175M+ ethically sourced IPs built for the highest reliability.
High-speed, cost-effective proxies built for any scraping workload.
Premium static residential proxies from trusted ASNs for most difficult targets.
Dedicated IPs from premium ASNs for demanding scraping.

AI-powered proxy solution for optimized web scraping performance.

20M+ IP addresses from real mobile devices for precise targeting.

Free Chrome proxy manager extension that works with any proxy provider.

Free Android proxy manager app that works with any proxy provider.

Free community-driven tools to improve your web scraping projects.
Web Scraper API
All-in-one web data collection platform for every stage of web scraping.
Fast Search API
Ultra-fast organic search results scraper tailored for AI workflows.
Headless Browser
Advanced browser automation solution for AI agents and scraping.
AI Studio
A suite of AI-powered tools for various scraping projects.

Documentation
All features, parameters, and integration details, backed by code samples in every coding language.
Tutorials, samples, and guides.
Latest fixes and features.





Web Scraper API: Extract Data from Any Website in One Place
Covers all steps of web scraping, from accessing any public website to delivering accurate, ready-to-use data at scale.
Free trial includes up to 2K results. Pay only for successful results. No credit card required.
Popular targets
{ "results": [ { "content": { "last_visible_page": 9, "page": 1, "parse_status_code": 12000, "results": { "knowledge": { "title": "adidas", "factoids": [ { "title": "Phone", "content": "1 (800) 982-9337" }, { "title": "Headquarters", "content": "Herzogenaurach, Germany" }, ], "profiles": [ { "title": "Instagram", "url": "https://www.instagram.com/adidas" }, { "title": "Facebook", "url": "https://www.facebook.com/adidas" }, { "title": "YouTube", "url": "https://www.youtube.com/user/adidas" } ] }, "organic": [ { "pos": 1, "pos_overall": 1, "title": "Sneakers and Activewear | adidas US", "url": "https://www.adidas.com/us", "url_shown": "https://www.adidas.com", "favicon_text": "Adidas", "desc": "Gear up for your favorite sport with adidas sneakers and activewear for men and women.", "sitelinks": { "expanded": [ { "title": "Men's Shoes", "url": "https://www.adidas.com/us/men-shoes", "desc": "Shop men's shoes at adidas." }, { "title": "Kids' Shoes and Clothes", "url": "https://www.adidas.com/us/kids", "desc": "Outfit your young athlete with the latest in kids' sneakers and apparel." }, { "title": "Women's Sneakers and Activewear", "url": "https://www.adidas.com/us/women", "desc": "Inspire your next workout with the latest in women's sneakers and apparel." }, { "title": "Clothes & Shoes on Sale", "url": "https://www.adidas.com/us/sale", "desc": "Explore clothes and shoes on sale at adidas." } ] } }, { "pos": 2, "pos_overall": 2, "title": "adidas Group: Home", "url": "https://www.adidas-group.com/", "url_shown": "https://www.adidas-group.com", "favicon_text": "adidas Group", "desc": "At adidas, we see how everything is connected: healthy soil, clean water, and responsible sourcing." }, { "pos": 3, "pos_overall": 3, "title": "Adidas - Wikipedia", "url": "https://en.wikipedia.org/wiki/Adidas", "url_shown": "https://en.wikipedia.org/wiki/Adidas", "favicon_text": "Wikipedia", "desc": "Adidas is a German athletic apparel and footwear corporation headquartered in Herzogenaurach." } ], "paid": [], "popular_products": [ { "title": "Popular products", "items": [ { "pos": 1, "title": "adidas Women's Samba OG", "seller": "DICK'S Sporting Goods", "currency": "USD", "price": "$99.99", "rating": "4.7", "rating_count": 20000 }, { "pos": 2, "title": "adidas Women's Grand Court 2.0", "seller": "adidas", "currency": "USD", "price": "$39.00", "previous_price": "$70.00", "rating": "4.7", "rating_count": 13000 } ] } ] } }, "created_at": "2026-01-01 12:00:00", "updated_at": "2026-01-01 12:00:02", "page": 1, "url": "https://www.google.com/search?q=adidas&hl=en&gl=us" } ], "parse_status_code": 12000 }
Render example



All-in-one solution
Structured, ready-to-use data from multiple websites through one API.

Fast-adapting infrastructure
Real-time updates keep data collection running through any website friction.

