175M+ ethically sourced IPs built for the highest reliability.
High-speed, cost-effective proxies built for any scraping workload.
Premium static residential proxies from trusted ASNs for most difficult targets.
Dedicated IPs from premium ASNs for demanding scraping.

AI-powered proxy solution for optimized web scraping performance.

20M+ IP addresses from real mobile devices for precise targeting.

Free Chrome proxy manager extension that works with any proxy provider.

Free Android proxy manager app that works with any proxy provider.

Free community-driven tools to improve your web scraping projects.
Web Scraper API
All-in-one web data collection platform for every stage of web scraping.
Fast Search API
Ultra-fast organic search results scraper tailored for AI workflows.
Headless Browser
Advanced browser automation solution for AI agents and scraping.
AI Studio
A suite of AI-powered tools for various scraping projects.

Documentation
All features, parameters, and integration details, backed by code samples in every coding language.
Tutorials, samples, and guides.
Latest fixes and features.





How to Scrape Google Flights with Python


Yelyzaveta Hayrapetyan
Last updated on
2025-02-12
6 min read
![]() AI Summary:
AI Summary:
This tutorial walks through scraping public flight data from Google Flights using Python and Oxylabs' Web Scraper API. It covers extracting flight prices, departure and arrival times, and airline names by inspecting Google Flights' HTML structure and parsing it with BeautifulSoup4, then saving the results as a JSON file. The article also compares three scraping methods — no API, proxies only, and a dedicated API — to help readers pick the right approach for their needs.
Google Flights is a flight booking service that makes buying tickets from third-party easier. It holds large amounts of flight data, including airfare, destinations, flight times, layovers, departing flights, departure date, and more. All this information is not only valuable for individual travelers but for businesses, too – it helps them conduct competitor analysis, analyze customer preferences, and more.
Without the right tools and methods, scraping Google Flights listings can get quite challenging. In today's article, we're going to demonstrate how to scrape public data from flight pages and generate search results with Python and Oxylabs' Web Scraper API. We'll gather all sorts of data, including flight prices, flight time, and airline name.
Try Web Scraper API for free
Get a free trial to test automated Google Flights scraping.
Up to 2K results
No credit card required
1. Installing prerequisite libraries
Let’s start by installing the prerequisites:
pip install bs4We’ll need BeautifulSoup4 to parse and extract information from the HTML that we’re going to scrape.
2. Creating core structure
Now, let's think about the general logic of our scraper. We'll create a functionality for defining multiple Google Flights URLs that we'd like to scrape. Then, we'll take these URLs one-by-one, extract the flight information we need and save it as a JSON object.
To start off, let's create a function that will take a URL as a parameter, scrape that URL with Web Scraper API for Google Flights data (you can get a free trial for it), and return the scraped HTML:
