175M+ ethically sourced IPs built for the highest reliability.
High-speed, cost-effective proxies built for any scraping workload.
Premium static residential proxies from trusted ASNs for most difficult targets.
Dedicated IPs from premium ASNs for demanding scraping.

AI-powered proxy solution for optimized web scraping performance.

20M+ IP addresses from real mobile devices for precise targeting.

Free Chrome proxy manager extension that works with any proxy provider.

Free Android proxy manager app that works with any proxy provider.

Free community-driven tools to improve your web scraping projects.
Web Scraper API
All-in-one web data collection platform for every stage of web scraping.
Fast Search API
Ultra-fast organic search results scraper tailored for AI workflows.
Headless Browser
Advanced browser automation solution for AI agents and scraping.
AI Studio
A suite of AI-powered tools for various scraping projects.

Documentation
All features, parameters, and integration details, backed by code samples in every coding language.
Tutorials, samples, and guides.
Latest fixes and features.






![]() AI Summary:
AI Summary:
This tutorial shows how to scrape Google Lens search results using Python and Oxylabs' Google Lens API. It walks through setting up the API connection, extracting visual match data such as organic and exact match results, and saving the parsed output to JSON files.
Google Lens is a free tool that allows you to analyze images to extract data like text and identify objects, people, animals, plants, etc. You can also use it to search for visual matches similar to the one provided.
In this blog post, you’ll learn how to set up and use Oxylabs’ Google Lens API, a part of Google Scraper API, to scrape Google Lens search results, extracting the image search data you need and saving it to a file.
Setting up
To start off, let’s set up a connection to the Google Lens API and use the google_lens source. You can do that by following the instructions provided in our documentation.
Try for free
Get a free trial to test Google Lens API.
Up to 2K free results
No credit card required
To simplify the setup, download and install the requests library using pip:
pip install requestsHere’s how your main.py code file should look like:
import requests
from pprint import pprint
# Structure payload.
payload = {
"source": "google_lens",
"query": "https://www.beginningboutique.com.au/cdn/shop/files/Flossie-Pink-Maxi-Sleeveless-Dress_750x.jpg",
"parse": "true"
}
# Get a response.
response = requests.request(
"POST",
"https://realtime.oxylabs.io/v1/queries",
auth=("USERNAME", "PASSWORD"),
json=payload,
)
# Print prettified response to stdout.
pprint(response.json())As you can see, the example already sets some query parameters, like parse. This suits our needs perfectly, as it returns search engine information that’s already parsed into a defined dictionary. With this parameter enabled, you won't need to use XPath or CSS selectors to select HTML elements. Additionally, you can add the locale parameter to retrieve page results in supported Google languages. You can explore all the other configurable parameters by looking at the documentation.
Fill in USERNAME and PASSWORD with your Oxylabs API credentials and run the code. It should print you out the results of the scraping job.
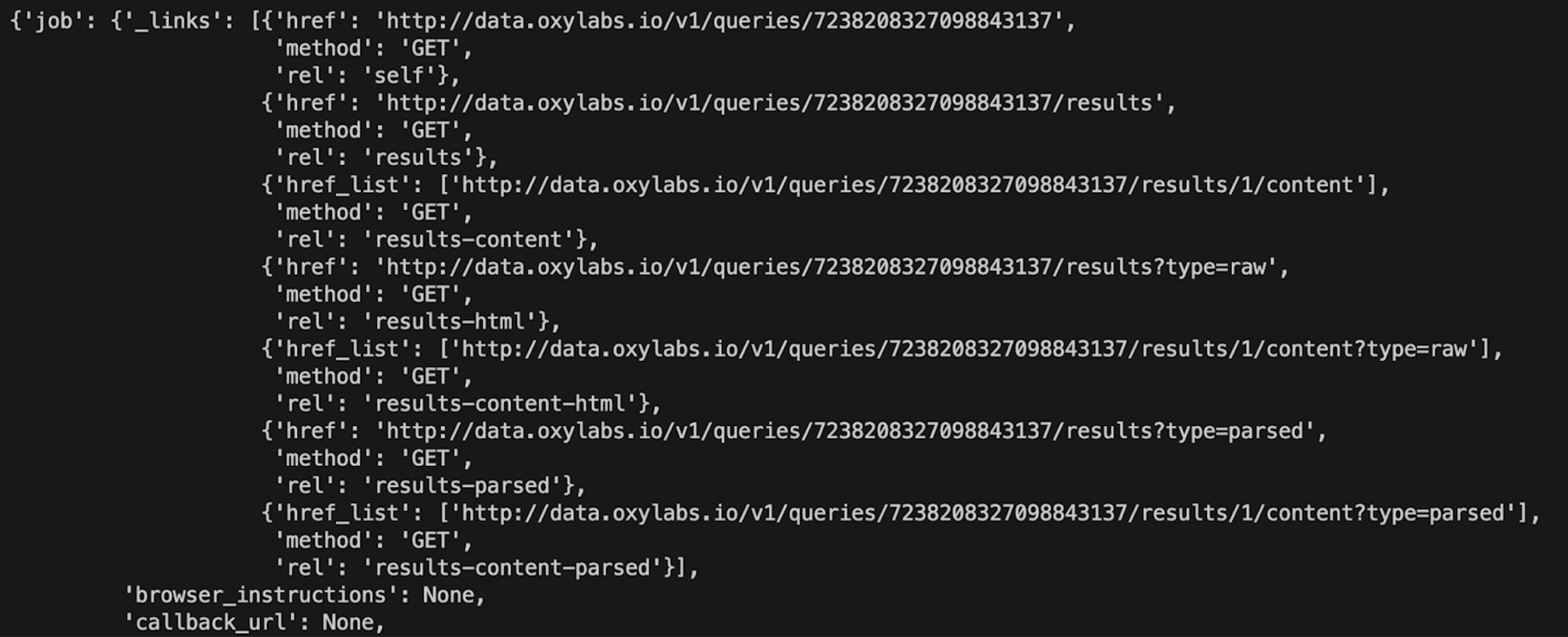
Extracting information
Now that you have the Google search results scraped and returned let’s extract the specific fields that contain the data you need and return it as a dict of visual matches results:
def extract_results(raw_results, result_type):
processed_results = []
for raw_result in raw_results:
result = {
"type":result_type,
"title": raw_result["title"],
"url": raw_result["url"],
"position": raw_result["pos"]
}
processed_results.append(result)
return processed_resultsThe function extract_results takes in raw results returned by the query to the Google Lens API and processes them into a desired format. You can then use this function to split the results for organic or exact_match:
# Structure payload.
payload = {
"source": "google_lens",
"query": "https://www.beginningboutique.com.au/cdn/shop/files/Flossie-Pink-Maxi-Sleeveless-Dress_750x.jpg",
"parse": "true"
}
response = requests.request(
"POST",
"https://realtime.oxylabs.io/v1/queries",
auth=("USERNAME", "PASSWORD"),
json=payload,
)
response_json = response.json()
organic_raw_results = response_json["results"][0]["content"]["results"]["organic"]