24/7 support
Fast troubleshooting and dedicated expert guidance available around the clock.
Target library
Pre-configured dedicated endpoints of Web Scraper API that collect live web data and simplify delivery. Each target supports customizable request parameters like location, language, custom headers, with automatic proxy rotation handled for you.
Universal Source
Universal Source
Parsing available with Oxy Parser
Raw HTML
See how your requests would look with the universal source.
86.9K
Amazon
Amazon ASIN: URL
Parsing available with Oxy Parser
Raw HTML
Scrape Amazon product pages by ASIN, including pricing, product details, reviews, seller informat...
2.1K
Amazon
Amazon Books: URL
Parsing available with Oxy Parser
Raw HTML
Scrape Amazon Books data by URL, including titles, authors, pricing, ratings, reviews, and more.
587
Amazon
Amazon: Best Sellers
Parsed JSON
22 Data Points
Discover Amazon Best Sellers data with Web Scraper API. Collect top-ranking product details, cate...
400
Amazon
Amazon: Pricing
Parsed JSON
23 Data Points
Access Amazon product pricing data with Web Scraper API. Retrieve price listings, discounts, and ...
15.0K
Amazon
Amazon: Product
Parsed JSON
129 Data Points
Extract Amazon product data effortlessly with Web Scraper API. Access titles, prices, reviews, an...
15.0K
Amazon
Amazon: Search
Parsed JSON
88 Data Points
Scrape Amazon search results with Web Scraper API. Retrieve product titles, prices, ratings & mor...
15.0K
Amazon
Amazon: Sellers
Parsed JSON
22 Data Points
Scrape Amazon seller pages with Oxylabs Web Scraper API. Get ratings, feedback, profile data & mo...
15.0K
Amazon
Amazon: URL
Parsing available with Oxy Parser
Raw HTML
Scrape Amazon pages by URL with Web Scraper API. Request examples, parsed output, JS rendering, g...
15.0K
Google Autocomplete: URL
Parsing available with Oxy Parser
Raw HTML
Extract Google Autocomplete suggestions by URL, including keyword predictions and search trends.
469
Google Books: URL
Parsing available with Oxy Parser
Raw HTML
Extract Google Books results by URL, including book titles, authors, publishers, ratings, and mor...
143
Google Carousel: URL
Parsing available with Oxy Parser
Raw HTML
Extract Google Carousel data by URL, including listed items, images, titles, and associated detai...
101
Google Events: URL
Parsing available with Oxy Parser
Raw HTML
Extract Google Events data by URL, including event titles, dates, locations, venues, and more.
307
Google Featured Snippet: URL
Parsing available with Oxy Parser
Raw HTML
Extract Google Featured Snippet data by URL, including the answer text, source URL, and related s...
117
Google Finance: URL
Parsing available with Oxy Parser
Raw HTML
Extract Google Finance data by URL, including stock prices, market trends, company financials, an...
421
Google Jobs: URL
Parsing available with Oxy Parser
Raw HTML
Extract Google Jobs results by URL, including job titles, locations, salaries, and more.
770
Google Knowledge Graph: URL
Parsing available with Oxy Parser
Raw HTML
Extract Google Knowledge Graph panel data by URL, including entity details, descriptions, key fac...
182
Google Local Pack: URL
Parsing available with Oxy Parser
Raw HTML
Extract Google Local Pack results by URL, including business names, ratings, addresses, phone num...
125
Google Product Listing Ads: URL
Parsing available with Oxy Parser
Raw HTML
Extract Google Product Listing Ads data by URL, including product titles, pricing, seller names, ...
124
Google Recipes: URL
Parsing available with Oxy Parser
Raw HTML
Extract Google Recipes results by URL, including recipe titles, ingredients, cook times, ratings,...
195
Google Related Questions: URL
Parsing available with Oxy Parser
Raw HTML
Extract Google Related Questions (People Also Ask) data by URL, including questions, answer snipp...
85
Google Related Searches: URL
Parsing available with Oxy Parser
Raw HTML
Extract Google Related Searches data by URL, including suggested search queries and keyword varia...
73
Google Scholar: URL
Parsing available with Oxy Parser
Raw HTML
Extract Google Scholar results by URL, including organic results, author citations, cited-by coun...
1.1K
Google Spell Check: URL
Parsing available with Oxy Parser
Raw HTML
Extract Google Spell Check suggestions by URL, including corrected queries and alternative search...
95
Google Top Stories: URL
Parsing available with Oxy Parser
Raw HTML
Extract Google Top Stories data by URL, including article headlines, publishers, timestamps, and ...
76
Google Video Results: URL
Parsing available with Oxy Parser
Raw HTML
Extract Google Video Results data by URL, including video titles, sources, durations, thumbnails,...
95
Google: Ads Max
Parsed JSON
17 Data Points
Scrape Google Search results optimized for maximum paid ad visibility, with parsed data for paid ...
1.3K
Google: AI Mode
Parsed JSON
12 Data Points
Extract Google AI Mode responses by submitting prompts, including the full response text, referen...
545
Google: AI Overviews
Parsed JSON
44 Data Points
Extract Google AI Overviews from search results with parsed data for answer text, bullet lists, p...
10.8K
Google: Image Search
Parsed JSON
19 Data Points
Extract Google Image Search results with parsed data, including organic image listings, image URL...
1.7K
Google: Lens
Parsed JSON
15 Data Points
Google Lens API extracts visual search results from provided image URLs. Returns visually matchin...
2.3K
Google: Local Search
Parsing available with Oxy Parser
Raw HTML
Google Local Search API retrieves location-based results for restaurants, hotels, and services wi...
10.8K
Google: News Search
Parsed JSON
25 Data Points
Scrape Google News results on a large scale and get completely parsed data. Extract articles with...
1.7K
Google: Travel: Hotels
Parsing available with Oxy Parser
Raw HTML
Scrape Google Travel: Hotels results with guest count, dates, and star rating filters. Flexible A...
328
Google: Trends: Explore
