175M+ ethically sourced IPs built for the highest reliability.
High-speed, cost-effective proxies built for any scraping workload.
Premium static residential proxies from trusted ASNs for most difficult targets.
Dedicated IPs from premium ASNs for demanding scraping.

AI-powered proxy solution for optimized web scraping performance.

20M+ IP addresses from real mobile devices for precise targeting.

Free Chrome proxy manager extension that works with any proxy provider.

Free Android proxy manager app that works with any proxy provider.

Free community-driven tools to improve your web scraping projects.
Web Scraper API
All-in-one web data collection platform for every stage of web scraping.
Fast Search API
Ultra-fast organic search results scraper tailored for AI workflows.
Headless Browser
Advanced browser automation solution for AI agents and scraping.
AI Studio
A suite of AI-powered tools for various scraping projects.

Documentation
All features, parameters, and integration details, backed by code samples in every coding language.
Tutorials, samples, and guides.
Latest fixes and features.






![]() AI Summary:
AI Summary:
This guide walks through building a Python script that scrapes Google Jobs listings. It uses `asyncio`, `aiohttp`, and Oxylabs' Google Jobs Scraper API to asynchronously extract job details like title, company, location, salary, and posting date across multiple search queries and geo-locations.
Google Jobs is a job listing aggregator that gathers job openings from various sources all over the world into one place. If you’re endlessly surfing the web for career opportunities or want to fuel your projects with fresh job listings on a large scale, your best bet is to start web scraping Google Jobs data. It saves time and effort, and you won’t have to maintain different scrapers for individual job search sites.
Follow this step-by-step tutorial and learn how to build your own Google Jobs scraper that simultaneously scrapes Google Jobs for multiple search queries and geo-locations with Python and Oxylabs’ Google Jobs Scraper API.
Google Jobs website overview
Once you visit the Google Jobs page, you'll see that all job listings for a query are displayed on the left side. Looking at the HTML structure, you can see that each listing is enclosed in the <li> tag and collectively wrapped within the <ul> tag:
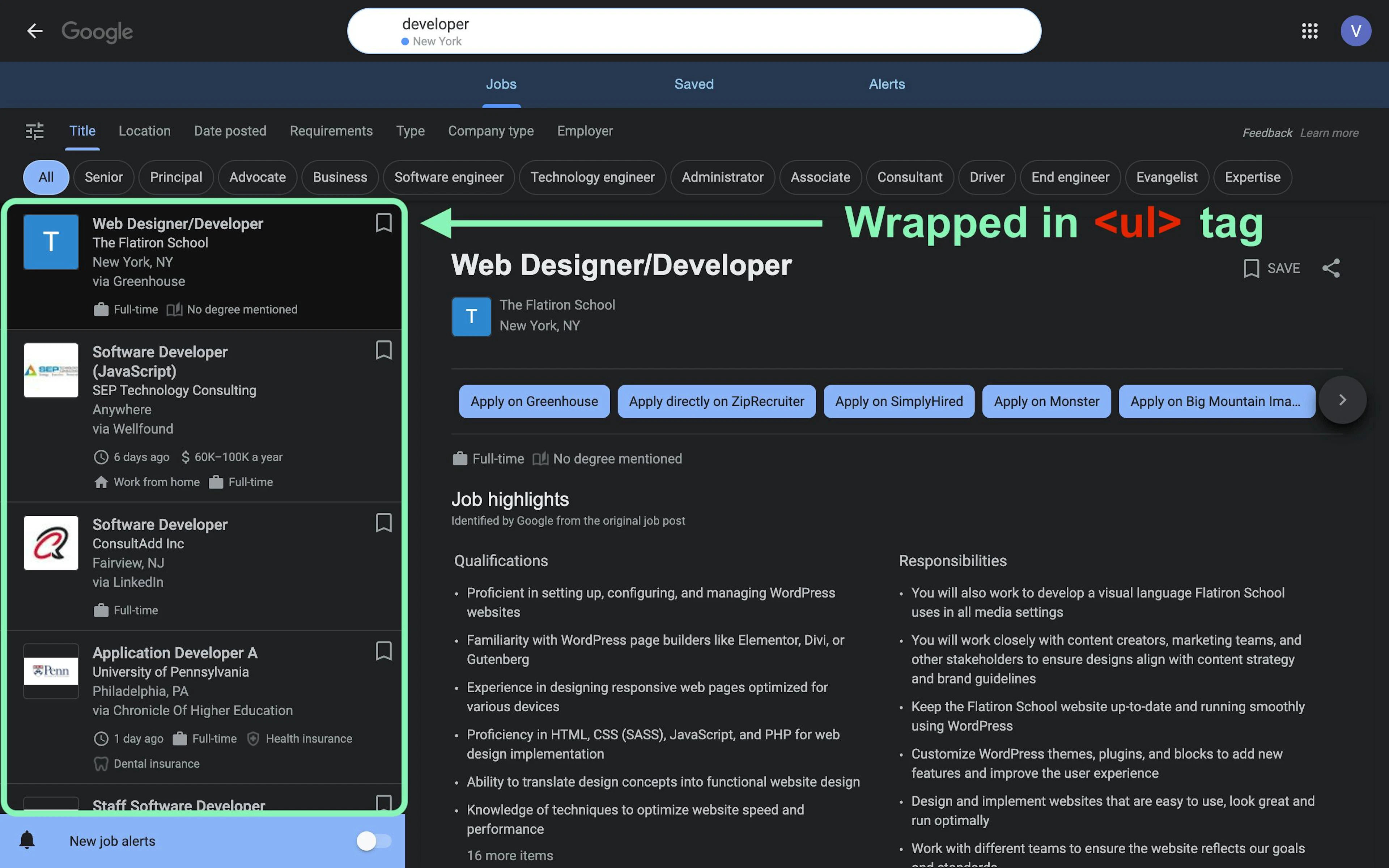
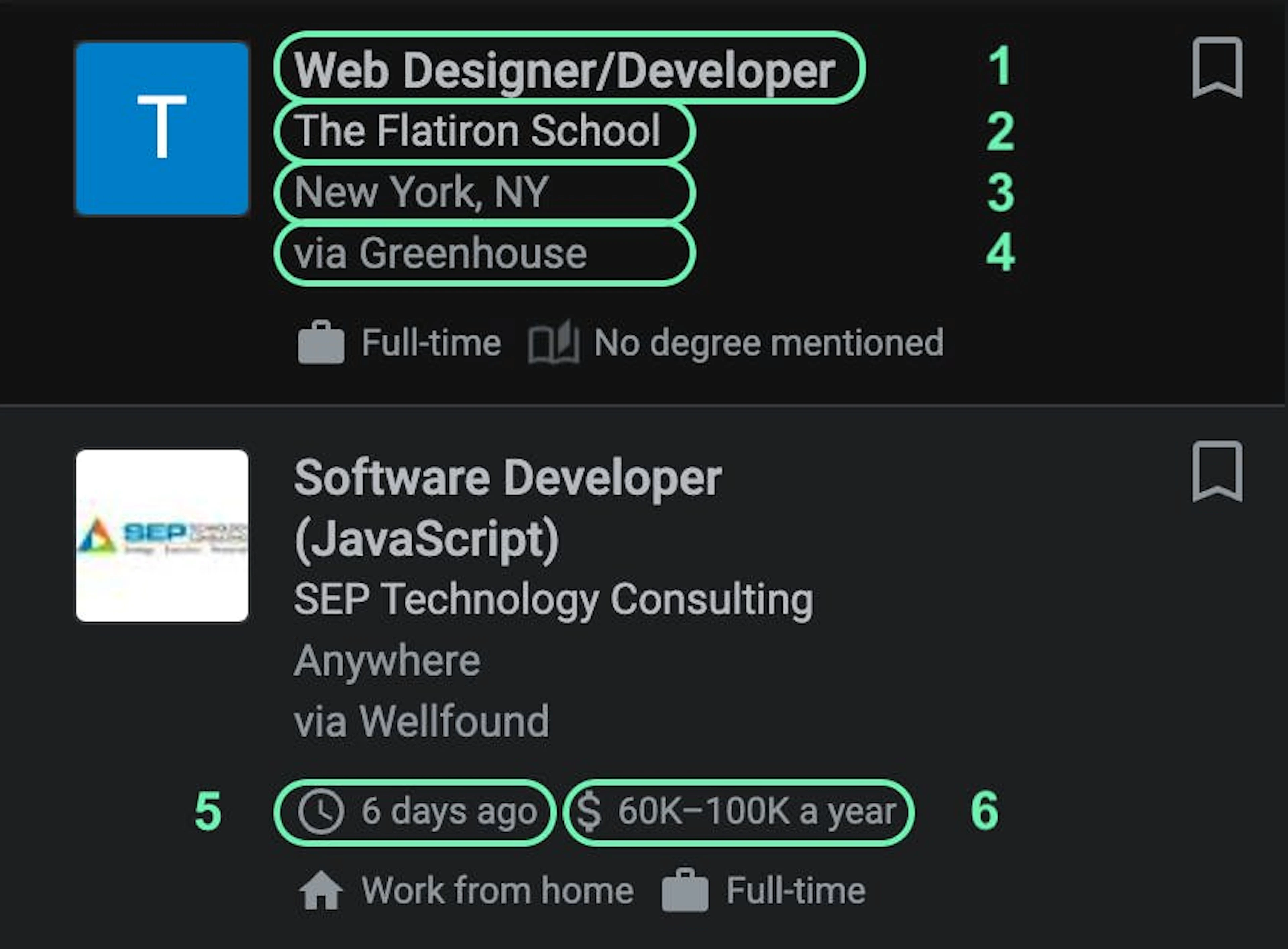
In this guide, let’s scrape Google Jobs results asynchronously and extract the following publicly available data:
Job title
Company name
Job location
Job posted via [platform]
Job listing date
Salary
Get a free trial
Claim a free trial to test Web Scraper API.
Up to 2K results
No credit card required
If you want to extract even more public data, such as job highlights, job description, and similar jobs, expand the code shown in this article to make additional API calls to the scraped job URLs.
1. Get a free trial and send a request
Visit the Oxylabs dashboard and create an account to claim your free trial for Oxylabs’ SERP Scraper API (now part of the Web Scraper API solution). It’s equipped with proxy servers, Custom Browser Instructions, Custom Parser, and other advanced features that’ll help you overcome blocks and fingerprinting. See this short guide that shows how to navigate the dashboard and get the free trial.
Install Python
If you don’t have Python installed yet, you can download it from the official Python website. This tutorial is written with Python 3.12.0, so ensure that you have a compatible version.
Send a request for testing
After creating an API user, copy and save your API user credentials, which you’ll use for authentication. Next, open your terminal and install the requests library:
pip install requestsThen run the following code that scrapes Google career opportunities and retrieves the entire HTML file.
import requests
payload = {
"source": "google",
"url": "https://www.google.com/search?q=developer&ibp=htl;jobs&hl=en&gl=us",
"render": "html"
}
response = requests.post(
"https://realtime.oxylabs.io/v1/queries",
auth=("USERNAME", "PASSWORD"), # Replace with your API user credentials
json=payload
)
print(response.json())
print(response.status_code)Once it finishes running, you should see a JSON response with HTML results and a status code of your request. If everything works correctly, the status code should be 200.
Now, let's dive into the fun part – building your very own asynchronous Google Jobs scraper.
2. Install and import libraries
For this project, let’s use the asyncio and aiohttp libraries to make asynchronous requests to the API. Additionally, the json and pandas libraries will help you deal with JSON and CSV files.