def get_flights_html(url):
payload = {
'source': 'google',
'render': 'html',
'url': url,
}
response = requests.request(
'POST',
'https://realtime.oxylabs.io/v1/queries',
auth=('username', 'password'),
json=payload,
)
response_json = response.json()
html = response_json['results'][0]['content']
return htmlMake sure to change up USERNAME and PASSWORD with your actual Oxylabs credentials.
If we inspect the HTML of the Google Flights page, we can see that all the flight listings are inside a <li> HTML object with the class pIav2d.
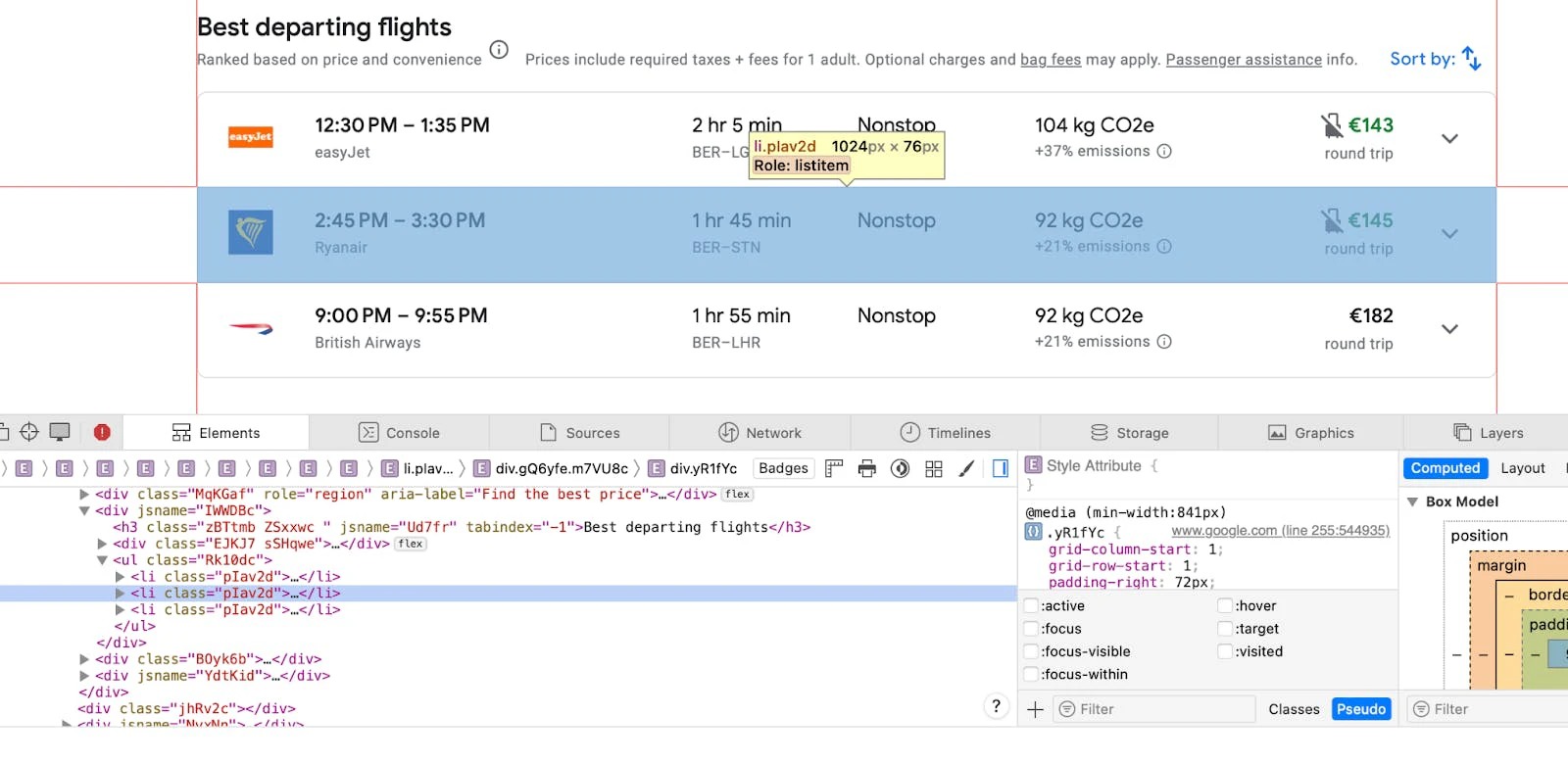
Next up, we’ll create a function that accepts a BeautifulSoup object created from the HTML of the whole page. This function will create and return an array of objects containing information from individual flight listings. Let’s try to form the function in such a way that makes it easily extendible if required:
def extract_flight_information_from_soup(soup_of_the_whole_page):
flight_listings = soup_of_the_whole_page.find_all('li','pIav2d')
flights = []
for listing in flight_listings:
if listing is not None:
# Add some specific data extraction here
flight = {}
flights.append(flight)
return flightsNow that we can get the HTML and have a function to hold our information extraction, we can organize both of those into one:
def extract_flights_data_from_urls(urls):
constructed_flight_results = []
for url in urls:
html = get_flights_html(url)
soup = BeautifulSoup(html,'html.parser')
flights = extract_flight_information_from_soup(soup)
constructed_flight_results.append({
'url': url,
'flight_data': flights
})
return constructed_flight_resultsThis function will take an array of URLs as a parameter and return an object of extracted flight data.
One thing left for our core is a function that takes this data and saves it as a file:
def save_results(results, filepath):
with open(filepath, 'w', encoding='utf-8') as file:
json.dump(results, file, ensure_ascii=False, indent=4)
returnWe can finish by creating a simple main function to invoke all that we’ve created so far:
def main():
results_file = 'data.json'
urls = [
'https://www.google.com/travel/flights?tfs=CBsQAhooEgoyMDI0LTA3LTI4agwIAxIIL20vMDE1NnFyDAgCEggvbS8wNGpwbBooEgoyMDI0LTA4LTAxagwIAhIIL20vMDRqcGxyDAgDEggvbS8wMTU2cUABSAFSA0VVUnABemxDalJJTkRCNVRGbDBOMU5UVEdOQlJ6aG5lRUZDUnkwdExTMHRMUzB0TFMxM1pXc3lOMEZCUVVGQlIxZ3dhRWxSUVRoaWFtTkJFZ1pWTWpnMk1qSWFDZ2lRYnhBQ0dnTkZWVkk0SEhEN2VBPT2YAQGyARIYASABKgwIAxIIL20vMDRqcGw&hl=en-US&curr=EUR&sa=X&ved=0CAoQtY0DahgKEwiAz9bF5PaEAxUAAAAAHQAAAAAQngM',
'https://www.google.com/travel/flights/search?tfs=CBwQAhooEgoyMDI0LTA3LTI4agwIAxIIL20vMDE1NnFyDAgDEggvbS8wN19rcRooEgoyMDI0LTA4LTAxagwIAxIIL20vMDdfa3FyDAgDEggvbS8wMTU2cUABSAFwAYIBCwj___________8BmAEB&hl=en-US&curr=EUR'
]
constructed_flight_results = extract_flights_data_from_urls(urls)
save_results(constructed_flight_results, results_file)With the core of the application complete, we can start creating specific data extraction functions that will gather the needed flight information.
3. Getting the price
First up is the price. Navigating the HTML of Google Flights can get tricky, as it seems to be quite dynamic. Let's see how we could pinpoint the price.
The first div to find is the one with the class BVAVmf.