Parsing available with Oxy Parser
Raw HTML
Extract Google Trends data by keyword, date range, and category. API supports multiple search typ...
1.5K
Google: URL
Parsing available with Oxy Parser
Raw HTML
Google URL scraper retrieves content from any Google page with ease. Simple integration with code...
10.8K
Google: Web Search
Parsed JSON
269 Data Points
Comprehensive Google Search scraper with parsed data for organic results, ads, snippets, knowledg...
10.8K
Universal Source
1688: URL
Parsing available with Oxy Parser
Raw HTML
Scrape 1688 data by URL, including pricing, product images, collection details, and more.
1.6K
Universal Source
Adidas: URL
Parsing available with Oxy Parser
Raw HTML
Scrape Adidas data by URL, including product details, pricing, sizes, availability, reviews, and ...
811
Airbnb
Airbnb: Homes
Parsing available with Oxy Parser
Raw HTML
Scrape Airbnb property listings by ID.
59
Airbnb
Airbnb: URL
Parsing available with Oxy Parser
Raw HTML
Scrape any Airbnb URL of your choice (homes, experiences, services).
59
Alibaba
Alibaba: Product
Parsing available with Oxy Parser
Raw HTML
Scrape Alibaba product pages by product ID.
851
Alibaba
Alibaba: Search
Parsing available with Oxy Parser
Raw HTML
Scrape Alibaba search result pages by providing a search term.
851
Alibaba
Alibaba: URL
Parsing available with Oxy Parser
Raw HTML
Scrape any Alibaba URL of your choice.
851
Aliexpress
Aliexpress: Product
Parsing available with Oxy Parser
Raw HTML
Scrape Aliexpress product pages by product ID.
2.2K
Aliexpress
Aliexpress: Search
Parsing available with Oxy Parser
Raw HTML
Scrape Aliexpress search result pages by providing a search term.
2.2K
Aliexpress
Aliexpress: URL
Parsing available with Oxy Parser
Raw HTML
Scrape any Aliexpress URL of your choice.
2.2K
Allegro
Allegro: Product
Parsing available with Oxy Parser
Raw HTML
Scrape Allegro product pages by product ID.
25.7K
Allegro
Allegro: Search
Parsing available with Oxy Parser
Raw HTML
See how you should formulate your request to scrape Allegro search result pages.
25.7K
Avnet
Avnet
Parsing available with Oxy Parser
Raw HTML
See how you can start formulating Avnet scraping requests.
33
Universal Source
Baidu: URL
Parsing available with Oxy Parser
Raw HTML
Scrape Baidu search results by URL, including organic listings, ads, snippets, and more.
683
Bed Bath & Beyond
Bed Bath & Beyond: Product
Parsing available with Oxy Parser
Raw HTML
Scrape Bed Bath & Beyond product pages by product ID.
30
Bed Bath & Beyond
Bed Bath & Beyond: Search
Parsing available with Oxy Parser
Raw HTML
Scrape Bed Bath & Beyond search result pages by providing a search term.
30
Bed Bath & Beyond
Bed Bath & Beyond: URL
Parsing available with Oxy Parser
Raw HTML
Scrape any Bed Bath & Beyond URL of your choice.
30
Best Buy
Best Buy: Product
Parsed JSON
17 Data Points
Get Best Buy product details including pricing, ratings, and specifications. Extract parsed or HT...
1.1K
Best Buy
Best Buy: Search
Parsing available with Oxy Parser
Raw HTML
Scrape Best Buy search results with domain, store, and fulfillment filtering using Web Scraper AP...
1.1K
Bing
Bing: Search
Parsed JSON
22 Data Points
Extract Bing Search results with parsed data for paid ads and organic listings, with support for ...
709
Bing
Bing: URL
Parsing available with Oxy Parser
Raw HTML
See how you can start scraping Bing URLs.
709
Bodega Aurrerá
Bodega Aurrerá: Product
Parsing available with Oxy Parser
Raw HTML
Scrape Bodega Aurrerá product pages by product ID.
38
Bodega Aurrerá
Bodega Aurrerá: Search
Parsing available with Oxy Parser
Raw HTML
Scrape Bodega Aurrerá search result pages by providing a search term.
38
Bodega Aurrerá
Bodega Aurrerá: URL
Parsing available with Oxy Parser
Raw HTML
Scrape any Bodega Aurrerá URL of your choice.
38
Universal Source
Booking: URL
Parsing available with Oxy Parser
Raw HTML
Scrape Booking data by URL, including hotel listings, pricing, ratings, availability, amenities, ...
390
Cdiscount
Cdiscount: Product
Parsing available with Oxy Parser
Raw HTML
Scrape Cdiscount product pages by product ID.
32
Cdiscount
Cdiscount: Search
Parsing available with Oxy Parser
Raw HTML
Scrape Cdiscount search result pages by keyword, with support for pagination.
32
Cdiscount
Cdiscount: URL
Parsing available with Oxy Parser
Raw HTML
Scrape any Cdiscount page by providing a direct URL.
32
ChatGPT
ChatGPT
Parsed JSON
17 Data Points
Extract ChatGPT responses by submitting prompts, with parsed data including response text, Markdo...
1.6K
Universal Source
Chewy: URL
Parsing available with Oxy Parser
Raw HTML
Extract Chewy data by URL, including product descriptions, pricing, search results, and more.
743
Universal Source
Coppel: URL
Parsing available with Oxy Parser
Raw HTML
Scrape Coppel data by URL, including product details, pricing, availability, and more.
59
Costco
Costco: Product
Parsing available with Oxy Parser
Raw HTML
Scrape Costco product pages by product ID, with support for domain localization across multiple C...
859
Costco
Costco: Search
Parsing available with Oxy Parser
Raw HTML
Scrape Costco search result pages by keyword, with support for pagination and domain localization...
859
Costco
Costco: URL
Parsing available with Oxy Parser
Raw HTML
Scrape any Costco page by providing a direct URL.
859
Universal Source
Craigslist: URL
Parsing available with Oxy Parser
Raw HTML
Scrape Craigslist data by URL, including classified listings, pricing, descriptions, locations, a...
628
Dcard
Dcard
Parsing available with Oxy Parser
Raw HTML
Retrieve Dcard search results using Web Scraper API. Simple integration with code examples for mu...
25.7K
Universal Source
Depop: URL
Parsing available with Oxy Parser
Raw HTML
Scrape Depop data by URL, including product listings, pricing, seller profiles, descriptions, and...
476
eBay
eBay: Product
Parsing available with Oxy Parser
Raw HTML
Get eBay product pages by product ID, with support for domain localization across multiple eBay r...