Open your terminal and run the following command to install the necessary libraries:
pip install asyncio aiohttp pandasThen, import them into your Python file:
import asyncio, aiohttp, json, pandas as pd
from aiohttp import ClientSession, BasicAuth3. Add your API user credentials
Create the API user credentials variable and use BasicAuth, as aiohttp requires this for authentication:
credentials = BasicAuth("USERNAME", "PASSWORD") # Replace with your API user credentials4. Set up queries and locations
You can easily form Google Jobs URLs for different queries by manipulating the q= parameter:
https://www.google.com/search?q=developer&ibp=htl;jobs&hl=en&gl=usThis enables you to scrape job listings for as many Google career search queries as you want. It's a good idea to visit the URLs with specific parameters using a VPN that's located in your desired country. This way, you can ensure that the URL works for that location, as Google may use different URL-forming techniques and present different SERPs that are incompatible with the CSS and XPath selectors used in this tutorial.
Note that the q=, ibp=htl;jobs, hl=, and gl= parameters are mandatory for the URL to work.
Additionally, you could set the UULE parameter for geo-location targeting yourself, but that’s unnecessary since the geo_location parameter of Google Jobs Scraper API does that by default.
URL parameters
Create the URL_parameters list to store your search queries:
URL_parameters = ["developer", "chef", "manager"]Locations
Then, create the locations dictionary where the key refers to the country, and the value is a list of geo-location parameters. This dictionary will be used to dynamically form the API payload and localize Google Jobs results for the specified location. The two-letter country code will be used to modify the gl= parameter in the Google Jobs URL:
locations = {
"US": ["California,United States", "Virginia,United States", "New York,United States"],
"GB": ["United Kingdom"],
"JP": ["Japan"]
}
Visit our documentation for more details about geo-locations.
5. Prepare the API payload with parsing instructions
Google Jobs Scraper API takes web scraping instructions from a payload dictionary, making it the most important configuration to fine-tune. The url and geo_location keys are set to None, as the scraper will pass these values dynamically for each search query and location. The "render": "html" parameter enables JavaScript rendering and returns the rendered HTML file:
payload = {
"source": "google",
"url": None,
"geo_location": None,
"user_agent_type": "desktop",
"render": "html"
}
Next, use Custom Parser to define your own parsing logic with xPath or CSS selectors and retrieve only the data you need. Remember that you can create as many functions as you want and extract even more data points than shown in this guide. Head to this Google Jobs URL in your browser and open Developer Tools by pressing Ctrl+Shift+I (Windows) or Option + Command + I (macOS). Use Ctrl+F or Command+F to open a search bar and test selector expressions.
As mentioned previously, the Google job listings are within the <li> tags, which are wrapped with the <ul> tag:
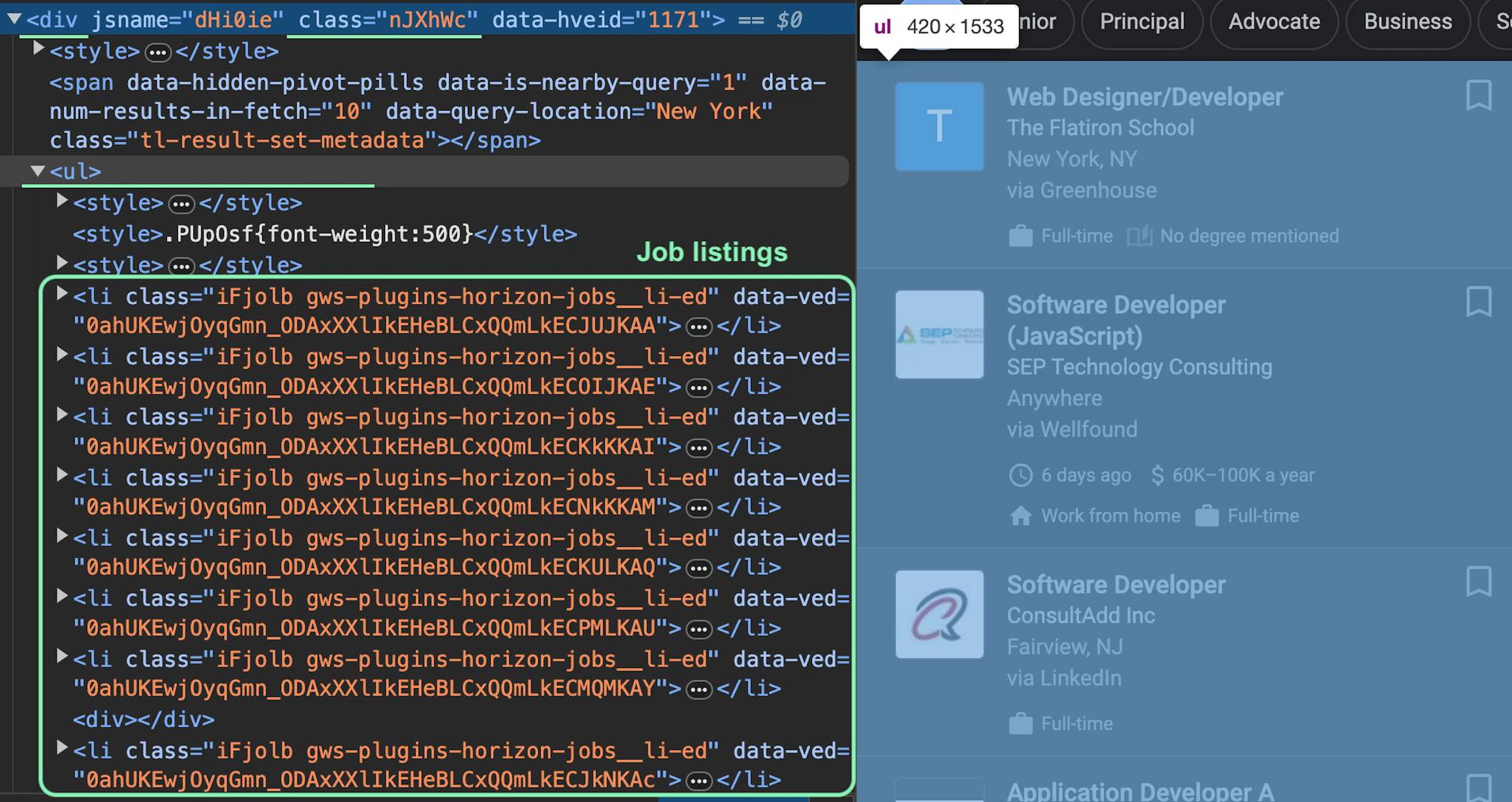
As there is more than one <ul> list on the Google Jobs page, you can form an xPath selector by specifying the div element that contains the targeted list:
//div[@class='nJXhWc']//ul/liYou can use this selector to specify the location of all job listings in the HTML file. In the payload dictionary, set the parse key to True and create the parsing_instructions parameter with the jobs function:
payload = {
"source": "google",
"url": None,
"geo_location": None,
"user_agent_type": "desktop",
"render": "html",
"parse": True,
"parsing_instructions": {
"jobs": {
"_fns": [
{
"_fn": "xpath",
"_args": ["//div[@class='nJXhWc']//ul/li"]
}
],
}
}
}Next, create the _items iterator that will loop over the jobs list and extract details for each listing:
payload = {
"source": "google",
"url": None,
"geo_location": None,
"user_agent_type": "desktop",
"render": "html",
"parse": True,
"parsing_instructions": {
"jobs": {
"_fns": [
{
"_fn": "xpath", # You can use CSS or xPath
"_args": ["//div[@class='nJXhWc']//ul/li"]
}
],
"_items": {
"data_point_1": {
"_fns": [
{
"_fn": "selector_type", # You can use CSS or xPath
"_args": ["selector"]
}
]
},
"data_point_2": {
"_fns": [
{
"_fn": "selector_type",
"_args": ["selector"]
}
]
},
}
}
}
}For each data point, you can create a separate function within the _items iterator. Let’s see how xPath selectors should look like for each Google Jobs data point:
Job title
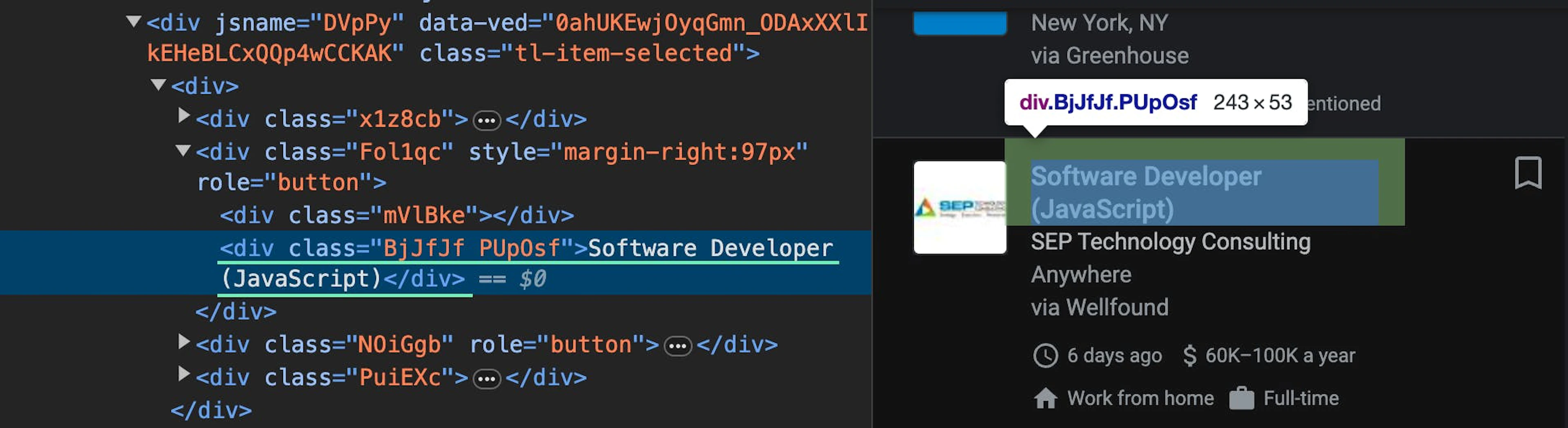
.//div[@class='BjJfJf PUpOsf']/text()Company name