Inside it, we can specify another one – YMlIz – which will contain only the price we need and nothing else.

Now that we got that, we just need to write the function itself:
def get_price(soup_element):
price = soup_element.find('div','BVAVmf').find('div','YMlIz').get_text()
return price4. Getting the flight time
Another important piece of information is the flight time. We’ll begin with the div containing both the flight time and the airline name – Ir0Voe.

Then, we can specify an inner div that contains only the time – zxVSec.

If we inspect this one closer, we’ll find that it has a lot of inner span containers with our time information split and repeated numerous times. But all of the needed time information can be found in the first child span container of the latter div.

We can also make good use of the fact that Oxylabs Web Scraper API renders JavaScript for us and extracts information in a very convenient format, as the exact flight dates can be seen when hovered over with a mouse.

We should keep in mind that there will be two span containers with the class eoY5cb that we will need: one for the departure and one for arrival. We should get them both.
Now that we’ve got all of the needed HTML information, let’s extract it.
def get_time(soup_element):
spans = soup_element.find('div','Ir0Voe').find('div','zxVSec', recursive=False).find_all('span', 'eoY5cb')
time = ""
for span in spans:
time = time + span.get_text() + "; "
return time5. Getting the airline name
For the last piece of information, we’ll need the name of the airline, which again, won’t be trivial.
We begin with the same div containing both the flight time and the airline name – Ir0Voe.

Then, we can specify an inner div that contains only the airline name – sSHqwe.

One more thing here, we can see that there might be some additional information about the flight and the airline in this field, such as the operator or the fact that tickets for this flight are from multiple airlines.