2.4K
eBay
eBay: Search
Parsing available with Oxy Parser
Raw HTML
Scrape eBay search results by keyword, with support for pagination and domain localization across...
2.4K
eBay
eBay: URL
Parsing available with Oxy Parser
Raw HTML
See how to scrape any eBay URL of your choice.
2.4K
Etsy
Etsy: Product
Parsed JSON
29 Data Points
Extract Etsy product page data by product ID, including pricing, images, seller details, reviews,...
1.5K
Etsy
Etsy: Search
Parsing available with Oxy Parser
Raw HTML
See how you should formulate your request to scrape Etsy search result pages.
1.5K
Etsy
Etsy: URL
Parsing available with Oxy Parser
Raw HTML
Scrape any Etsy page by providing a direct URL.
1.5K
Universal Source
Expedia: URL
Parsing available with Oxy Parser
Raw HTML
Scrape Expedia data by URL, including flight, hotel, and car rental details, pricing, availabilit...
824
Falabella
Falabella: Product
Parsing available with Oxy Parser
Raw HTML
Scrape Falabella product pages by product ID.
64
Falabella
Falabella: Search
Parsing available with Oxy Parser
Raw HTML
Scrape Falabella search results by keyword, with support for pagination.
64
Falabella
Falabella: URL
Parsing available with Oxy Parser
Raw HTML
Scrape any Falabella page by providing a direct URL.
64
Flipkart
Flipkart: Product
Parsing available with Oxy Parser
Raw HTML
Scrape Flipkart product pages by product ID.
500
Flipkart
Flipkart: Search
Parsing available with Oxy Parser
Raw HTML
Scrape Flipkart search results by keyword, with support for pagination and JavaScript rendering.
500
Flipkart
Flipkart: URL
Parsing available with Oxy Parser
Raw HTML
Scrape any Flipkart page by providing a direct URL.
500
Universal Source
Fotocasa: URL
Parsing available with Oxy Parser
Raw HTML
Scrape Fotocasa data by URL, including property listings, pricing, locations, sizes, and more.
21
Universal Source
GitHub: URL
Parsing available with Oxy Parser
Raw HTML
Scrape GitHub data by URL, including search results, topics, trends, repositories, profiles, cont...
222
Universal Source
Google Play: URL
Parsing available with Oxy Parser
Raw HTML
Scrape Google Play data by URL, including app titles, pricing, version numbers, download rates, r...
1.4K
Grainger
Grainger: Product
Parsing available with Oxy Parser
Raw HTML
Scrape Grainger product pages by product ID, with support for domain localization across Grainger...
25.7K
Grainger
Grainger: Search
Parsing available with Oxy Parser
Raw HTML
Scrape Grainger search result pages by keyword.
25.7K
Grainger
Grainger: URL
Parsing available with Oxy Parser
Raw HTML
Scrape any Grainger page by providing a direct URL.
25.7K
Universal Source
Home Depot: URL
Parsing available with Oxy Parser
Raw HTML
Scrape Home Depot data by URL, including product details, pricing, search results, and more.
1.4K
Universal Source
Hotels.com: URL
Parsing available with Oxy Parser
Raw HTML
Scrape Hotels.com data by URL, including hotel listings, pricing, ratings, availability, and more...
425
Universal Source
Idealista: URL
Parsing available with Oxy Parser
Raw HTML
Scrape Idealista data by URL, including property listings, pricing, sizes, locations, description...
382
Universal Source
Indeed: URL
Parsing available with Oxy Parser
Raw HTML
Scrape Indeed data by URL, including job titles, locations, salaries, company reviews, and more.
949
IndiaMART
IndiaMART: Product
Parsing available with Oxy Parser
Raw HTML
Scrape IndiaMART product pages by product ID.
64
IndiaMART
IndiaMART: Search
Parsing available with Oxy Parser
Raw HTML
Scrape IndiaMART search result pages by providing a search term.
64
IndiaMART
IndiaMART: URL
Parsing available with Oxy Parser
Raw HTML
Scrape any IndiaMART URL of your choice.
64
Instacart
Instacart: Product
Parsing available with Oxy Parser
Raw HTML
Scrape Instacart product pages by product ID.
44
Instacart
Instacart: Search
Parsing available with Oxy Parser
Raw HTML
Scrape Instacart search result pages by providing a search term.
44
Instacart
Instacart: URL
Parsing available with Oxy Parser
Raw HTML
Scrape any Instacart URL of your choice.
44
Universal Source
Kobo: URL
Parsing available with Oxy Parser
Raw HTML
Scrape Kobo data by URL, including e-book titles, authors, pricing, ratings, and more.
17
Kroger
Kroger: Product
Parsing available with Oxy Parser
Raw HTML
Scrape Kroger product page data including pricing, availability, and fulfillment options using pr...
253
Kroger
Kroger: Search
Parsing available with Oxy Parser
Raw HTML
Scrape Kroger search pages with filters for price range, brand, and store location. Retrieve orga...
253
Kroger
Kroger: URL
Parsing available with Oxy Parser
Raw HTML
Scrape any Kroger page via a direct URL, supporting store-specific results, delivery ZIP codes, a...
253
Lazada
Lazada: Product
Parsing available with Oxy Parser
Raw HTML
Scrape Lazada product pages by product ID.
438
Lazada
Lazada: Search
Parsing available with Oxy Parser
Raw HTML
Scrape Lazada search result pages by keyword, with support for pagination and domain localization...
438
Lazada
Lazada: URL
Parsing available with Oxy Parser
Raw HTML
Scrape any Lazada URL of your choice.
438
Universal Source
Logitech: URL
Parsing available with Oxy Parser
Raw HTML
Scrape Logitech data by URL, including pricing, product images, and new releases.
18
Lowe's
Lowe's: Product
Parsing available with Oxy Parser
Raw HTML
Scrape Lowe's product pages by product ID, with support for store and delivery ZIP localization.
1.1K
Lowe's
Lowe's: Search
Parsing available with Oxy Parser
Raw HTML
Scrape Lowe's search results by keyword, with support for store and delivery ZIP localization, an...
1.1K
Lowe's
Lowe's: URL
Parsing available with Oxy Parser
Raw HTML
Scrape any Lowe's page using a direct URL, with support for store and delivery ZIP code localizat...
1.1K
Universal Source
Macy's: URL
Parsing available with Oxy Parser
Raw HTML
Scrape Macy's data by URL, including product details, pricing, reviews, sizes, colors, and more.
214