.//div[@class='vNEEBe']/text()Location

.//div[@class='Qk80Jf'][1]/text()Date
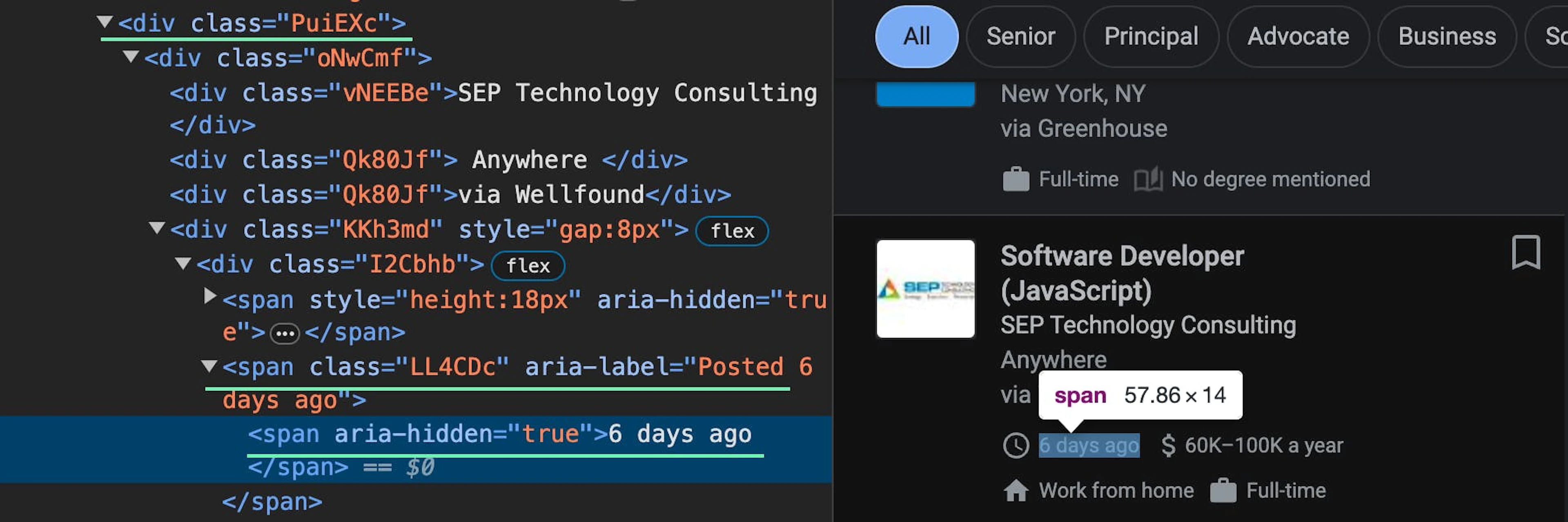
.//div[@class='PuiEXc']//span[@class='LL4CDc' and contains(@aria-label, 'Posted')]/span/text()Salary
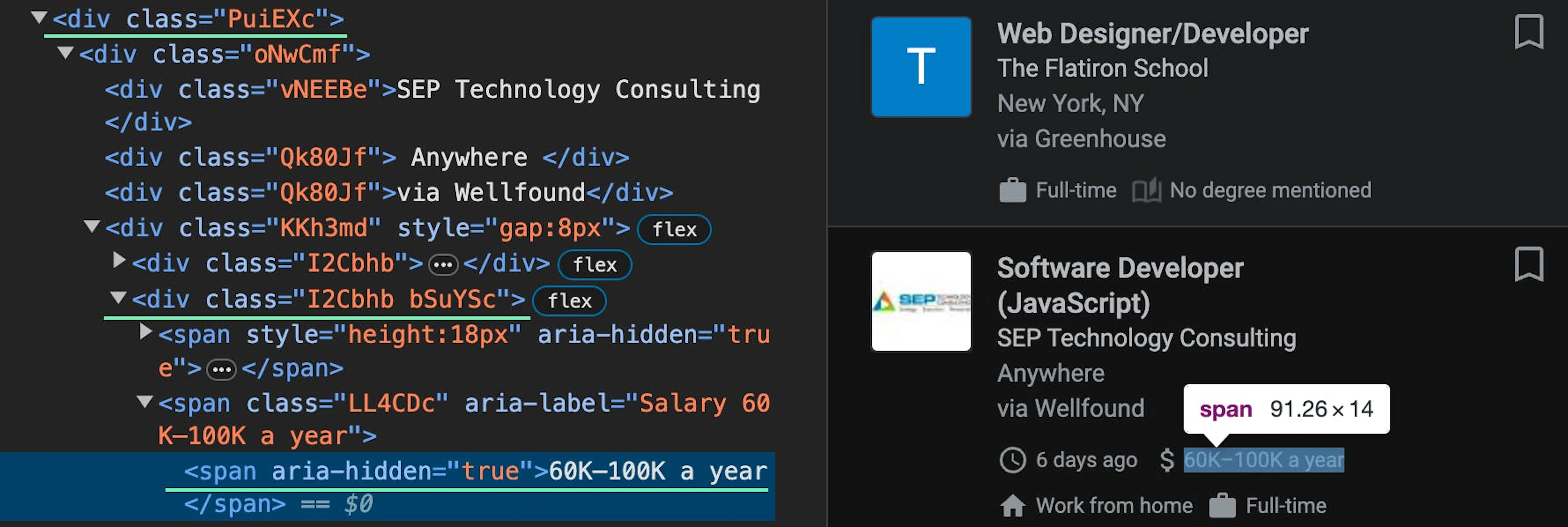
.//div[@class='PuiEXc']//div[@class='I2Cbhb bSuYSc']//span[@aria-hidden='true']/text()Job posted via