As all of this information is important for us, let’s try to gather it all. We can see that all of the texts are inside classless span containers.
The final step is to put everything we found so far into a function for extraction.
def get_airline(soup_element):
airline = soup_element.find('div','Ir0Voe').find('div','sSHqwe')
spans = airline.find_all('span', attrs={"class": None}, recursive=False)
result = ""
for span in spans:
result = result + span.get_text() + "; "
return resultHaving all of these functions for data extraction, we just need to add them to the place we designated earlier to finish up our code.
def extract_flight_information_from_soup(soup_of_the_whole_page):
flight_listings = soup_of_the_whole_page.find_all('li','pIav2d')
flights = []
for listing in flight_listings:
if listing is not None:
price = get_price(listing)
time = get_time(listing)
airline = get_airline(listing)
flight = {
"airline": airline,
"time": time,
"price": price
}
flights.append(flight)
return flights6. Final result
If we add all of it together, the final product should look something like this.
from bs4 import BeautifulSoup
import requests
import json
def get_price(soup_element):
price = soup_element.find('div','BVAVmf').find('div','YMlIz').get_text()
return price
def get_time(soup_element):
spans = soup_element.find('div','Ir0Voe').find('div','zxVSec', recursive=False).find_all('span', 'eoY5cb')
time = ""
for span in spans:
time = time + span.get_text() + "; "
return time
def get_airline(soup_element):
airline = soup_element.find('div','Ir0Voe').find('div','sSHqwe')
spans = airline.find_all('span', attrs={"class": None}, recursive=False)
result = ""
for span in spans:
result = result + span.get_text() + "; "
return result
def save_results(results, filepath):
with open(filepath, 'w', encoding='utf-8') as file:
json.dump(results, file, ensure_ascii=False, indent=4)
return
def get_flights_html(url):
payload = {
'source': 'google',
'render': 'html',
'url': url,
}
# Get response.
response = requests.request(
'POST',
'https://realtime.oxylabs.io/v1/queries',
auth=('username', 'password'),
json=payload,
)
response_json = response.json()
html = response_json['results'][0]['content']
return html
def extract_flight_information_from_soup(soup_of_the_whole_page):
flight_listings = soup_of_the_whole_page.find_all('li','pIav2d')
flights = []
for listing in flight_listings:
if listing is not None:
price = get_price(listing)
time = get_time(listing)
airline = get_airline(listing)
flight = {
"airline": airline,
"time": time,
"price": price
}
flights.append(flight)
return flights
def extract_flights_data_from_urls(urls):
constructed_flight_results = []
for url in urls:
html = get_flights_html(url)
soup = BeautifulSoup(html,'html.parser')
flights = extract_flight_information_from_soup(soup)
constructed_flight_results.append({
'url': url,
'flight_data': flights
})
return constructed_flight_results
def main():
results_file = 'data.json'
urls = [
'https://www.google.com/travel/flights?tfs=CBsQAhooEgoyMDI0LTA3LTI4agwIAxIIL20vMDE1NnFyDAgCEggvbS8wNGpwbBooEgoyMDI0LTA4LTAxagwIAhIIL20vMDRqcGxyDAgDEggvbS8wMTU2cUABSAFSA0VVUnABemxDalJJTkRCNVRGbDBOMU5UVEdOQlJ6aG5lRUZDUnkwdExTMHRMUzB0TFMxM1pXc3lOMEZCUVVGQlIxZ3dhRWxSUVRoaWFtTkJFZ1pWTWpnMk1qSWFDZ2lRYnhBQ0dnTkZWVkk0SEhEN2VBPT2YAQGyARIYASABKgwIAxIIL20vMDRqcGw&hl=en-US&curr=EUR&sa=X&ved=0CAoQtY0DahgKEwiAz9bF5PaEAxUAAAAAHQAAAAAQngM',
'https://www.google.com/travel/flights/search?tfs=CBwQAhooEgoyMDI0LTA3LTI4agwIAxIIL20vMDE1NnFyDAgDEggvbS8wN19rcRooEgoyMDI0LTA4LTAxagwIAxIIL20vMDdfa3FyDAgDEggvbS8wMTU2cUABSAFwAYIBCwj___________8BmAEB&hl=en-US&curr=EUR'
]
constructed_flight_results = extract_flights_data_from_urls(urls)
save_results(constructed_flight_results, results_file)
if __name__ == "__main__":
main()Alternative methods for scraping Google Flights
If you found yourself needing to extract Google Flights data, you have several options: scraping without an API by building your own custom Google Flights scraper, using or not using proxies, or leveraging a dedicated scraping API like Oxylabs Web Scraper API. Each approach comes with its own set of difficulties and trade-offs.
If you were to scrape Google Flights without an API – using only the requests library, for example – you would quickly run into significant roadblocks. Web scraping Google Flights is particularly challenging because it is a highly dynamic website that relies heavily on JavaScript to load flight data, making it impossible to get meaningful results with simple HTTP requests. Even if you tried to fetch the raw HTML, you would likely encounter blank pages or incomplete data because the critical content is rendered on the client side using JavaScript. To work around this, you would need a headless browser, such as Selenium or Puppeteer, which adds complexity and slows down the process. Additionally, Google has aggressive anti-bot mechanisms, so frequent requests from the same IP would result in immediate blocks.
