = MinMaxScaler()
X = scaler.fit_transform(df[features])
tscv = TimeSeriesSplit(n_splits=10)
for train_index, test_index in tscv.split(X):
X_train, X_test = X[train_index], X[test_index]
y_train, y_test = y.iloc[train_index], y.iloc[test_index]
X_train = X_train.reshape(X_train.shape[0], 1, X_train.shape[1])
X_test = X_test.reshape(X_test.shape[0], 1, X_test.shape[1])
model = Sequential()
model.add(LSTM(32, activation='relu', return_sequences=False))
model.add(Dense(1))
model.compile(loss='mean_squared_error', optimizer='adam')
model.fit(X_train, y_train, epochs=100, batch_size=8)
y_pred= model.predict(X_test)
plt.figure(figsize=(15, 6))
plt.plot(y_test.values, label='Actual Value')
plt.plot(y_pred, label='Predicted Value')
plt.ylabel('Adjusted Close (Scaled)')
plt.xlabel('Time Scale')
plt.legend()
plt.show()Conclusion
This tutorial explored a real-life scenario where web scraping and machine learning work in tandem. We went through writing a web scraping program that can extract data in a format suitable for machine learning. Then, we cleaned the data, updated its type, and applied other preprocessing techniques to make the combined effort ideal for the machine learning program. Finally, we finished by creating a machine learning model that used a neural network to predict stock pricing, which altogether, hopefully, gave you a valuable introduction to how web scraping can be used for machine learning.
Building an in-house web scraping tool has its challenges; thus, we offer ready-made web intelligence solutions for collecting AI training data, such as Web Scraper API, with features for AI web scraping – OxyCopilot. Be sure to try them out with a free trial. Or, take a look at our article on AI scraping to learn more about the topic of web scraping and AI.
If you want to know more about how proxies and advanced data acquisition tools work or are simply curious to see specific web scraping use cases, such as web scraping job postings, web scraping with Python, and building a yellow page scraper, check out our blog.
Forget about complex web scraping processes
Choose Oxylabs' advanced web intelligence collection solutions to gather real-time public data hassle-free.
About the author

Danielius Radavicius
Former Copywriter
Danielius Radavičius was a Copywriter at Oxylabs. Having grown up in films, music, and books and having a keen interest in the defense industry, he decided to move his career toward tech-related subjects and quickly became interested in all things technology. In his free time, you'll probably find Danielius watching films, listening to music, and planning world domination.
All information on Oxylabs Blog is provided on an "as is" basis and for informational purposes only. We make no representation and disclaim all liability with respect to your use of any information contained on Oxylabs Blog or any third-party websites that may be linked therein. Before engaging in scraping activities of any kind you should consult your legal advisors and carefully read the particular website's terms of service or receive a scraping license.
Related articles

Web Crawler vs Web Scraper: The Differences

Gabija Fatėnaitė
2024-10-04

How to Make Web Scraping Faster – Python Tutorial

Yelyzaveta Hayrapetyan
2023-03-29

6 Web Scraping Project Ideas to Sharpen Your Skills
Gabija Fatėnaitė
2022-08-31

Get the latest news from data gathering world
Scale up your business with Oxylabs®
Proxies
Advanced proxy solutions
Data Collection
Datasets
Resources
Innovation hub
Forget about complex web scraping processes
Choose Oxylabs' advanced web intelligence collection solutions to gather real-time public data hassle-free.