Magazine Luiza
Magazine Luiza: Product
Parsing available with Oxy Parser
Raw HTML
Scrape Magazine Luiza product pages by product ID.
51
Magazine Luiza
Magazine Luiza: Search
Parsing available with Oxy Parser
Raw HTML
Scrape Magazine Luiza search result pages by providing a search term.
51
Magazine Luiza
Magazine Luiza: URL
Parsing available with Oxy Parser
Raw HTML
Scrape any Magazine Luiza URL of your choice.
51
Universal Source
Marks: URL
Parsing available with Oxy Parser
Raw HTML
Scrape Marks & Spencer data by URL, including product details, pricing, sizes, availability, and ...
12
MediaMarkt
MediaMarkt: Product
Parsing available with Oxy Parser
Raw HTML
Scrape MediaMarkt product pages by product ID.
235
MediaMarkt
MediaMarkt: Search
Parsing available with Oxy Parser
Raw HTML
See how you should formulate your request to scrape MediaMarkt search results.
235
MediaMarkt
MediaMarkt: URL
Parsing available with Oxy Parser
Raw HTML
Scrape any MediaMarkt URL of your choice.
235
Menards
Menards: Product
Parsing available with Oxy Parser
Raw HTML
See how to scrape Menards product pages by product ID.
37
Menards
Menards: Search
Parsing available with Oxy Parser
Raw HTML
Scrape Menards search result pages by providing a search term.
37
Menards
Menards: URL
Parsing available with Oxy Parser
Raw HTML
Scrape any Menards URL of your choice.
37
Mercado Libre
Mercado Libre: Product
Parsing available with Oxy Parser
Raw HTML
Scrape Mercado Libre product pages by product ID, with support for domain localization across mul...
261
Mercado Libre
Mercado Libre: Search
Parsing available with Oxy Parser
Raw HTML
Scrape Mercado Libre search results by keyword.
261
Mercado Libre
Mercado Libre: URL
Parsing available with Oxy Parser
Raw HTML
Scrape any Mercado Libre page by providing a direct URL.
261
Mercado Livre
Mercado Livre: Product
Parsing available with Oxy Parser
Raw HTML
Scrape Mercado Livre product pages by product ID.
25.7K
Mercado Livre
Mercado Livre: Search
Parsing available with Oxy Parser
Raw HTML
Scrape Mercado Livre search results using Web Scraper API. Retrieve product listings with simple ...
25.7K
Universal Source
Mercari: URL
Parsing available with Oxy Parser
Raw HTML
Scrape Mercari data by URL, including product listings, pricing, item conditions, seller details,...
254
Universal Source
Milanuncios: URL
Parsing available with Oxy Parser
Raw HTML
Scrape Milanuncios by URL, including search listings, product data, price points, and other infor...
260
Universal Source
Newegg: URL
Parsing available with Oxy Parser
Raw HTML
Scrape Newegg data by URL, including product specifications, pricing, ratings, reviews, and more.
322
Universal Source
Notebooksbilliger: URL
Parsing available with Oxy Parser
Raw HTML
Scrape Notebooksbilliger data by URL, including product specifications, pricing, availability, an...
29
Universal Source
OpenSea: URL
Parsing available with Oxy Parser
Raw HTML
Scrape OpenSea data by URL, including NFT listings, pricing, collection details, ownership histor...
376
Universal Source
Overstock: URL
Parsing available with Oxy Parser
Raw HTML
Scrape Overstock data by URL, including product details, pricing, reviews, specifications, and mo...
17
Perplexity
Perplexity
Parsed JSON
24 Data Points
Extract Perplexity responses by submitting prompts, with parsed data including answer text, Markd...
327
Petco
Petco: Search
Parsing available with Oxy Parser
Raw HTML
Scrape Petco search result pages by keyword, with support for pagination, store selection, and fu...
32
Petco
Petco: URL
Parsing available with Oxy Parser
Raw HTML
Scrape any Petco page by providing a direct URL, with support for store-specific results.
32
Universal Source
Plus: URL
Parsing available with Oxy Parser
Raw HTML
Extract Plus data by URL, including product details, pricing, availability, and more.
13
Universal Source
Priceline: URL
Parsing available with Oxy Parser
Raw HTML
Scrape Priceline data by URL, including hotel, flight, and car rental details, pricing, availabil...
181
Universal Source
Product Hunt: URL
Parsing available with Oxy Parser
Raw HTML
Scrape Product Hunt data by URL, including product listings, descriptions, upvotes, reviews, and ...
1.7K
Publix
Publix: Product
Parsing available with Oxy Parser
Raw HTML
Scrape Publix product pages by product ID.
25.7K
Publix
Publix: Search
Parsing available with Oxy Parser
Raw HTML
Scrape Publix search result pages by providing a search term.
25.7K
Publix
Publix: URL
Parsing available with Oxy Parser
Raw HTML
Scrape any Publix URL of your choice.
25.7K
Universal Source
Quill: URL
Parsing available with Oxy Parser
Raw HTML
Scrape Quill data by URL, including product details, pricing, specifications, and more.
48
Rakuten
Rakuten: Search
Parsing available with Oxy Parser
Raw HTML
Scrape Rakuten search result pages by keyword.
28
Rakuten
Rakuten: URL
Parsing available with Oxy Parser
Raw HTML
Scrape any Rakuten page by providing a direct URL.
28
Universal Source
Redfin: URL
Parsing available with Oxy Parser
Raw HTML
Extract Redfin data by URL, including property listings, pricing, home sizes, locations, and more...
2.6K
Universal Source
Rockler: URL
Parsing available with Oxy Parser
Raw HTML
Scrape Rockler data by URL, including product details, images, pricing, and more.
12
Universal Source
Sephora: URL
Parsing available with Oxy Parser
Raw HTML
Scrape Sephora data by URL, including product details, pricing, delivery info, ingredients, and m...
418
Universal Source
Shein: URL
Parsing available with Oxy Parser
Raw HTML
Scrape SHEIN data by URL, including pricing, product images, descriptions, inventory levels, and ...
940
Universal Source
Skyscanner: URL
Parsing available with Oxy Parser
Raw HTML
Scrape Skyscanner data by URL, including flight, hotel, and car rental details, pricing, and more...
987
Universal Source
Sonos: URL
Parsing available with Oxy Parser
Raw HTML
Scrape Sonos data by URL, including product specifications, pricing, compatibility details, and m...
