175M+ ethically sourced IPs built for the highest reliability.
High-speed, cost-effective proxies built for any scraping workload.
Premium static residential proxies from trusted ASNs for most difficult targets.
Dedicated IPs from premium ASNs for demanding scraping.

AI-powered proxy solution for optimized web scraping performance.

20M+ IP addresses from real mobile devices for precise targeting.

Free Chrome proxy manager extension that works with any proxy provider.

Free Android proxy manager app that works with any proxy provider.

Free community-driven tools to improve your web scraping projects.
Web Scraper API
All-in-one web data collection platform for every stage of web scraping.
Fast Search API
Ultra-fast organic search results scraper tailored for AI workflows.
Headless Browser
Advanced browser automation solution for AI agents and scraping.
AI Studio
A suite of AI-powered tools for various scraping projects.

Documentation
All features, parameters, and integration details, backed by code samples in every coding language.
Tutorials, samples, and guides.
Latest fixes and features.






![]() AI Summary:
AI Summary:
Learn how to automate real estate data collection from Redfin using Python and Oxylabs’ Web Scraper API. The tutorial walks through extracting listings, parsing key property details, and exporting the results to a CSV file.
Real estate brokerage platforms offer a huge variety of listings that are updated constantly, making them a good target for web scraping. That said, keeping up with the real estate market in real-time and at a large scale is challenging.