.//div[@class='Qk80Jf'][2]/text()URL
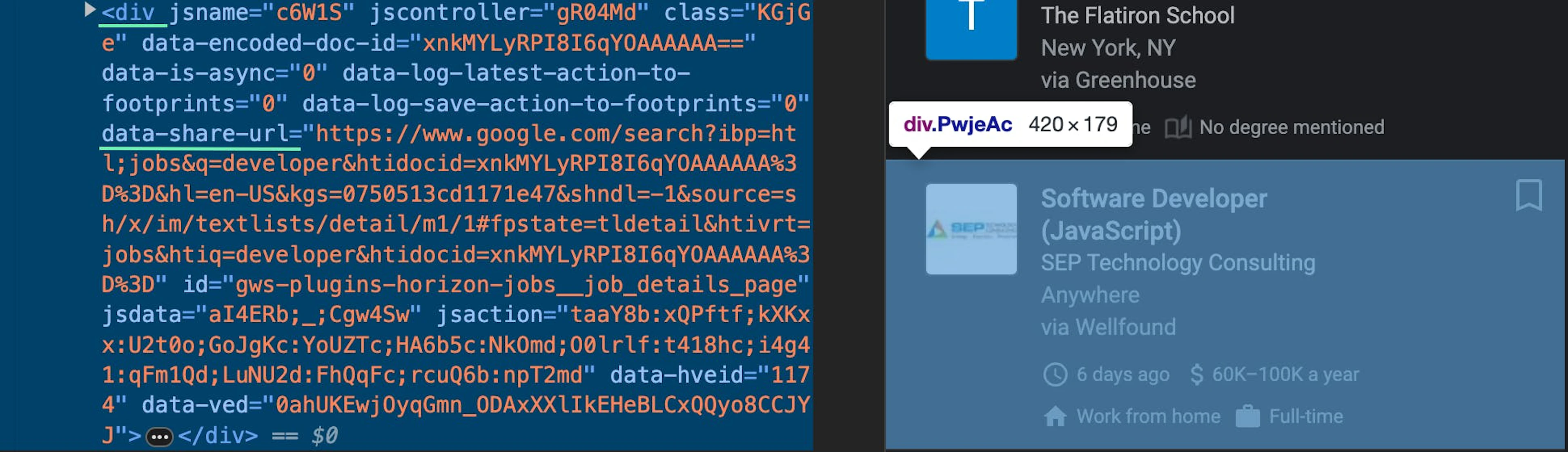
.//div[@data-share-url]/@data-share-urlPlease be aware that you can only access this job listing URL in your browser with an IP address from the same country used during web scraping. If you’ve used a United States proxy, make sure to use a US IP address in your browser.
In the end, you should have a payload that looks like shown below. Save it to a separate JSON file and ensure that the None and True parameter values are converted to respective JSON values: null and true:
import json
payload = {
"source": "google",
"url": None,
"geo_location": None,
"user_agent_type": "desktop",
"render": "html",
"parse": True,
"parsing_instructions": {
"jobs": {
"_fns": [
{
"_fn": "xpath",
"_args": ["//div[@class='nJXhWc']//ul/li"]
}
],
"_items": {
"job_title": {
"_fns": [
{
"_fn": "xpath_one",
"_args": [".//div[@class='BjJfJf PUpOsf']/text()"]
}
]
},
"company_name": {
"_fns": [
{
"_fn": "xpath_one",
"_args": [".//div[@class='vNEEBe']/text()"]
}
]
},
"location": {
"_fns": [
{
"_fn": "xpath_one",
"_args": [".//div[@class='Qk80Jf'][1]/text()"]
}
]
},
"date": {
"_fns": [
{
"_fn": "xpath_one",
"_args": [".//div[@class='PuiEXc']//span[@class='LL4CDc' and contains(@aria-label, 'Posted')]/span/text()"]
}
]
},
"salary": {
"_fns": [
{
"_fn": "xpath_one",
"_args": [".//div[@class='PuiEXc']//div[@class='I2Cbhb bSuYSc']//span[@aria-hidden='true']/text()"]
}
]
},
"posted_via": {
"_fns": [
{
"_fn": "xpath_one",
"_args": [".//div[@class='Qk80Jf'][2]/text()"]
}
]
},
"URL": {
"_fns": [
{
"_fn": "xpath_one",
"_args": [".//div[@data-share-url]/@data-share-url"]
}
]
}
}
}
}
}
with open("payload.json", "w") as f:
json.dump(payload, f, indent=4)This allows you to import the payload and make the scraper code much shorter:
payload = {}
with open("payload.json", "r") as f:
payload = json.load(f)6. Define functions
There are several ways you can integrate Oxylabs' Google Scraper, namely Realtime, Push-Pull, and Proxy endpoint. For this guide, let’s use Push-Pull, as you won’t have to keep your connection open after submitting a scraping job to the API. The API endpoint to use in this scenario is https://data.oxylabs.io/v1/queries.
You could also use another endpoint to submit batches of up to 5,000 URLs or queries. Keep in mind that making this choice will require you to modify the code shown in this tutorial. Read up about batch queries in our documentation.
Submit job
Define an async function called submit_job and pass the session: ClientSession together with the payload to submit a web scraping job to the Oxylabs API using the POST method. This will return the ID number of the submitted job:
async def submit_job(session: ClientSession, payload):
async with session.post(
"https://data.oxylabs.io/v1/queries",
auth=credentials,
json=payload
) as response:
return (await response.json())["id"]Check job status
Then, create another async function that passes the job_id (this will be defined later) and returns the status of the scraping job from the response:
async def check_job_status(session: ClientSession, job_id):
async with session.get(f"https://data.oxylabs.io/v1/queries/{job_id}", auth=credentials) as response:
return (await response.json())["status"]Get job results
Next, create an async function that retrieves the scraped and parsed jobs results. Note that the response is a JSON string that contains the API job details and the scraped content that you can access by parsing nested JSON properties:
async def get_job_results(session: ClientSession, job_id):
async with session.get(f"https://data.oxylabs.io/v1/queries/{job_id}/results", auth=credentials) as response:
return (await response.json())["results"][0]["content"]["jobs"]Save data to a CSV file
Define another async function that saves the scraped and parsed data to a CSV file. Later on, we’ll create the four parameters that are passed to the function. As the pandas library is synchronous, you must use asyncio.to_thread() to run the df.to_csv asynchronously in a separate thread:
async def save_to_csv(job_id, query, location, results):
print(f"Saving data for {job_id}")
data = []
for job in results:
data.append({
"Job title": job["job_title"],
"Company name": job["company_name"],
"Location": job["location"],
"Date": job["date"],
"Salary": job["salary"],
"Posted via": job["posted_via"],
"URL": job["URL"]
})
df = pd.DataFrame(data)
filename = f"{query}_jobs_{location.replace(',', '_').replace(' ', '_')}.csv"
await asyncio.to_thread(df.to_csv, filename, index=False)Scrape Google Jobs
Make another async function that passes parameters to form the Google Jobs URL and the payload dynamically. Create a variable job_id and then call the submit_job function to submit the request to the API and create a while True loop by calling the check_job_status function to keep checking whether the API has finished web scraping. At the end, initiate the get_job_results and save_to_csv functions:
async def scrape_jobs(session: ClientSession, query, country_code, location):
URL = f"https://www.google.com/search?q={query}&ibp=htl;jobs&hl=en&gl={country_code}"
payload["url"] = URL
payload["geo_location"] = location
job_id = await submit_job(session, payload)
await asyncio.sleep(15)
print(f"Checking status for {job_id}")
while True:
status = await check_job_status(session, job_id)
if status == "done":
print(f"Job {job_id} done. Retrieving {query} jobs in {location}.")
break
elif status == "failed":
print(f"Job {job_id} encountered an issue. Status: {status}")
return
await asyncio.sleep(5)
results = await get_job_results(session, job_id)