13
Staples
Staples
Parsing available with Oxy Parser
Raw HTML
Scrape Staples search result pages by keyword, with support for pagination and domain localizatio...
30
Universal Source
Taobao: URL
Parsing available with Oxy Parser
Raw HTML
Scrape Taobao data by URL, including product listings, titles, descriptions, pricing, and more.
824
Target
Target: Category
Parsing available with Oxy Parser
Raw HTML
Scrape Target category pages by taxonomy node ID, with support for store, fulfillment type, and d...
1.1K
Target
Target: Product
Parsed JSON
16 Data Points
Extract Target product pages by product ID with parsed data including pricing, brand, category, d...
1.1K
Target
Target: Search
Parsed JSON
24 Data Points
Extract Target search results with parsed data for organic listings, including pricing, ratings, ...
1.1K
Universal Source
Temu: URL
Parsing available with Oxy Parser
Raw HTML
Scrape Temu product and search data by URL, including pricing, descriptions, images, inventory le...
2.3K
TikTok
TikTok: Shop Product
Parsing available with Oxy Parser
Raw HTML
Get TikTok Shop product pages by product ID.
166
TikTok
TikTok: Shop Search
Parsing available with Oxy Parser
Raw HTML
Scrape TikTok Shop search result pages by keyword.
166
TikTok
TikTok: Shop URL
Parsing available with Oxy Parser
Raw HTML
Scrape any TikTok Shop page by providing a direct URL.
166
Tokopedia
Tokopedia: Search
Parsing available with Oxy Parser
Raw HTML
Scrape Tokopedia search result pages by keyword, with support for pagination.
25.7K
Tokopedia
Tokopedia: URL
Parsing available with Oxy Parser
Raw HTML
Scrape any Tokopedia page by providing a direct URL.
25.7K
Universal Source
Trendyol: URL
Parsing available with Oxy Parser
Raw HTML
Extract Trendyol data by URL, including product availability, pricing, descriptions, and more.
598
Universal Source
Trivago: URL
Parsing available with Oxy Parser
Raw HTML
Scrape Trivago data by URL, including hotel listings, pricing, ratings, availability, and more.
439
Walmart
Walmart: Product
Parsed JSON
59 Data Points
Extract Walmart product pages by product ID with parsed data including pricing, ratings, seller i...
2.6K
Walmart
Walmart: Search
Parsed JSON
58 Data Points
Extract Walmart search results with parsed data, including pricing, ratings, seller info, variant...
2.6K
Walmart
Walmart: URL
Parsing available with Oxy Parser
Raw HTML
Scrape any Walmart URL of your choice.
2.6K
Universal Source
Wayfair: URL
Parsing available with Oxy Parser
Raw HTML
Scrape Wayfair data by URL, including product details, pricing, reviews, specifications, and more...
936
Universal Source
Wikipedia: URL
Parsing available with Oxy Parser
Raw HTML
Scrape Wikipedia data by URL, including article content, references, categories, and more.
410
Universal Source
Worten: URL
Parsing available with Oxy Parser
Raw HTML
Scrape Worten data by URL, including product details, pricing, specifications, availability, and ...
118
Universal Source
Yandex: URL
Parsing available with Oxy Parser
Raw HTML
Scrape Yandex search results by URL, including organic listings, ads, snippets, and more.
1.5K
Universal Source
YellowBook
Parsing available with Oxy Parser
Raw HTML
Scrape YellowBook data by URL, including business listings, contact details, categories, and more...
95
Zillow
Zillow: URL
Parsing available with Oxy Parser
Raw HTML
Scrape any Zillow page by providing a direct URL.
2.2K
Universal Source
ZoomInfo: URL
Parsing available with Oxy Parser
Raw HTML
Extract ZoomInfo data by URL, including company profiles, contact details, industry information, ...
766
Universal Source
Zoopla: URL
Parsing available with Oxy Parser
Raw HTML
Scrape Zoopla data by URL, including property listings, pricing, locations, home specifications, ...
680
Web Scraper API pricing
Get started with a free trial
Micro
Up to 98,000 results
Starts from
$
0.50
/1K results
$49
billed monthly
VAT may apply
Successful results without JS rendering:
Amazon: $0.50/1K results
Google: $1.00/1K results
Other: $1.15/1K results
Successful results with JS:
$1.35 / 1K results
Media Download:
$3 / GB
Top up: up to $249
Rate limit: 50 requests / s
24/7 support
Dedicated Account Manager
Starter
Up to 220,000 results
Starts from
$
0.45
/1K results
$99
billed monthly
VAT may apply
Successful results without JS rendering:
Amazon: $0.45/1K results
Google: $0.90/1K results
Other: $1.10/1K results
Successful results with JS:
$1.30 / 1K results
Media Download:
$2.50 / GB
Top up: up to $499
Rate limit: 50 requests / s
24/7 support
Dedicated Account Manager
Business
Up to 3,330,000 results
Starts from
$
0.30
/1K results
$999
billed monthly
VAT may apply
Successful results without JS rendering:
Amazon: $0.30/1K results
Google: $0.60/1K results
Other: $0.75/1K results
Successful results with JS:
$1.00 / 1K results
Media Download:
$1 / GB
Top up: up to $499
Rate limit: 100 requests / s
24/7 support
Dedicated Account Manager
Custom+
Custom
Tailored Solutions for High-Volume Needs
Starts from:
$
0.25
/1K results
Successful results without JS rendering:
Amazon: $0.25/1K results
Google: $0.50/1K results
Other: $0.70/1K results
Successful results with JS:
$0.95 / 1K results
Media Download:
$0.95 / GB
Top up: up to $2000
Rate limit: 100 requests / s
24/7 support
Dedicated Account Manager
Can’t find the plan that suits your business case? Explore more options
Fast & Secure payments powered by Stripe
Why our Web Scraper API is the best choice
Reliable premium proxies
CAPTCHA handling
Adaptive custom parsers
Real-time data at scale
Automated scheduling
Batch scraping
JavaScript rendering
Flexibility for custom use cases
All-in-one solution for data collection at scale
Collect structured, ready-to-use data from multiple domains without managing infrastructure, maintenance, or downtime.
Fast-adapting infrastructure
Uninterrupted data access despite website changes, dynamic content, or blocks, through constantly updated and maintained scrapers.