What is data scraping in real estate?
Data scraping in real estate is the extraction of data from online real estate listings. The extracted data includes property listings, prices, amenities, images, and more. Data scraping typically uses automated tools that navigate real estate websites and gather data from their pages.
In this guide, you’ll learn how to collect public property data from Redfin with the help of Oxylabs Real Estate Scraper API (now part of a Web Scraper API solution) and Python. You can scrape real estate data like prices, sizes, number of beds and baths available, and addresses, increasing the likelihood of finding a good deal or understanding the market better.
You can find the following code on our GitHub.
1. Prepare environment
You can download the latest version of Python from the official website.
To store your Python code, run the following command to create a new Python file in your current directory.
touch main.pyInstall dependencies
Next, run the command below to install the dependencies required for web scraping and data processing. Let’s use Requests, Beautiful Soup, and Pandas.
pip install bs4 requests pandasImport libraries
Now, open the previously created Python file and import the installed libraries.
import requests
import pandas as pd
from bs4 import BeautifulSoup2. Prepare the API request
After importing the libraries, the following step is to prepare the payload for the API request. Using Web Scraper API, you’ll need to retrieve credentials for API authentication from the Oxylabs dashboard. Replace USERNAME and PASSWORD with your retrieved credentials.
USERNAME = "USERNAME"
PASSWORD = "PASSWORD"
payload = {
"source": "universal",
"url": "https://www.redfin.com/city/29470/IL/Chicago",
}For this example, let’s scrape real estate listings in Chicago. You can replace the url value with a Redfin home listings page of your choosing. Make sure the source parameter is set to universal.
NOTE: You can find all the parameters and more samples in our documentation.
3. Send request
Use the declared credentials and payload to send a POST request to the API. Pass the credentials and payload to the auth and JSON parameters, respectively.
response = requests.post(
url="https://realtime.oxylabs.io/v1/queries",
auth=(USERNAME, PASSWORD),
json=payload,
)
print(response.status_code)If everything works as expected, you should see a 200 status code printed out in your terminal.
As a best practice, consider adding this line after your POST request. It guarantees that the data you receive from the API is what you expect instead of an error code.
response.raise_for_status()Here’s the full code for sending the request:
response = requests.post(
url="https://realtime.oxylabs.io/v1/queries",
auth=(USERNAME, PASSWORD),
json=payload,
)
response.raise_for_status()
print(response.status_code)If you get an HTTPException, check if your payload and credentials are correct.
4. Extract HTML
The API response comes back in JSON format, equivalent to a dictionary in Python. You can use the response object and the Beautiful Soup library to extract the HTML content as follows.
html = response.json()["results"][0]["content"]
soup = BeautifulSoup(html, "html.parser")The Soup object will be used to extract the necessary data from the HTML content. Use CSS selectors to select specific data from the HTML content.
5. Parse data from HTML
Start with collecting every home listing found on the page. Navigate to the web page, right-click on the part of the listing that includes the data you need, and click Inspect.
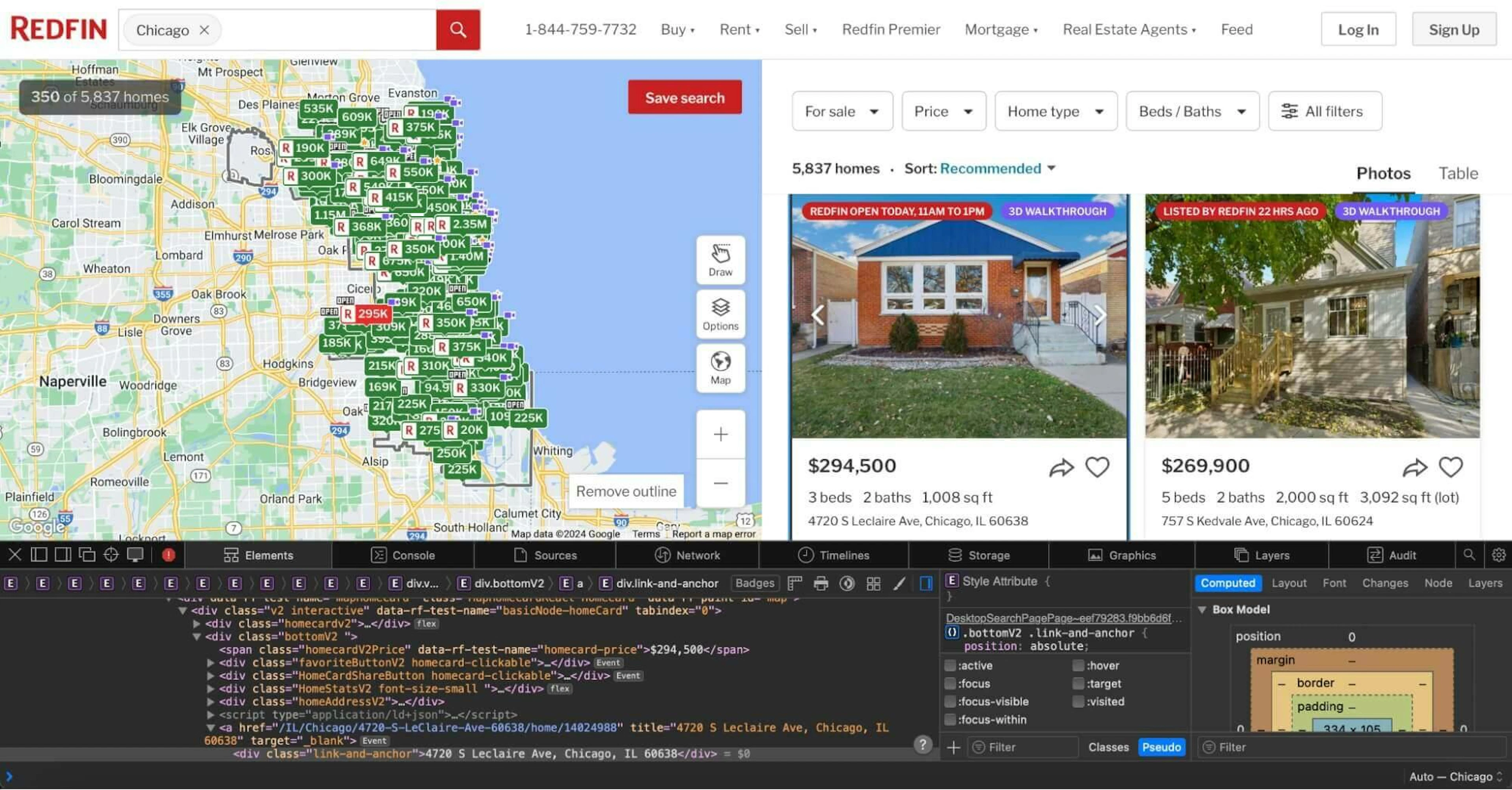
You should see that the parent element has a class called bottomV2. Use it to select each listing from the HTML content.
data = []
for listing in soup.find_all("div", {"class": "bottomV2"}):
...For cleaner code, create a function called extract_data_from_listing and write your data extraction code there. The function should accept the HTML content of the listing as an argument and return a dictionary containing the extracted data.
def extract_data_from_listing(listing):
...Next, implement the created function.
By inspecting the price and address fields, you can see that they’re both span elements with homecardV2 and collapsedAddress classes, respectively. Let’s use them to retrieve the values.