On the other hand, using proxies can help mitigate blocking issues, but they don’t solve JavaScript rendering or dynamic content loading problems. Even with high-quality rotating proxies, you’d still need to use browser automation or advanced web scraping techniques like session management and fingerprint spoofing to make your scraper appear human-like. If you’re up for the challenge, you can test Oxylabs free proxies for your Flight Scraper Python based project. However, this approach increases the technical overhead, making it difficult to scale efficiently. On the other hand, with an API like Oxylabs Web Scraper API, these challenges are handled automatically. The API takes care of JavaScript rendering, proxy rotation, and CAPTCHA solving, ensuring that you get structured flight data without dealing with the complexities of scraping Google Flights manually.
| Method | Frequent blocking | JavaScript handling | Setup complexity | Maintenance | Scalability | Success rate |
|---|---|---|---|---|---|---|
| No proxies, no API | Very High | No (needs extra tools) | High | High | Low | Low |
| With proxies, no API | Medium | No (needs browser automation) | High | Medium | Medium | Medium |
| Using API (e.g., Oxylabs) | Very Low | Yes (handled by API) | Low | Low | High | High |
While it is technically possible to scrape Google Flights without an API, the process is complex, time-consuming, and prone to frequent blocking. Using proxies can improve success rates but still requires advanced configurations to handle JavaScript and anti-bot systems. A dedicated scraping API like Oxylabs' Web Scraper API simplifies the process by handling these challenges for you, providing a scalable and reliable solution to extract data efficiently. You can even try it for free once you sign up for the free trial – to test out if the Web Scraper API is the solution for your data extraction project. In any case, it would be safe to say that if your goal is to minimize technical difficulties and maximize success when scraping Google Flights, using an API is the most effective approach.
Conclusion
In today's article, we've learned how to extract public pricing information, flight times, and airline names from Google Flights. By employing Python and Oxylabs Web Scraper API, we were able to deal with the dynamic nature of Google Flights and extract data successfully.
Curious about scraping data from other Google platforms? Check out our Jobs, Search, Images, Trends, News, Scholar, and AI Mode step-by-step guides.
For web scraping, proxies are an essential anti-blocking measure. To avoid detection by the target website, you can buy proxies of various types to fit any scraping scenario.
Frequently asked questions
Is scraping Google Flights legal?
Scraping itself is not an illegal activity as long as it's performed without violating any laws, regulations, or target website's requirements. Therefore, before extracting public data from Google Flights, you need to make sure your scraping activities are ethical and that you're using a high-quality web scraping tool.
How do I get Google flight data?
How accurate is Google Flights?
About the author
Yelyzaveta Hayrapetyan
Former Senior Technical Copywriter
Yelyzaveta Hayrapetyan was a Senior Technical Copywriter at Oxylabs. After working as a writer in fashion, e-commerce, and media, she decided to switch her career path and immerse in the fascinating world of tech. And believe it or not, she absolutely loves it! On weekends, you’ll probably find Yelyzaveta enjoying a cup of matcha at a cozy coffee shop, scrolling through social media, or binge-watching investigative TV series.
All information on Oxylabs Blog is provided on an "as is" basis and for informational purposes only. We make no representation and disclaim all liability with respect to your use of any information contained on Oxylabs Blog or any third-party websites that may be linked therein. Before engaging in scraping activities of any kind you should consult your legal advisors and carefully read the particular website's terms of service or receive a scraping license.
Related articles






Try Web Scraper API
Collect large-volume public Google Flights data with Oxylabs' Web Scraper API.
Buy Paid Proxy Servers
One of the largest proxy pools in the market with 177M+ IPs in 195 countries with continent, country, city, state, ZIP code, ASN, and coordinate-level targeting opportunities

Get the latest news from data gathering world
Scale up your business with Oxylabs®
Proxies
Advanced proxy solutions
Data Collection
Datasets
Resources
Innovation hub
Try Web Scraper API
Collect large-volume public Google Flights data with Oxylabs' Web Scraper API.
Buy Paid Proxy Servers
One of the largest proxy pools in the market with 177M+ IPs in 195 countries with continent, country, city, state, ZIP code, ASN, and coordinate-level targeting opportunities