Accurate & structured data
Delivers analysis-ready data to your chosen endpoint using a Custom Parser with XPath or CSS selectors that extract structured data – from product listings and image URLs to contact details – capturing only what you need.

Access to any public website
Sourced from premium providers only, 177M+ proxies across 195+ countries enable accurate, localized data from any region, with reliable proxy handling across the most popular targets.

24/7 technical support
Dedicated 24/7 technical support ensures fast troubleshooting and seamless operations, with an in-house engineering team for complex needs.

Guaranteed peak performance
Maintains 99.9% API uptime with high success rates and fast response time, returning data reliably regardless of request volume.

Explore what others achieved
View all stories




1,150+ positive reviews
Top-rated across platforms
Safe, secure, and industry recognized

Highest standards in security & compliance
SOC 2 Type 2 & GDPR









Leader in the G2 Enterprise Grid® Report
Summer, 2026

Most Scalable Provider
Proxyway, 2026
Certified infrastructure





Insured by Lloyd's
All of our products are covered by Technology Errors & Omissions (Technology E&O) and Cyber Insurance.

Oxylabs Dashboard
Each product solves departmental needs, and together, they power seamless operations across your organization.
Product management
Activate or deactivate products, manage users, control your IPs, rotate your API key, and more.

Limits & spending
Stay in control by tracking spend and setting limits – with a transparent pricing model and no hidden fees.

Advanced statistics
Monitor traffic, successful requests, and success rates for a clear view of performance.