price = listing.find("span", {"class": "homecardV2Price"}).get_text(strip=True)
address = listing.find("span", {"class": "collapsedAddress"}).get_text(strip=True)For the rest of the fields, you can see that they all contain the same stats class.
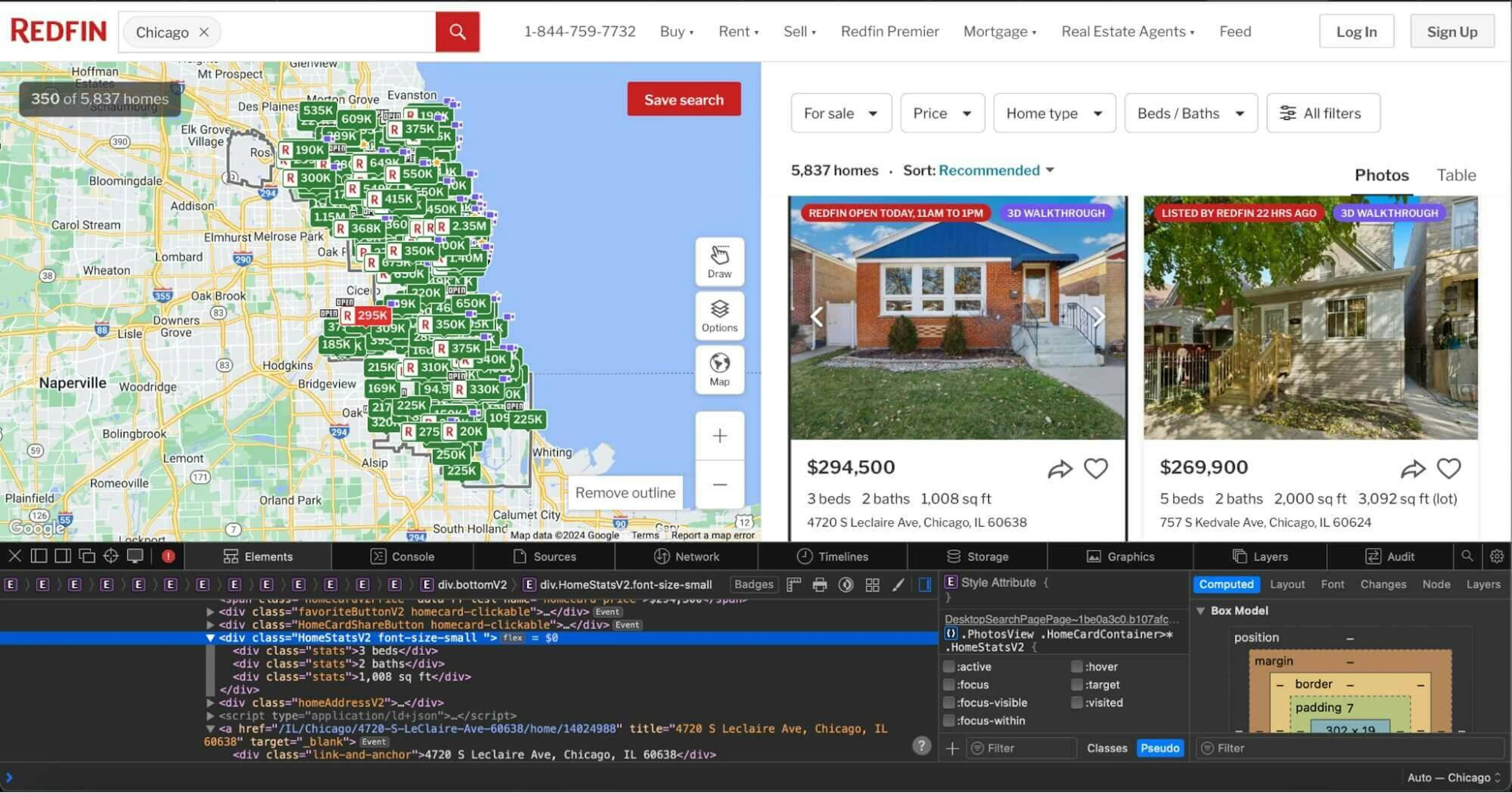
Use this class to select all elements at once and parse them separately.
stats = listing.find_all("div", {"class":"stats"})
try:
bed_count_elem, bath_count_elem, size_elem = stats[0], stats[1], stats[2]
except IndexError:
raise Exception("Got less stats than expected")
bed_count = bed_count_elem.get_text(strip=True)
bath_count = bath_count_elem.get_text(strip=True)
size = size_elem.get_text(strip=True)If Redfin’s page structure changes, raise an exception to know what went wrong.
After parsing each data entry, construct dictionaries and append them to the previously declared list.
entry = {
"price": price,
"address": address,
"bed_count": bed_count,
"bath_count": bath_count,
"size": size,
}
data.append(entry)Here’s the full code for extracting data from the HTML content:
def extract_data_from_listing(listing):
price = listing.find("span", {"class": "homecardV2Price"}).get_text(strip=True)
address = listing.find("span", {"class": "collapsedAddress"}).get_text(strip=True)
stats = listing.find_all("div", {"class": "stats"})
try:
bed_count_elem, bath_count_elem, size_elem = stats[0], stats[1], stats[2]
except IndexError:
raise Exception("Got less stats than expected")
bed_count = bed_count_elem.get_text(strip=True)
bath_count = bath_count_elem.get_text(strip=True)
size = size_elem.get_text(strip=True)
return {
"price": price,
"address": address,
"bed_count": bed_count,
"bath_count": bath_count,
"size": size,
}
data = []
for listing in soup.find_all("div", {"class": "bottomV2"}):
entry = extract_data_from_listing(listing)
data.append(entry)6. Save to CSV
Lastly, dump your collected data into a CSV file using pandas.
df = pd.DataFrame(data)
df.to_csv("real_estate_data.csv")The complete code
Here’s the full code for scraping real estate data from Redfin with Oxylabs' Web Scraper API:
import requests
import pandas as pd
from bs4 import BeautifulSoup
def extract_data_from_listing(listing):
price = listing.find("span", {"class": "homecardV2Price"}).get_text(strip=True)
address = listing.find("span", {"class": "collapsedAddress"}).get_text(strip=True)
stats = listing.find_all("div", {"class": "stats"})
try:
bed_count_elem, bath_count_elem, size_elem = stats[0], stats[1], stats[2]
except IndexError:
raise Exception("Got less stats than expected")
bed_count = bed_count_elem.get_text(strip=True)
bath_count = bath_count_elem.get_text(strip=True)
size = size_elem.get_text(strip=True)
return {
"price": price,
"address": address,
"bed_count": bed_count,
"bath_count": bath_count,
"size": size,
}
USERNAME = "USERNAME"
PASSWORD = "PASSWORD"
payload = {
"source": "universal",
"url": "https://www.redfin.com/city/29470/IL/Chicago",
}
response = requests.post(
url="https://realtime.oxylabs.io/v1/queries",
auth=(USERNAME, PASSWORD),
json=payload,
)
response.raise_for_status()
html = response.json()["results"][0]["content"]
soup = BeautifulSoup(html, "html.parser")
data = []
for listing in soup.find_all("div", {"class": "bottomV2"}):
entry = extract_data_from_listing(listing)
data.append(entry)
df = pd.DataFrame(data)
df.to_csv("real_estate_data.csv")Final word
As results prove, using Python along with Redfin Scraper API is a seamless way to automate real estate data collection processes required for insights into the real estate market.
Oxylabs' Web Scraper API enables you to extract data from Redfin and navigate typical challenges associated with web scraping. Please refer to our technical documentation for more on the API parameters and variables discussed in this tutorial.
Under Oxylabs’ real estate umbrella, you can find more target-tailored scrapers: Zillow Data API and Zoopla Scraper.
For more tutorials on popular targets like Amazon, Zillow, Craigslist, IMDb, and many others, check our blog.
If you have any questions, feel free to reach out by sending a message to support@oxylabs.io or live chat.
About the author