exact_match_raw_results = response_json["results"][0]["content"]["results"]["exact_match"]
organic_results = extract_results(organic_raw_results, "organic")
exact_match_results = extract_results(exact_match_raw_results, "exact_match")Saving to a file
Having all the desired information in the needed format, you just need to save it to a preferred file. You can do that with a simple function:
def save_results(results, filepath):
with open(filepath, "w", encoding="utf-8") as file:
json.dump(results, file, ensure_ascii=False, indent=4)
returnThe final code should look something like this:
import requests
import json
def save_results(results, filepath):
with open(filepath, "w", encoding="utf-8") as file:
json.dump(results, file, ensure_ascii=False, indent=4)
return
def extract_results(raw_results, result_type):
processed_results = []
for raw_result in raw_results:
result = {
"type":result_type,
"title": raw_result["title"],
"url": raw_result["url"],
"position": raw_result["pos"]
}
processed_results.append(result)
return processed_results
payload = {
"source": "google_lens",
"query": "https://www.beginningboutique.com.au/cdn/shop/files/Flossie-Pink-Maxi-Sleeveless-Dress_750x.jpg",
"parse": "true"
}
response = requests.request(
"POST",
"https://realtime.oxylabs.io/v1/queries",
auth=("USERNAME", "PASSWORD"),
json=payload,
)
response_json = response.json()
organic_raw_results = response_json["results"][0]["content"]["results"]["organic"]
exact_match_raw_results = response_json["results"][0]["content"]["results"]["exact_match"]
organic_results = extract_results(organic_raw_results, "organic")
exact_match_results = extract_results(exact_match_raw_results, "exact_match")
save_results(organic_results, "organic.json")
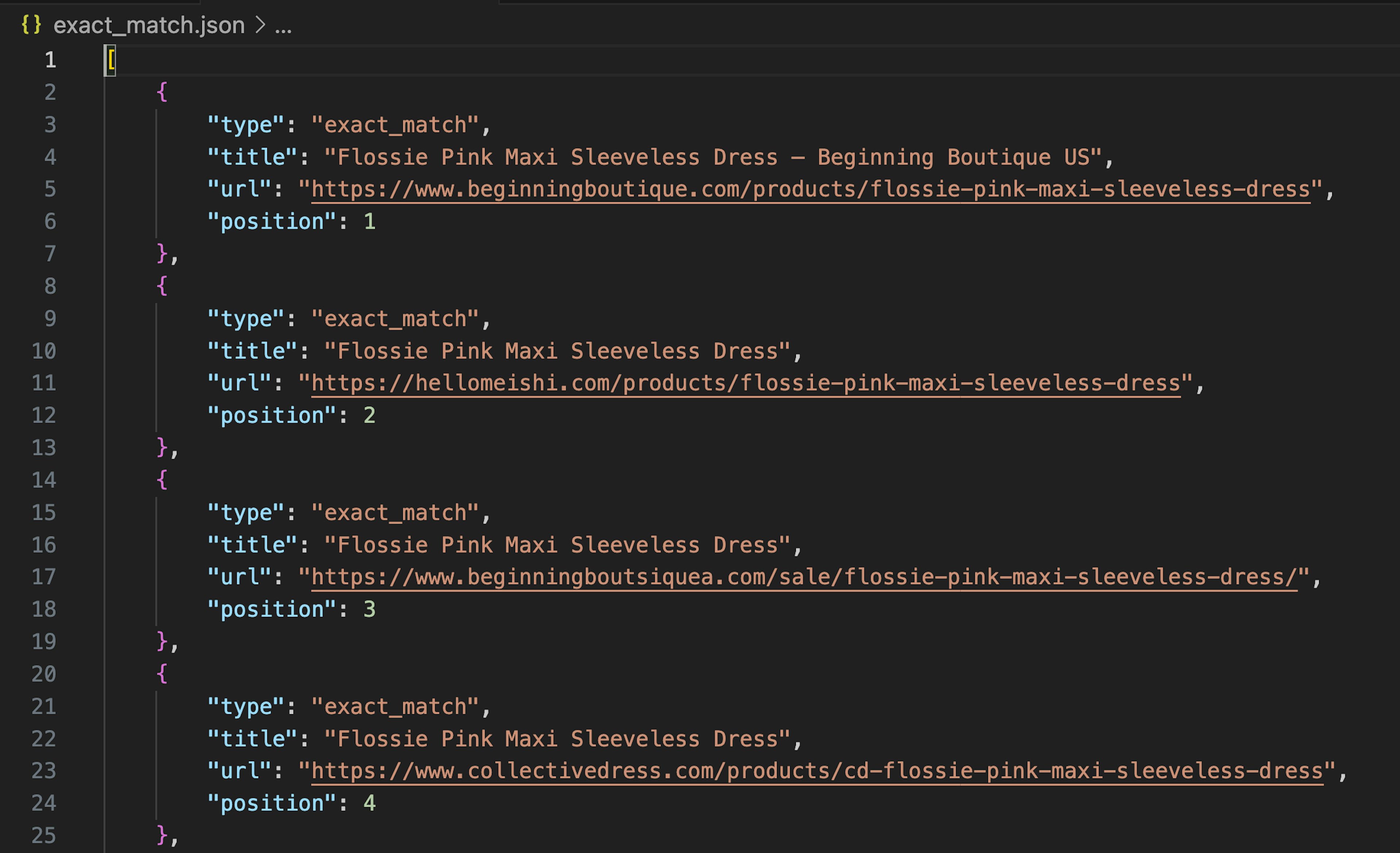
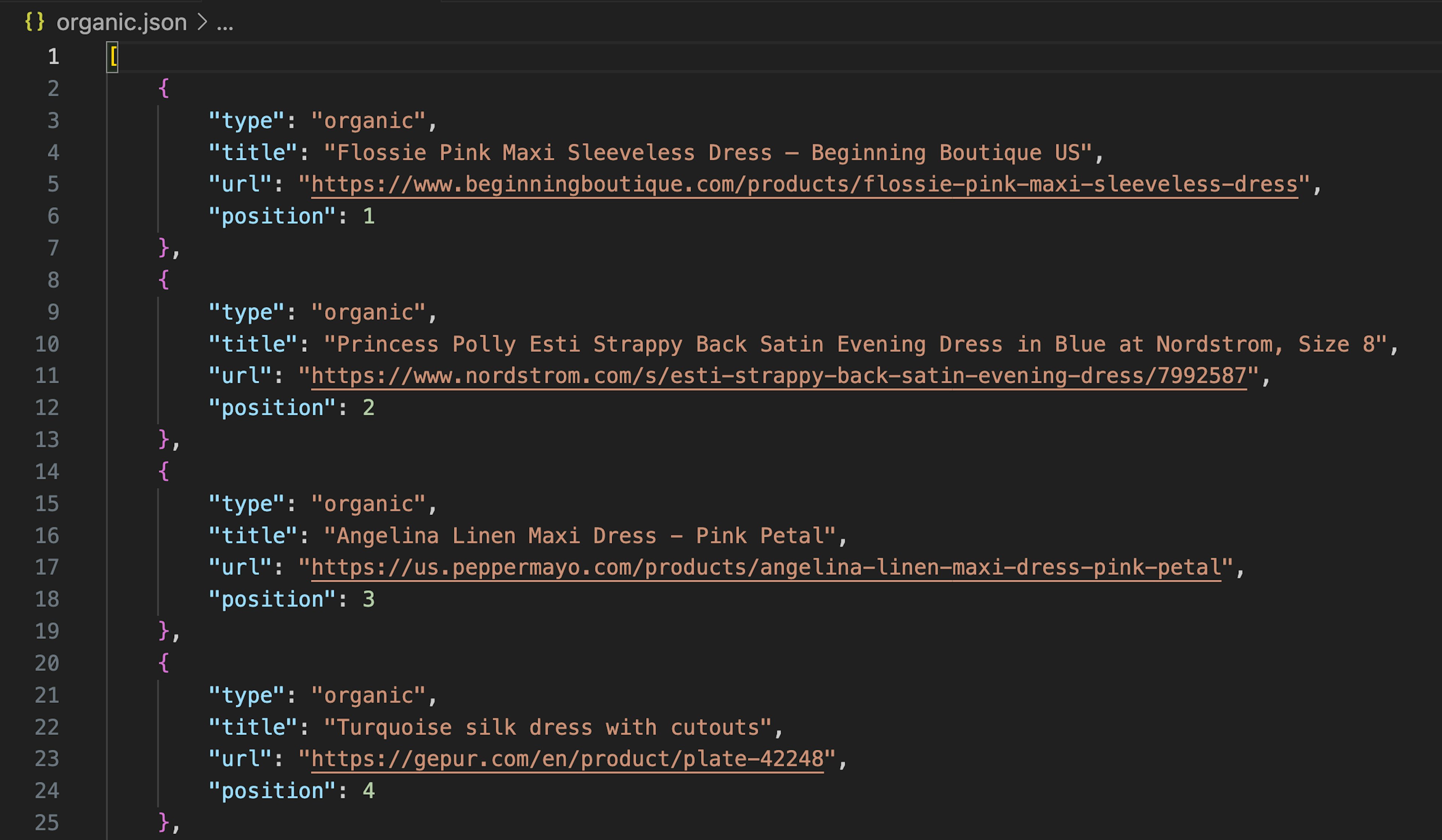
save_results(exact_match_results, "exact_match.json")After running the code, you should see two JSON files in your working directory. The exact_match.json file contains exact Google results, while the organic.json file contains other visual matches found via the Google Lens search engine.
exact_match.json file
organic.json file
Conclusion