await save_to_csv(job_id, query, location, results)7. Create the main() function
You’ve written most of the code, what’s left is to pull everything together by defining an async function called main() that creates an aiohttp session. It makes a list of tasks to scrape jobs for each combination of location and query and executes each task concurrently using asyncio.gather():
async def main():
async with aiohttp.ClientSession() as session:
tasks = []
for country_code, location_list in locations.items():
for location in location_list:
for query in URL_parameters:
task = asyncio.ensure_future(scrape_jobs(session, query, country_code, location))
tasks.append(task)
await asyncio.gather(*tasks)Lastly, initialize the event loop and call the main() function:
if __name__ == "__main__":
loop = asyncio.new_event_loop()
asyncio.set_event_loop(loop)
loop.run_until_complete(main())
print("Completed!")8. Run the complete code
Here’s the full Python code that scrapes Google Jobs listings for each query and location asynchronously:
import asyncio, aiohttp, json, pandas as pd
from aiohttp import ClientSession, BasicAuth
credentials = BasicAuth("USERNAME", "PASSWORD") # Replace with your API user credentials
URL_parameters = ["developer", "chef", "manager"]
locations = {
"US": ["California,United States", "Virginia,United States", "New York,United States"],
"GB": ["United Kingdom"],
"JP": ["Japan"]
}
payload = {}
with open("payload.json", "r") as f:
payload = json.load(f)
async def submit_job(session: ClientSession, payload):
async with session.post(
"https://data.oxylabs.io/v1/queries",
auth=credentials,
json=payload
) as response:
return (await response.json())["id"]
async def check_job_status(session: ClientSession, job_id):
async with session.get(f"https://data.oxylabs.io/v1/queries/{job_id}", auth=credentials) as response:
return (await response.json())["status"]
async def get_job_results(session: ClientSession, job_id):
async with session.get(f"https://data.oxylabs.io/v1/queries/{job_id}/results", auth=credentials) as response:
return (await response.json())["results"][0]["content"]["jobs"]
async def save_to_csv(job_id, query, location, results):
print(f"Saving data for {job_id}")
data = []
for job in results:
data.append({
"Job title": job["job_title"],
"Company name": job["company_name"],
"Location": job["location"],
"Date": job["date"],
"Salary": job["salary"],
"Posted via": job["posted_via"],
"URL": job["URL"]
})
df = pd.DataFrame(data)
filename = f"{query}_jobs_{location.replace(',', '_').replace(' ', '_')}.csv"
await asyncio.to_thread(df.to_csv, filename, index=False)
async def scrape_jobs(session: ClientSession, query, country_code, location):
URL = f"https://www.google.com/search?q={query}&ibp=htl;jobs&hl=en&gl={country_code}"
payload["url"] = URL
payload["geo_location"] = location
job_id = await submit_job(session, payload)
await asyncio.sleep(15)
print(f"Checking status for {job_id}")
while True:
status = await check_job_status(session, job_id)
if status == "done":
print(f"Job {job_id} done. Retrieving {query} jobs in {location}.")
break
elif status == "failed":
print(f"Job {job_id} encountered an issue. Status: {status}")
return
await asyncio.sleep(5)
results = await get_job_results(session, job_id)
await save_to_csv(job_id, query, location, results)
async def main():
async with aiohttp.ClientSession() as session:
tasks = []
for country_code, location_list in locations.items():
for location in location_list:
for query in URL_parameters:
task = asyncio.ensure_future(scrape_jobs(session, query, country_code, location))
tasks.append(task)
await asyncio.gather(*tasks)
if __name__ == "__main__":
loop = asyncio.new_event_loop()
asyncio.set_event_loop(loop)
loop.run_until_complete(main())
print("Completed!")After the scraper finishes running, you’ll see all the CSV files saved in your local directory.
Can you use other tools?
When scraping Google Jobs or other challenging targets, choosing the right method is crucial. The table below compares different approaches:
| Scraping method | Success rate | Handling blocks | Speed | Ease of use | Maintenance effort |
|---|---|---|---|---|---|
| No proxies | Low | Frequent IP bans | Fast | Simple | High – needs manual fixes due to blocks |
| With proxies | Medium | Better, but still requires IP rotation | Moderate | Moderate | Medium – needs proxy management |
| Headless browser | Medium | Can handle some blocks but may be detected | Slow | Complex | High – requires CAPTCHA handling and anti-bot evasion |
| Web Scraper API | High | Built-in anti-bot bypassing | Fast | Easy | Low – no need for manual adjustments |
As you can see, the best way to scrape jobs data is by using our API. This way, the public data acquisition projects are fast, efficient, and effective. You can always customize and expand the code as you wish, bringing you more flexibility to achieve your goals.
Want to learn more? Read this quick overview of the challenges and solutions of scraping job postings
If you're curious about scraping other Google services, see our how-to guides for scraping Scholar, Search, Images, Trends, News, Flights, and AI Mode.
Frequently asked questions
Is it legal to scrape Google Jobs?
The legality of web scraping Google Jobs depends on the data you collect and how you use it. It's crucial to follow data regulations, like privacy and copyright laws, and seek legal advice before you engage in scraping activities. Additionally, follow Google's Terms of Service and use best practices for web scraping.
To learn more about the topic, check out this article: Is Web Scraping Legal?
About the author