Augustas Pelakauskas
Former Senior Technical Copywriter
Augustas Pelakauskas was a Senior Technical Copywriter at Oxylabs. Coming from an artistic background, he is deeply invested in various creative ventures - the most recent being writing. After testing his abilities in freelance journalism, he transitioned to tech content creation. When at ease, he enjoys the sunny outdoors and active recreation. As it turns out, his bicycle is his fourth-best friend.
All information on Oxylabs Blog is provided on an "as is" basis and for informational purposes only. We make no representation and disclaim all liability with respect to your use of any information contained on Oxylabs Blog or any third-party websites that may be linked therein. Before engaging in scraping activities of any kind you should consult your legal advisors and carefully read the particular website's terms of service or receive a scraping license.
Related articles

Cheerio vs. Puppeteer: Which Should You Use for Web Scraping?

Shinthiya Nowsain Promi
2026-06-23



List Crawling in Python: Tools, Tips, and Techniques

Danielė Virinaitė
2026-06-17
Try Redfin Scraper API
Choose Oxylabs' Redfin Scraper API to gather real-time product data hassle-free.

Get the latest news from data gathering world
Scale up your business with Oxylabs®
Proxies
Advanced proxy solutions
Data Collection
Datasets
Resources
Innovation hub
Try Redfin Scraper API
Choose Oxylabs' Redfin Scraper API to gather real-time product data hassle-free.