This tutorial shows how to scrape Google Lens results using Oxylabs’ Scraper API. By following these steps, you can set up your environment, extract relevant data, and save it to a file for easy access. This approach provides a simple and efficient way to handle access restrictions and automate Google Lens image data extraction using Python. For speed-sensitive projects, consider using Fast Search API to get organic search results in under a second.
Additionally, you can use the API to scrape Google Ads, Google Search Autocomplete, Google Image Search, Google News, Google Trends, Google AI Mode, and other services provided by Google.
Frequently asked questions
Can you scrape Google results?
Yes, with the Oxylabs’ Scraper API, it's also possible to gather publicly-available search results. Visit the documentation to learn more.
How to extract text from Google Lens?
Can you save Google Lens results?
About the author

Vytenis Kaubrė
Technical Content Researcher
Vytenis Kaubrė was a Technical Content Researcher at Oxylabs. Creative writing and a growing interest in technology fueled his work, where he researched and crafted technical content while honing his skills in Python. Off duty, he could often be found working on personal projects, learning about cybersecurity, or relaxing with a book.
All information on Oxylabs Blog is provided on an "as is" basis and for informational purposes only. We make no representation and disclaim all liability with respect to your use of any information contained on Oxylabs Blog or any third-party websites that may be linked therein. Before engaging in scraping activities of any kind you should consult your legal advisors and carefully read the particular website's terms of service or receive a scraping license.
Related articles

Cheerio vs. Puppeteer: Which Should You Use for Web Scraping?

Shinthiya Nowsain Promi
2026-06-23



List Crawling in Python: Tools, Tips, and Techniques

Danielė Virinaitė
2026-06-17
Try Google Lens API
Choose Oxylabs' Google Lens API to gather real-time search data hassle-free.

Get the latest news from data gathering world
Scale up your business with Oxylabs®
Proxies
Advanced proxy solutions
Data Collection
Datasets
Resources
Innovation hub
Try Google Lens API
Choose Oxylabs' Google Lens API to gather real-time search data hassle-free.