Connect your AI agent to Web Scraper API
Skip the manual setup. The Oxylabs Agent Skills teach your AI agent to scrape through the Web Scraper API. Add it once, then just describe the job. Works with Claude, Cursor, Copilot, and more.
Open the Agent Skills repository1. Add Agent Skills
Drop our SKILL.md files into your AI agent.

2. Describe the task
Explain what you need in plain language.
3. Start building
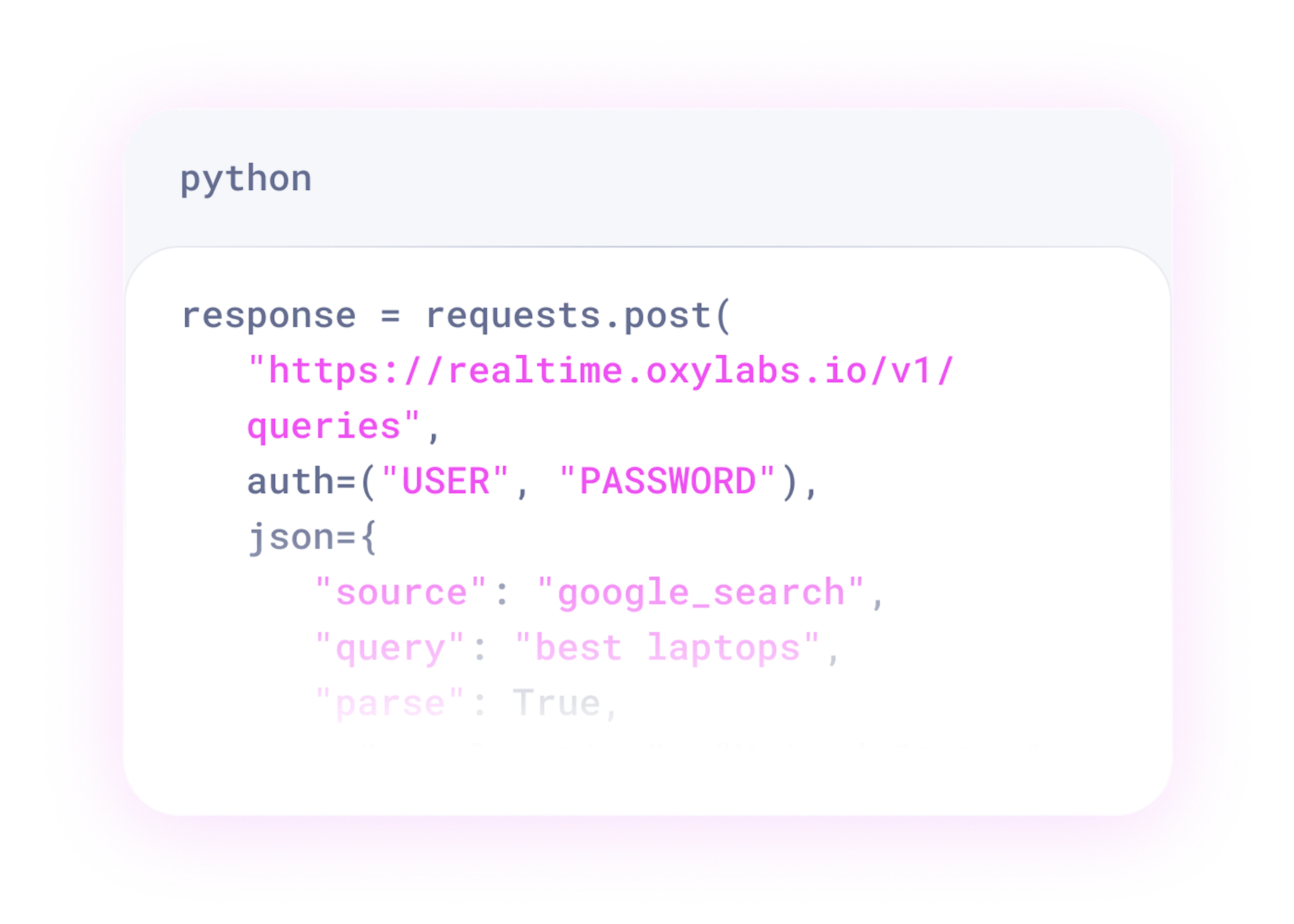
AI agent generates the code for you.
Integrate Web Scraper API with AI platforms
Web Scraper API feeds structured web data directly to the AI agents, LLM frameworks, and automation tools you use – a cloud-based service that plugs into low-code tools and code alike.














Frequently asked questions
What is a web scraping API?
A web scraping API is a software that retrieves data from a URL with the help of an API call. It helps establish a connection between a user and a web server to access and extract data. To compare the best web scraping APIs and pick the best web scraping API for your scraping infrastructure, you can explore our guide to the best web scraping APIs in 2026.
What type of data can I extract with Web Scraper API?
Can I automate recurring scraping jobs with Web Scraper API?
How long does Web Scraper API take to give the results back?
Is it legal to scrape a website?
How to use a web scraping API?
What is the difference between a scraper and a parser?
Does Web Scraper API have rate limits?
Is Web Scraper API ISO certified?
How to set up Postman with Web Scraper API?
Can I use JavaScript for web scraping?
What features should the best web scraping APIs include?
What features separate the best web scraping APIs from the rest?
What should you look for in the best web scraping APIs?
Try Web Scraper API today

Get the latest news from data gathering world
Scale up your business with Oxylabs®
Proxies
Advanced proxy solutions
Data Collection
Datasets
Resources
Innovation hub