Vytenis Kaubrė
Technical Content Researcher
Vytenis Kaubrė was a Technical Content Researcher at Oxylabs. Creative writing and a growing interest in technology fueled his work, where he researched and crafted technical content while honing his skills in Python. Off duty, he could often be found working on personal projects, learning about cybersecurity, or relaxing with a book.
All information on Oxylabs Blog is provided on an "as is" basis and for informational purposes only. We make no representation and disclaim all liability with respect to your use of any information contained on Oxylabs Blog or any third-party websites that may be linked therein. Before engaging in scraping activities of any kind you should consult your legal advisors and carefully read the particular website's terms of service or receive a scraping license.
Related articles

Cheerio vs. Puppeteer: Which Should You Use for Web Scraping?

Shinthiya Nowsain Promi
2026-06-23



Top 7 Web Price Scraping Software and Tools for 2026
Shinthiya Nowsain Promi
2026-06-11
Try Google Jobs Scraper API
Choose Oxylabs' Google Jobs Scraper API to gather real-time job data hassle-free.

Get the latest news from data gathering world
Scale up your business with Oxylabs®
Proxies
Advanced proxy solutions
Data Collection
Datasets
Resources
Innovation hub
Try Google Jobs Scraper API
Choose Oxylabs' Google Jobs Scraper API to gather real-time job data hassle-free.